目标:
- 学习模型中经典的网络模块
- 学习常用的损失函数
- 了解目前的进展
- 尝试发现一些我不了解的trick
说明:
- 研究的论文其实蛮多是关于super resolution,这里我将这两个大类简单地理解为一个概念。具体的概念分析可参考:https://www.zhihu.com/question/65791339?sort=created,简单来说图像复原 = denoising + SR + inpainting(图像修复)
- 我需要处理的输入图像分辨率较大,2K左右,需特别关注一些有利于压缩的操作。
参考:
https://github.com/icpm/super-resolution
https://github.com/kozistr/Awesome-GANs
https://blog.csdn.net/abluemouse/article/details/78710553
https://zhuanlan.zhihu.com/p/104407869
https://zhuanlan.zhihu.com/p/165050802
一些知识
整体目标
VDSR论文作者提到:输入的LR图像和输出的HR图像很大程度上是相似的,因为它们的低频信息相近,训练这部分会花费大量的时间,实际只需要学习LR和HR图像间高频部分的差别即可。因此,残差网络结构用适合用于解决超分问题。denoising任务中直接连接输入和输出能降低模型和学习复杂度
Resblock的发展脉落
图源见水印: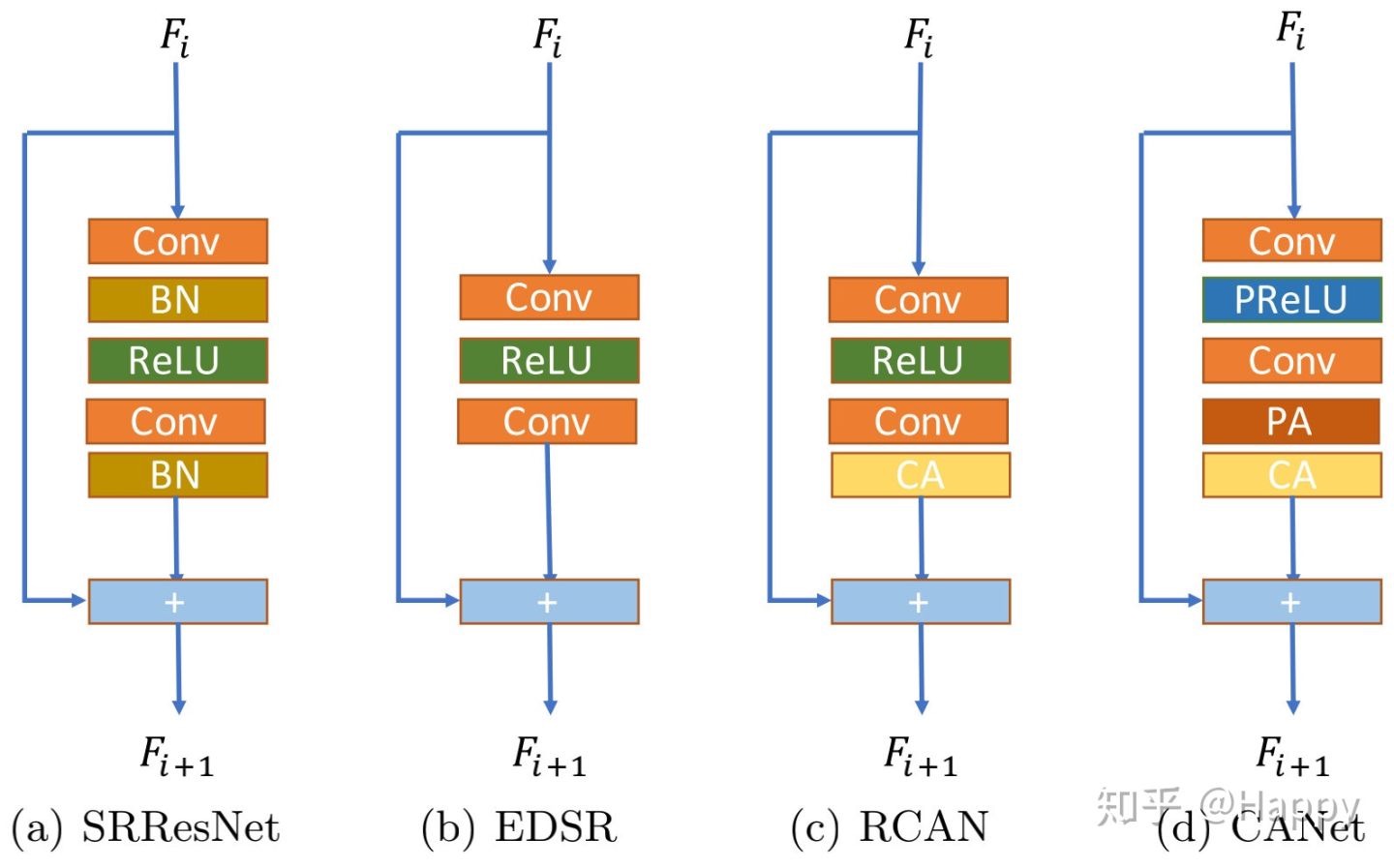
网络尾部的重建部分通常会采用PixelShuffle上采样(如EDSR、RCAN等)
Denoising和SR的区别
SR是由LR图像到HR图像。Denoising的输入输出分辨率相同,因此无需SR中的上采样层
SRGAN(SRResNet)(2016)
这是SR领域中目前引用量最高的论文
https://arxiv.org/abs/1609.04802
model
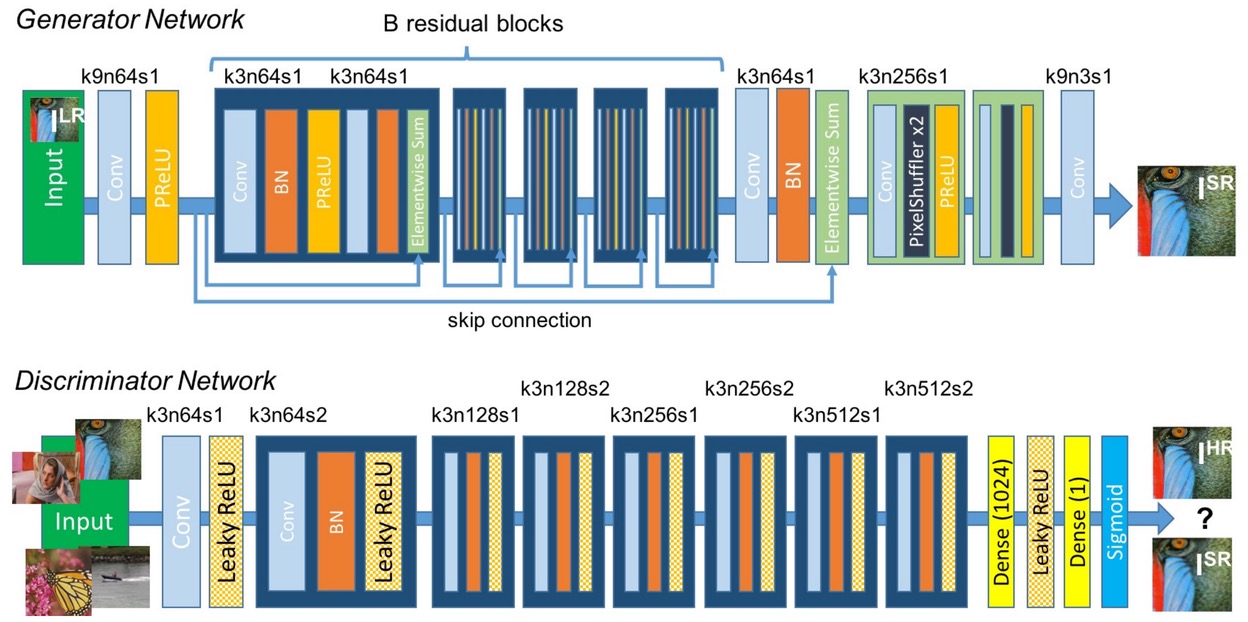
Generator
- 激活函数选择了PRelu(补课:PRelu是leaky relu的变体,根据数据集确实负值时的斜率)
- 最后几层都没有BN
- 有sum操作无concat操作
- PixelShuffle(不确定是不是shuffleNet中的shuffle操作,如果后续的经典论文中也用到了这个结构我就来细看,2016, https://arxiv.org/abs/1609.05158,nn.pixelshuffle,作用是上采样)
- ResBlock后面没有relu层
Discriminator
Disc loss
EDSR (2017)
model
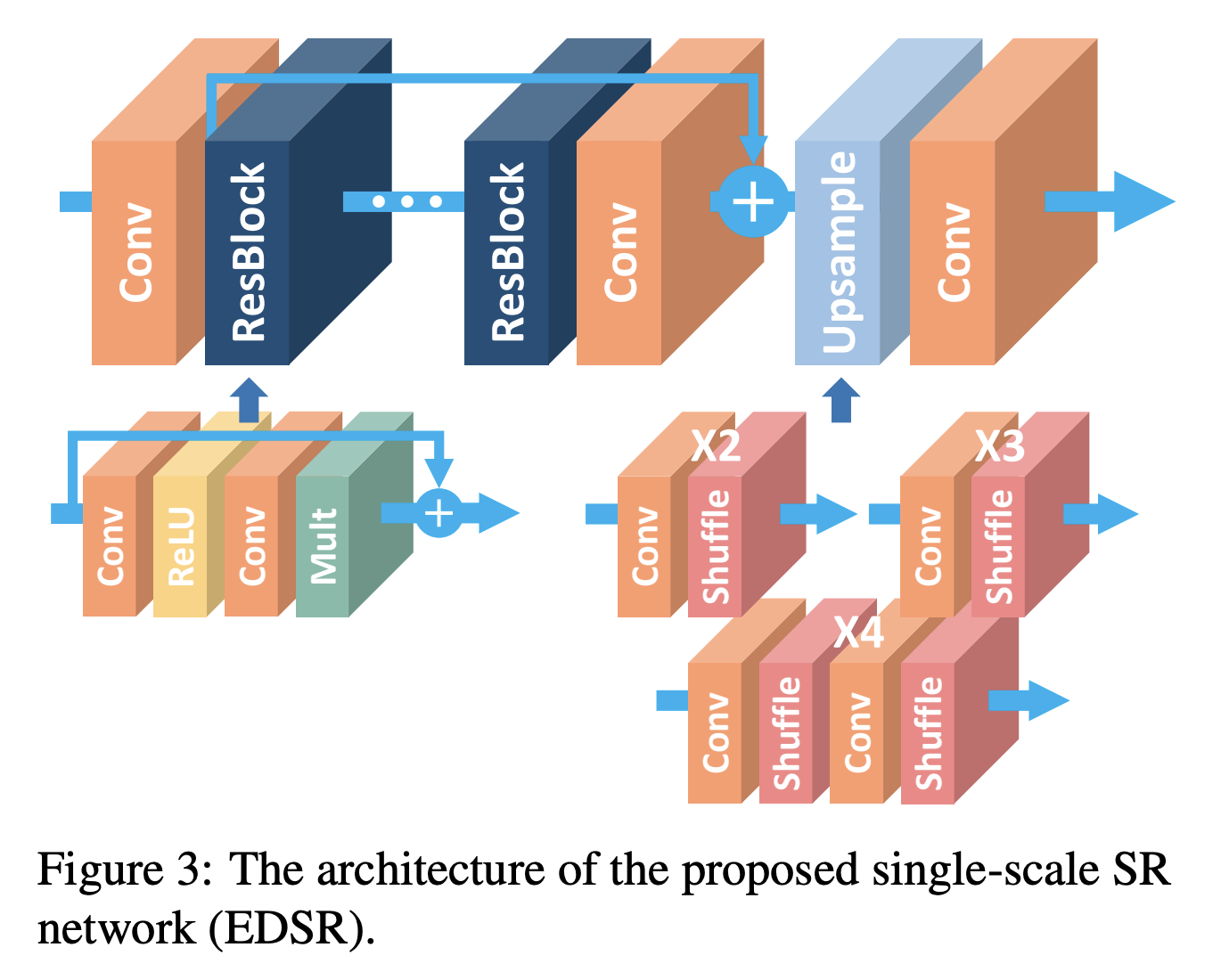
Generator
主要是基于SRGAN做了修改,去除其中多余的模块,从而扩大模型尺寸提高结果
- 主要是对Resblock进行了修改,见下图
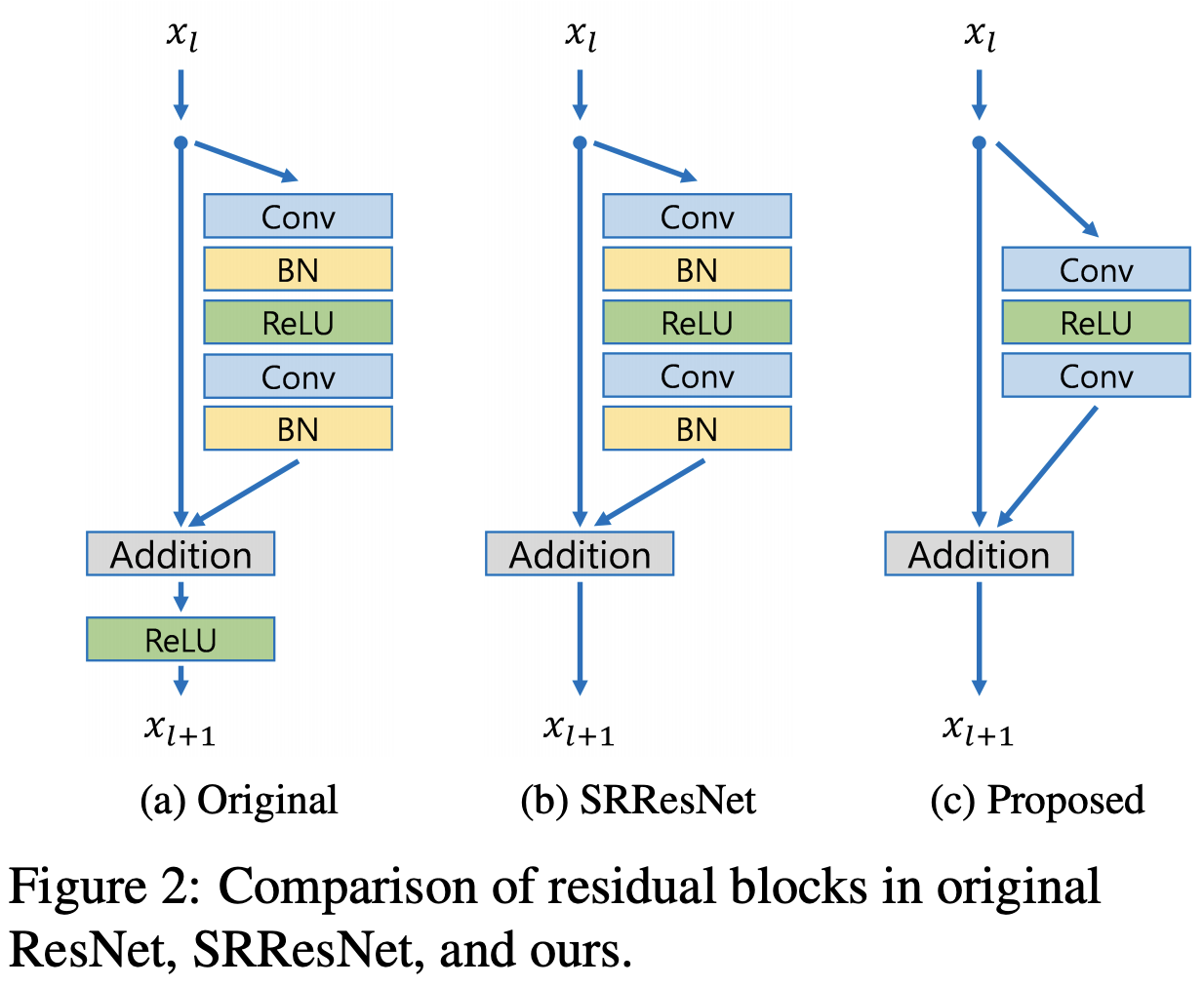
- 最有提升的点在于去掉BN层(BN会是网络训练时使数据包含忽略图像像素(或者特征)之间的绝对差异(因为均值归零,方差归一),而只存在相对差异。所以在不需要绝对差异的任务中(比如分类),BN提升效果。而对于图像超分辨率这种需要利用绝对差异的任务,BN会适得其反。)
other tricks
- 残差缩放(过多的残差块会使训练过程中的数值不稳定,残差缩放在残差块相加前,让经过卷积处理的一路剩以一个小数,作者用了0.1。参考:https://www.pianshen.com/article/2449328261/)
RCAN(2018)
反对EDSR中简单地堆叠Resblock,RCAN作者认为应该更好地利用特征,提出了channel attention对特征图中的通道赋予不同的权重,增加通道的差异性。
class CALayer(nn.Module):def __init__(self, channel, reduction=16):super(CALayer, self).__init__()# global average pooling: feature --> pointself.avg_pool = nn.AdaptiveAvgPool2d(1) # shape: (1, 1, channel),所以是channel attention# feature channel downscale and upscale --> channel weightself.conv_du = nn.Sequential(nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),nn.ReLU(inplace=True),nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),nn.Sigmoid())def forward(self, x):y = self.avg_pool(x)y = self.conv_du(y)return x * y
Deep Generative Prior (ECCV2020 oral)
https://zhuanlan.zhihu.com/p/165050802
PANet
https://zhuanlan.zhihu.com/p/137496566
https://github.com/SHI-Labs/Pyramid-Attention-Networks
这个好像给很多任务都单独去训练了一个模型,不确定整体效果怎么样

若有收获,就点个赞吧
0 人点赞
