一句话总结
利用深度网络生成仿射变换的系数矩阵和引导图,做空间和颜色深度上的插值,实现图像增强。
一图观全文
论文阅读
Introduction
作者想针对摄影图像实现实时增强,提出了三个key strategies:
- slicing: We perform most predictions in a low-resolution bilateral grid。
这里引入一个新节点用来查找数据,以允许后续的slicing operation
slicing operation指的是在输入像素基础上对原始分辨率图像的重建 - affine color transform: it is often simpler to predict the transformation from input to output rather than predicting the output directly
学仿射变换的系数,而非直接学输出图像 - full-resolution loss: While most of our learning and inference is performed at low resolution, the loss function used during training is evaluated at full resolution
引导图和学习是基于低分辨率,但损失函数基于高分辨率
Architecture

上面一行,We perform most of the inference on a low-resolution copy ˜I of the input I in the low-res stream. our low-res stream is further split into a local path and a global path. Our architecture then fuses these two paths to yield the final coefficients representing the affine transforms. 原图上生成一个低分辨率版本,从局部和全局考虑合成最终的仿射变换的系数
下面一行,The high-res stream works at full resolution and performs minimal computation but has the critical role of capturing high-frequency effects and preserving edges when needed. We introduce a slicing node inspired by bilateral grid processing. This node performs data-dependent lookups in the low-resolution grid of affine coefficients based on a learned guidance map. 原始分辨率上执行的操作很少,但对捕捉高频信息和边缘非常重要。引入双边网格处理的slicing node,这个node会基于学习到的原始分辨率guidance map在低分辨率网格上查找系数获得颜色。训练时,使用的loss是基于原始分辨率的
综上,本文其实是在低分辨率下寻找双边网格中仿射变换的系数。其中有三个注意点。
- 生成双边网格的下彩样过程是学习得到的
- 引导图是学习得到的,对光照不敏感
损失函数不是基于双边网格,而是基于原始分辨率的最终生成图像。
低分辨率下双边仿射系数的预测
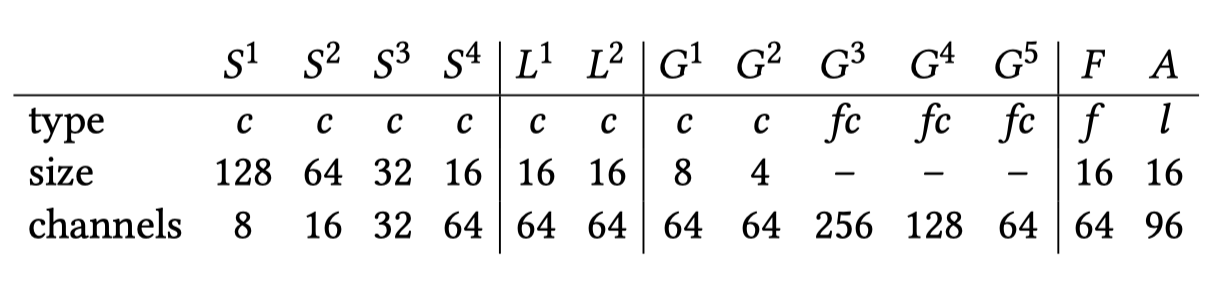
先缩放到固定尺寸(256*256,因为之后会用到全连接)。
- 接着使用strided convolution去提取低层特征、降低分辨率。low-level features
将空间尺寸降低有两个好处:空间下采样;控制最终系数的复杂程度(这边主要是和其它非深度学习方法做比较) - 然后用两个对称的方法处理特征。
3.1 局部特征处理, local features,用了两个stride=1的普通卷积.
这里只要控制low-level features和local features的卷积层数,就能控制最终系数的空间清晰度
3.2 全局特征处理,Global features,用两个stride=2的普通卷积和三个全连接层,生成64维的数据
因为有全连接层,所以输入需要固定尺寸,但由于slicing operation,增强的还是原尺寸图像 - 融合局部特征和全局特征
融合的公式挺好理解的,就是对应位置权重,相加后做relu激活,生成16_1664
再做一个卷积生成1616*96

这一部分的网络结构如下图所示。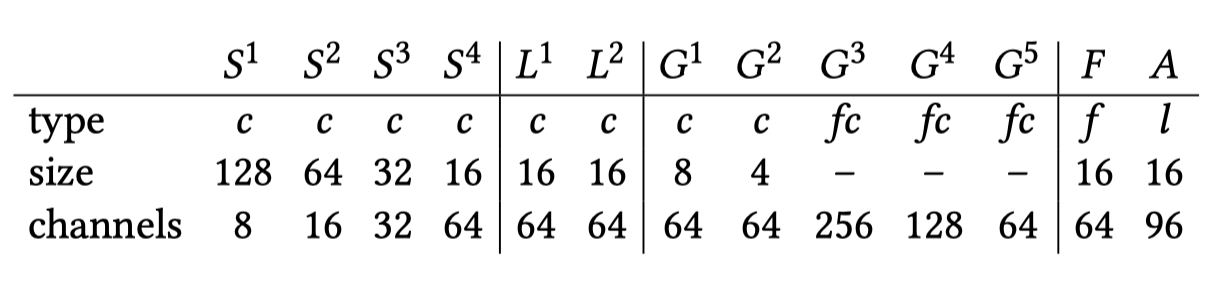
将输出看成双边网格
这个地方看不懂的有很多。
将161696的深度网络输出,看成是16168(8是Depth)的双边网格,每个格子含有3*4大小的仿射变换矩阵
使用可训练的slicing layer进行上采样
这一步的目的是为了把仿射变换系数应用到原始输入中,为此作者引入了前人的工作:a layer based on the bilateral grid slicing operation。slicing layer需要一张引导图g,一张分辨率远低于g的双边网格A。它提供数据查询功能,以便反向传播用于训练
g提供gray scale value,根据这个value去查询双边网格A中数值时有对应的Depth,
slicing layer相比反卷积,保留了边缘信息且更快
原始分辨率输出
- 先生成引导图(guidance map)
![[HDRNet]Deep Bilateral Learning for Real-Time Image Enhancement - 图5](/uploads/projects/grace-gu2@cv/107b4fabc9c336ab6323f526d70cda69.svg)
用一个颜色转换矩阵+分段线性函数生成引导图,其中的参数都是学习得到的。 - 整合输出结果
(尽管从整个图像的角度看图像操作符可能很复杂,但是最近的工作发现,即使是复杂的图像处理管道,也通常可以准确地建模为简单局部变换的集合)![[HDRNet]Deep Bilateral Learning for Real-Time Image Enhancement - 图6](/uploads/projects/grace-gu2@cv/b85c77b5bb22d52841b39f1419629dcd.svg)

若有收获,就点个赞吧
0 人点赞

{kind=link}