论文
明确一下阅读重点:HDRNet: Deep Bilateral Learning for Real-Time Image Enhancement中提到了slicing node,将3*4的仿射矩阵应用到原始分辨率中,讲的非常粗,完全没看懂。希望通过阅读这篇理解这个步骤。
听说需要了解JBU(Joint Bilateral Upsampling),我决定先看这篇,看得懂就不看JBU了,看不懂就再去补JBU的课。
这篇论文有很多细节不是非常理解,大概逻辑学习了一下
bilateral grid的演变历史可以看这个链接:https://zhuanlan.zhihu.com/p/37404280
Abstract
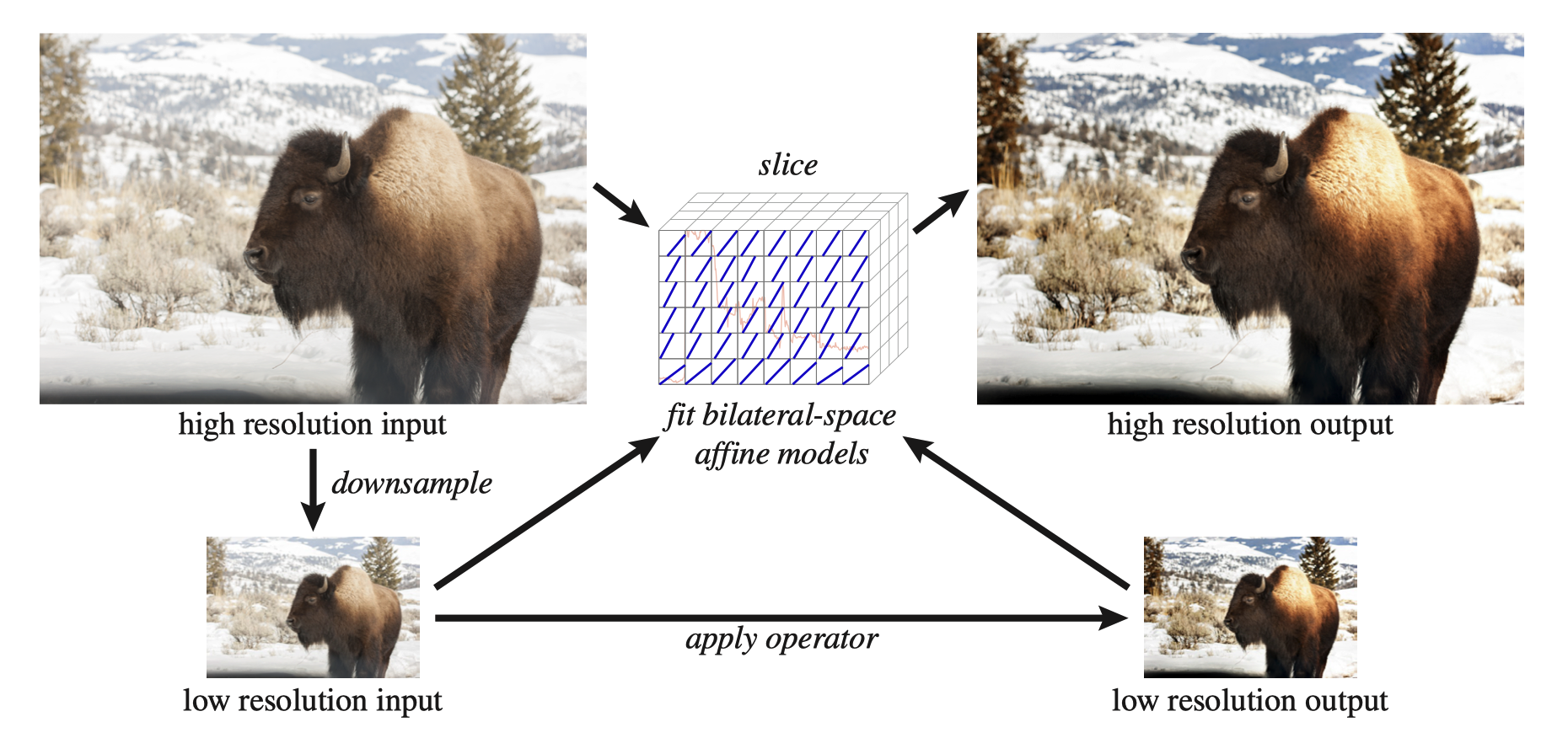
通过低分辨率的引导图输入和输出pair,作者模拟局部曲线进行建模,实现了全分辨率图像的输出。建模的方法是将输入转换成双边网格(bilateral grid),求解从低分辨率输入到输出的最佳3D(x, y, intensity bin)仿射变换矩阵。对该矩阵添加平滑项(smoothness term)避免伪边缘和噪声。
该算法拟合曲线在移动端用时10ms,在桌面CPU用时1-2ms。
该方法可应用于色调转换、网格迁移和上色。
Introduction
之前的方法部署在移动端时都比较慢。一个简单的加速方法是:对低分辨率应用变换操作,将其上采样并引入部分细节实现高分辨率的结果输出。Joint Bilateral Upsampling和Fast Guided Filter都是这样。
本文提出Bilateral Guided Upsampling,结合了这两种方法。
(之后的内容我觉得讲的比较碎(可能是因为我还不理解),做一个概括)
- 产生伪边缘、光晕或噪声,所以需要双边空间中的平滑操作
- 三次线性插件是一个关于(x, y, intensity)的函数,x和y表示位置
- 介绍了Joint Bilateral Upsampling和Fast Guided Filter的区别(这里没看懂)
- 低分辨率是原分辨率的1/8,操作可以减少到原来的1/64,速度会很快
-
Related Work
双边滤波是非线性的,能保护边缘。
相比较He的2D矩阵,本文采用3D矩阵,对每种强度采用不同的仿射函数,能获得更强的特征表达能力。如果输入是灰度图(极端情况),本文方法即guided filter
Gharbi的方法也不错,提出了transform recipe的方法,但是这个方法在云端跑且难以在移动端使用。Local properties of Imaging Operators
这一方法背后的理论
这一大段写了很多翻译,但句子翻译过来了,作者讲的细节我没懂。最后删掉了。总之这一段作者利用一些常理性知识、泰勒展开式证明: 输出在输入有扰动时的变化应尽可能小
- 对不同强度使用不同的映射模型是合理的
- 对于输入的每个patch,当这过大时,算子无法模拟其映射。因此需要分块、合理安排patch
- 出于平滑的考虑,在低分辨率上模型这种映射关系是合理的
- 3D的映射矩阵存储的是仿射模型的参数,而非颜色
为什么仿射变换矩阵不是基于(x, y, r, g, b)?因为空间太大了
Algorithm
主体思路:在低分辨率下拟合仿射变换模型,应用到高分辨率上。
应用到高分辨率上时会使用3*4的仿射色彩变换进行三次线性插值。准备工作
通过三步创建双边网格
splat the input
- blur the values(一个小的高斯核)
- slice the values out of the grid(在引导图同样的位置进行采样)
其中splt矩阵和slice矩阵互为转置
(我觉得这儿应该是超级精华的步骤,但我对splat、slice的意思一知半解)
优化
构建优化函数(energy function):线性最小二次平方和,是数据和平滑项的和
gama是whd34的元素矩阵。S^T是三次线性插值的slice矩阵,A是低分辨率输入图像,将其复制并整形,使得能对每个像素应用3*4矩阵的矩阵(怎么整形还不理解)。beta是我们期望得到的低分辨输出。
Fast approximation
优化函数不在全局使用,而是对每一块使用。
alpha是输入的RGB矩阵,Beta是输出的RGB矩阵。M是34维的变换矩阵。我们期望求解M:
优化可得:
这一部分解答了一个问题,为什么变换矩阵是34。
3还挺好理解的。因为我们期望输出是RGB三个值。
4是因为我们在输入RGB基础上加上第4维,是一个常数1。这个操作在图像变换中还挺常见的,一开始不懂,现在觉得还蛮简单
输入4维,输出3维,变换矩阵就是34了
作者在每个输入像素上进行迭代,双边网格与位置和强度对应,并累加该单元的alpha alpha’ 和 beta * alpha’。
[疑问: 前者是对称矩阵,每个单元上会累积22个不同的值(为啥是22??)。]
接着使用7个独立的滤波,对x轴、y轴和强度轴上的22个项模糊,增强平滑。该优化问题变为重叠加权最小二乘问题。滤波使用了Farbman等人的1 /(r + 1)3滤波器。(这个滤波器我也不懂,但因为不是研究重点,我把这个问题先搁置了)
最后说明了本文算法和fast guided filter和joint bilateral upsampling的区别。
fast guided filter:借鉴Gram矩阵,没有针对intensity进行建模
joint bilateral upsampling:求解的是结果,而非变换矩阵

若有收获,就点个赞吧
0 人点赞
