本书是基于JDK7创作的,所以下面说的性质都是JDK7特性的总结
- 为什么要使用ConcurrentHashMap?
- JDK7中ConcurrentHashMap的结构
- JDK7中ConcurrentHashMap的初始化过程
- key-value进入后,如何判断属于那个segment呢?
- get操作
- put操作
- size操作
为什么要使用ConcurrentHashMap
- HashMap不是线程安全的,在并发环境下,put操作会发生死循环
- Hashtable是线程安全的,但是每个操作都是synchronized修饰,太慢
- ConcurrentHashMap也用锁,但是不锁全部的Map,使用 分段锁。
```java
//jdk7 死循环代码
public static void main(String[] args) throws InterruptedException {
final Map<String,String> map = new HashMap<>(2);Thread thread = new Thread(new Runnable() {@Overridepublic void run() {for (int i = 0; i < 10000; i++) {new Thread(new Runnable() {@Overridepublic void run() {map.put(UUID.randomUUID().toString(), "");// System.out.println("hello");}}, "gx" + i).start();}}}, "gx");thread.start();thread.join();
}
<a name="ImVSn"></a># JDK7中ConcurrentHashMap结构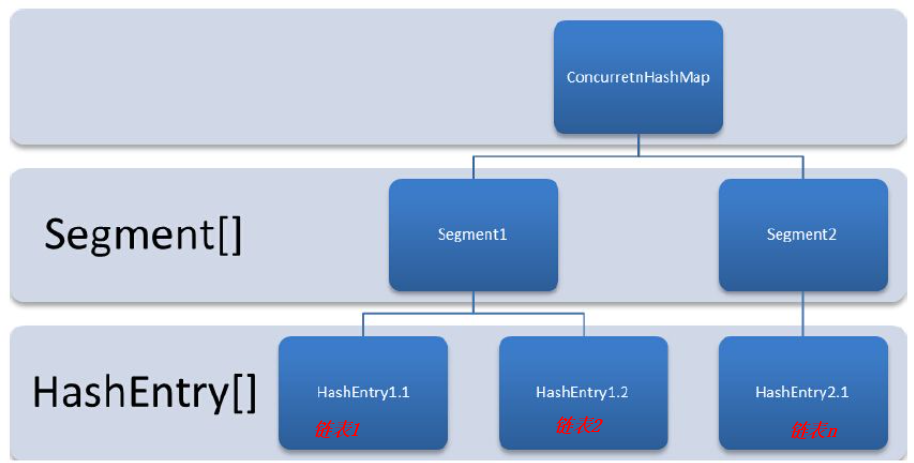<br />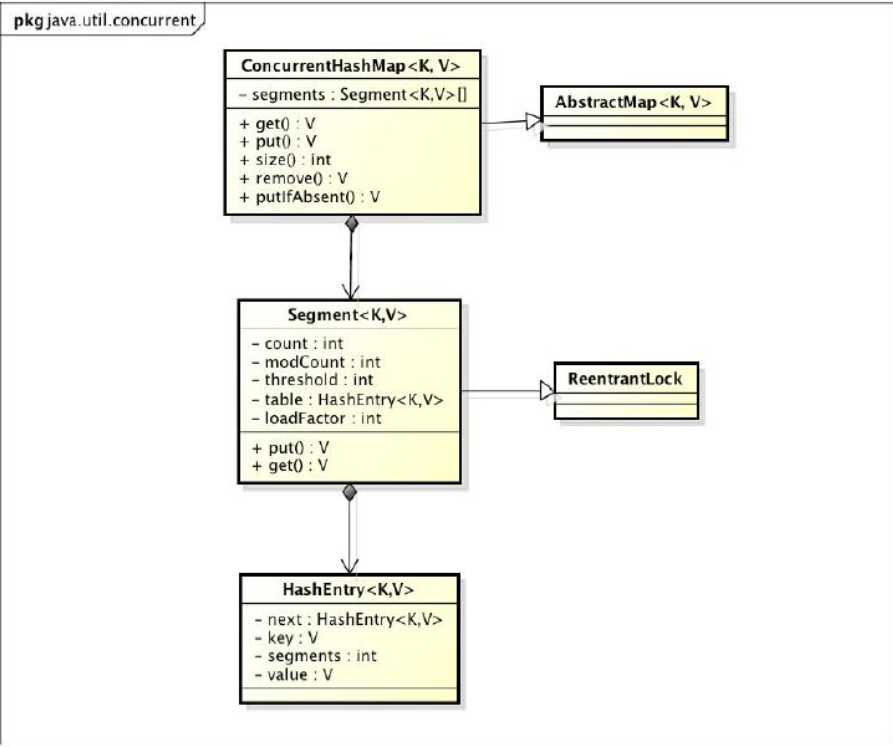- 一个ConcurrentHashMap里包含一个Segment数组- 每个Segment基础ReentrantLock- 每个Segment的结构又和一个HashMap结构类似,数组链表- HashEntry数组,每个数组的元素是一个链表。<a name="QURFK"></a># JD7中初始化过程<a name="l5rlr"></a>## 重要参数- initialCapacity:初始化容量,默认16- loadFactor:加载因子,默认 0.75- concurrencyLevel:指定Segement数组长度,默认16用上面三个参数来初始化下面参数- segment数组:- segmentShift:段偏移量- segmentMask:段掩码- segment中的HashEntry数组<a name="Uq8Ng"></a>## 初始化segments数组和掩码和偏移量```java//三个参数都要大于0if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();if (concurrencyLevel > MAX_SEGMENTS)concurrencyLevel = MAX_SEGMENTS;// Find power-of-two sizes best matching argumentsint sshift = 0;//指定segment数组的长度,必须2^Nint ssize = 1;while (ssize < concurrencyLevel) {//偏移次数++sshift;ssize <<= 1;}//偏移量 据左边this.segmentShift = 32 - sshift;this.segmentMask = ssize - 1;
- concurrenyLevel用来计算segments数组的长度
- 最后以ssize为准,是2^N
- sshift计算的是1左移次数,也就是ssize的二进制值,然后用32-sshift得到segmentShift
- segmentMask等于ssize-1
初始化每个segment
```java if (initialCapacity > MAXIMUM_CAPACITY)
//初始容量 / segment数组大小 , 每个segment中应该有多少个元素 int c = initialCapacity / ssize; //不能整除要+1, 可多不可少 if (c * ssize < initialCapacity)initialCapacity = MAXIMUM_CAPACITY;
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;while (cap < c)cap <<= 1;// create segments and segments[0]Segment<K,V> s0 =new Segment<K,V>(loadFactor, (int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]this.segments = ss;
- cap:是segment中HashEntry数组的长度,最小值为2- cap*loadFacotr:是每个segment的阈值。<a name="LWkBY"></a># 定位Segment一个key-value对进入后,如何判断其放在哪个segment中。<br />是通过Wang/Jenkins hash的变种算法对元素的hashCode进行再散列```javaprivate int hash(Object k) {int h = hashSeed;if ((0 != h) && (k instanceof String)) {return sun.misc.Hashing.stringHash32((String) k);}h ^= k.hashCode();// Spread bits to regularize both segment and index locations,// using variant of single-word Wang/Jenkins hash.h += (h << 15) ^ 0xffffcd7d;h ^= (h >>> 10);h += (h << 3);h ^= (h >>> 6);h += (h << 2) + (h << 14);return h ^ (h >>> 16);}
通过上面的方法计算了散列值后,通过下面一段代码找到具体的index
int j = (hash >>> segmentShift) & segmentMask;if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegments = ensureSegment(j);
- hash后的结果int,无符号右移后&掩码的作用是让长度落在数组范围
get操作
get操作流程简单经过一次再散列,定位到segment,再调用segment的get获取值
get操作整体若读取的值是空,才会加锁重读。
原因:get方法将要使用的共享变量定义成了 volatile。
在segment中的散列是通过hashCode直接&
put操作
put操作方法必须加锁

若有收获,就点个赞吧
0 人点赞
