问题
面试官:能说说es的深度分页的解决办法吗? 我:额,额,额 面试官:好今天面试就到这里吧!回去等待通知。
实验环境

- ES分页写法
- 指定
from和size即可。 from=0,size=10等价于SQL中limit 0,10```json GET /zipkin2:span-2022-03-29/_search { “from”: 0, “size”: 10 }
- 指定
2. Java Transport Client API```javaSearchRequestBuilder searchRequestBuilder = transportClient.prepareSearch("zipkin2:span-2022-03-29").setFrom(from).setSize(size);SearchResponse response = searchRequestBuilder.get();
常规分页问题
6.4.2官方文档中点出:from+size>
max_result_window就不可以用from和size了。max_result_window默认值为10000

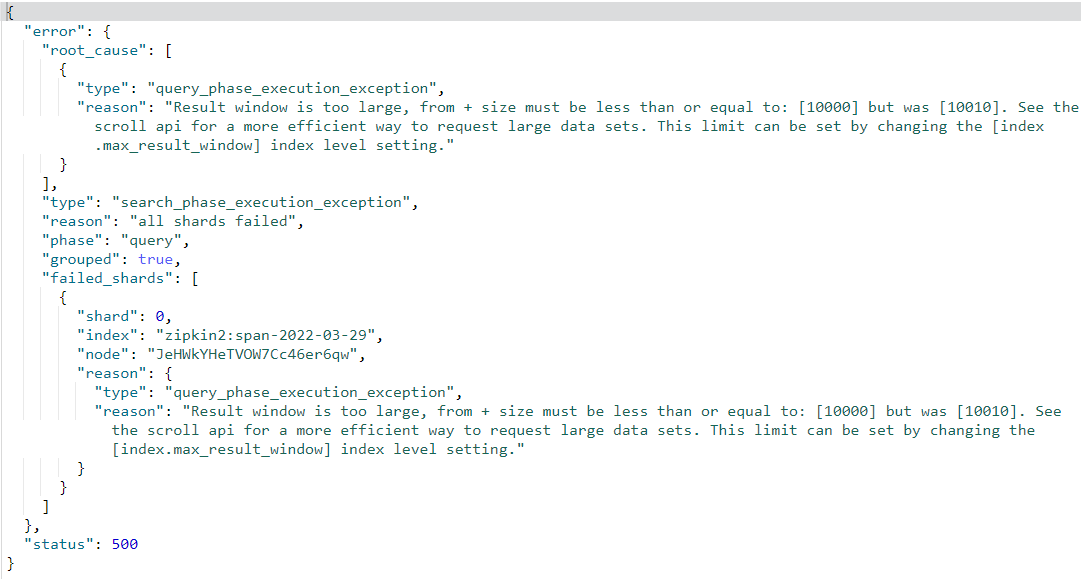
Scroll解决方法
使用方式
步骤1:设置每页大小,指定scroll的存活时间
GET /zipkin2:span-2022-03-29/_search?scroll=1m{"size": 10}
执行结果: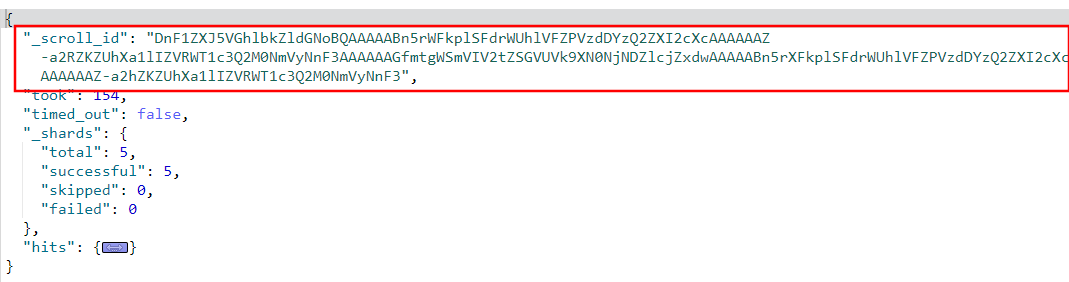
这里会返回一个
_scroll_id,用作下次查询的入参
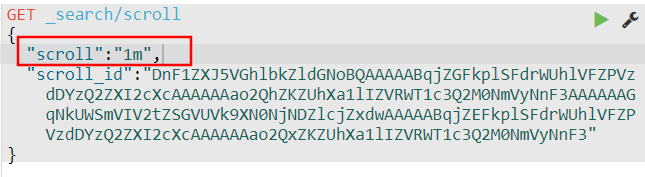
步骤2:进行之后每页数据查询
GET _search/scroll{"scroll":"1m","scroll_id":"DnF1ZXJ5VGhlbkZldGNoBQAAAAABn6m7FkplSFdrWUhlVFZPVzdDYzQ2ZXI2cXcAAAAAAZ-pvRZKZUhXa1lIZVRWT1c3Q2M0NmVyNnF3AAAAAAGfqb8WSmVIV2tZSGVUVk9XN0NjNDZlcjZxdwAAAAABn6m-FkplSFdrWUhlVFZPVzdDYzQ2ZXI2cXcAAAAAAZ-pvBZKZUhXa1lIZVRWT1c3Q2M0NmVyNnF3"}
scroll_id:一直指定首次查询的scroll_idscroll:暂时理解,是每次为scroll_id中正在使用的游标续命(这块我在后面解释)分片Scroll
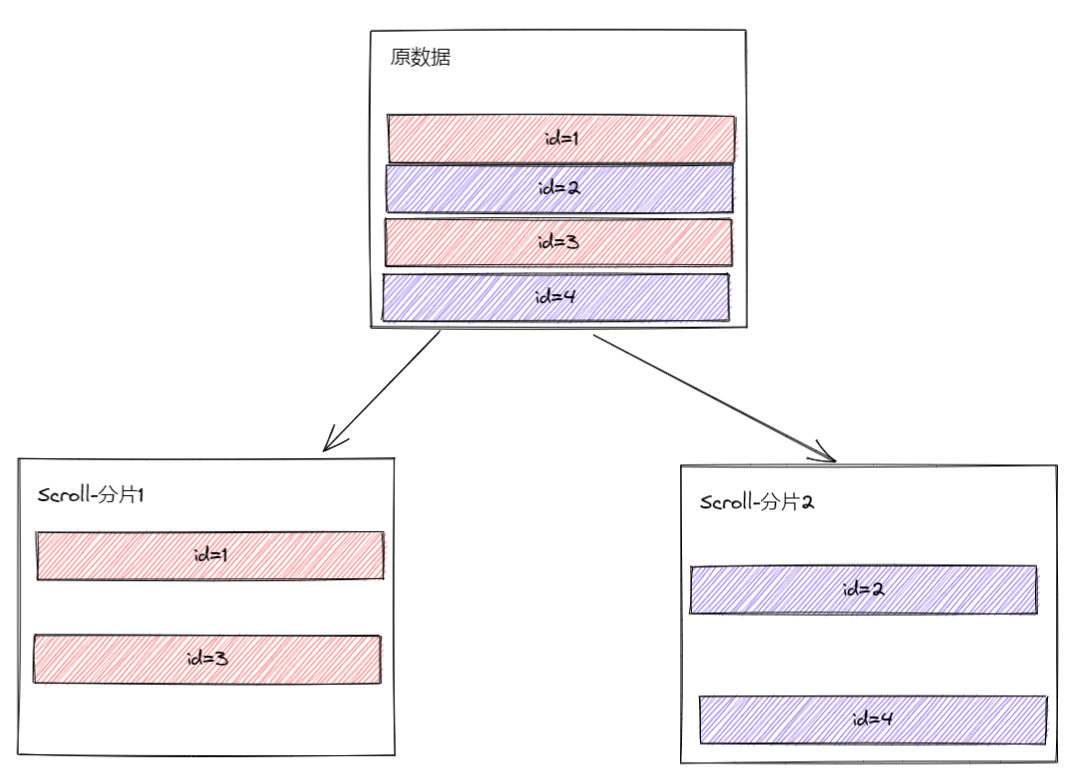
分片Scroll其实就是原本的一个Scroll分为多个Scroll。可以指定字段进行分片。多个分片的Scroll数据加起来是之前一个Scroll的数据。不分片的情况

分片的情况
每次查询中指定scroll的作用
作用:就是为当前使用的search context(游标) 续命。若不指定
scroll,当前的search context(游标)就被释放了。以我实验的结果,推测一下大致的模型
- 就是说,我原数据从不同的起点开始分成多个search context
- 最开始使用第一个search context。
- 若前面的search context过期啦,从接下来的search context开始走
- 每个search context有个游标。

Search After解决方法
Scroll可以解决深度分页问题,但是对于用户实时查询的场景,Scroll的价值太大了。

- 比如:我上一页的最后一条数据id=100,那我下一页就要从id>100查询。
对应SQL深度分页
```plsql上一页最后一个数据的id =100
select * from table_name where id>100 limit 10;
<a name="QO1AC"></a>### 使用方式在我的数据集中,有个timestamp_millis时间戳字段。当然这里用时间戳不合适。因为有重复> 官方说一定要无重复字段:> <a name="GSAwP"></a>#### 步骤1: 第1页查询不用`scroll after````java{"size": 10,"sort": [{"timestamp_millis": {"order": "desc"}}]}
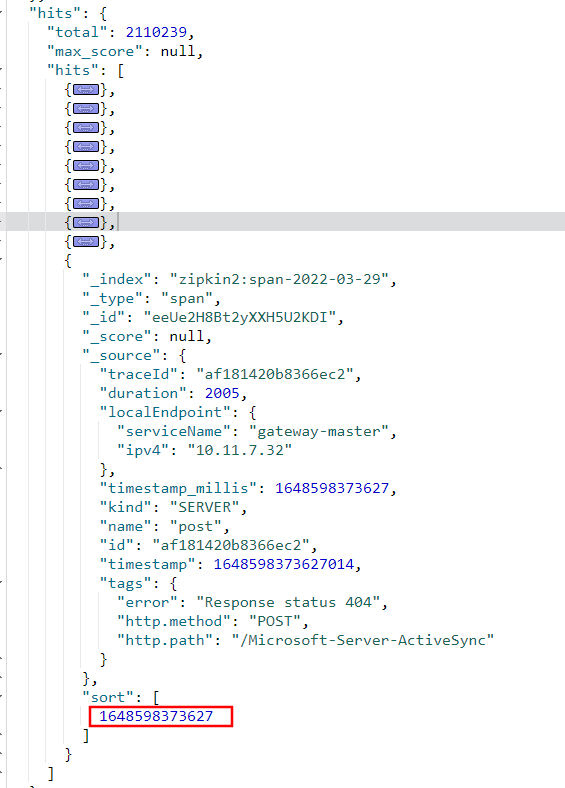
步骤2:之后查询要按顺序一页一页的查询
GET /zipkin2:span-2022-03-29/_search{"size": 10,"search_after": [1648598373627],#指定上次查询页中的最后一条结果的sort字段"sort": [{"timestamp_millis": {"order": "desc"}}]}
注意事项

若有收获,就点个赞吧
0 人点赞
