数据结构定义
m阶的定义
m是指树中结点可以拥有的最多孩子数量
1阶:任一结点最多拥有一个孩子结点
3阶:任一结点最多拥有三个孩子结点
m阶B-Tree的定义
- 根结点的孩子数量:[2,m]
- 非根结点的孩子数量:[
 ,m]
,m] - 叶子结点都同一级,且均为null(严老师)
- 结点的结构
- 关键字个数n:该结点的关键字数量
- 关键字:n个关键字
- 指针:n+1个子结点指针

关键字数据中已经记录了真实数据的指针或数据。同一个关键字出现后就不会再次出现
m阶B+Tree的定义
根结点的孩子数量:[2,m](同B-Tree)
- 非根结点的孩子数量:[
 ,m](同B-Tree)
,m](同B-Tree) - 叶子节点记录全部的关键字,且按照顺序依次连接
- 结点的结构
- 关键字个数n:该结点的关键字数量
- 关键字:n个关键字
- 指针:n个子结点指针
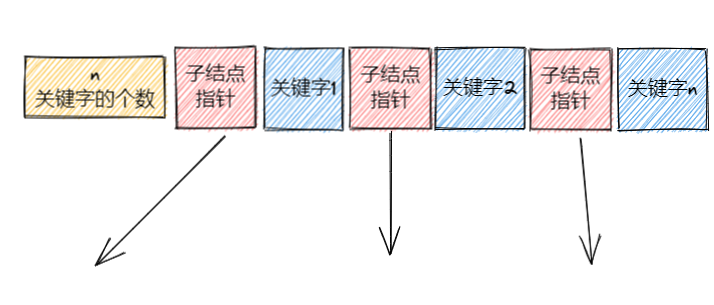
非叶子结点的关键字数据中只记录关键字,没有记录的指针或数据,只有叶子节点中有
为什么MySQL使用B+Tree
B-Tree
优点
查询单条记录,只要在结点中检索到关键字就可以立即返回,无需到叶子节点。可以将高频的数据放在靠近根结点的层级上,可以更快的查到。
缺点
范围查询时,B-Tree需要加载不同的层级去寻找数据
由于非叶子结点中也存储了关键字对应的数据,导致数据占用关键字的存放空间。使得每页的关键字会更少一点。降低检索速度。
B+Tree
优点
范围查询时,B+Tree只需要寻找叶子节点那层即可遍历出符合条件的所有数据
-
缺点
单条数据查询时,可能没有B-Tree快,因为均需要加载到叶子结点
小结
使用数据库查询的时候,较多的场景还是范围查询,B-Tree的范围查询效率实在太差。B+Tree的话虽然单条记录的查询速度略逊于B-Tree,但是也差不了太多。综合考虑下,还是使用B+Tree更好。
MySQL不同引擎的索引数据结构
MyISAM
- 不支持Hash
- 支持B+Tree
- InnoDB
- 不支持Hash
- 支持B+Tree
Memory
InnoDB的聚簇索引存储的就是数据,MyISAM的聚簇索引依旧要回表
- InnoDB的回表是拿着主键取聚簇索引查,MyISAM的回表都是拿着数据指针去查(更快)
- InnoDB必须有主键,没有则选择一个唯一非空的键或者使用隐藏整数列
Hash和B+Tree
- Hash查询单条记录很快,但是都要回表,范围查询比B-Tree还拉胯
- B+Tree查询单条记录性能差,但是不一定都要回表,范围查询完胜Hash和B-Tree

若有收获,就点个赞吧
0 人点赞
