1.使用场景
intervals这种查询属于全文检索查询中的一种,不同的是这种查询可以指定分词后的词项的出现顺序是否与查询的一致。词项间是否紧挨着。
比如:查询内容:my favorite。会分为my 和 favorite两个词项。于是你查询后只能查询到存在my和favorite两个单词,并且 my favorite是紧挨着的。像my most favorite、favorite my 等等。都是查询不到的。
个人认为:在正常做搜索时不会用到。
2.使用方式
- match
- prefix
- wildcard
- fuzzy
- all_of
- any_of
2.1match的用法
intervals中的match用法与 全文检索match不太一样,我总结的是:
①可以指定分词器,查询前也要分词
②词项必须全部匹配
③默认使用intervals的字段,但是也可以指定{"query": {"intervals": {"my_text": {"match": {"query": "查询内容","max_gaps": "分词后各个词项的间隔","ordered": "是否遵循先后顺序","analyzer": "standard","filter": "这个暂时不会","user_field": "可以指定其他字段"}}}}}
2.2prefix的用法
这个用法我试了一下,没太懂官方的解释,也没从使用中感受到可用价值。
①我只能输入一个单词可以查询
②这个单词即使不是查询字段的前缀,也被查询出来了。
所以这个用法没试出来。2.3wildcard的用法
这个wildcard感觉就是普通的通配符查询2.4fuzzy的用法
普通模糊查询的用法
2.5 all_of 和 any_of的用法
这两者+match是intervals的核心用法。all/any_of下面包含一个intervals列表。all_of是包含intervals列表中的所有条件才返回。any_of包含其一即可。下面我解释一下官方的查询例子。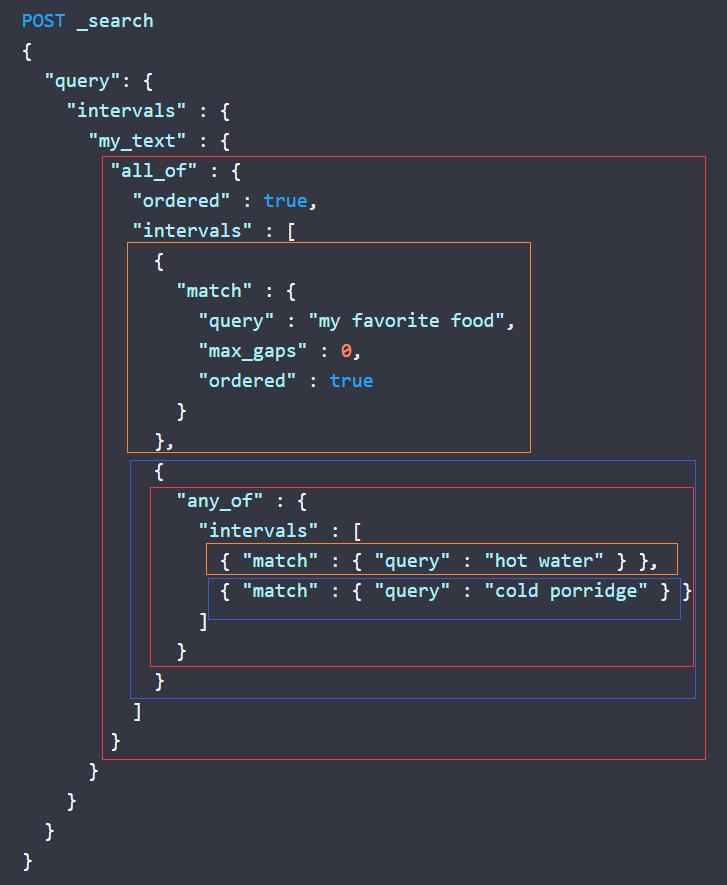
这个一层层的嵌套。其实就是说,分为(my favorite food)and ((hot water)or (cold porridge))
也就是说,my favorite food 必须在 ((hot water)or (cold porridge))之前。my favorite food 之后要么给我匹配 hot water ,要么是 cold porridge。
3.总结
intervals的用法通过写这篇文章+实际练习一把。大概明白了其中的意思。和我开篇写的一样。就是当你需要限制匹配词的配置的时候使用。但是我认为还不如用精确查询中的通配符(wildcard)查询。

若有收获,就点个赞吧
0 人点赞
