- 1.MySQL使用有哪些注意事项
- 2.一条SQL在MySQL中如何运行的?
- 3.不可重复读和幻读
- 4.聚簇和非聚簇索引
- 5.如何定位并优化慢SQL
- 6.InnoDB和MyISAM的区别
- 7.索引数据结构选择
- 8.锁分类
- 9.MySQL中如何存储emoji标签
- 10.自增ID和UUID的选择
- 11.SQL的生命周期
- 12.SQL的执行顺序
- 13.varchar能放多少内容
- 14.Innodb的事务日志
- 15.Innodb的事务实现原理?
- 16.MySQL的复制原理以及流程
- 17.mysql自增主键用完了怎么办?
- 18.count(1)、count(*) 与 count(列名) 的区别
- 19.什么是死锁?怎么解决?
- 20.如何选择合适的分布式主键方案呢?
- 21.MySQL中in 和exists的区别
- 22.数据库自增主键可能遇到什么问题
- 23.MVCC熟悉吗,它的底层原理?
- 24.MySQL的主从延迟,你怎么解决?
- 25.MySQL的binlog有几种录入格式
- 26.读写分离常见方案?
- 27.数据库范式
- 参考资料
1.MySQL使用有哪些注意事项
索引失效规则
- where子句中包含or查询,可能会导致索引失效
- where子句中like ‘%xxx’会导致索引失效
- where子句中索引列上使用函数、算术运算会导致索引失效
- where子句中索引列上使用(!=、<>、not in、is not null)可能会导致索引失效
- where字句中索引列类型和查询参数类型不统一时,会导致索引失效(整形除外)
- where字句中左右连接字段编码不统一时,会导致索引失效
- 优化器认为全表扫描更快的情况下,索引失效
小结:
- 失效的场景
- 不等于
- like’%’
- 计算后的索引列
- 类型不匹配
- 连接时连个索引字段编码不匹配
- 优化器自己的确定
- 失效的场景
不适合索引场景
- 数据量少的情况下不适合加索引
- 写多读少的场景不适合加索引
-
索引相关概念
覆盖索引
- 索引下推
- B+Tree
- 回表
-
2.一条SQL在MySQL中如何运行的?
MySQL的逻辑架构图
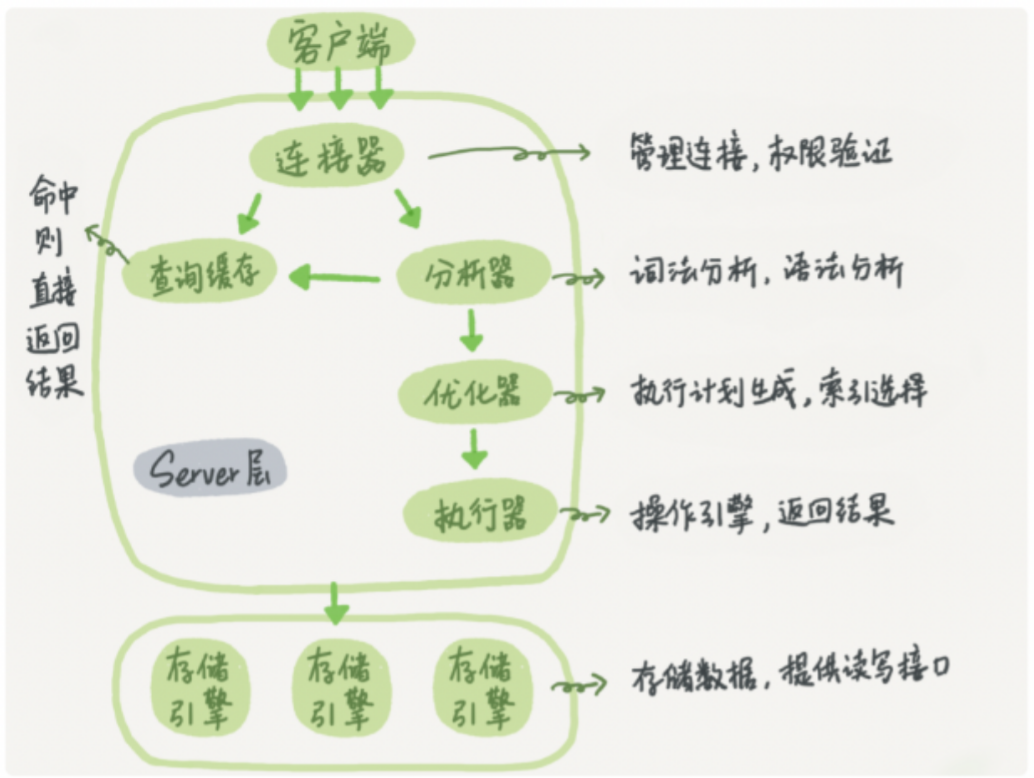
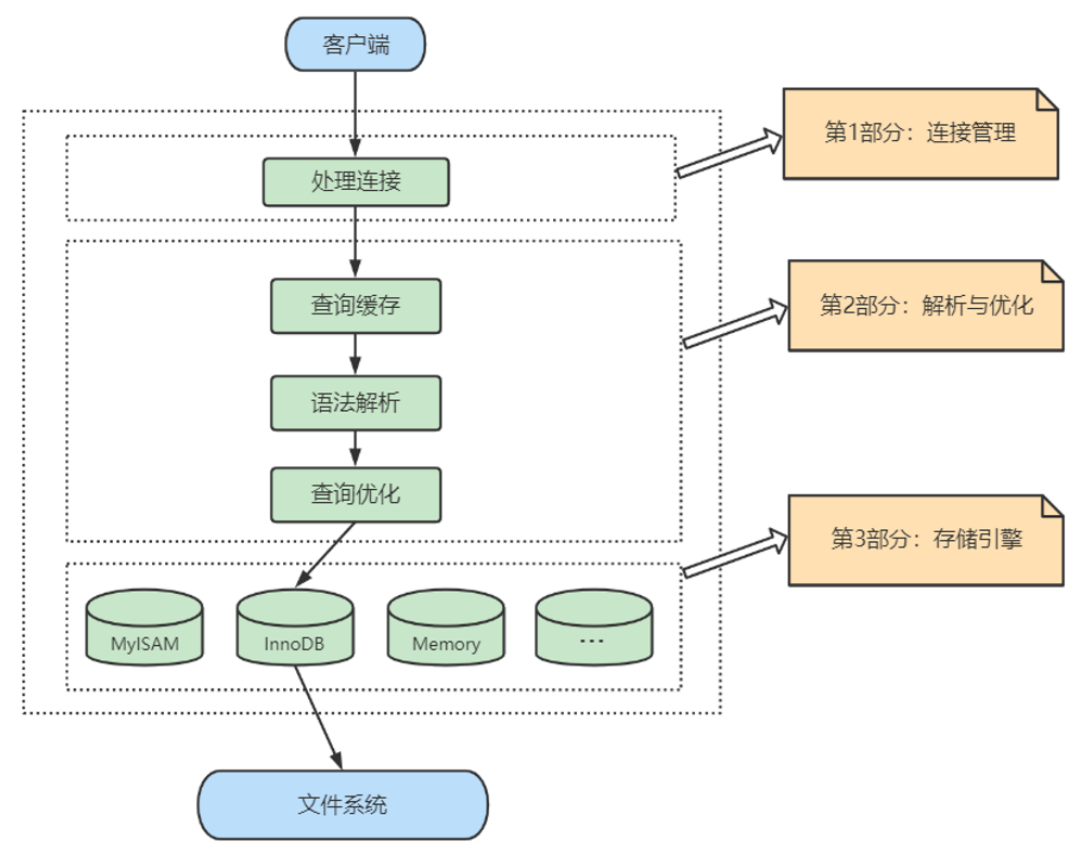
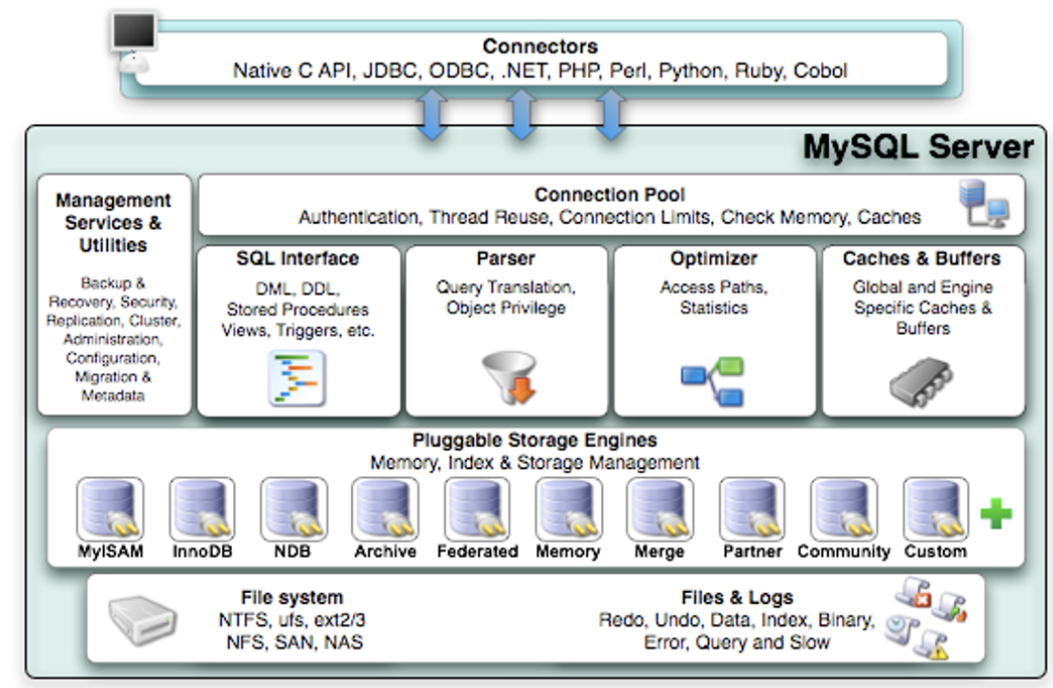
第一层:连接层:管理客户端连接,进行用户认证
- 第二层:服务层
- SQL Interface:接收用户SQL语句
- Parser 解析器:对SQL进行语法和语义上的分析
- Optimizer优化器:生成执行计划,确定索引
- Caches & Buffers:缓冲(SQL语句:结果)
- 执行器:操作引擎,返回结果
- 第三层:引擎层:负责文件系统交互,负责MySQL数据的存储和提取操作。先上提供读写接口,向下完成与文件系统交互
-
SQL如何运行的
MySQL对客户端进行认证和权限查询
- 连接层会校验用户是否有执行该SQL的权限,无则直接错误返回
- MySQL8.0前,先查缓存,有数据则直接返回
- 对SQL进行语法分析和词法分析
- 通过优化器生成执行计划和进行索引选择
-
3.不可重复读和幻读
不可重复读:针对的是同一条数据而言,同一事务中两次读取结果不一致
- 幻读:针对的是范围查询而言,同一个范围事务前后两次读取,数据条数不一致
思考: 照上面的规则来说的话,MySQL的MVCC机制在不可重复读的级别就解决了幻读的问题
4.聚簇和非聚簇索引
- 数量:
- 聚簇索引:仅可有一个
- 非聚簇索引:可以有多个
物理存储顺序:
定位:开启慢查询日志
- 查看是否开启:show variables like ‘slow_query_log’
- 设置开启:set global slow_query_log = on
- 设置慢查询阈值:set global long_query_time = 5
- 定位日志位置:show variables like ‘%slow_query_log%’
- 通过文件查看日志内容:datadir/XXX-slow.log
- SQL本身优化
- 通过指定所需字段代替select *
- 修改导致索引失效的写法
- 避免使用子查询,使用连接查询代替
- 索引优化
- 最佳左前缀
- explain
- 索引失效规则
- 表结构优化
- 适当的冗余,反范式化
- 引入缓存中间件
- 数据库优化
- 单数据库参数优化:join_buffer_size、sort_buffer_size
- 分库分表
6.InnoDB和MyISAM的区别
| 特性 | InnoDB | MyISAM | | —- | —- | —- | | count(*) | 全表扫描 | 额外变量存储、O(1)查询速度 | | 事务 | 支持 | 不支持 | | 外键 | 支持 | 不支持 | | 索引底层实现 | B+Tree | B+Tree | | 物理存储属性 | 按照主键顺序 | 按照插入顺序 | | 锁粒度 | 行级 | 表级 | | 必须有主键? | 必须 | 不必须 | | 文件实际存储格式 |
- MySQL5.7
- 独立表空间模式
- 表名.frm:每个表结构
- 表名.idb:每个表的索引和数据
- 系统表空间模式
- 表名.frm:每个表结构
- ibdata1:索引和数据
- MySQL8.0
- 表名.idb:包含表结构、索引和数据
|
- 表结构
- 5.7:表名.frm
- 8.0:表名.sdi
- 索引:表名.MYI
- 数据:表名.MYD
|
7.索引数据结构选择
为什么不是二叉树
-
为什么不是平衡二叉树
平衡二叉树不会出现极端的情况,但是考虑到我们的查询是建立的磁盘IO上的。平衡二叉树对于基于内存的查询效果很好,但是基于磁盘IO,二叉树每个节点的载入都是一次磁盘IO操作。每次磁盘IO只能筛选粒度太粗啦。数量大的情况下树的深度太深啦!
为什么不是B-Tree
B-Tree的每个节点上不仅存储索引值,而且存储数据,这样相比较B+Tree只存储索引值而言,B+Tree的一个数据也可以存放下更多的索引值。导致树的高度就越低,磁盘IO次数就越少
B-Tree对于单条记录的查询可能优于B+Tree,但是范围查询时,还需要在树的上下层之间回溯。B+Tree所有数据存放在叶子节点,并且使用链表指针顺序链接。范围查询时极其容易
为什么不用Hash
hash单条记录ok,效率极高,范围查询怎么办?所以还是B+Tree
8.锁分类
读写类型角度
- 读锁
- 写锁
- 加锁态度
- 悲观锁
- 乐观锁
- 加锁方式
- 显式加锁:在SQL中显式地加锁
- 隐式加锁:MySQL依据隔离级别进行的加锁
- 锁粒度角度
- 表级锁
- 手动给表上锁
- 表级意向锁:执行行级别的加锁操作后,对于后面的数据表结构修改操作的一种锁控制
- 自增锁:生成记录的自增id时,表级加锁(3种加锁模式)
- MDL(元数据锁):有SQL对表结构做变更时
- 页级锁
- 行级锁
- 记录锁:针对某条具体的记录加锁,如:id=8加锁
- 间隙锁:锁住某段不存在的记录,如:id在(3,8)区间内的
- 临键锁:锁住某个条记录以及之前的不存在的记录,如:id在(3,8]区间的内的记录
- 插入意向锁:某个事务插入某条记录前,需要等待Gap锁的那个事务,在等待的时候上插入意向锁,插入意向锁实际就是一个特殊的Gap锁
- 表级锁
显式or隐式
自增ID值大小顺序即插入顺序,插入效率高,占有空间少
-
11.SQL的生命周期
客户端连接MySQL服务器
- 数据库进程拿到SQL
- 对SQL进行语法和词法分析
- 优化器生成执行计划
- 通过存储引擎查询数据,读取到内存中进行处理
- 返回处理结果到客户端
-
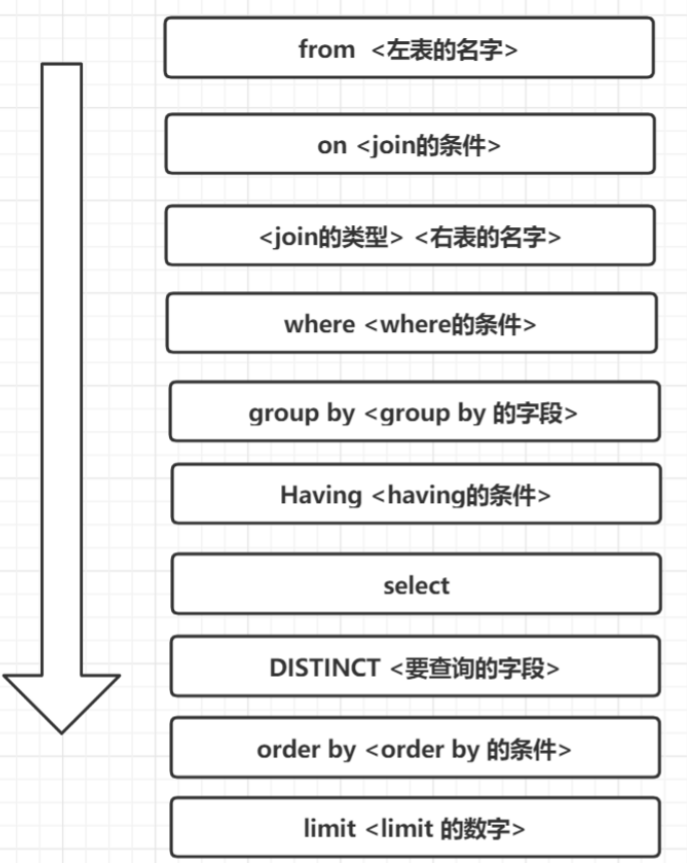
12.SQL的执行顺序
13.varchar能放多少内容
varchar最多可定义为varchar(65532)
- varchar(n)中的n指定的是字节数
varchar(n)具体可以放多少内容,要根据编码,如utf-8(3字节)。n/3
14.Innodb的事务日志
事务相关日志:redo日志和undo日志
- redo日志:提供再写入操作,恢复提交事务修改的页操作,用来保证事务的持久性。
- undo日志:在更新操作前要记录undo log,保存当前数据镜像。回滚行记录到某个特定版本,用来保证事务的原子性、一致性。
日志存放方式
持久化:只要操作记录到redo log中,系统崩溃恢复后可以通过redo log做数据恢复
- 原子性:undo log记录历史版本信息,可以对事务进行回滚
- 隔离性:锁机制和MVCC机制(undo log)
一致性:回滚(事务之间的原子性)、事务之间的隔离性,保证了一致性
16.MySQL的复制原理以及流程
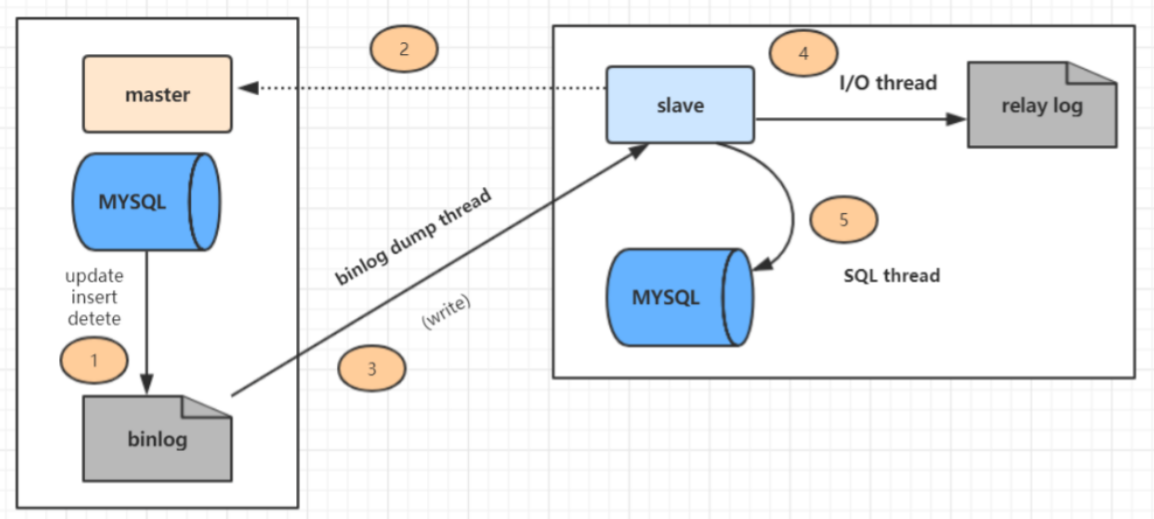
主库发生数据更新操作被记录到binlog中
- 从库连接主库,主库开启binlog dump 线程将binlog发送到从库
- 从库开启IO线程,将binlog写入relaylog中
从库开启SQL线程,读取relaylog中的内容并执行,完成数据复制
17.mysql自增主键用完了怎么办?
18.count(1)、count(*) 与 count(列名) 的区别
count(1)/count(*):不忽略null值
-
19.什么是死锁?怎么解决?
是什么:死锁是2个或多个事务在同一资源相互占用,并请求锁定对方的资源
- 四个必要条件:
- 互斥条件:资源的获取时互斥
- 请求和保持条件:线程因请求资源而导致阻塞时,对已获资源不释放
- 环路等待条件:出现等待环路
- 不剥夺条件:线程已获得的资源,在未使用完前无法被剥夺
解决方式
UUID
- Snowflake算法
- Redis生成ID
- ZooKeeper生成ID
-
21.MySQL中in 和exists的区别
前提:A是主表,B是放在in或exists中查询的表
B表的数据量小:使用in
-
22.数据库自增主键可能遇到什么问题
分库分表后,主键重复问题
- 自增主键产生锁,引发并发问题
-
23.MVCC熟悉吗,它的底层原理?
记录隐藏字段
- trx_id:每次记录当前记录的是哪个事务修改的
- roll_pointer:指向undo log日志中该记录旧版本的数据链
- undo log:该条记录所有的历史版本
- ReadView
- creator_trx_id:创建这个ReadView的事务id(纯select语句事务id=0)
- trx_ids:创建ReadView时系统中活跃的事务id
- up_limit_id:活跃事务中最小的事务id
- low_limit_id:下一个事务的id(最大事务id)
运行规则
产生原因:多个客户端并发对主库进行写操作,主库只有一个binlog dump线程在工作,当某个SQL执行时间过长或锁表,则导致SQL大量堆积。此时从库和主库就有不一致的状态产生
解决方式
statement:记录每条更新操作的SQL,函数无法记录,会出现语义分歧
- row:记录每一行的变动,日志量太大
mixed:普通操作记录statement模式,否则用row模式
26.读写分离常见方案?
应用程序自己编写逻辑,实现读写分离
-
27.数据库范式
1NF:所有字段都是不可再分的
- 2NF:所有的非主属性都完全函数依赖于候选键
- 3NF:所有的非主属性都不传递函数依赖于候选键
- BCNF:只有有X->Y,那么X必是候选键。(任何属性都完全函数依赖于候选键)
参考资料

若有收获,就点个赞吧
0 人点赞
