消息发送
原理
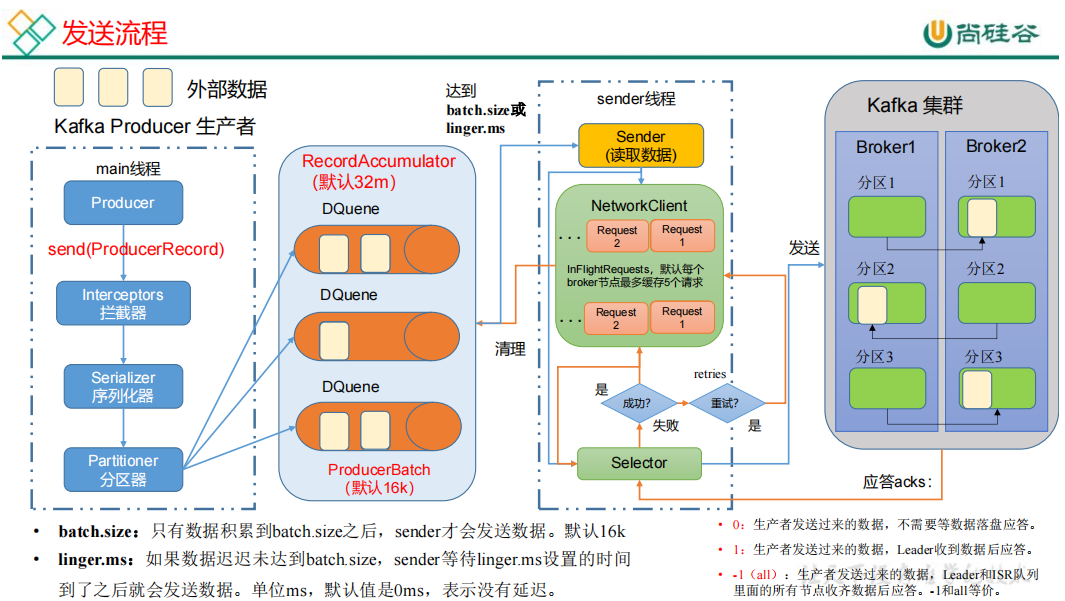
- 在
main()方法中调用send(),消息会经过拦截器、序列化器、分区器,最后发送到RecordAccumulator - 程序会启动一个额外的
sender线程,当达到某种条件时,sender线程从RecordAccumulator中拉取数据,发送到Broker上sender线程何时拉取RecordAccumulator数据batch.size:默认16k,当数据量达到batch.size时,拉取linger.ms:默认0ms,当数据在RecordAccumulator中的时间大于等于linger.ms时,拉取ack应答级别
- 0:生产者发送过来的数据,不需要数据落盘就响应ack
- 1:Leader副本落盘后就可以返回ack
- -1(all):所有副本都落盘后可以返回ack
重要参数
| bootstrap.servers | 指定broker地址,多个地址,可以用”,”分隔 | | —- | —- | | key.serializer 和 value.serializer | key、value的序列化方式,指定序列化器全类名 | | buffer.memory |RecordAccumulator的大小 | | batch.size | 缓存一批的最大容量 | | linger.ms | 每次储蓄多长时间就发一批 | | acks | 应答模式 | | max.in.flight.requests.per.connection | 允许最多没有返回 ack 的次数 | | retries | 重试次数,默认Integer.MAX_VALUE | | retry.backoff.ms | 两次重试间隔 | | enable.idempotence | 幂等? | | compression.type | 压缩方式 |
发送方式
普通异步发送
带回调的异步发送
同步发送
send()方法调用后,立刻get()
消息分区
好处
- 提高并行度
-
分区策略
默认分区策略
- 参数中指明分区号
- 参数中未指明分区号,但指明key:key的hash值对分区总数取余
- 参数中啥都没指定:黏性分区,随机1个分区,只要批次没被发送一直此分区,发送后从其他分区进行随机
- 自定义分区策略
生产者如何提高吞吐量
主要是从以下参数出发:
- batch.size
- linger.ms
- buffer.memory
- compression.type
数据发送可靠性
数据如何确保发送到了Broker且不会丢失,在消息发送的阶段,可以通过设置acks应答级别来保证。
0:这种方式十分容易丢消息
1:当一个Leader挂了后,消息就丢了
-1:需要保证isr中的元素大于等于2,即至少2个副本
数据去重
数据传递语义
- 至多一次:acks=0就是这样
- 至少一次:acks=-1,就是这样的语义,确保消息发送到leader和follow
- 精确一次:至少一次+幂等
幂等性
kafka0.11后引入,通过enable.idempotence设置。
判断幂等方式:PID+Partition+Sequence事务消息
略消息有序
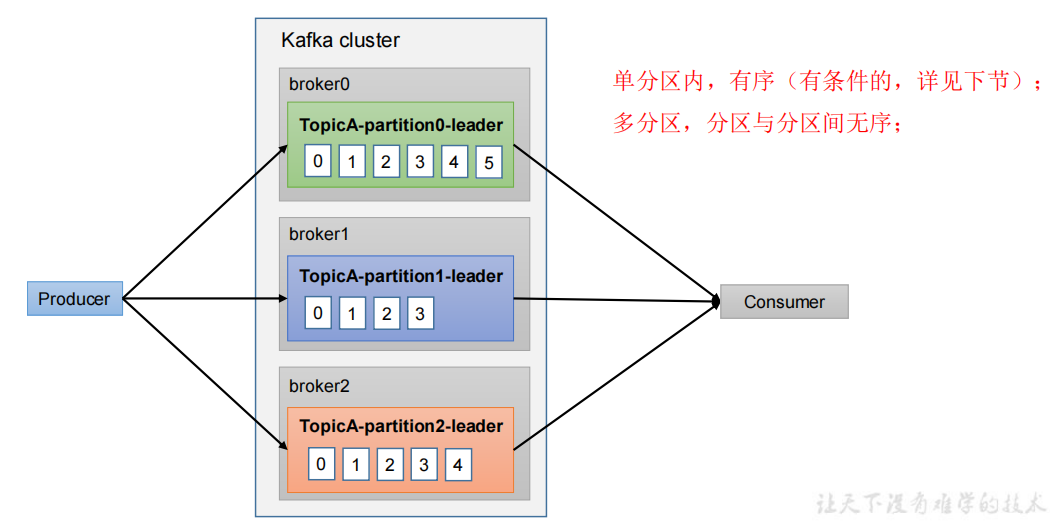
- 单个分区内有序
- 分区间无序
单分区保证发送顺序和消费顺序一致
在单分区的情况下,如何保证发送顺序就是消费顺序呢?
- 问题
- 消息A,消息B,消息C依次发送
- 消息C后发送但是比消息B先到且先落入分区
- 此时消费顺序就是 A,C,B
- 原因
max.in.flight.requests.per.connection允许最多n个未返回ack的请求同时存在导致的问题
- 解决
- 情况1:未开启幂等
max.in.flight.requests.per.connection参数设置为1
- 情况2:开启幂等
max.in.flight.requests.per.connection设置小于等于5,因为broker会缓存近5个请求并重排。
- 情况1:未开启幂等
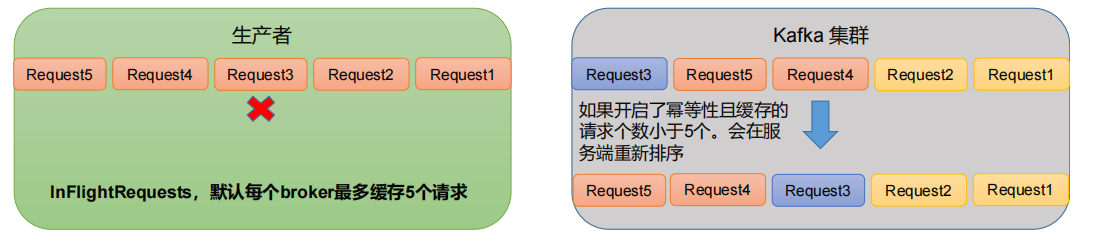
疑问:其实情况2,万一Request3后Request6也发送了,且先ack,那不是还是乱序?

若有收获,就点个赞吧
0 人点赞
