select *from t1where t1.id in(select t2.id from t2);

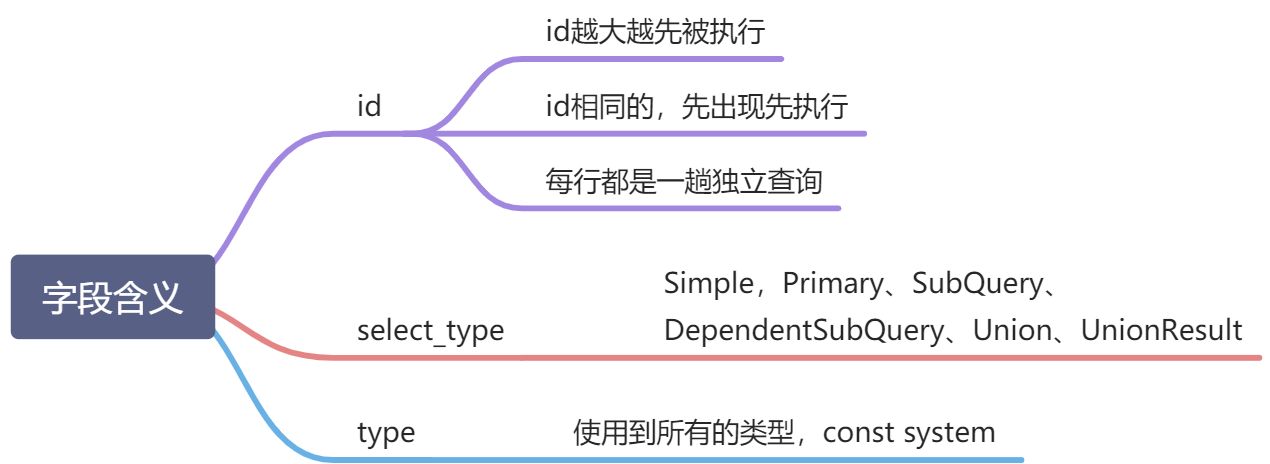
1.首先,explain后,有几行就说明要查询几趟。
比如上面的sql会先查询t2表的所有数据select t2.id from t2 ,查询一趟,
之后才是 查询一趟 t1表 (select * from t1 where t1.id in (select t2.id from t2 );)
2.同一id,先出现先执行, 比如 t2先被查询,之后查询 t1。
3.id值越大,越先被查询
select_type
select *from t1where t1.id not in (select t2.idfrom t2)

比如 t1表是主查询 ,其 select_type 为 primary
子查询
select t2.id from t2 where t2.id=(select t3.id from t3 where t3.id =1 )

子查询: subquery,就是 不依赖主查询的。。。。
依赖查询
select * from t1unionselect * from t2unionselect * from t3;

建立索引的原则。
①全值匹配我最爱———索引尽可能的覆盖 where 子句中的内容
②最佳左前缀 ———— 每个字段是层级关系,中间一个断了,其他的索引都无效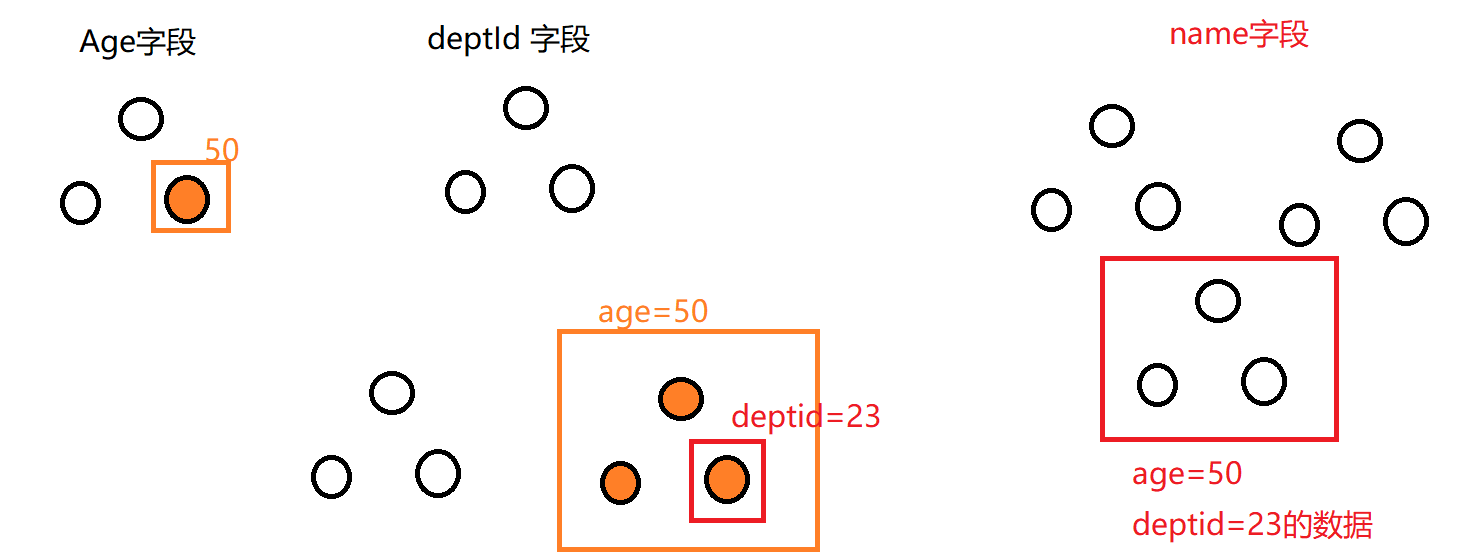
组合索引 (age,deptid,name)
中间如果deptId断了,name索引就使用不上了。
如果额外再创建一个 name索引, 就会从组合索引中选择一个最优的。
③在where中使用函数,类型不一致的where条件,会导致索引的失效
④范围查询的字段,建立索引时,放在最后面,
一旦范围查询的字段在前面,其他索引会立即失效。
⑤ != 和<> 会造成全表扫描
⑥ is not null 不可以使用索引, is null 可以使用索引
⑦’%’ 开头会造成全表扫描

若有收获,就点个赞吧
0 人点赞
