ZK存储的Kafka信息
Kafka的所有消息都会存储在zk中的/kafka节点中。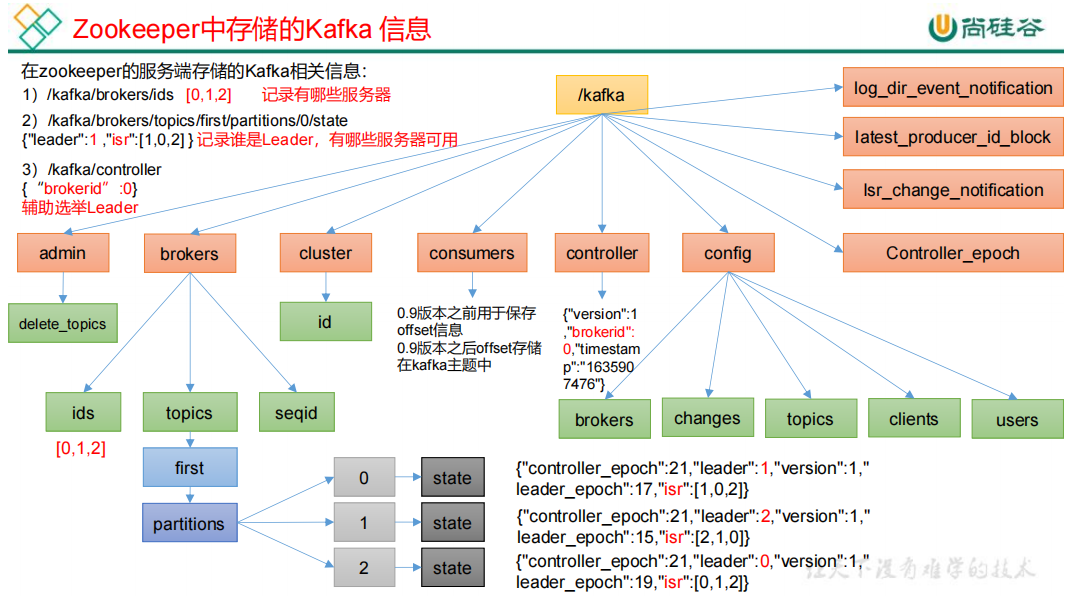
- /kafka/brokers/ids:存储所有注册在zk上的Kafka的broker.id
- /kafka/brokers/topics/主题名/partitions/0/state:记录的是某个主题的0号分区的信息,leader是谁,isr(in-sync replica set)有哪些
- /kafka/controller:存放的是辅助选举分区的broker.id
/kafka/consumers:0.9前保存消费的offset
Broker工作流程
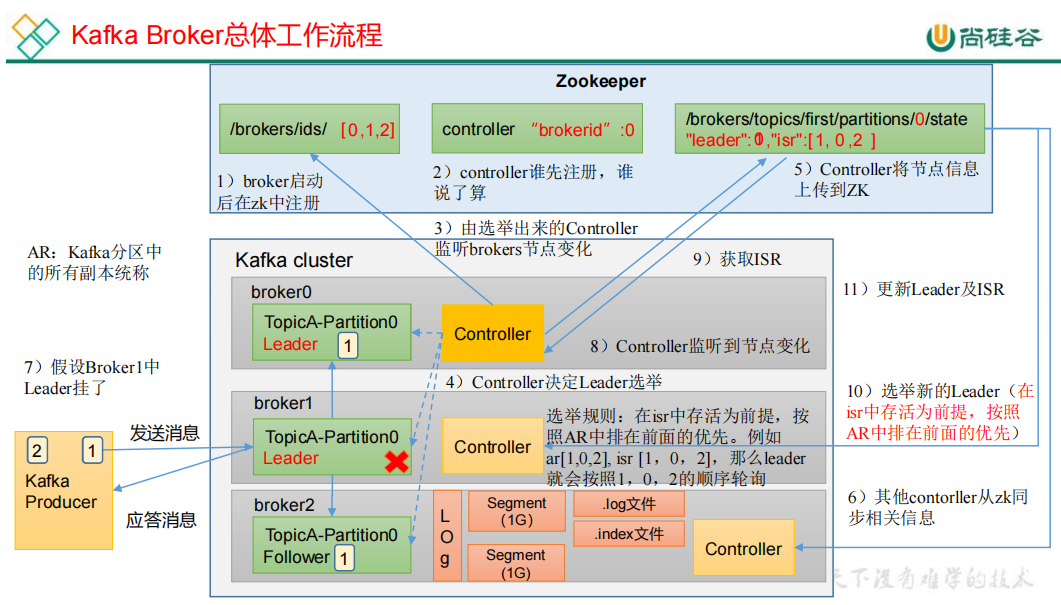
broker启动后向zk中的/kafka/ids中注册:【0,1,2】
- 各个broker注册成为controller,/kafka/controller。谁先注册谁就赢
- controller需要监听broker节点变化
- contorller决定分区副本leader的选举
- controller将分区副本信息上传
- zk将第5步中的信息同步给其他的controller
- 假如某个分区leader副本所在的broker挂了,
- controller就可以监听到副本leader挂了
- controller从zk获取分区信息,重新选举一个leader,并更新到zk
重点内容
- Controller:每个Broker中都有且仅有一个Controller,但只有一个说话好使
- Controller:负责监听各个分区的leader、follower副本,同步给zk
- Controller:负责选举新的分区的leader
Broker的重点参数
| replica.lag.time.max.ms | ISR中副本长时间未向Leader通信,则踢除ISR |
|---|---|
| auto.leader.rebalance.enable | 自动leader分区平衡(leader负责接收请求,所以不能所有leader往一个Broker中塞) |
| leader.imbalance.per.broker.percentage | 每个broker允许leader不平衡的比率,超过后看上个参数是否开启 |
| leader.imbalance.check.interval.seconds | 检查leader是否均衡的间隔时间 |
| log.segment.bytes | log被分成segment,设置每个segment的大小 |
| log.index.interval.bytes | log中写入多少数据后,插入一条索引到.index文件 |
Broker的服役和退役
新节点服役
- 加入新broker:这步和其他broker一样配置后启动即可
平衡分区副本:新节点需要分担老的主体的分区副本信息
作用:提高数据的可靠性
- AR:All Replica
- ISR:in-sync replica set(同步的副本)
- OSR:被踢除的replica
- AR = ISR + OSR
- 角色:副本有一个Leader和多个Follower
副本Leader选举流程
Leader的选举是通过Controller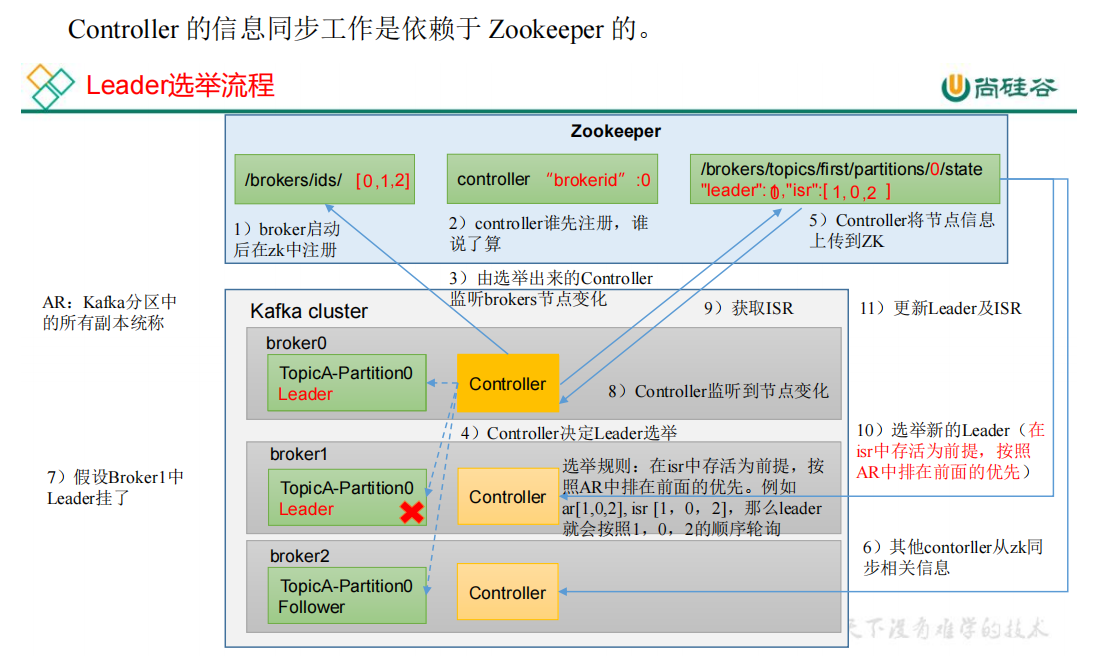
查看主体分区情况
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe

规则:按照AR中的顺序,且在ISR中存活
故障处理细节
- HW(High Watermark):所有副本中最小的那个LEO
- LEO(Log End Offset):每个副本最后一个offset

Leader发生故障后,选举出来的新Leader 其余的Follower会对齐当前新Leader的数据 所以Kafka保证数据一致性,但是不保证数据不丢
副本分配策略
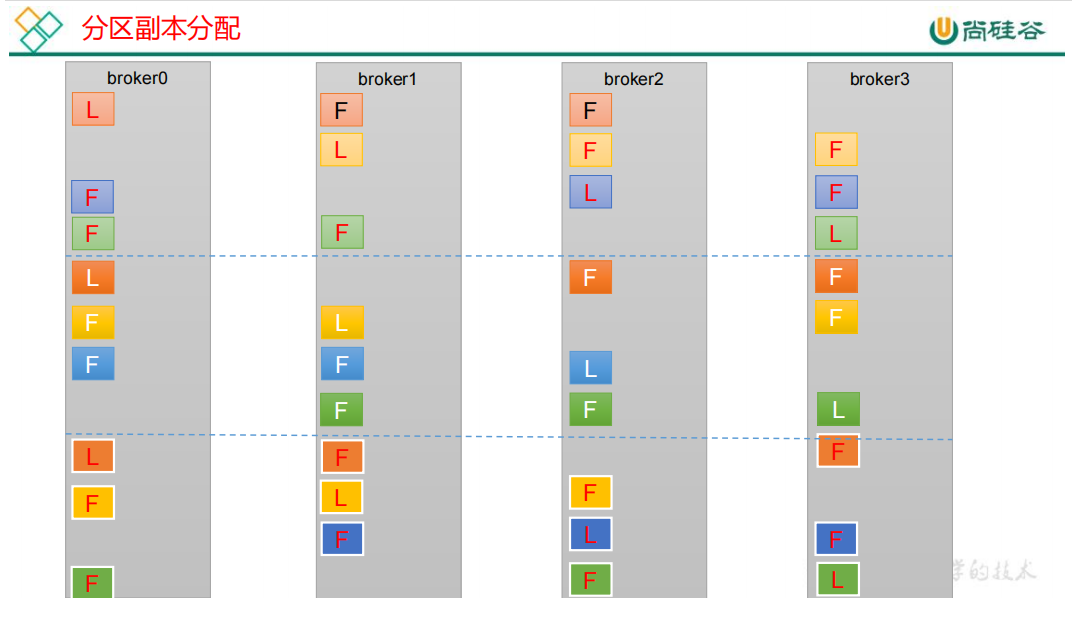
16个分区,每个分区3副本
- 4个、4个一分
- 第一组:0~3,Leader和Follower间隔0个Broker开始分配
- 0分区:Leader在broker0
- 1分区:leader在broker1
- 2分区:leader在broker2
- 3分区:leader在broker3
- 第二组:4~7,Leader和Follower间隔1个Broker开始分配
- 第三组:8~11,Leader和Follower间隔2个Broker开始分配
手动调整分区
执行脚本,指定json文件Leader分区的平衡

相关参数
增加一个副本
现在的副本不够用了,想再填一个
手动写json执行脚本
文件存储
消息数据存放在哪?如何存放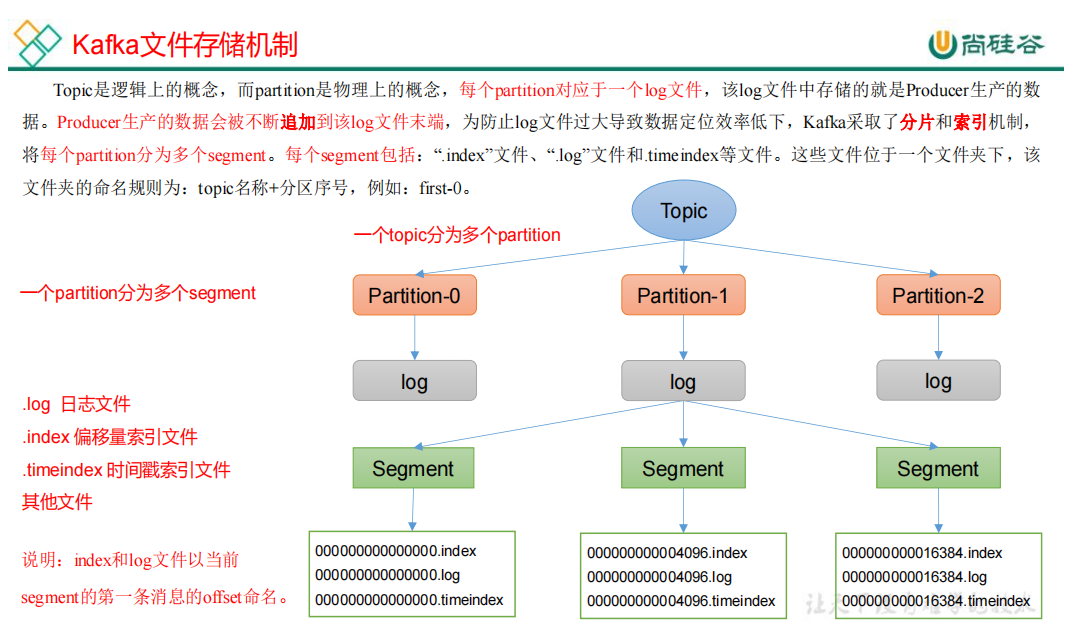
- Topic是个逻辑上的概念
- 每个Topic会生成多个分区,每个分区对应一个目录命名:${Topic}-分区序号
- 每个分区中有多个Segment
- 每个Segment包含了.index,.log,*.timeindex文件
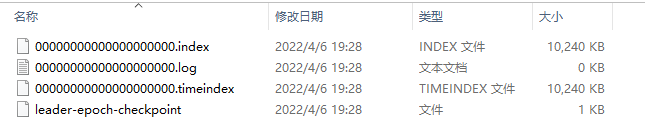
如何查看三个文件内容
kafka-run-class.sh kafka.tools.DumpLogSegments--files ./00000000000000000000.index
文件命名规则
- .index和.log和*.timestamp是一组文件,所以它们是成组出现
- 有000001.index,则必有000001.log和000001.timeindex
-
通过index如何定位数据
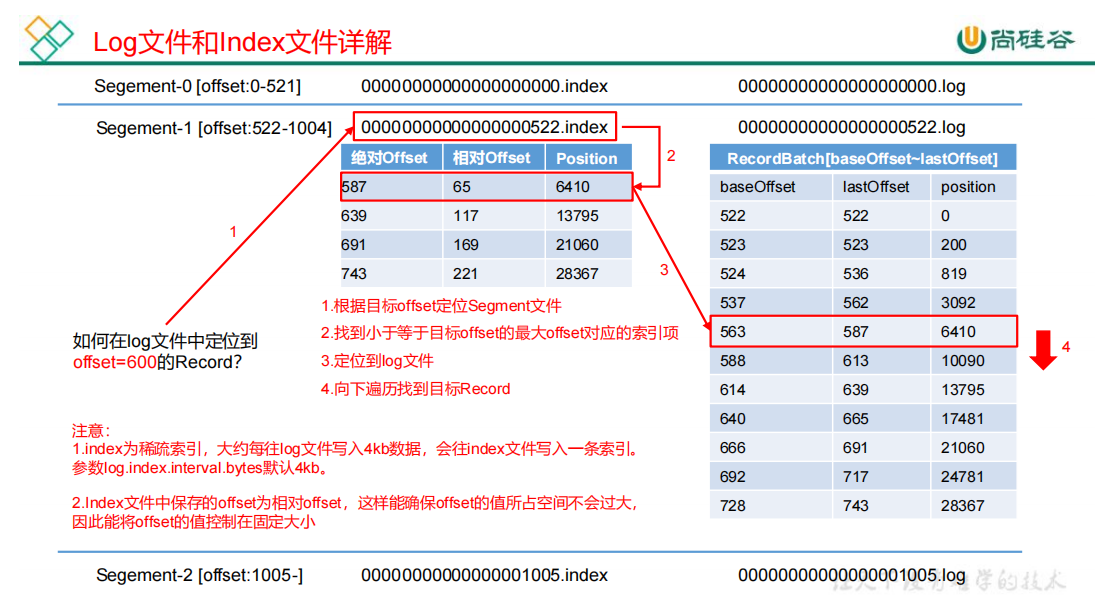
根据offset=600在文件名确定是哪个index,这里确定是00..0522.index
- index文件记录相对offset,相对于522的offset,判断后发现 (65,6410)合适,于是去522.log中找
- log中记录定位到position后,最多找4k数据,即可找到600
index是稀疏索引,log记录4k数据,index新增一条

文件清理策略
- 配置清理策略

- 清理方式
- 删除
- 基于时间:默认方式,以文件最大时间戳,确定是否可以删除log文件
- 删除
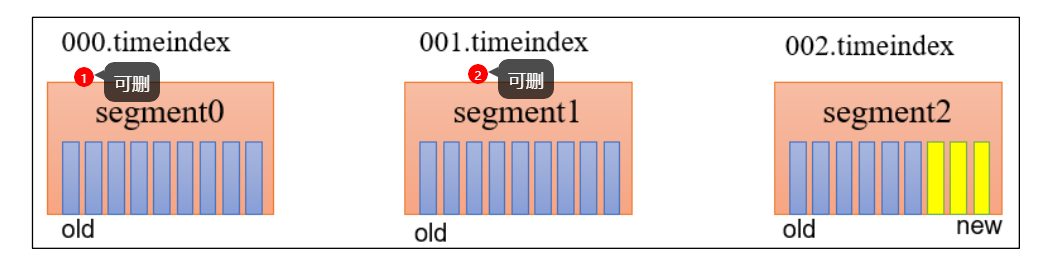
- 基于文件大小:默认关闭,超过日志总大小,删除最早的那个segment
- 分布式,分区提高并行度
- 读数据采取稀疏索引,可以快速定位数据
- 顺序写
- 零拷贝


若有收获,就点个赞吧
0 人点赞
