卡诺模型(KANO模型)是对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。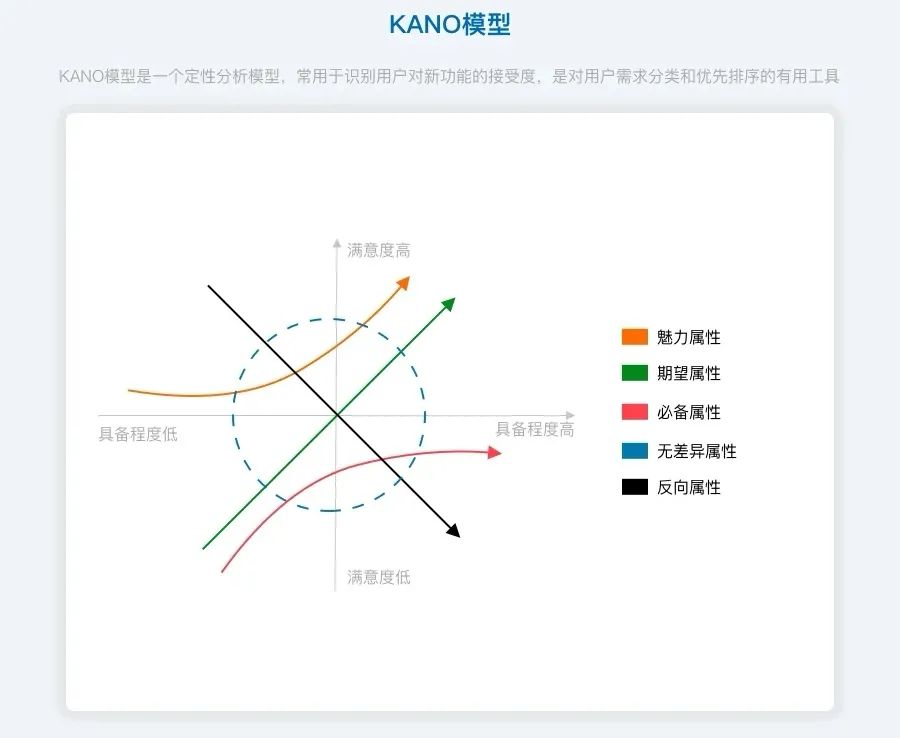
在卡诺模型中,将产品和服务的质量特性分为四种类型:
⑴必备属性;⑵期望属性;⑶魅力属性;⑷无差异属性。
kano模型是对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。
魅力属性—— Attractive
Quality/Excitement:用户意想不到的,如果不提供此需求,用户满意度不会降低,但当提供此需求,用户满意度会有很大提升;
期望属性——One- dimensional Quality
Performance:当提供此需求,用户满意度会提升,当不提供此需求,用户满意度会降低;
必备属性——Must -be- Quality/Basic:
当优化此需求,用户满意度不会提升,当不提供此需求,用户满意度会大幅降低;
无差异属性—— Indifferent Quality:
无论提供或不提供此需求,用户满意度都不会有改变,用户根本不在意;
反向属性—— Reverse Quality:
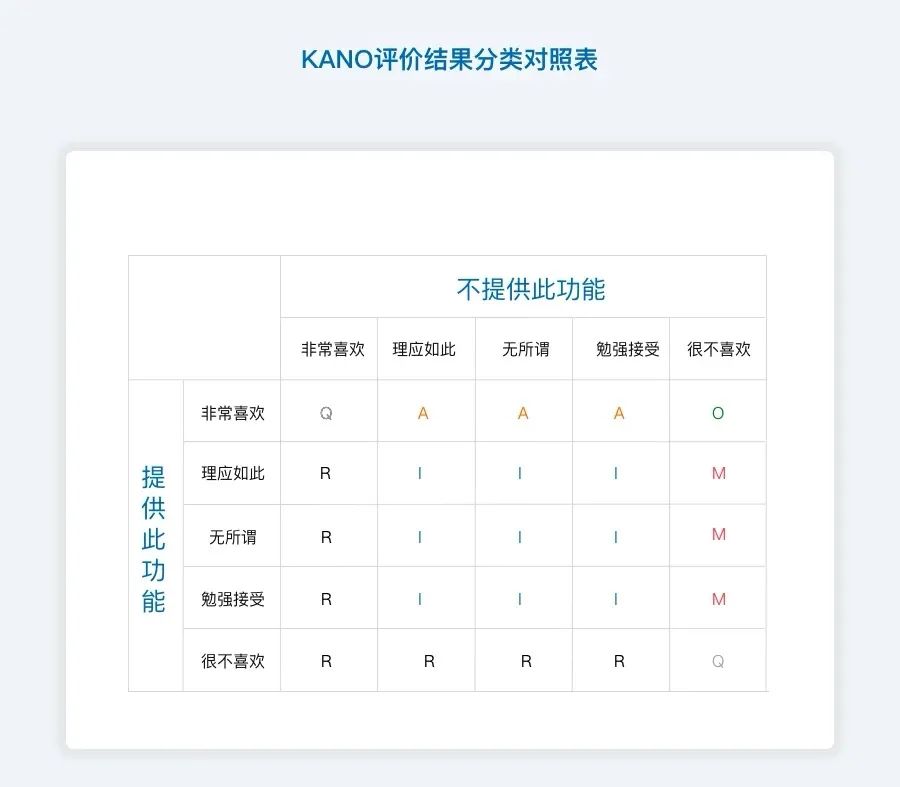
KANO问卷:
对每个质量特性都由正向和负向两个问题构成,分别测量用户在面对存在或不存在某项质量特性时的反应。
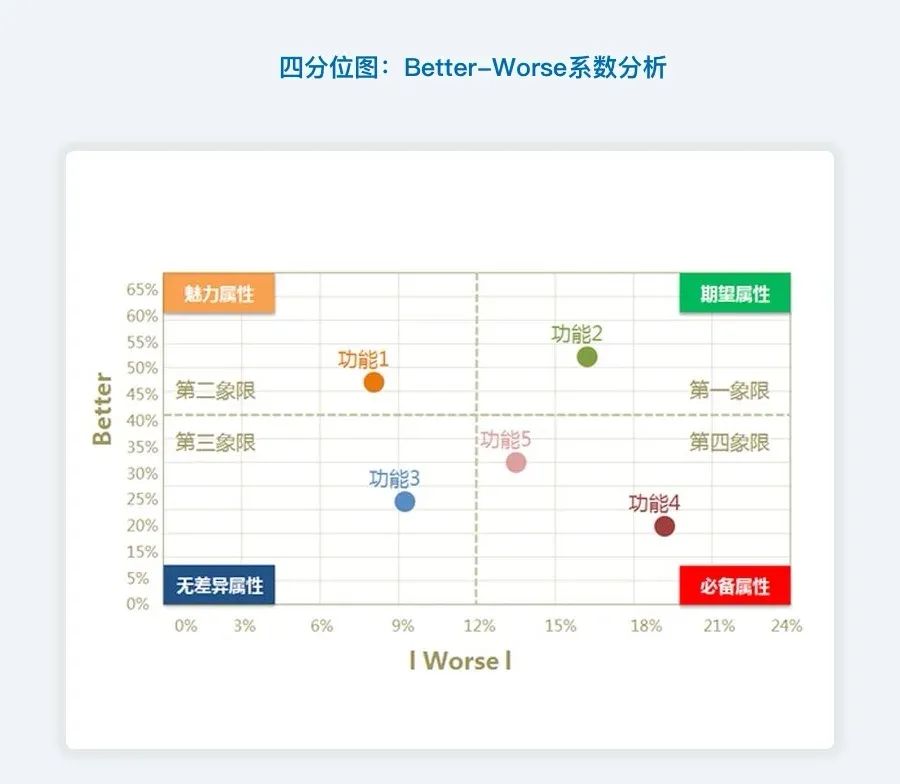
四分位图 better worse系数分析:
根据 better-worse-系数值,将散点图划分为四个象限。
第一象限表示:
better系数值高, worse系数绝对值也很高的情况。落入这一象限的属性,称之为是期望属性,即表示产品提供此功能,用户满意度会提升。
当不提供此功能,用户满意度就会降低,这是质量的竞争性属性,应尽力去满足用户的期望型需求。
当不提供此功能,用户满意度就会降低,这是质量的竞争性属性,应尽力去满足用户的期望型需求。提供用户喜爱的额外服务或产品功能,使其产品和服务优于竞争对手并有所不同,引导用户加强对本产品的良好印象;
第二象限表示:
better系数值高, worse系数绝对值低的情况。落入这一象限的属性,称之为是魅力属性,即表示不提供此功能,用户满意度不会降低,但当提供此功能,用户满意度和忠诚度会有很大提升;
第三象限表示:
better系数值低, worse系数绝对值也低的情况。落入这一象限的属性,称之为是无差异属性,即无论提供或不提供这些功能,用户满意度都不会有改变。
第四象限表示:
better系数值低, worse系数绝对值高的情况。落入这一象限的属性,称之为是必备属性,即表示当产品提供此功能,用户满意度不会提升。
当不提供此功能,用户满意度会大幅降低;说明落入此象限的功能是最基本的功能,这些需求是用户认为我们有义务做到的事情。
卡诺模型实操:
由于KANO模型问卷均需要了解以下两个方面:
用户对于产品/服务具备某功能时的评价(态度)和产品/服务不具备某功能时的评价(态度),需要分别正向和反向地询问用户。
需要注意:
① KANO问卷:
问卷中与每个功能点相关的题目都有正反两个问题,正反问题之间的区别需注意强调,防止用户看错题意;
② 在实际题目设置上:
当功能点个数比较多(大于5个时)或功能点的差异不大时,有相似之处时,建议对用户进行分组,每个用户最多回答5个功能点,且尽量是区分度大的功能点。
③ 在题型上:
建议优先选择单选题,避免使用阵列题,因为阵列题下,用户更容易乱答或者回答得没有区分度,导致最终各个功能点没有区分度,如都属于期望功能。
④ 功能的解释:
⑤ 选项说明:
由于用户对“我很喜欢”“理应如此”“无所谓”“勉强接受”“我很不喜欢”的理解不尽相同,因此需要在问卷填写前给出统一解释说明,让用户有一个相对一致的标准,方便填答。
- 我很喜欢:让你感到满意、开心、惊喜。
- 它理应如此:你觉得是应该的、必备的功能/服务。
- 无所谓:你不会特别在意,但还可以接受。
- 勉强接受:你不喜欢,但是可以接受。
- 我很不喜欢:让你感到不满意。
⑥ 增加效标以用于验证KANO结果或分人群分析:
用户使用功能的频率(后台数据、问卷询问)、用户最喜欢哪个功能(如果各个功能点区分度小时,如都属于期望属性,可从喜爱度上再进行二次划分)、用户会因为哪个功能而选择使用该产品。数据分析
数据清洗→KANO二维属性归属分析→Better-Worse系数计算。可以直接在Excel或SPSS中进行分析。
此外,还可以结合产品的一些数据支持进行结合分析,如用户画像,UV,转化率等。
数据解读
KANO模型是对功能/服务的优先级进行探索,具体情况还需要和业务方进行讨论。
将Kano模型结果和业务实际情况结合讨论确定可行的产品功能开发/优化的优先级顺序,以将调研结果落地实施。

若有收获,就点个赞吧
0 人点赞
