像这样的[ ] 里面的内容是选填的,执行sql时,不一定要写[ ] 里面的东西,如果写了,千万不要把[ ]也写上,执行sql语句里面选填内容不用加上[ ]
mysql语法的注释
#这是单行注释-- 这也是单行注释,不过需要在--后面打上一个空格/*这是一个多行注释*/
数据库操作
选择数据库
use dataname #在操作数据库之前,先要选择到这个数据库
查询数据库
select database(),now(),user(),version() #查询当前数据库,时间,用户名,数据库版本show databases [like '%a%'] #查询已有的数据库,like语句表示模糊匹配数据库名
创建数据库
create database [if not exists] dataname #数据库名dataname,选填的内容是如果没存在这个数据库就创建,加上这句,创造已经存在的数据库不报错[character set utf8] #设置字符集[collate utf8_general_ci] #设置排序规则#字符集和排序规则可以不写,字符集和排序规则写什么,在可视化操作页面用鼠标点击创建数据库,那里面可以选择
删除数据库
drop database dataname #删除dataname数据库,删除结构的那种
表操作
创建表
#这是创建数据表的基础的语法create table table_name (列名 列类型)-- 这是创建数据表的较为全面的语法#创建性别表create table sex(s_id int [auto_increment] [primary key] [not null],#列名,类型,自增,主键,非空s_name varchar(2))#创建学生表create table [if not exists] students(std_id int [auto_increment] [not null],std_name varchar(100) [not null],std_sexid int(2) [not null],std_birthday date,[[constraint pk] primary key(std_id)], #创建主键[[constraint fk] foreign key (std_sexid) references sex(s_id)], #创建外键,第一个参数写本表列名,后面是引用的表名和与本外键对应的主键[[constraint ue] unique(std_name)] #唯一约束,和主键约束差不多)
可以通过以上的方式创建约束,如果用以上的方式创建约束,
constraint 约束名可以省略,这样创建的约束没有约束名,加上constraint 约束名创建约束,取一个约束名,方便后期通过约束名删除约束
修改表名
alter table students rename to st #把students表名改成st
添加约束
#给已存在的表添加约束,主外键等alter table students add [constraint pk] primary key(std_id)
删除约束
alter table students drop foreign key fk #删除students表里面的名为fk的外键约束,逐渐约束好像不能用名字删除,直接primary key
添加字段
#向已有的表中添加新字段,default设置默认值,如果写 after 字段名 就是是把新的字段添加到这一字段之后,写first就是把新字段添加到最前面,after和first选择其中一个写,不要都写alter table students add column std_new varchar(20) [not null] [default 100] [after std_name] [first]
修改字段
#修改已有表的字段alter table students change std_name s_n varchar(88)#change后面指定要修改的字段名std_name,之后就写要改的字段的名字,类型等,default可以设置默认值
删除字段
alter table students drop column std_birthday #删除students表中std_birthday字段
修改/删除字段默认值
#修改已有表中字段的默认值alter table students alter std_new set default 888;#删除已有列的默认值alter table students alter std_new drop default
数据操作——增删改
添加
#单行指定字段添加,没添加的字段需要设置默认值之类的,不然报错insert into students(std_name,std_sexid) values('小明',1)#单行全部添加,每一列都要写对应的值,主键都要写null,值得数量和字段的数量不匹配就报错insert into students values(null,'小明',1,'1998-1-2')#多行插入insert into students values(null,'小明',1,'1998-1-2'),(null,'小强',2,'1998-1-3')
如果要插入很多条数据的话,不要用单行插入,一行一行的插入。这样会很慢。 用多行插入,速度快得多。
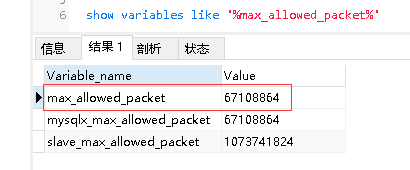
有可能会报错max_allowed_packet不足,需要设置max_allowed_packet变大一些。顾名思义就是最大的数据包的限制,单位是字节
show variables like '%max_allowed_packet%'
设置大小,设置最大数据包为100MB
set global max_allowed_packet=100*1024*1024
修改完成后再次查询需要,打开新的窗口页面进行查询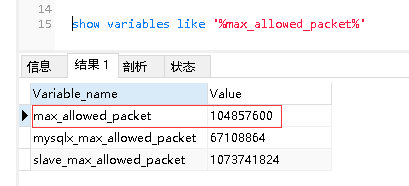
修改
update students set std_name = '小红',std_sexid = 2 [where std_id = 1]#更新多个字段用逗号隔开,where可以选择写,不写就是更新全部数据
删除
#普通删除数据delete from students [where std_id=1] #不写where就全部删除,表还在,结构还在#删除表结构drop table students #这么删除,数据表都没有了,表结构都被删了
数据操作——查
select
# *号表示查询全部字段,也可以写字段名,函数,表达式等,用逗号隔开,all限定符表示查询某字段的全部,distinct表示过滤某字段重复数据select [all|distinct] * from students#取个别名,as后面加名字,可以是中文select distinct std_name as 别名 from students
from
#from后面可以跟多个表名,用逗号隔开,连接查询,多张数据表连接查询出来的数据数量是每张表数据数量的乘积,表也可以取别名select *from students,sex as 性别表
如果表取了别名,在where条件里面,用
原表名.列名是定位不到的,取了别名就要用表别名.列名
where
条件判断,各种逻辑组合
#用and和or连接多个条件,&&和||一样的where 条件1 [and|or] (条件2 [&& | ||] 条件3)
#多表查询,要把每个表连接起来,通常是x表主键=y表外键select *from students,sexwhere students.std_sexid = sex.s_idand std_name is [not] null #判断名字为空and std_name [not] like '_明' #模糊查询2字,第二字是明and std_name [not] in('小工','小明','小红')#查看名字在这个集合里面and std_score [not] between 71 and 99 #查看成绩在71到99之间的,包含71和99
聚合函数
sum()求和,max()最大值,min()最小值,avg()平均数,count()计数
#查询成绩最高的学生select max(std_score) from students
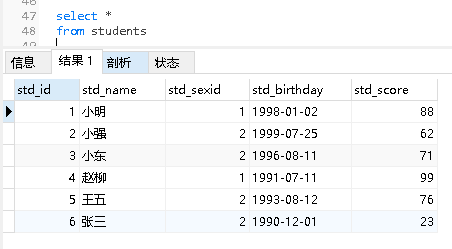
group by
分组查询,把某一字段进行分组,假如”学科”字段里面的数据,有32个语文,67个数学,82个英语,通过group by ‘学科’,把语文分一组,数学分一组,英语分一组
- 全部数据是这样
- 分组std_sexid
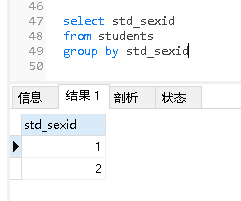
- 查看std_sexid字段中1和2这两组里面的最高分
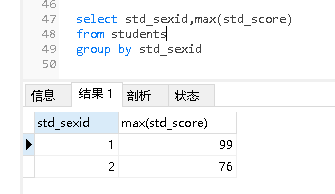
如果select 后面出现的列里面包含了聚合函数,那么不是聚合函数的列必须,在group by后面写上
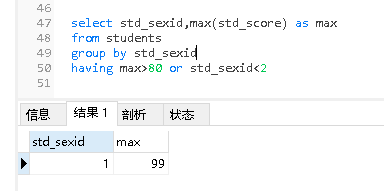
having
在group by后面写的条件
与 where 功能、用法相同,执行时机不同。
where 在开始时执行检测数据,对原数据进行过滤。 having 对筛选出的结果再次进行过滤。 having 字段必须是查询出来的,where 字段必须是数据表存在的。 where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值。 where 不可以使用合计函数。一般需用合计函数才会用 having
order by
排序
#按成绩排序,默认升序,可以用逗号分隔排序多列select *from studentsorder by std_score [asc|desc] #升序和降序
limit
限制查询,分页的好东西
limit 起始位置,获取条数如果limit后面只写一个数字,就是默认从0开始,取多条数据
#查询结果从索引1开始,取3条select *from studentslimit 1,3
子查询
就是先select查询出一部分数据,以这查出来的数据作为参数再次查询,得出新的结果。 本来是两个步骤,现在合并到一起写一条sql语句,就成了子查询
#随便举两个例子-- where型-- 先查询出学生的平均成绩,然后再查比平均成绩高的学生select *from studentswhere std_score>(select avg(std_score) from students)-- from型-- 先查询3个字段,成绩大于30的学生,输出的新表,取个别名,必须取别名!在查询这个新表,同时限定条件std_sexid=1select *from (select std_id,std_name,std_sexid from students where std_score>30) as new_tablewhere std_sexid=1
union
连接多个查询结果,把这些查询结果合并到一个查询结果里面。
比如查询结果A,有20条记录,查询结果B有15条记录,查询结果C有15条记录,用union把他们连接起来,合成一个新的查询结果D,D最多有20+15+15=50条数据。因为重复的数据会被删除
select *from students where std_sexid=1 #查询出来有2条记录union select *from students where std_score>20 #查询出来6条记录,本表全部数据#最后的结果来时6条数据,有2条重复了
两个查询结果字段可以不同,但是列的数量要一样,不然就是这样的报错


若有收获,就点个赞吧
0 人点赞
