https://blog.51cto.com/u_15444123/4713797
什么是多租户?
多租户技术或称多重租赁技术,简称**SaaS**,是一种软件架构技术,是实现如何在多用户环境下(多用户一般是面向企业用户)共用相同的系统或程序组件,并且可确保各用户间数据的隔离性。简单讲:在一台服务器上运行单个应用实例,它为多个租户(客户)提供服务。从定义中我们可以理解:多租户是一种架构,目的是为了让多用户环境下使用同一套程序,且保证用户间数据隔离。那么重点就很浅显易懂了,多租户的重点就是同一套程序下实现多用户数据的隔离。
简单说就是每个用户的数据隔离了。比如一个用户一个数据库,这个用户指的是机构学校公司等用户。一个用户数据库里面又包含了很多用户的用户。
多租户架构以及数据隔离方案
1.独立数据库
即一个租户一个数据库,这种方案的用户数据隔离级别最高,安全性最好,但成本较高。
- 优点:为不同的租户提供独立的数据库,有助于简化数据模型的扩展设计,满足不同租户的独特需求;如果出现故障,恢复数据比较简单。
缺点:增多了数据库的安装数量,随之带来维护成本和购置成本的增加。
2.共享数据库,独立 Schema
也就是说 共同使用一个数据库 使用表进行数据隔离
多个或所有租户共享Database,但是每个租户一个Schema(也可叫做一个user)。底层库比如是:DB2、ORACLE等,一个数据库下可以有多个SCHEMA。优点:为安全性要求较高的租户提供了一定程度的逻辑数据隔离,并不是完全隔离;每个数据库可支持更多的租户数量。
缺点:如果出现故障,数据恢复比较困难,因为恢复数据库将牵涉到其他租户的数据;
3.共享数据库,共享 Schema,共享数据表
也就是说 共同使用一个数据库一个表 使用字段进行数据隔离
即租户共享同一个Database、同一个Schema,但在表中增加TenantID多租户的数据字段。这是共享程度最高、隔离级别最低的模式。
简单来讲,即每插入一条数据时都需要有一个客户的标识。这样才能在同一张表中区分出不同客户的数据,这也是我们系统目前用到的(tenant_id)优点:三种方案比较,第三种方案的维护和购置成本最低,允许每个数据库支持的租户数量最多。
缺点:隔离级别最低,安全性最低,需要在设计开发时加大对安全的开发量;数据备份和恢复最困难,需要逐表逐条备份和还原。
springboot动态数据源原理
1.继承AbstractRoutingDataSource得到数据源
抽象类AbstractRoutingDataSource,通过继承这个类实现根据不同的请求切换数据源。
AbstractRoutingDataSource继承自AbstractDataSource,如果声明一个类继承AbstractRoutingDataSource则这个类本身就是数据源。2.数据源的getConnection()方法
既然是数据源一定会用到getConnection()方法,下面看源码: ```java public Connection getConnection() throws SQLException {
return this.determineTargetDataSource().getConnection();
}
public Connection getConnection(String username, String password) throws SQLException {
return this.determineTargetDataSource().getConnection(username, password);
}
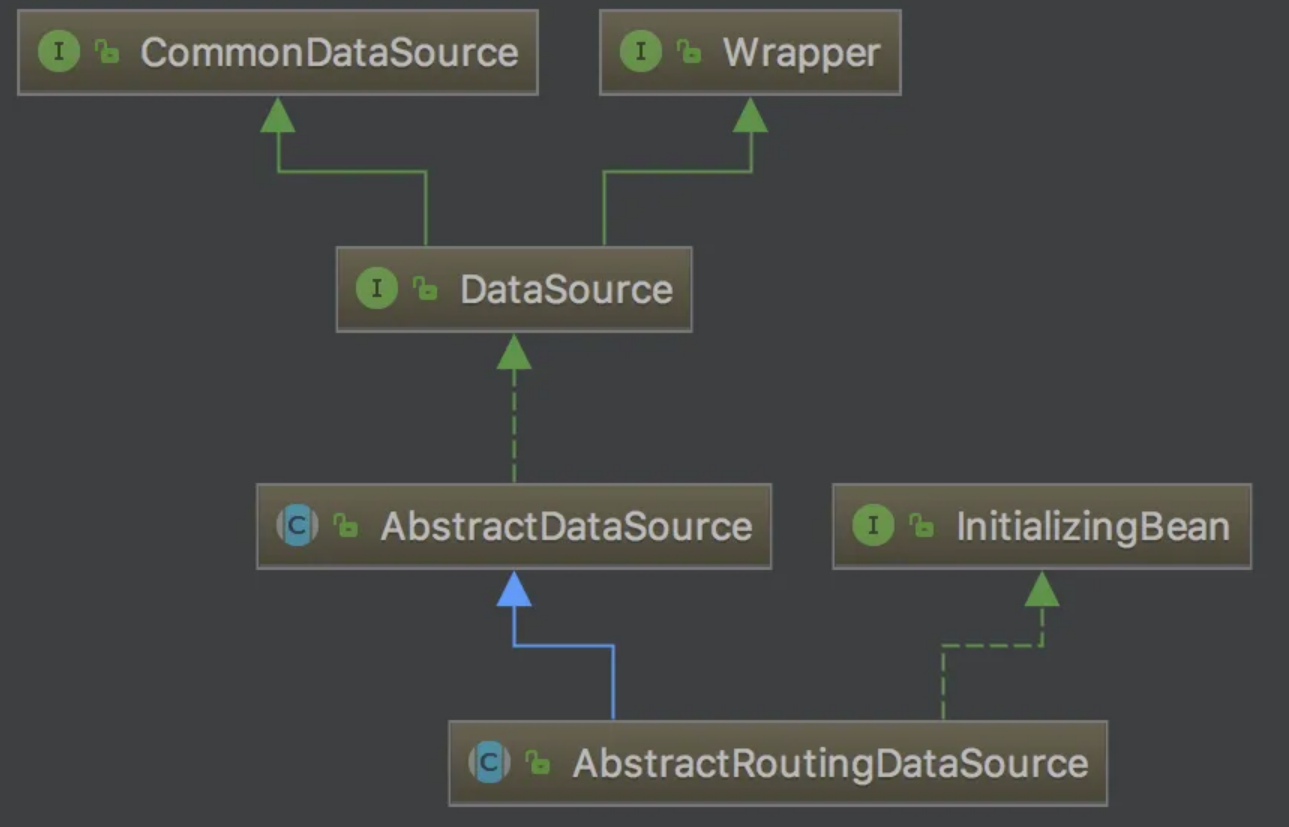
通过上面源码能分析得到数据库连接是由determineTargetDataSource()得来,下面继续分析determineTargetDataSource()方法。<a name="KAtid"></a>## 3.解析determineTargetDataSource方法这个方法是用来设置数据源的,重写的时候也是这个方法设置数据源```javaprotected DataSource determineTargetDataSource() {Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");Object lookupKey = this.determineCurrentLookupKey();DataSource dataSource = (DataSource)this.resolvedDataSources.get(lookupKey);if (dataSource == null && (this.lenientFallback || lookupKey == null)) {dataSource = this.resolvedDefaultDataSource;}if (dataSource == null) {throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");} else {return dataSource;}}
通过这段源码能否得到数据源首先需要获取 lookupKey:Object lookupKey = this.determineCurrentLookupKey();
然后通过这个key得到对应的数据源:DataSource dataSource = (DataSource)this.resolvedDataSources.get(lookupKey);
4.解析afterPropertiesSet
看代码resolvedDataSources的属性,首先它是Map,通过Object可以得到DataSoure
//用户设置的目标数据源和用户设置的默认目标数据源,需要转换成最终数据源才能使用@Nullableprivate Map<Object, Object> targetDataSources;@Nullableprivate Object defaultTargetDataSource;//最终决定的数据源,最终使用这个resolved数据源作为最终数据源@Nullableprivate Map<Object, DataSource> resolvedDataSources;@Nullableprivate DataSource resolvedDefaultDataSource;
然后这个属性的赋值代码:
public void afterPropertiesSet() {if (this.targetDataSources == null) {throw new IllegalArgumentException("Property 'targetDataSources' is required");} else {this.resolvedDataSources = CollectionUtils.newHashMap(this.targetDataSources.size());this.targetDataSources.forEach((key, value) -> {Object lookupKey = this.resolveSpecifiedLookupKey(key);DataSource dataSource = this.resolveSpecifiedDataSource(value);this.resolvedDataSources.put(lookupKey, dataSource);});if (this.defaultTargetDataSource != null) {this.resolvedDefaultDataSource = this.resolveSpecifiedDataSource(this.defaultTargetDataSource);}}}
可以看到是将targetDataSources对象的内容赋值给了它。就是说用户自己设置的数据源最终会被这个方法转换成系统最终决定的数据源。
倒入依赖
<dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.5.1</version></dependency>
实现动态数据源
package com.lyd.holder;import com.alibaba.druid.pool.DruidDataSource;import com.lyd.utils.RedisCache;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.jdbc.core.JdbcTemplate;import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;import org.springframework.stereotype.Component;import javax.sql.DataSource;import java.sql.Connection;import java.sql.SQLException;import java.util.HashMap;import java.util.List;import java.util.Map;/*** 继承AbstractRoutingDataSource实现动态数据源* 需要放入容器中,这个类写完了动态数据源就成了,能切换,不过细节就是怎么切换,需要再附加一些代码* 怎么得到数据源的key是关键*/@Componentpublic class DynamicDataSource extends AbstractRoutingDataSource {//redis操作类,可有可无,用来判断当前数据源的,还有其他办法@AutowiredRedisCache redisCache;//默认数据源private static DataSource defaultDataSource;//保存所有的数据源,key就是数据源的名字,value就是数据源private static Map<Object,Object> targetDataSources = new HashMap<>();static {//初始化默认数据源,用的Druid数据源DruidDataSource source = new DruidDataSource();source.setUrl("jdbc:sqlserver://127.0.0.1:1433;DatabaseName=CATALOG");source.setUsername("sa");source.setPassword("123456");source.setDriverClassName("com.microsoft.sqlserver.jdbc.SQLServerDriver");source.setInitialSize(2);source.setMinIdle(2);source.setMaxActive(5);defaultDataSource = source;}/*** 获取数据库连接* @return* @throws SQLException*/@Overridepublic Connection getConnection() throws SQLException {return super.getConnection();}/*** 设置默认数据源*/@Overridepublic void setDefaultTargetDataSource(Object defaultTargetDataSource) {super.setDefaultTargetDataSource(defaultDataSource);}/*** 设置用户的数据源,并制作成系统用的最终数据源*/@Overridepublic void afterPropertiesSet() {//初始化所有租户的数据源initTargetDataSources();//一些参数设置操作super.afterPropertiesSet();}/*** 初始化所有租户的数据源*/public void initTargetDataSources(){//去数据库里面查询得到所有动态数据源//这里不能用mybatis mapper查询,会照成循环依赖,或者用其他的办法,数据源存在其他地方等,总之就是在这个地方要获取到用户的全部数据源信息JdbcTemplate jdbcTemplate = new JdbcTemplate(defaultDataSource);List<Map<String, Object>> maps = jdbcTemplate.queryForList("select * from dbset");//遍历这些数据源信息,把他们组装成数据源,加入到上面定义的用来装全部数据源的map里面for(Map<String, Object> dbSetMap : maps){try {//创建租户的数据源DataSource tenantDataSource = createDataSourceByTTenant(dbSetMap);//放到所有数据源的容器中targetDataSources.put(dbSetMap.get("setid"), tenantDataSource);} catch (Exception e) {//e.printStackTrace();}}//传给父类,设置所有的数据源Mapsuper.setTargetDataSources(targetDataSources);}/*** 每次执行sql请求,都会调用这个方法,返回一个key,然后在数据源map里面通过这个key查找对应的数据源,就用这个key的数据源进行sql操作* 这个方法返回的key是怎么来的是关键,每个请求是那个数据源,主要这个决定的,我这里写的是从redis里面取* 比如用户发请求带的token里面的的用户id是2,就去redis里面找用户2的数据源key,然后这个方法返回用户2的数据源key,去全部数据源里面找到用户2的数据源,数据源就切换到了用户2的*/@Overrideprotected Object determineCurrentLookupKey() {return redisCache.getCacheObject("k1");}/*** 每次sql请求会决定使用哪个数据源* 和上面的方法是联动的,看上面的注解*/@Overrideprotected DataSource determineTargetDataSource() {DataSource dataSource = null;//如果未获取到if (null == determineCurrentLookupKey()) {dataSource = defaultDataSource;}else {dataSource = (DataSource) targetDataSources.get(determineCurrentLookupKey());}return dataSource;}/*** 根据表里数据源 初始化话数据源* 这个完全就是自定义的,我的数据源来源,结构等不定,但是最终都要封装成一个数据源返回,用的是druid* @return*/public DataSource createDataSourceByTTenant(Map<String, Object> dbSet){String ip=dbSet.get("dbserver").toString().split(",")[0];String port=dbSet.get("dbserver").toString().split(",")[1];String dbname=dbSet.get("dbname").toString();String username=dbSet.get("dbuser").toString();String pwd=dbSet.get("dbpass").toString();//创建一个数据源返回DruidDataSource source = new DruidDataSource();source.setUrl("jdbc:sqlserver://"+ip+":"+port+";DatabaseName="+dbname);source.setUsername(username);source.setPassword(pwd);source.setDriverClassName("com.microsoft.sqlserver.jdbc.SQLServerDriver");source.setInitialSize(2);source.setMinIdle(1);source.setMaxActive(3);return source;}}

若有收获,就点个赞吧
0 人点赞
