SELECT语法
SELECT <选择查询结果列表>[INTO <新表名>] --指定查询的结果创建一个新表FROM <表源> --查询的表或者视图的名称[WHERE <查询条件表达式>][GROUP BY <分组表达式>][HAVING <分组条件表达式>][ORDER BY <排序表达式> [ASC | DESC]]
SELECT子句
SELECT [ALL | DISTINCT] [TOP <n> [PERCENT] [WITH TIES]] <选择查询结果列表>
ALL:默认,指定查询结果集中的所有行 DISTINCT:去重 TOP
[PERCENT]:指定返回查询结果集中的前n行,如果加了PERCENT,则表示返回查询结果集中的前n%行 WITH TIES:用于指定从基本结果集中返回附加的行
INTO子句
查询的结果不仅可以显示查看还可以作为一个数据表永久的保存起来。使用INTO子句可以创建一个新表,并将查询的结果直接插入到新表中。新表名以#为前缀,则保存查询结果的新表为临时表。
INTO子句和COMPUTE子句具有互斥性,二者不能并存于同一查询语句中
INTO <新表名>
FROM子句
FROM子句用于指定SELECT语句查询的源表,视图,派生表,连接表,中间用逗号隔开,FROM子句最多可以使用16个表或者视图。
FROM <表源>[,...n]
WHERE子句
给查询添加限制条件。通常情况下,必须定义一个或者多个条件限制检索选择的数据行。WHERE子句后面跟逻辑表达式,结果集将返回表达式为TRUE的数据行。WHERE一般放在FROM子句后面。
WHERE <查询条件表达式>
在WHERE子句中条件表达式可以包含比较运算符,逻辑运算符。
GROUP BY子句
如果需要按某一列的值进行分类,在分类的基础上再进行统计,就要使用GROUP BY子句分组了
GROUP BY <分组表达式>
- GROUP BY子句写在WHERE子句之后。
- 分组表达式可以是普通列名或一个包含SQL函数的计算列,但不能是字段表达式。
当使用GROUP BY子句进行分组时,SELECT子句的选项列表可以包含聚合函数。但是SELECT子句后的各列或包含在聚合函数中,或包含在GROUP BY子句中。
例子:统计每个年级的平均分,最高分,最低分
SELECT AVG(分数) AS '平均分',MAX(分数) AS '最高分',MIN(分数) AS '最低分' FROM 学生表 GROUP BY 年级
HAVING子句
用于限定组或者聚合函数的查询条件。通常在GROUP BY子句后,即为GROUP BY分组的结果设置筛选条件,使得满足限定条件的那些组被挑选出来,构成最终的查询结果。通常HAVING子句和WHERE子句作用一样。但是WHERE子句是对原始记录进行过滤,HAVING是对查询结果进行过滤。HAVING子句中可以使用聚合函数,而WHERE子句不能使用聚合函数
HAVING <分组条件表达>
ORDER BY子句
进行排序显示
ORDER BY {排序列表达式}[ASC | DESC][,...n]
- ORDER BY子句中可以指定一个或者多个排序列,即嵌套排序,检索结果首先按第1列进行排序,对第1列值相同的那些数据行,再按照第二列排序……以此类推
- 默认ASC
- ORDER BY子句要写在WHERE子句后面,而且ORDER BY子句中不能使用NTEXT,TEXT和IMAGE列。
集合查询
集合查询是指将两个或者两个以上的SELECT语句,用UNION(并),INTERSECT(交)或者EXCEPT(差)运算符链接起来查询。参与集合查询的各查询结果的列数必须相同,对应项的数据类型也必须相同。
例子
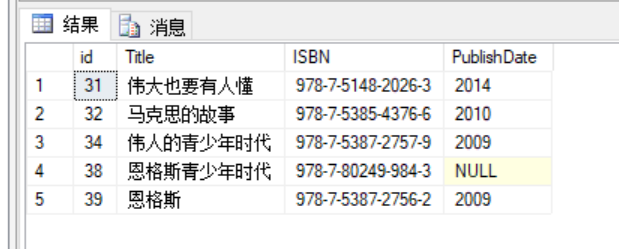
SELECT id,Title,ISBN,PublishDate FROM BookList WHERE id BETWEEN 30 AND 40SELECT id,Title,ISBN,PublishDate FROM BookList WHERE PublishDate=2013 AND id BETWEEN 30 AND 60
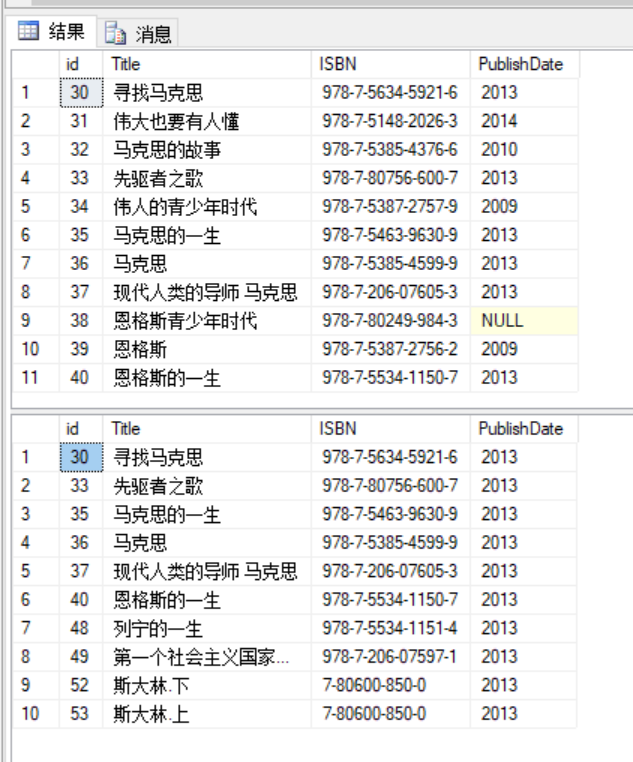
UNION(并)
SELECT id,Title,ISBN,PublishDate FROM BookList WHERE id BETWEEN 30 AND 40UNIONSELECT id,Title,ISBN,PublishDate FROM BookList WHERE PublishDate=2013 AND id BETWEEN 30 AND 60
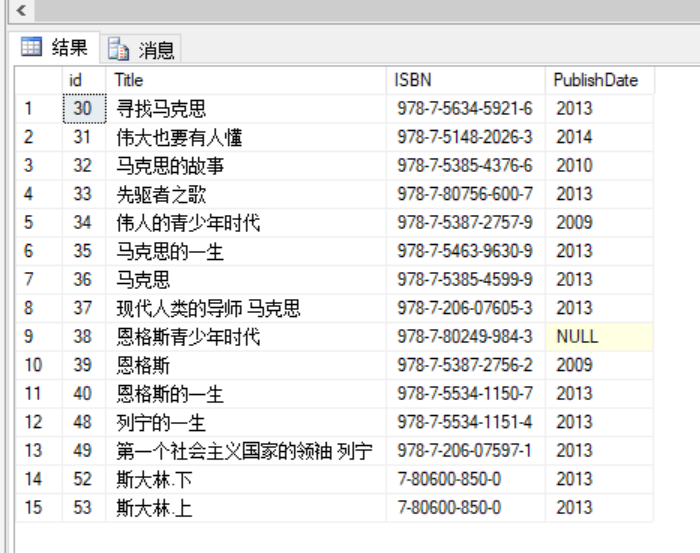
INTERSECT(交)
SELECT id,Title,ISBN,PublishDate FROM BookList WHERE id BETWEEN 30 AND 40INTERSECTSELECT id,Title,ISBN,PublishDate FROM BookList WHERE PublishDate=2013 AND id BETWEEN 30 AND 60
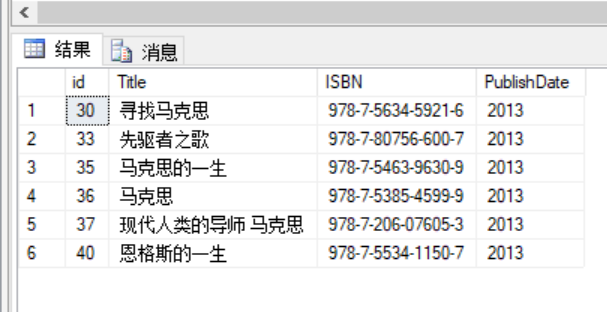
EXCEPT(差)
SELECT id,Title,ISBN,PublishDate FROM BookList WHERE id BETWEEN 30 AND 40EXCEPTSELECT id,Title,ISBN,PublishDate FROM BookList WHERE PublishDate=2013 AND id BETWEEN 30 AND 60
检索某一范围内的信息
BETWEEN … AND …
例子:检查id在30到40之间的数据,等于id>=30 AND id<=40
SELECT id,Title,ISBN,PublishDate FROM BookList WHERE id BETWEEN 30 AND 40
IN
让用户选择与列表中的值想匹配的行,指定项必须用括号括起来,用逗号隔开,表示或的关系,NOT IN相反。
SELECT * FROM BookList WHERE id in (20,30,40,50)--也可以子查询SELECT * FROM BookList WHERE id in (SELECT id FROM BookList WHERE id<20)
LIKE
模糊查询。LIEK后的表达式被定义为字符串。可以使用以下4种通配符。
%:可以匹配任意类型和长度的字符串_:可以匹配任何单个字符[]:指定范围或集合中的任何单个字符[^]:不属于指定范围或集合的任何单个字符--检查名字中是否出现一个子字,任何位置出现都匹配SELECT * FROM Student WHERE name LIKE '%子%'--姓张的,单名SELECT * FROM Student WHERE name LIKE '张_'--等级在abcdefghi中单个字母SELECT * FROM Student WHERE grade LIKE '[a-i]'--等级A开头,第二个字符不在1,2,3,4中SELECT * FROM Student WHERE grade LIKE 'A[^1-4]'
IS NULL
可以检索数据列中没有赋值的行SELECT * FROM Student WHERE name IS NULL
指定别名
SELECT <列名> [AS] <表别名>[,...n] FROM <表名> [AS] <表别名>
连接查询
链接类型有
- 内链接
- 外链接
- 交叉链接
连接格式
链接的格式有以下两种FROM子句定义连接
SELECT <输出列表> FROM <表1> {<连接类型> <表2> [ON <连接条件>]}[ ...n]
WHERE子句定义连接
SELECT <输出列表> FROM <表1>,<表2>[,...n] WHERE <表1的某一列> <连接操作符> <表2的某一列>[AND ...n]
连接类型:内连接(INNER JOIN),外连接(OUTER JOIN),交叉连接(CROSS JOIN)
WHERE子句没有指定连接类型,而FROM子句可以指定连接,建议用FROM子句。WHERE子句定义连接默认为内连接
内连接
内连接INNER JOIN将两个表中的列进行比较,将两个表中满足连接条件的行组合起来生成第三个表,仅包含那些满足连接条件的数据行。内连接有等值连接,自然连接和不等值连接3种。
等值连接:连接操作符是“=”时 自然连接:等值连接且去重 不等值连接:和等值连接相反
WHERE内连接
SELECT * FROM People AS P,Sex AS S where P.Id=S.Id
FROM内连接
SELECT * FROM BookClass AS bc INNER JOIN BookList AS bl ON bc.id=bl.id
外连接
在内连接中,只有两个表的匹配记录才能在结果集中出现,而外连接只限制一个表,而对另一个表不限制,即所有的行都出现在结果集中。
外连接分为左外连接(LEFT [OUTER] JOIN),右外连接(RIGHT [OUTER] JOIN),全外连接(FULL [OUTER] JOIN)。使用中可以省略OUTER关键字
左外连接
左外连接对左边的表不加以限制。显示左边的表的全部数据,右边的表和左边的表里面的数据能匹配上才显示
FROM <左表名> LEFT [OUTER] JOIN <右表名> ON <连接条件>
右外连接
右外连接对右边的表不加以限制。显示右边的表的全部数据,左边的表和右边的表里面的数据能匹配上才显示。和左外连接相反的。
FROM <左表名> RIGHT [OUTER] JOIN <右表名> ON <连接条件>
全外连接
全外连接对两张表都不加以限制,两个表中所有行都会出现在结果集中。
FROM <左表名> FULL [OUTER] JOIN <右表名> ON <连接条件>
交叉链接
交叉连接又称为非限制连接,它将两个表不加任何约束的组合起来。在数学上就是两个表的笛卡尔积,交叉链接得到的结果集的行数是两个被链接的表的行数的乘积。交叉连接的结果一般没有什么意义。
FROM <表名1> CROSS JOIN <表名2>
自连接
自连接就是一个表与它自身的不同行进行连接。因为表名要在FROM子句出现两次,所以分别取不同的别名。
SELECT s1.id1,s2.id2 FROM Stu s1,Stu s2 WHERE s1.id1 = s2.id2
嵌套查询
T-SQL将一个SELECT-FROM-WHERE语句称作一个查询块。嵌套查询又称子查询,是多个SELECT语句的一种嵌套包含结构。T-SQL能够将多个简单查询语句通过嵌套关系关联起来,创造出更为复杂的查询结果。
在嵌套查询中,外部的SELECT语句被称为父查询或者外层查询,内部的SELECT语句被称为子查询或者内层查询。子查询还可以一直嵌套更深的子查询
- 多层嵌套查询是由内往外查,先查询最内部的查询,依次往外。
- 父查询块在WHERE子句中通过某些条件与子查询关联
- 嵌套查询只能在最外层的查询块中使用ORDER BY子句进行排序。所有内层查询不能使用ORDER BY与COMPUTE BY子句,但是可以使用GROUP BY和HAVING子句。
- 通常将内层查询放在小括号里面。
使用IN或者NOT IN嵌套查询
SELECT-FROM-WHERE <列名或者表达式> [NOT] IN (<子查询>)
先查出子查询,在比较父查询的条件里面的列名或者表达式是否在子查询的结果里面,在结果里面的就放入最终的父查询结果集 NOT IN就是不在子查询里面,和IN相反
使用比较运算符嵌套查询
SELECT-FROM-WHERE <列名或者表达式> <比较运算符> (<子查询>)
先查出子查询,得到某个单独的值,就是子查询SELECT后面只有一个列,而且最后的结果是一个值。父查询在比较子查询的这个值,根据结果查询数据。
使用ANY或者ALL嵌套查询
ALL或者ALL关键字必须与比较运算符联合使用,用来对比较运算符的运算范围进行特定的语意修饰。
比较运算符在左边,ANY或ALL在右边,中间没有空格。
SELECT-FROM-WHERE <列名或者表达式> <比较运算符>[ANY | ALL](<子查询>)
关于比较运算符加上ANY或者ALL的意思。 举两个例子:
- =ALL:等于子查询结果集中的所有值
ANY:大于子查询结果集中的某个值
和光用比较运算符嵌套查询的区别在于,比较运算符嵌套查询,子查询的结果集为单独的一个值,而ANY或ALL嵌套查询,子查询结果集为一组单值。
ANY或者ALL的可以等价一些聚合函数,两种实现方法功能上等价,后者更加效率。
| 运算符+ALL | 等价于 | 运算符+ANY | 等价于 |
|---|---|---|---|
| !=ALL或<>ALL | NOT IN | =ANY | IN |
| >ALL | >MAX() | >ANY | >MIN() |
| >=ALL | >=MAX() | >=ANY | >=MIN() |
| <ALL | <MIN() | <ANY | <MAX() |
| <=ALL | <=MIN() | <=ANY | <=MAX() |
| !>ALL | <=MIN() | !>ANY | <=MAX() |
| !<ALL | >=MAX() | !<ANY | >=MIN() |
使用EXISTS或NOT EXISTS嵌套查询
EXISTS用来判断子查询是否存在记录。NOT EXISTS用来判断是否不存在记录。反正仅仅是用来判断返回的数据集是否为空集,至于数据集包含哪些字段毫无意义,子查询用*号省事。
SELECT-FROM-WHERE [NOT] EXISTS (<子查询>)

若有收获,就点个赞吧
0 人点赞
