Work queues,也被称为(Task queues),任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。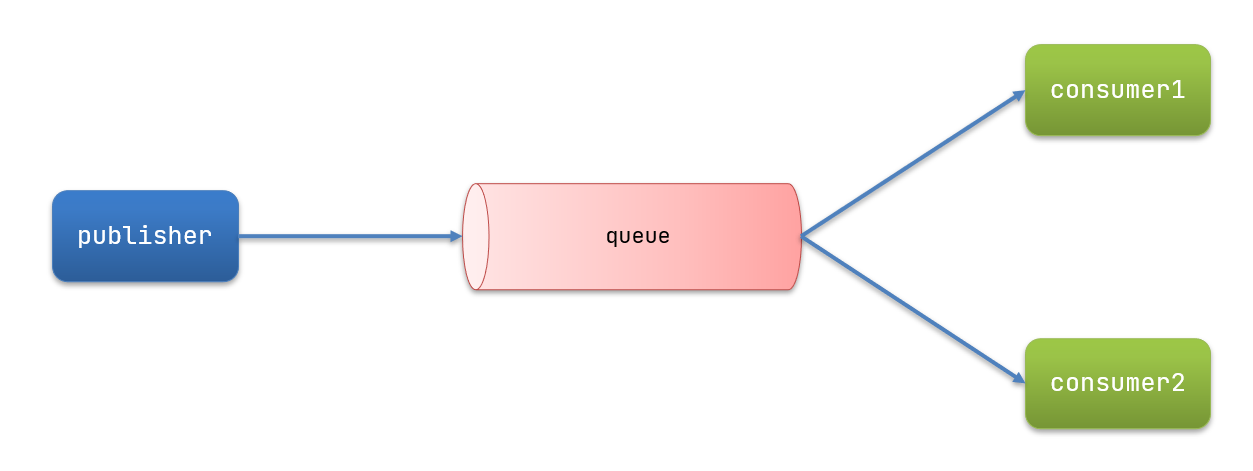
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,速度就能大大提高了。
1.引入依赖
2.消息发送
这次我们循环发送,模拟大量消息堆积现象。
在publisher服务中的SpringAmqpTest类中添加一个测试方法:
/*** workQueue* 向队列中不停发送消息,模拟消息堆积。*/@Testpublic void testWorkQueue() throws InterruptedException {// 队列名称String queueName = "simple.queue";// 消息String message = "hello, message_";for (int i = 0; i < 50; i++) {// 发送消息rabbitTemplate.convertAndSend(queueName, message + i);Thread.sleep(20);}}
3.消息接受
要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法:
package cn.itcast.mq.listener;@Componentpublic class SpringRabbitListener {@RabbitListener(queues = "simple.queue")public void listenWorkQueue1(String msg) throws InterruptedException {System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());Thread.sleep(20);}@RabbitListener(queues = "simple.queue")public void listenWorkQueue2(String msg) throws InterruptedException {System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());Thread.sleep(200);}}
4.测试
启动ConsumerApplication后,在执行publisher服务中刚刚编写的发送测试方法testWorkQueue。
可以看到消费者1很快完成了自己的25条消息。消费者2却在缓慢的处理自己的25条消息。
也就是说消息是平均分配给每个消费者,并没有考虑到消费者的处理能力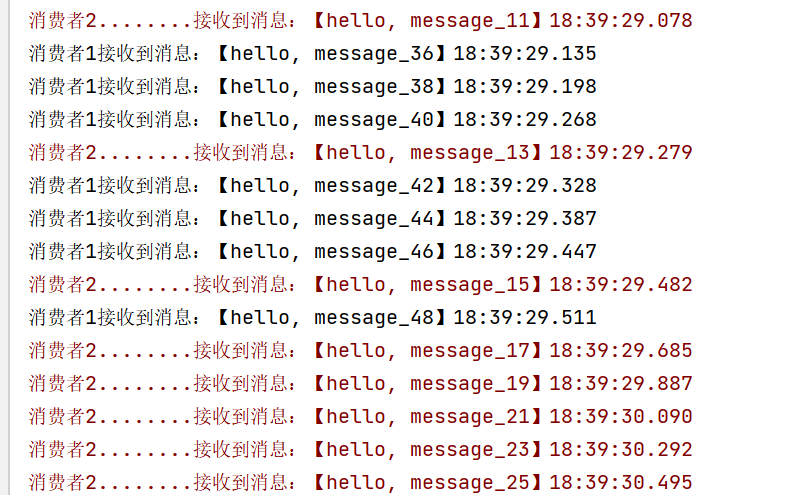
消息预取机制
就像上面那样,提前先分配好,两个消费者要处理哪些消息。把这些消息先给分配的消费者,等他们慢慢处理。所以消费者2就消息堆积了。
在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:
spring:rabbitmq:listener:simple:prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息

若有收获,就点个赞吧
0 人点赞
