- 一、安装 Gitlab Runner
- Ubuntu 系统
- 二、Gitlab Runner
- 测试
- 三、配置
gitlab-ci.yml - This file is a template, and might need editing before it works on your project.
- https://docs.gitlab.com/ce/ci/yaml/README.html for all available options">see https://docs.gitlab.com/ce/ci/yaml/README.html for all available options
- 处于相同的 stage 并行执行
- 四、部署测试环境
- 五、定期清理磁盘空间
原文链接:
一、安装 Gitlab Runner
1.1 基于 Shell 安装
- 查看服务器架构
dpkg命令可用于查看 Debian/ Ubuntu 操作系统是 32 位还是 64 位,此命令只适用于基于 Debian 和 Ubuntu 的 Linux 发行版。
在终端中执行如下命令:
dpkg —print-architecture
如果当前 Linux 是 64 位则输出 amd64,是 32 位则会输出 i386。
- 下载二进制文件
Ubuntu 系统
curl -LJO “https://gitlab-runner-downloads.s3.amazonaws.com/latest/deb/gitlab-runner_**amd64.**deb“
- 安装依赖包
dpkg -i gitlab-runner_amd64.deb
注意:gitlab-runner运行在 debug 模式
gitlab-runner —debug run
1.2 基于 Docker 安装
使用本地系统卷挂载来启动 Gitlab Runner 容器
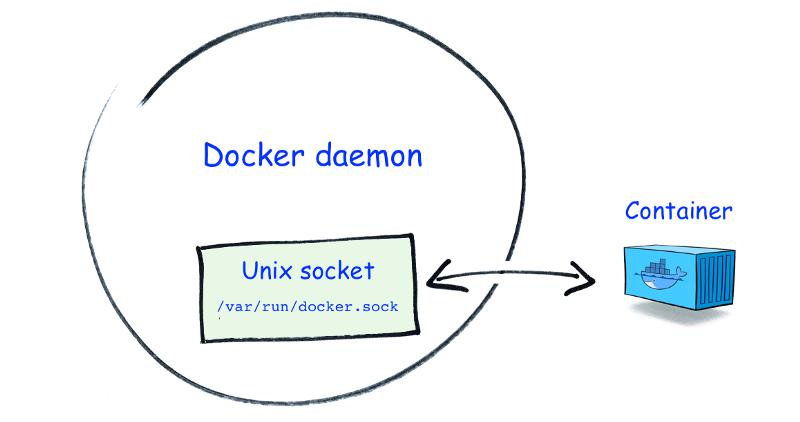
docker run -d --name gitlab-runner --restart always \-v /srv/gitlab-runner/config:/etc/gitlab-runner \-v /var/run/docker.sock:/var/run/docker.sock \gitlab/gitlab-runner:latest
其中:
- 挂载卷
/srv/gitlab-runner/config/config.toml包含了所有 runner 的配置信息(在宿主机上)。 - 通过挂载
/var/run/docker.sock:/var/run/docker.sock,使得容器中的进程可以通过它与Docker 守护进程通信。
二、Gitlab Runner
2.1 GitLab Runner 与执行器 Executor 的关系
先从 GitLab 与 GitLab Runner 的关係开始。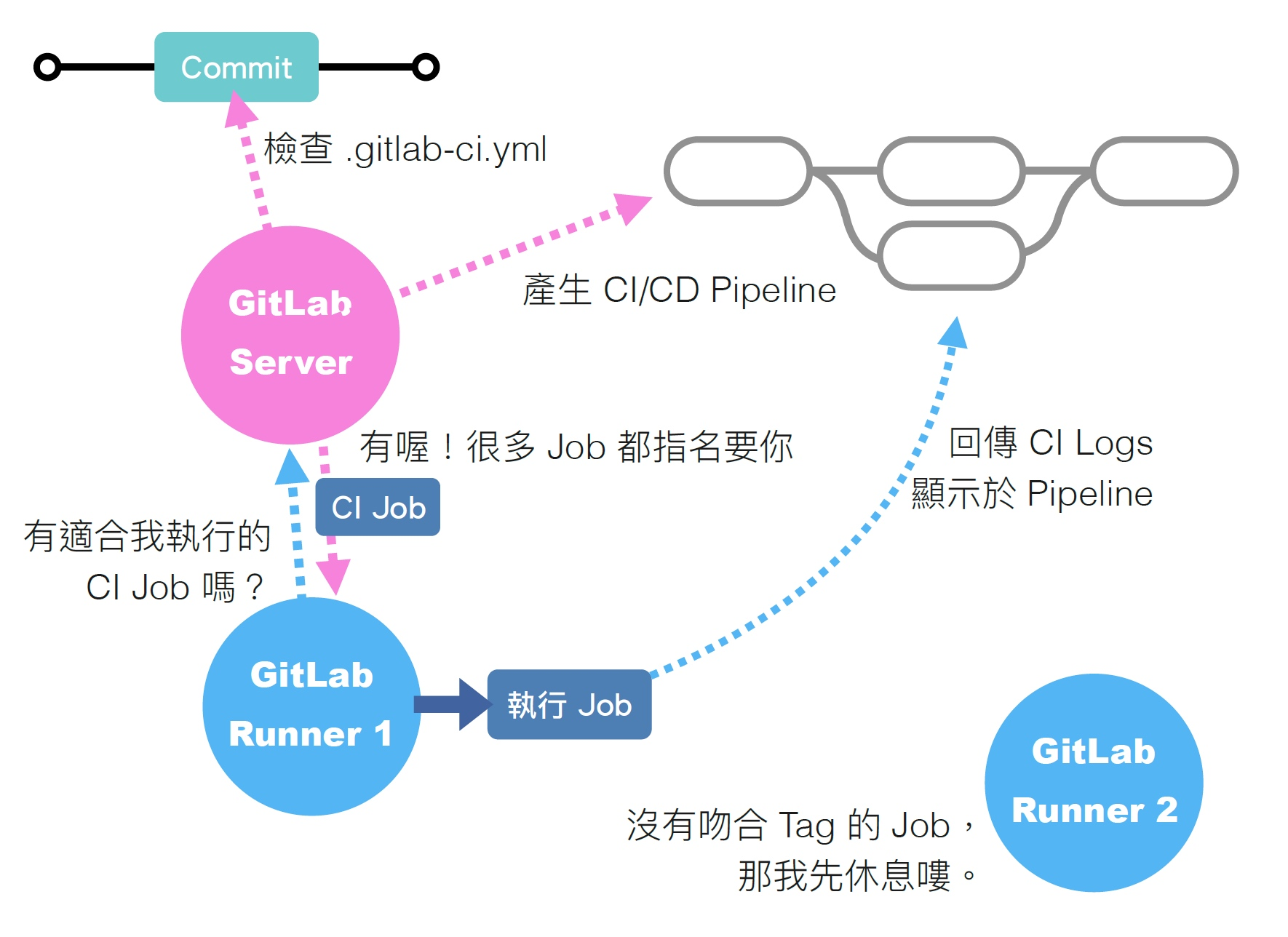
如上图,我们都知道 GitLab Runner 是用来帮助我们执行 CI Job 的工人,而 GitLab 就是这些工人的老板。老板(GitLab)会去查看需求单(.gitlab-ci.yml)建立一张又一张有先后顺序的工单(CI Pipeline),而每一位工人(Runner)则是每隔固定的时间就去询问老板(GitLab)现在有分配给自己的工作(CI Job)吗?现在自己应该做哪一项工作?工人拿到工作后开始执行,并且在执行过程中将处理进度即时填写在工单上。
到这裡为止,大部分的人都不太会有什么问题,让我们接著说明 GitLab Runner 与 Executor 的关係。
前面我们将 GitLab 与 GitLab Runner 比喻为老板与工人,那么 Executor 是什么?是工人的工具吗?舰长觉得与其说是“工具”,Executor 反倒更像是工人的“完成工作的方式”或“工作的环境”。
举例来说,就像我们都曾听过的都市传说,据说在国外有某知名企业的工程师,偷偷将自己的程式开发工作远距外包给印度工程师完成,藉此实现上班摸鱼打混还能取得高绩效表扬的神奇故事。当然偷偷把正职工作私下外包是不正确的行为,但在这个故事中,这就是这位工程师“完成工作的方式”;同理用嘴巴命令别人做事、自己苦力的土法炼钢、善用自动化工具或高科技工具辅助、远距连线工作⋯⋯这些都是不同的“完成工作的方式”。
按著上面的比喻,依据你选择的 Executor 决定了 Runner 将会採用何种“方式”及在哪个“工作环境”来完成 CI Job。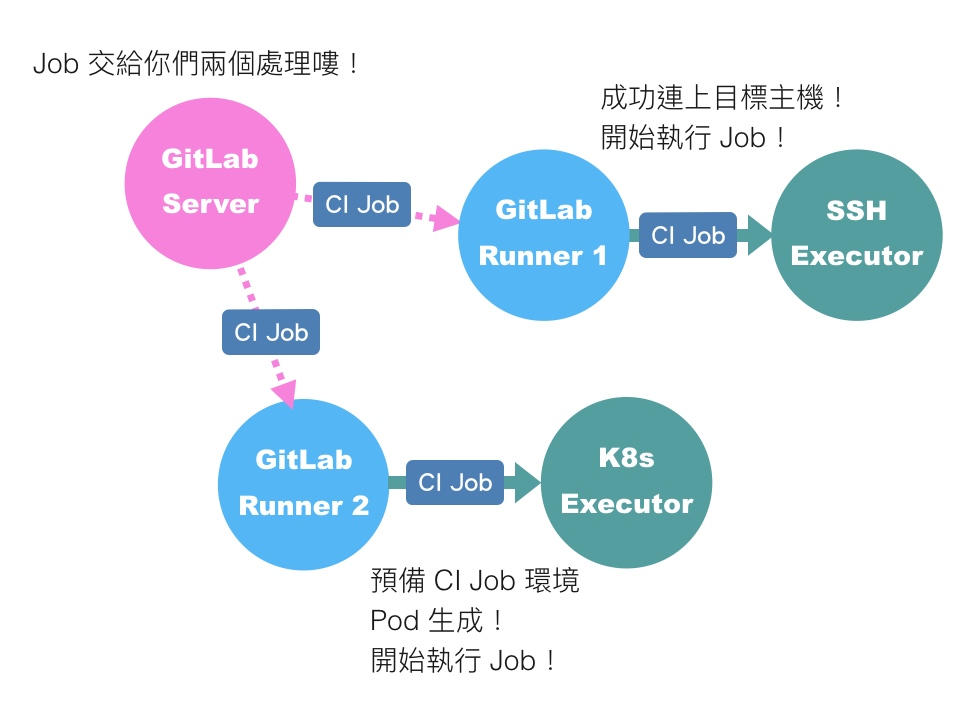
因此我们可以明白,这意味著身为老板的我们,很可能需要聘雇多位不一样的工人。举例来说,炒菜煮饭这种工作,我们就会安排给在厨房工作的厨师、闯入民宅开宝箱这种工作,我们就会安排给 RPG 游戏中的勇者。根据不同的 CI Job,我们有可能需要准备设置了不同 Executor 的 Runner 来响应。
2.2 执行器 Executor
了解 Runner 与 Executor 的关係后,接著来认识目前 GitLab Runner 可选择的 Executor 有哪些。
2.2.1 Executor 类别
目前可选用的 Executor 如下:
- Shell :即 Runner 直接在自己的本地环境执行 CI Job,因此如果你的 CI Job 要执行各种指令,例如 make、npm、composer⋯⋯,则需要事先确定在此 Runner 的本地环境是否已具备执行 CI Job 所需的一切环境及依赖。
- SSH:Runner 会透过 SSH 连上目标主机,并且在目标主机上执行 CI Job。因此你要提供 Runner 足以 SSH 连线目标主机的帐号密码或 SSH Key,也要提供足够的使用者权限。当然目标主机上也要事先处理好执行 CI Job 所需的一切相依程式与套件。
- Parallels:每次要执行 CI Job 时,Runner 会先透过 Parallels 建立一个乾淨的 VM,然后透过 SSH 登入此 VM 并在其中执行 CI Job。所以同样的用来建立 VM 的 Image 是先要预备好执行 CI Job 所需的一切相依程式与套件,这样 Runner 建立好的环境才能正确地执行 CI Job。另外,当然架设 Runner 的主机上,记得要安装好 Parallels。
- VirtualBox:同上,只是改成用 VirtualBox 建立乾淨的 VM。同样架设 Runner 的主机上,记得要安装好 VirtualBox。
- Docker:Runner 会透过 Docker 建立乾淨的 Container,并且在 Container 内执行 CI Job。因此架设 Runner 的主机上,记得要安装好 Docker,另外在规划 CI Pipeline 时也要记得先准备能顺利执行 CI Job 的各种 Docker image。在 CI Pipeline 中採用 Container 已是十分普遍的作法,建议大家可以优先评估 Docker executor 是否适合你的工作场景。
- Docker Machine:延续上一个 Executor,此种 Executor 一样会透过 Container 来执行 CI Job,但差别在于这次你原本的 Runner 将不再是一般的工人了,它已经摇身一变成为工头,每当有工作(CI Job)分派下来,工头就会去自行招募工人(auto-scaling)来执行工作。因此倘若在短时间内有大量的工作需要执行,工头就会去招募大量的工人迅速的将工作们全数搞定。需要注意的是因为招募工人需要一些时间,故有时此种 Executor 在启动时会需要多花费一些时间。
- Kubernetes:延续前两个与 Container 相关的 Executor,这次直接进入超级工头 K8s 的世界。与前两种 Executor 类似,但这次 Runner 操控的不是小小的 Docker engine 了,而是改为操控 K8s。此种 Executor 让 Runner 可以透过 K8s API 控制分配给 Runner 使用的 K8s Cluster 相关资源。每当有 CI Job 指派给 Runner 时,Runner 就会透过 K8s 先建立一个乾淨的 Pod,接著在其中执行 CI Job。当然使用此种 Executor 依然记得先准备好能顺利执行 CI Job 的各种 Container image。
- Custom:如果上面这七种 Executor 都不能让你满意,那就只好请客官您自行动手啦!Custom Executor 即是 GitLab 提供给使用者自行客制 Executor 的管道。
2.2.2 选择哪种 Executor?
简单来说就是根据你的需要来选择 Executor!(谜之音:舰长你这不是废话吗~)
如果你的团队已经很熟悉 Container 技术,不论是开发、测试及 Production 环境都已全面拥抱 Container,那当然选择 Docker executor 是再正常不过了。更不用说如果 Production 环境已经採用 K8s,那么 CI/CD Pipeline 想必也离不开 K8s 的魔掌,Runner 势必会选用 Kubernetes executor。(但还是别忘了凡事都有例外。)
假如只有开发环境拥抱 Container,但实际上测试机与 Production 环境还是採用实体伺服器或 VM,这时你可能就会准备多个 Runner 并搭配多种 Executor。例如 Build、Unit Testing 或某些自动化测试的 CI Job 让 Docker executor 去处理;而像是 Performers testing 则用 VirtualBox executor 开一台乾淨的 VM 并部署程式来执行测试。
又或者,你的公司有非常多项目正在同步进行中,同时间需要执行的 CI Job 时多时少,那么可以 auto-scaling 的 Docker Machine executor 也许会是一个可以考虑的选择。事实上 gitlab.com 提供给大家免费使用的 Shared Runner,就有採用 Docker Machine executor。
再举例,假如有某个 CI Job 只能在某台主机上执行,也许是为了搭配实体服务器的某个硬体装置、也许是基于安全性或凭证的缘故,在这种情况下很可能你会用到 SSH executor,或甚至是在该主机上安装 Runner 并设定为 Shell executor,让特定的 CI Job 只能在该 Runner 主机上执行。
最后,也有可能你因为刚好身处在一个完全没有 Container 知识与技能的团队,所以才只好选择 Shell、SSH、VirtualBox 这些不需要碰到 Container 的 Executor。
【小提醒】由于 SSH、VirtualBox、Parallels 这三种 Executor,Runner 都是先连上别的主机或 VM 之后才执行 CI Job 的内容,因此都不能享受到 GitLab Runner 的 caching feature。 (官网文件也有特别提醒这件事。)
2.2.3 什么是 Docker in Docker(dind)
参考官方文档 - dind
使用dind的背景是: 需要在容器内执行docker命令
在 1.2 中注册好了一个docker executor之后,只需要完成两个操作,即可使用
- 在
gitlab-ci.yml中添加: ```yaml image: docker:stable
service:
- docker:dind
测试
before_script:
- docker info ```
- 确保
config.toml中该 runner 中设置了privileged = true
2.3 Gitlab Runner
2.3.1 Runner 分类
一个 Runner 可以特定于某个项目,也可以在 GitLab CI 中服务于任何项目。服务于所有项目的Runner称为共享Runner。
理想情况下,不应将 GitLab Runner 与 GitLab 安装在同一台机器上。
- Shared Runners :顾名思义,共享 Runner。对于具有相似要求的作业,可以考虑用 Shared Runners。你可以用一个或少量几个 Runner 处理多个项目,而不是让多个 Runner 空闲着。这样可以更轻松地维护和更新它们。Shared Runners 使用公平队列处理作业,与使用FIFO队列的 Specific Runners 相比,这可以防止项目创建数百个作业,而导致耗尽所有可用的共享Runner资源。
- Specific Runners :顾名思义,对于有特殊要求的作业,可以考虑用Specific Runners。
- Group Runners :顾名思义,当一个小组中有多个项目,并且希望这些项目都可以访问一组job时,可以考虑用 Group Runners。Group Runners 也是用FIFO队列处理作业的。
怎么理解 Shared Runners 用的公平队列和 Specific Runners 用的FIFO队列呢?举个例子: 假设有这个一个队列 Job 1 for Project 1
Job 2 for Project 1
Job 3 for Project 1
Job 4 for Project 2
Job 5 for Project 2
Job 6 for Project 3 那么,Shared Runner执行作业的顺序会是146253,而 Specific Runner 执行作业的顺序是123456
Specific Runners 仅针对特定的项目运行,Shared Runners 则可以为每一个启用了“运行shared Runners”的项目执行作业。通过Settings > CI/CD下进行设置。
如果你是GitLab实例管理员的话,你可以注册一个 Shared Runner
- 在 admin/runners 页面获取shared-Runner token
2.3.2 注册 Runner
基于 Shell 注册
# 注册sudo gitlab-runner register# 输出Runtime platform arch=amd64 os=linux pid=31237 revision=21cb397c version=13.0.1Running in system-mode.# 指定 GitLab 实例 URLPlease enter the gitlab-ci coordinator URL (e.g. https://gitlab.com/):https://xxx.gitlab.com/# 输入注册令牌(从项目-设置-CI/CD 设置-Runners 那里拷贝)Please enter the gitlab-ci token for this runner:JhXh7o********yDXATd# 输入描述Please enter the gitlab-ci description for this runner:xxxxx description.# 输入关联标签Please enter the gitlab-ci tags for this runner (comma separated):feWhether to run untagged builds [true/false]:falseWhether to lock Runner to current project [true/false]:false# 选择执行环境,这里选择的是 shellPlease enter the executor: virtualbox, docker-ssh+machine, kubernetes, parallels, shell, ssh, docker+machine, custom, docker, docker-ssh:shell# 输出Runner registered successfully. Feel free to start it, but if it\'s running already the config should be automatically reloaded!
基于 Docker 注册
docker run --rm -it -v /srv/gitlab-runner/config:/etc/gitlab-runner gitlab/gitlab-runner register
注册内容如下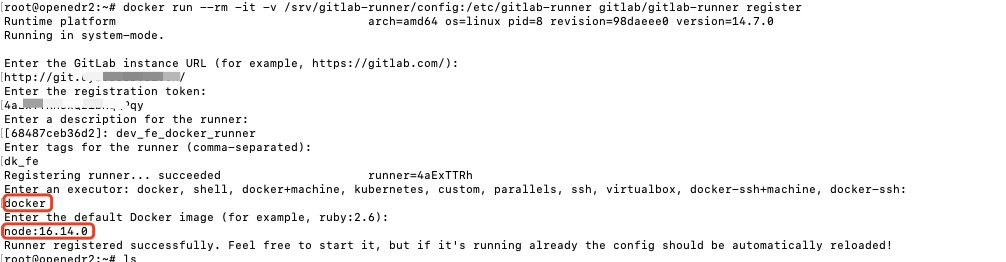
查看 Runner
注册完 Runner 后,返回 CI / CD Settings 页面,现在应该能看到项目关联的 Runner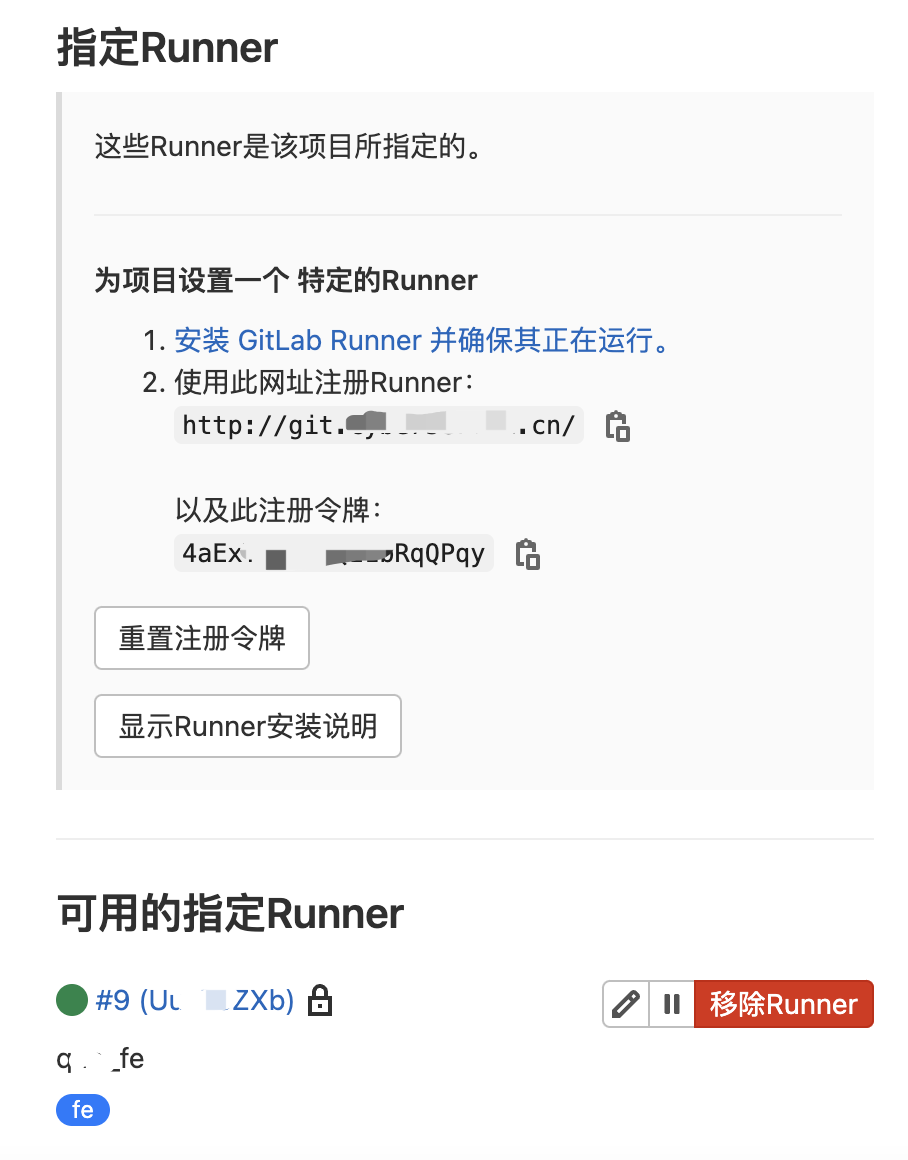
注意:
事项1: 运行未标记的作业
如果你设置了运行未标记的作业为否,那你需要在gitlab-ci.yml文件中指定你要使用 runner 的 tag,才能运行对应的 runner,否则你任务可能一直在 pending 状态,找不到 runner 执行。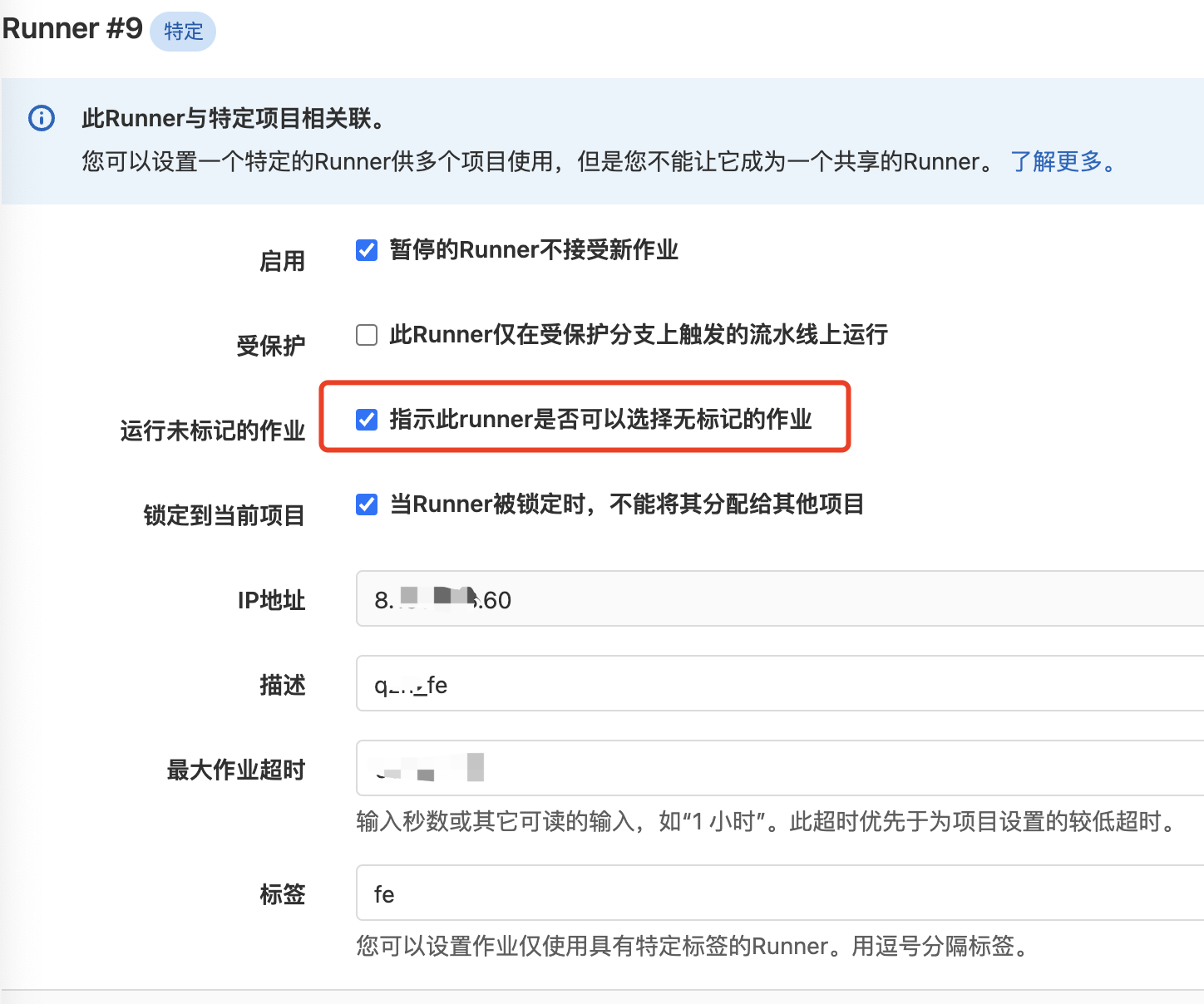
事项2:部署 Docker 容器连接错误问题
基于 Docker 部署的 Gitlab Runner 容器在部署 Docker 容器时可能会遇到一个连接错误问题: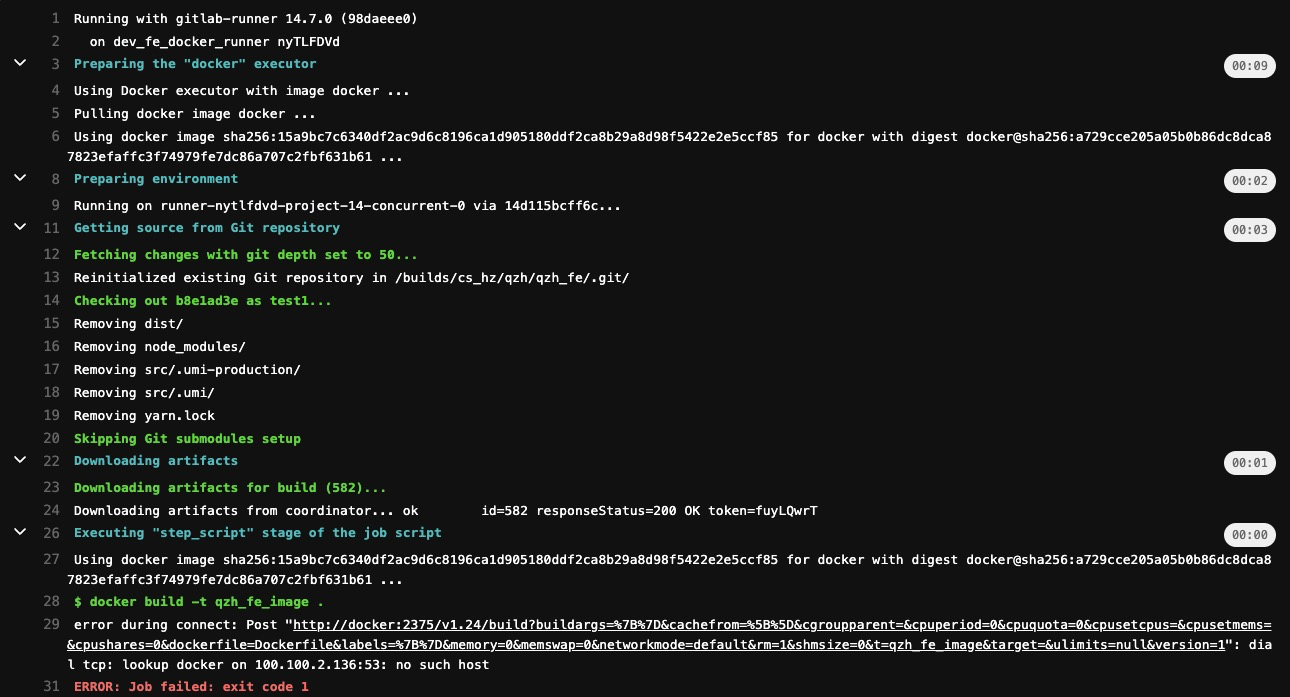
针对这一情况,可以修改config.toml文件。
- 登录到 Gitlab Runner 容器中,命令如下:
docker exec -it 容器ID bash 若容器中没有 vim,则需安装下vim, 命令如下:
apt-get updateapt-get install vim
修改
config.toml文件,添加如下内容:

三、配置 gitlab-ci.yml
3.1 配置gitlab-ci.yml
开发环境的gitlab-ci.yml配置如下:
image: docker:stablevariables:ROBOT_URL: https://open.feishu.cn/open-apis/bot/v2/hook/e2451a7b-xxxxxxxxxxxxxxservices:# Docker in Docker- docker:dindbefore_script:- docker infostages:- build- deploy# 开发环境构建build:stage: buildimage: node:16.14.0timeout: 1 hourtags:- dk_febefore_script:- echo "====Start===="- node -v- npm -v- yarn -v# 缓存时的上传也会非常耗时# cache:# key:# files:# # 根据文件计算SHA校验和# - package.json# paths:# # 指定需要被缓存的文件路径# - node_modules/script:- echo "====开始构建===="- yarn --verbose- yarn run build- echo "====结束构建===="only:# 只有dev开头的分支才会执行- /^dev.*$/artifacts:expire_in: 1 daypaths:- dist # 发送dist目录下的所有文件# 开发环境部署deploy:# image: dockerstage: deploytags:- dk_fevariables:ROBOT_DATA: '{"msg_type":"text","content":{"text":"前端开发环境部署成功,请开发同学回归功能:http://8.xxx.xxx.60:4080/"}}'before_script:# 解决找不到 curl 命令问题- apk add --update curl && rm -rf /var/cache/apk/*script:- if [ $(docker ps -aq --filter name=qzh-fe-container) ]; then docker rm -f qzh-fe-container;fi# 删除旧镜像,创建新镜像- docker rmi qzh_fe_image- docker build -t qzh_fe_image .- docker run -d -p 4080:4080 --name qzh-fe-container qzh_fe_image- curl -X POST -H "Content-Type:application/json" -d "$ROBOT_DATA" "$ROBOT_URL"only:# 只有dev开头的分支才会执行- /^dev.*$/
完成部署后,通过 curl 工具给飞书机器人发送构建成功消息。
注意:
问题1:日志较大报错 “Job’s log exceeded limit of 4194304bytes.”
答:修改 gitlab runner 配置config.toml。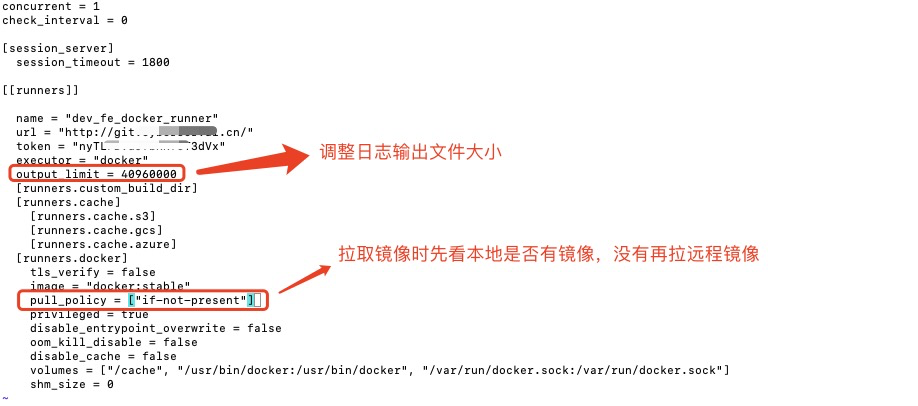
3.2 配置参数详解
script
script 是作业中唯一必须的关键字参数,是运行器需要执行的脚本,如:
build1:script:- echo "Do your build here"- uname -a
表示build1作业需要执行的命令是输出”Do your build here”。
image
默认在注册 runner 的时候需要填写一个基础的镜像,请记住一点只要使用执行器为 docker 类型的 runner 所有的操作运行都会在容器中运行。 如果全局指定了images 则所有作业使用此image创建容器并在其中运行。 全局未指定image,再次查看job中是否有指定,如果有此job按照指定镜像创建容器并运行,没有则使用注册runner时指定的默认镜像。
services
工作期间运行的另一个 Docker 映像,并 link 到 image 关键字定义的 Docker 映像。这样,您就可以在构建期间访问服务映像.
服务映像可以运行任何应用程序,但是最常见的用例是运行数据库容器,例如mysql 。与每次安装项目时都安装mysql相比,使用现有映像并将其作为附加容器运行更容易,更快捷。
services:- name: mysql:latestalias: mysql-1
before_script
before_script 用于定义在所有作业之前需要执行的命令,比如更新代码、安装依赖、打印调试信息之类的事情。
示例:
before_script:- echo "Before script section"- echo "For example you might run an update here or install a build dependency"- echo "Or perhaps you might print out some debugging details"
after_script
after_script 用于定义在所有作业(即使失败)之后需要执行的命令,比如清空工作空间。
示例:
after_script:- echo "After script section"- echo "For example you might do some cleanup here"
重要:
- before_script和script在一个上下文中是串行执行的,after_script是独立执行的,即after_script与before_script/script的上下文环境不同。
- after_script会将当前工作目录设置为默认值。
- 由于after_script是分离的上下文,在after_script中无法看到在before_script和script中所做的修改:
- 在before_script和script中的命名别名、导出变量,对after_script不可见;
- before_script和script在工作树之外安装的软件,对after_script不可见。
- 你可以在作业中定义before_script,after_script,也可以将其定义为顶级元素,定义为顶级元素将为每一个任务都执行相应阶段的脚本或命令。作业级会覆盖全局级的定义。
示例:
before_script:- echo "Before script section"- echo "For example you might run an update here or install a build dependency"- echo "Or perhaps you might print out some debugging details"after_script:- echo "After script section"- echo "For example you might do some cleanup here"build1:stage: build# 会覆盖上面的定义before_script:- echo "Before script in build stage that overwrited the globally defined before_script"- echo "Install cloc:A tool to count lines of code in various languages from a given directory."- yum install cloc -yafter_script:- echo "After script in build stage that overwrited the globally defined after_script"- cloc --version- cloc .script:- echo "Do your build here"- cloc --version- cloc .tags:- bluelog
将修改上传提交,查看作业build1的控制台输出: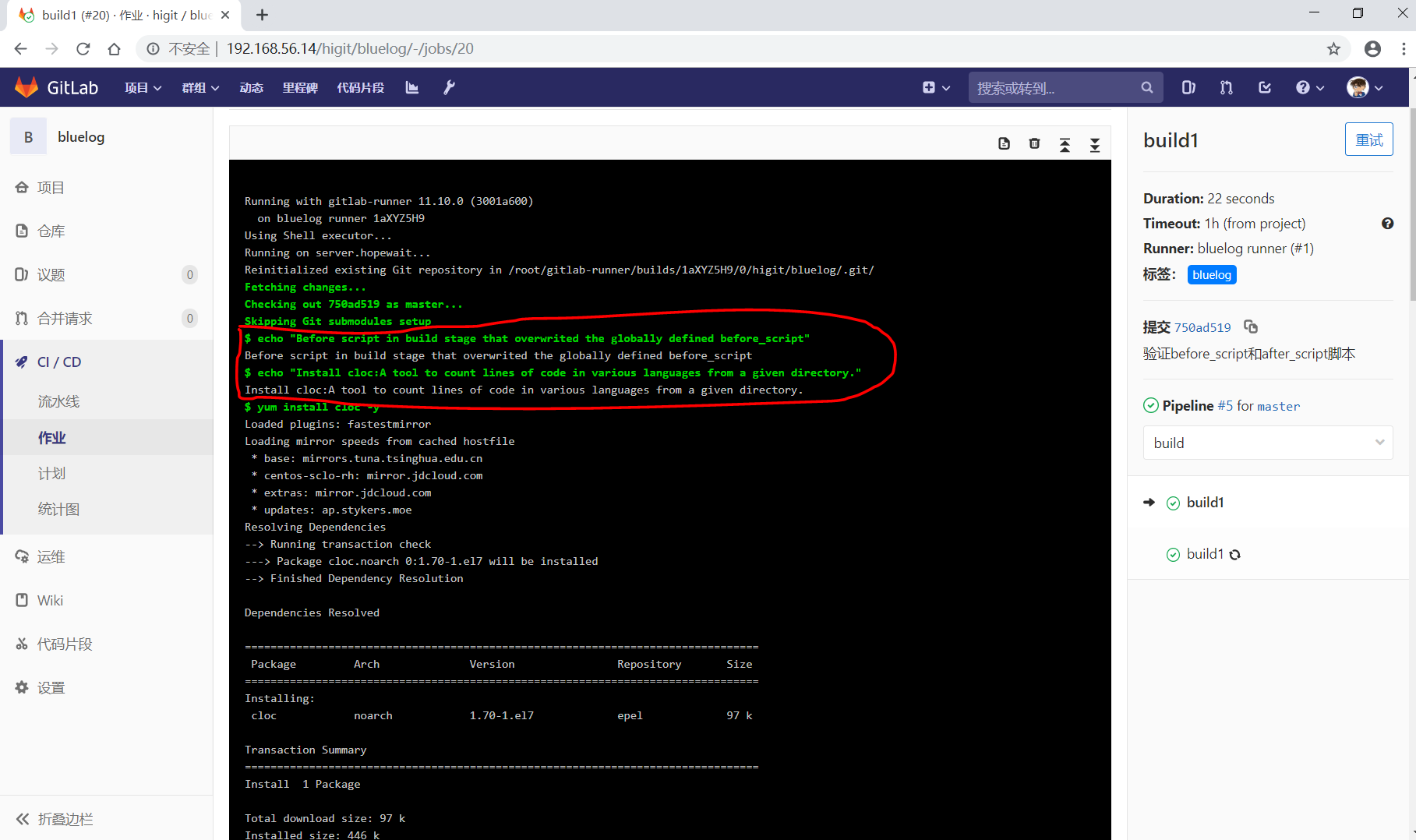
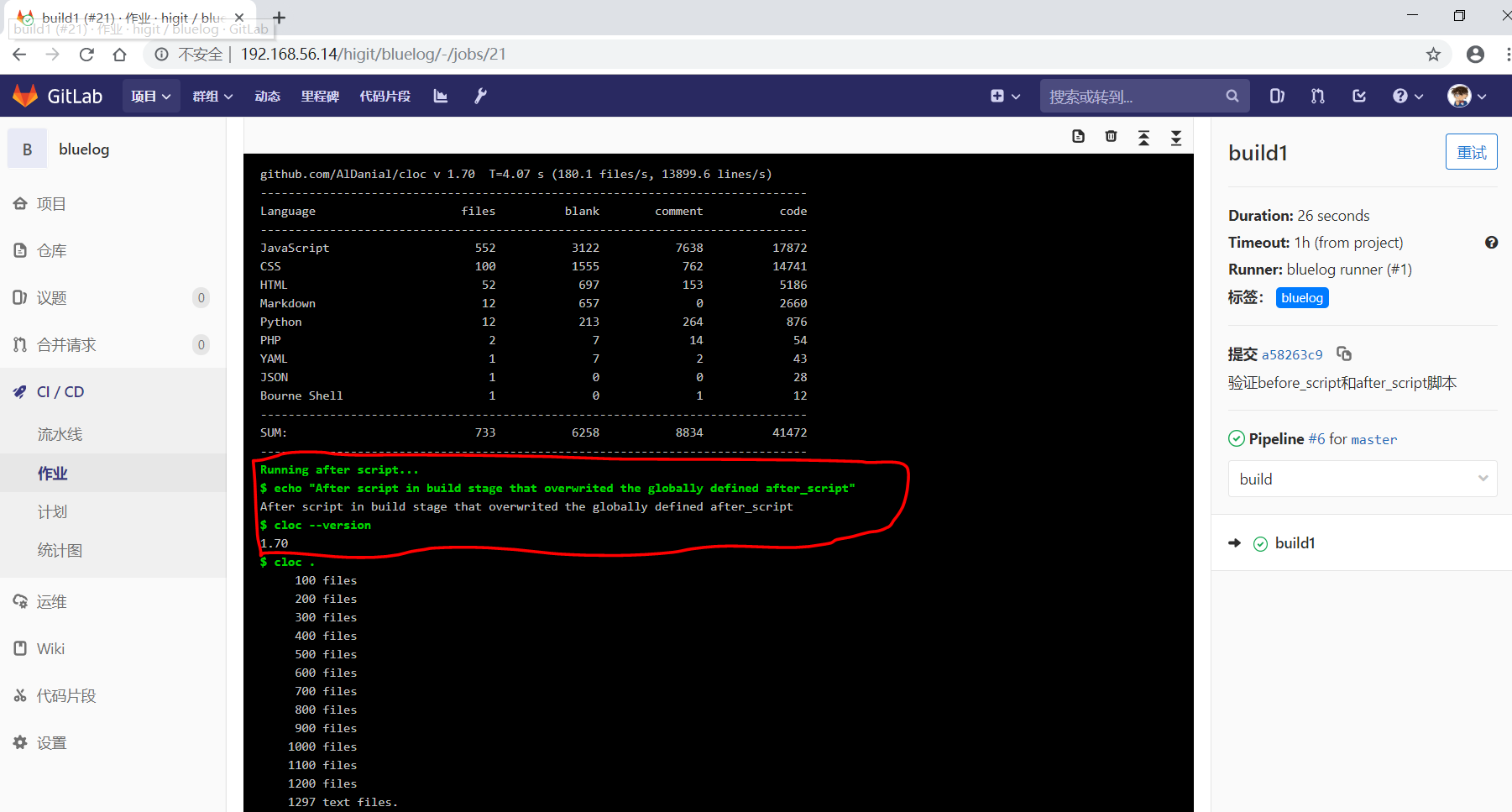
可以发现build1作业的 before_script 和 after_script 将全局的 before_script 和 after_script 覆盖了。
stages
stages 定义流水线全局可使用的阶段,阶段允许有灵活的多级管道,阶段元素的排序定义了作业执行的顺序。
- 相同 stage 阶段的作业并行运行。
- 默认情况下,上一阶段的作业全部运行成功后才执行下一阶段的作业。
- 默认有三个阶段, build 、test 、deploy 三个阶段,即 构建 、测试 、部署 。
- 如果一个作业未定义 stage 阶段,则作业使用 test 测试阶段。
- 默认情况下,任何一个前置的作业失败了,commit提交会标记为failed并且下一个stages的作业都不会执行。
stage
stage 定义流水线中每个作业所处的阶段,处于相同阶段的作业并行执行。
示例: ```yamlThis file is a template, and might need editing before it works on your project.
see https://docs.gitlab.com/ce/ci/yaml/README.html for all available options
before_script:
- echo “Before script section”
- echo “For example you might run an update here or install a build dependency”
- echo “Or perhaps you might print out some debugging details”
after_script:
- echo “After script section”
- echo “For example you might do some cleanup here”
stages:
- build
- code_check
- test
- deploy
build1: stage: build before_script:
- echo "Before script in build stage that overwrited the globally defined before_script"- echo "Install cloc:A tool to count lines of code in various languages from a given directory."- yum install cloc -y
after_script:
- echo "After script in build stage that overwrited the globally defined after_script"- cloc --version- cloc .
script:
- echo "Do your build here"- cloc --version- cloc .
tags:
- bluelog
find Bugs: stage: code_check script:
- echo "Use Flake8 to check python code"- pip install flake8- flake8 --version- flake8 .
tags:
- bluelog
处于相同的 stage 并行执行
test1: stage: test script:
- echo "Do a test here"- echo "For example run a test suite"
tags:
- bluelog
test2: stage: test script:
- echo "Do another parallel test here"- echo "For example run a lint test"
tags:
- bluelog
我们增加一个 code_check 阶段,该阶段有一个作业 find Bugs ,该作业主要是先安装Flake8,然后使用Flake8对Python代码进行规范检查。<br />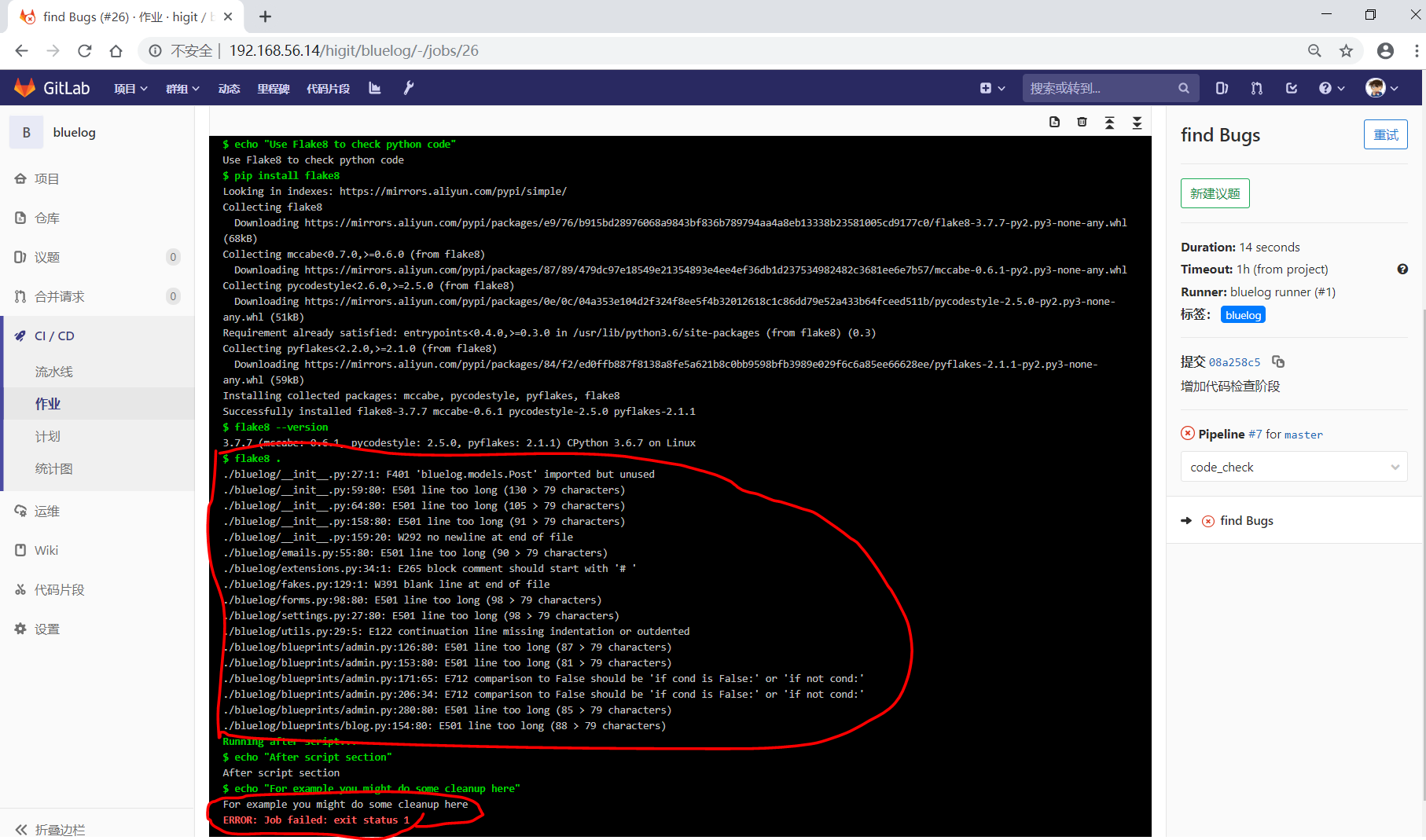<br />由于Flake8检查到了Python代码中的缺陷,导致find Bugs作业失败!这样可以控制开发人员提交有坏味道的代码到仓库中。另外,在上一个流水线中,Test阶段的作业test1和test2是**并行执行的**,如下图所示:<br />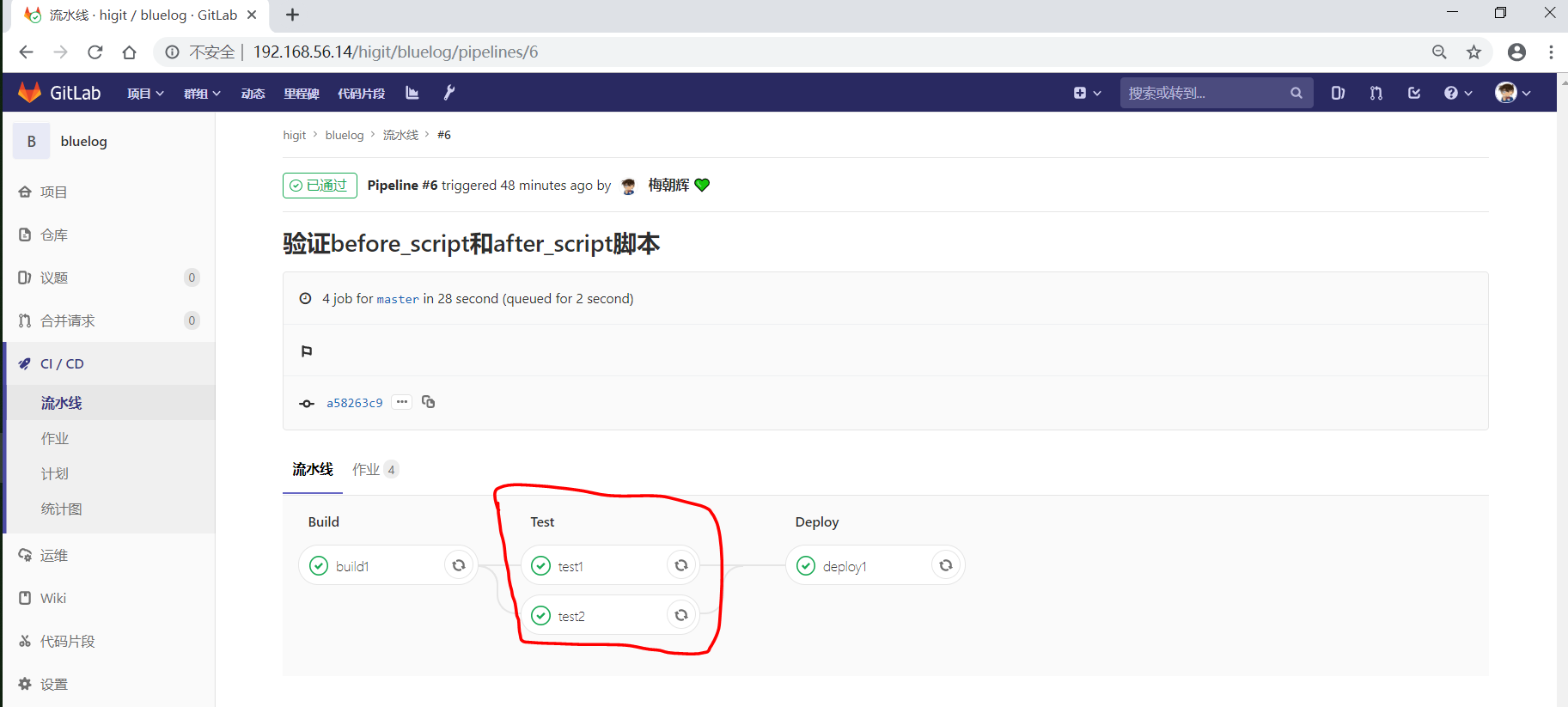<br />本次(pipeline #7)流水线由于在作业 find Bugs 检查不通过,导致整个流水线运行失败,后续的作业不会执行: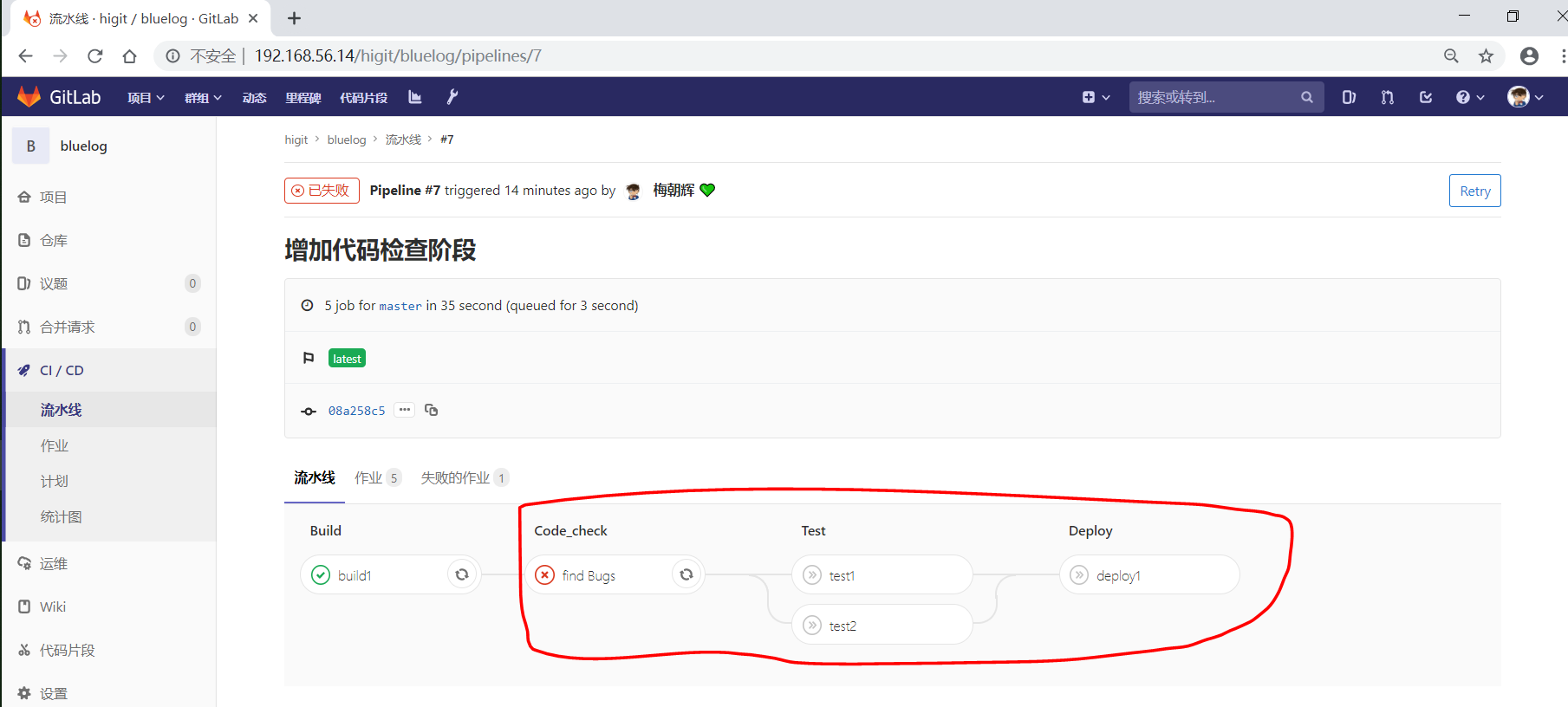<br />**注意:**<br />默认情况下,GitLab Runner 运行器**每次只执行一个作业**,只有当满足以下条件之一时,才会真正的并行执行:- 作业运行在不同的运行器上;- 你修改了运行器的 concurrent 设置,默认情况下 concurrent = 1 。<a name="trPSU"></a>#### [only 和 except](https://meigit.readthedocs.io/en/latest/gitlab_ci_.gitlab-ci.yml_detail.html#id47)only 和 except 用于在创建作业时对作业的限制策略。- only 定义了**哪些分支或标签(branches and tags)的作业**会运行- except 定义了哪些分支或标签(branches and tags)的作业不会运行下面是策略规则:- only 和 except 可同时使用,如果在一个作业中同时定义了 only 和 except ,则同时 only except 进行过滤(注意,不是忽略 except 条件) 。- only 和 except 可以使用正则表达式。- only 和 except 允许指定用于过滤forks作业的存储库路径。- only 和 except 中可以使用特殊的关键字,如 branches 、 tags 、 api 、 external 、 pipelines 、 pushes 、 schedules 、 triggers 、 web 、 merge_requests 、 chats 等。only 和 except 中可以使用特殊的关键字:| 关键字 | 描述释义 || --- | --- || branches | 当一个分支被push上来 || tags | 当一个打了tag标记的Release被提交时 || api | 当一个pipline被第二个piplines api所触发调起(不是触发器API) || external | 当使用了GitLab以外的外部CI服务,如Jenkins || pipelines | 针对多项目触发器而言,当使用CI_JOB_TOKEN, 并使用gitlab所提供的api创建多个pipelines的时候 || pushes | 当pipeline被用户的git push操作所触发的时候 || schedules | 针对预定好的pipline计划而言(每日构建一类) || triggers | 用触发器token创建piplines的时候 || web | 在GitLab WEB页面上Pipelines标签页下,按下run pipline的时候 || merge_requests | 当合并请求创建或更新的时候 || chats | 当使用GitLab ChatOps 创建作业的时候 |在下面这个例子中,job将只会运行以 issue- 开始的refs(分支),然而except中指定分支不能执行,所以这个job将不会执行:```yamljob:# use regexponly:- /^issue-.*$/# use special keywordexcept:- branches
匹配模式默认是大小写敏感的(case-sensitive),使用 i 标志,如 /pattern/i 可以使匹配模式大小写不敏感:
job:# use regexponly:- /^issue-.*$/i# use special keywordexcept:- branches
下面这个示例,仅当指定标记的tags的refs引用,或者通过API触发器的构建、或者流水线计划调度的构建才会运行:
job:# use special keywordsonly:- tags- triggers- schedules
仓库的路径(repository path)只能用于父级仓库执行作业,不能用于forks:
job:only:- branches@gitlab-org/gitlab-ceexcept:- master@gitlab-org/gitlab-ce- /^release/.*$/@gitlab-org/gitlab-ce
上面这个例子,将会在所有分支执行,但不会在 master主干以及以release/开头的分支上执行。
- 当一个作业没有定义 only 规则时,其默认为 only: [‘branches’, ‘tags’] 。
- 如果一个作业没有定义 except 规则时,则默认 except 规则为空。
注意:
关于正则表达式使用的说明:
- 因为 @ 用于表示ref的存储库路径的开头,所以在正则表达式中匹配包含 @ 字符的ref名称需要使用十六进制字符代码 \x40 。
- 仅标签和分支名称才能使用正则表达式匹配,仓库路径按字面意义匹配。
- 如果使用正则表达式匹配标签或分支名称,则匹配模式的整个引用部分都是正则表达式。
- 正则表达式必须以 / 开头和结尾,即 /regular expressions/ ,因此, issue-/.*/ 不会匹配以 issue- 开头的标签或分支。
- 可以在正则表达式中使用锚点 ^$ ,用来匹配开头或结尾,如 /^issue-.*$/ 与 /^issue-/ 等价, 但 /issue/ 却可以匹配名称为 severe-issues 的分支,所以正则表达式的使用要谨慎!
tags
tags 关键字用于指定 GitLab Runner 运行器使用哪一个运行器来执行作业。
下面这个例子中,只有运行器注册时定义了 ruby 和 postgres 两个标签的运行器才能执行作业:
job:tags:- ruby- postgres
而我们的 bluelog 项目中,所有的作业都是使用的是标签为 bluelog 的运行器:
find Bugs:stage: code_checkonly:- triggersscript:- echo "Use Flake8 to check python code"- pip install flake8- flake8 --version# - flake8 .tags:- bluelog
运行器标签可用于定义不同平台上运行的作业,如 Mac OS X Runner 使用 osx 标签, Windows Runner 使用 windows 标签,而 Linux Runner 使用 linux 标签:
windows job:stage:- buildtags:- windowsscript:- echo Hello, %USERNAME%!osx job:stage:- buildtags:- osxscript:- echo "Hello, $USER!"linux job:stage:- buildtags:- linuxscript:- echo "Hello, $USER!"
cache
- GitLab Runner v0.7.0 引入 cache 缓存机制。
- cache 缓存机制,可以在全局设置或者每个作业中设置。
- 从 GitLab 9.0 开始, cache 缓存机制,可以在不同的的流水线或作业之间共享数据。
- 从 GitLab 9.2 开始, 在 artifacts 工件之前恢复缓存。
- cache 缓存机制用于指定一系列的文件或文件夹在不同的流水线或作业之间共享数据,仅能使用项目工作空间( project workspace )中的路径作为缓存的路径。
- 如果 cache 配置的路径是作业工作空间外部,则说明配置是全局的缓存,所有作业共享。
- 访问 Cache dependencies in GitLab CI/CD 文档来获取缓存是如何工作的以及好的实践实例的例子。
- cache 缓存机制的其他介绍请参考 https://docs.gitlab.com/ce/ci/yaml/README.html#cache 。
cache 缓存
用来指定需要在 job 之间缓存的文件或目录。只能使用该项目工作空间内的路径。不要使用缓存在阶段之间传递工件,因为缓存旨在存储编译项目所需的运行时依赖项。
如果在job范围之外定义了cache ,则意味着它是全局设置,所有job都将使用该定义。如果未全局定义或未按job定义则禁用该功能。
cache:paths
使用paths指令选择要缓存的文件或目录,路径是相对于项目目录,不能直接链接到项目目录之外。$CI_PROJECT_DIR项目目录
在 job build 中定义缓存,将会缓存 target 目录下的所有 .jar文件。
build:script: testcache:paths:- target/*.jar
当在全局定义了cache:paths会被 job 中覆盖。以下实例将缓存binaries目录。
cache:paths:- my/filesbuild:script: echo "hello"cache:key: buildpaths:- target/
由于缓存是在 job 之间共享的,如果不同的 job 使用不同的路径就出现了缓存覆盖的问题。如何让不同的 job 缓存不同的 cache 呢?设置不同的 cache:key。
cache:key 缓存标记
为缓存做个标记,可以配置job、分支为 key 来实现分支、作业特定的缓存。为不同 job 定义了不同的 cache:key 时, 会为每个 job 分配一个独立的 cache。cache:key变量可以使用任何预定义变量,默认default ,从GitLab 9.0 开始,默认情况下所有内容都在管道和作业之间共享。
按照分支设置缓存
cache:key: ${CI_COMMIT_REF_SLUG}
files:文件发生变化自动重新生成缓存(files最多指定两个文件),提交的时候检查指定的文件。
根据指定的文件生成密钥计算SHA校验和,如果文件未改变值为default。
cache:key:files:- Gemfile.lock- package.jsonpaths:- vendor/ruby- node_modules
prefix: 允许给定prefix的值与指定文件生成的秘钥组合。
在这里定义了全局的cache,如果文件发生变化则值为 rspec-xxx111111111222222 ,未发生变化为rspec-default。
cache:key:files:- Gemfile.lock- package.jsonpaths:- vendor/ruby- node_modules
例如,添加 $CI_JOB_NAME prefix将使密钥看起来像: rspec-feef9576d21ee9b6a32e30c5c79d0a0ceb68d1e5 ,并且作业缓存在不同分支之间共享,如果分支更改了 Gemfile.lock ,则该分支将为cache:key:files具有新的SHA校验和. 将生成一个新的缓存密钥,并为该密钥创建一个新的缓存. 如果Gemfile.lock未发生变化 ,则将前缀添加default ,因此示例中的键为rspec-default 。
cache:policy 策略
默认:在执行开始时下载文件,并在结束时重新上传文件。称为 “pull-push” 缓存策略.
policy: pull跳过下载步骤policy: push跳过上传步骤
artifacts
- artifacts 用于指定在 job 成功、失败、或者一直等状态下时,一系列的文件或文件夹附加到 job 中。artifacts 可以称为工件或者归档文件。
- job 完成后,工件被发送到GitLab,可以在GitLab Web界面下载。
- 默认情况下,只有成功的作业才会生成工件。
- 并不是所有的 executor 执行器都支持工件。
- 工件的详细介绍可参考 Introduction to job artifacts
artifacts:paths
artifacts:paths用于指定哪些文件或文件夹会被打包成工件,仅仅项目工作空间( project workspace )的路径可以使用。- 要在不同作业间传递工作,请参数 dependencies
下面示例,将目录 binaries/ 和文件 .config 打包成工件:
artifacts:paths:- binaries/- .config
要禁用工件传递,请使用空依赖关系定义作业:
job:stage: buildscript: make builddependencies: []
你可以仅为打标记的release发布版本创建工作,这样可以避免临时构建产生大量的存储需求:
default-job:script:- mvn test -Uexcept:- tagsrelease-job:script:- mvn package -Uartifacts:paths:- target/*.waronly:- tags
上面的示例中,default-job 作业不会在打标记的release发布版本中执行,而 release-job 只会在打标记的release发布版本执行,并且将 target/*.war 打包成工件以供下载。
artifacts:when
artifacts:when 用于在作业失败时或者忽略失败时上传工件。artifacts:when可以设置以下值:
- on_success ,默认值,当作业成功上传工件。
- on_failure ,当作业失败上传工件。
- always ,无论作业是否成功一直上传工件。
当作业失败时,上传工件:
job:artifacts:when: on_failure
artifacts:expire_in
artifacts:expire_in用于设置工件的过期时间。- 你可以点击界面上的 Keep 保持按钮,永久保存工件。
- 工件到期后,默认情况下每小时删除一次工件(通过cron作业),并且后续不能再访问该工件。
- 工件默认有效期是30天,可以通过
Admin area –> Settings –> Continuous Integration and Deployment设置默认的有效性时间。 - 如果你不提供时间单位的话,工作有效性的时间是以秒为单位的时间,下面是一些示例:
- ‘42’
- ‘3 mins 4 sec’
- ‘2 hrs 20 min’
- ‘2h20min’
- ‘6 mos 1 day’
- ‘47 yrs 6 mos and 4d’
- ‘3 weeks and 2 days’
下面示例中工件有效期为一周:
job:artifacts:expire_in: 1 week
dependencies
- dependencies 依赖关键字应该与 artifacts 工件关键字联合使用,允许你在不同 job 间传递工件。
- 默认情况下,会传递所有本 job 之前阶段的所有工件。
- 需要在 job 上下文中定义 dependencies 依赖关键字,并指出所有需要使用的前序工件的作业名称列表。 作业列表中不能使用该作业后的作业名称 。
- 定义空的依赖项,将下不会下载任何工件。
- 使用依赖项不会考虑前面作业的运行状态。
示例:
build:osx:stage: buildscript: make build:osxartifacts:paths:- binaries/build:linux:stage: buildscript: make build:linuxartifacts:paths:- binaries/test:osx:stage: testscript: make test:osxdependencies:- build:osxtest:linux:stage: testscript: make test:linuxdependencies:- build:linuxdeploy:stage: deployscript: make deploy
上面示例中, build:osx 和 build:linux 两个 job 定义了工件, test:osx 作业执行时,将会下载并解压 build:osx 的工件内容。相应的, test:linux 也会获取 build:linux 的工件。 deploy 作业会下载全部工件。
Attention
如果作为依赖的作业的工件过期或者被删除,那么依赖这个作业的作业将会失败。
四、部署测试环境
测试环境场景:将构建文件上传到远程服务器上
ssh 登录服务器通常有两种方式:用户名密码登录和用户公私钥登录。使用用户名密码登录每次都要输入密码,相当麻烦,而使用用户公私钥登录则可以避免这个问题。
- 本地生成公钥和私钥
ssh-keygen -t rsa -C ‘your email@xxx.com’
- 复制公钥至服务器
使用 scp 命令将本地的公钥文件 id_rsa.pub 复制到需要连接的服务器:
scp ~/.ssh/id_rsa.pub <用户名>@
:/home/id_rsa.pub
如果修改了 ssh 默认端口,需要加上端口信息:
scp -P <端口号> ~/.ssh/id_rsa.pub <用户名>@
:/home/id_rsa.pub
登录服务器,把公钥追加到服务器 ssh 认证文件中:
cat /home/id_rsa.pub >> ~/.ssh/authorized_keys
这时候在本地终端中使用用户名和ip登录就不需要密码了:
ssh <用户名>@
- 使用 scp 上传文件到服务器指定目录
scp -r ./dist <用户名>@
:/home/xxx_fe
注意:scp 拷贝时如果报 its a directory 错误,则需在服务器端手动创建xxx_fe目录,因为 scp 命令不会自动创建目录。
- 配置
**gitlab-ci.yml**文件
由于QA环境,后端已提供网关服务,只需将静态文件拷贝到相应目录下即可。
image: docker:stablevariables:QA_SERVER: $QA_SERVERQA_USER: $QA_USERSSH_PRIVATE_KEY: $SSH_PRIVATE_KEYROBOT_URL: https://open.feishu.cn/open-apis/bot/v2/hook/e2451a7b-xxxxxxxxxservices:# Docker in Docker- docker:dindbefore_script:- docker infostages:- build- deploy# QA环境构建qa_build:stage: buildimage: node:16.14.0timeout: 1 hourtags:- dk_febefore_script:- echo "====Start===="- node -v- npm -v- yarn -vcache:key:files:# 根据文件计算SHA校验和- package.jsonpaths:# 指定需要被缓存的文件路径- node_modules/script:- echo "====开始构建===="- yarn --verbose- yarn run build- echo "====结束构建===="only:# 只有qa开头的分支才会执行- /^qa.*$/artifacts:expire_in: 1 daypaths:- dist # 发送dist目录下的所有文件# 测试环境部署qa_deploy:stage: deploytags:- dk_fevariables:ROBOT_DATA: '{"msg_type":"text","content":{"text":"前端测试环境部署成功,请测试同学回归功能:http://39.xxx.xx.213"}}'before_script:# 若没有 ssh-agent,则安装 SSH- 'which ssh-agent || (apt-get update -y && apt-get install openssh-client -y)'# 运行 ssh-agent,添加私钥,以便无密码登录服务器- eval $(ssh-agent -s)- echo "$SSH_PRIVATE_KEY" | tr -d '\r' | ssh-add - > /dev/null- mkdir -p ~/.ssh- chmod 700 ~/.ssh- ssh-keyscan "$QA_SERVER" > ~/.ssh/known_hosts- chmod 644 ~/.ssh/known_hosts# 解决找不到 curl 命令问题- apk add --update curl && rm -rf /var/cache/apk/*script:- echo "====QA部署===="- ssh "$QA_USER"@"$QA_SERVER" 'rm -rf /opt/openedr/compose/armor/gateway/nginx/data/front/qzh/*'- scp -r ./dist/* "$QA_USER"@"$QA_SERVER":/opt/openedr/compose/armor/gateway/nginx/data/front/qzh/- curl -X POST -H "Content-Type:application/json" -d "$ROBOT_DATA" "$ROBOT_URL"only:- qa
注意:
问题1: SSH 添加密钥失败,报如下错误:“SSH key invalid format”.
答:可将变量设置成非受保护模式,如下所示。
五、定期清理磁盘空间
磁盘过满的时候,也会影响性能,当磁盘空间不足时,甚至会使 CI 服务直接停止工作。所以需要加一些清理脚本。
在使用 Docker executor 的时候,磁盘的占用主要是已经不再使用的 Docker image,以及一些 Docker volume。
要定期清理它们,可以使用下面的命令:
#!/bin/bash# 清理镜像,保留一天docker system prune -f --filter "until=$((1*24))h"docker volume prune -f
把这个脚本随便起个名字,加上可执行权限,然后复制到 /etc/cron.daily 或 /etc/cron.hourly 等目录中,实现每天清理一次或每小时清理一次的效果。

若有收获,就点个赞吧
0 人点赞
