原文链接
本文要回答一个很重要的问题:函数式编程有什么用?
目前,主流的编程语言都不是函数式的,已经能够满足需求。为何还要学函数式编程呢,只为了多理解一些新奇的概念?
一个网友说:
“函数式编程有什么优势呢?” “我感觉,这种写法可能会令人头痛吧。”
很长一段时间,我根本不知道从何入手,如何将它用于实际项目?直到有一天,我学到了 Pointfree 这个概念,顿时豁然开朗,原来应该这样用!
我现在觉得,Pointfree 就是如何使用函数式编程的答案。
一、程序的本质
为了理解 Pointfree,请大家先想一想,什么是程序?
上图是一个编程任务,左侧是数据输入(input),中间是一系列的运算步骤,对数据进行加工,右侧是最后的数据输出(output)。一个或多个这样的任务,就组成了程序。
输入和输出(统称为 I/O)与键盘、屏幕、文件、数据库等相关,这些跟本文无关。这里的关键是,中间的运算部分不能有 I/O 操作,应该是纯运算,即通过纯粹的数学运算来求值。否则,就应该拆分出另一个任务。
I/O 操作往往有现成命令,大多数时候,编程主要就是写中间的那部分运算逻辑。现在,主流写法是过程式编程和面向对象编程,但是我觉得,最合适纯运算的是函数式编程。
二、函数的拆分与合成
上面那张图中,运算过程可以用一个函数fn表示。
fn的类型如下。
fn :: a -> b
上面的式子表示,函数fn的输入是数据a,输出是数据b。
如果运算比较复杂,通常需要将fn拆分成多个函数。
f1、f2、f3的类型如下。
f1 :: a -> mf2 :: m -> nf3 :: n -> b
上面的式子中,输入的数据还是a,输出的数据还是b,但是多了两个中间值m和n。
我们可以把整个运算过程,想象成一根水管(pipe),数据从这头进去,那头出来。
函数的拆分,无非就是将一根水管拆成了三根。
进去的数据还是a,出来的数据还是b。fn与f1、f2、f3的关系如下。
fn = R.pipe(f1, f2, f3);
上面代码中,我用到了 Ramda 函数库的pipe方法,将三个函数合成为一个。Ramda 是一个非常有用的库,后面的例子都会使用它,如果你还不了解,可以先读一下教程。
三、Pointfree 的概念
fn = R.pipe(f1, f2, f3);
这个公式说明,如果先定义f1、f2、f3,就可以算出fn。整个过程,根本不需要知道a或b。
也就是说,我们完全可以把数据处理的过程,定义成一种与参数无关的合成运算。不需要用到代表数据的那个参数,只要把一些简单的运算步骤合成在一起即可。
这就叫做 Pointfree:不使用所要处理的值,只合成运算过程。中文可以译作”无值”风格。
请看下面的例子。
var addOne = x => x + 1;var square = x => x * x;
上面是两个简单函数addOne和square。
把它们合成一个运算。
var addOneThenSquare = R.pipe(addOne, square);addOneThenSquare(2) // 9
上面代码中,addOneThenSquare是一个合成函数。定义它的时候,根本不需要提到要处理的值,这就是 Pointfree。
四、Pointfree 的本质
Pointfree 的本质就是使用一些通用的函数,组合出各种复杂运算。上层运算不要直接操作数据,而是通过底层函数去处理。这就要求,将一些常用的操作封装成函数。
比如,读取对象的role属性,不要直接写成obj.role,而是要把这个操作封装成函数。
var prop = (p, obj) => obj[p];var propRole = R.curry(prop)('role');
上面代码中,prop函数封装了读取操作。它需要两个参数p(属性名)和obj(对象)。这时,要把数据obj要放在最后一个参数,这是为了方便柯里化。函数propRole则是指定读取role属性,下面是它的用法(查看完整代码)。
var isWorker = s => s === 'worker';var getWorkers = R.filter(R.pipe(propRole, isWorker));var data = [{name: '张三', role: 'worker'},{name: '李四', role: 'worker'},{name: '王五', role: 'manager'},];getWorkers(data)// [// {"name": "张三", "role": "worker"},// {"name": "李四", "role": "worker"}// ]
上面代码中,data是传入的值,getWorkers是处理这个值的函数。定义getWorkers的时候,完全没有提到data,这就是 Pointfree。
简单说,Pointfree 就是运算过程抽象化,处理一个值,但是不提到这个值。这样做有很多好处,它能够让代码更清晰和简练,更符合语义,更容易复用,测试也变得轻而易举。
五、Pointfree 的示例一
下面,我们来看一个示例。
var str = 'Lorem ipsum dolor sit amet consectetur adipiscing elit';
上面是一个字符串,请问其中最长的单词有多少个字符?
我们先定义一些基本运算。
// 以空格分割单词var splitBySpace = s => s.split(' ');// 每个单词的长度var getLength = w => w.length;// 词的数组转换成长度的数组var getLengthArr = arr => R.map(getLength, arr);// 返回较大的数字var getBiggerNumber = (a, b) => a > b ? a : b;// 返回最大的一个数字var findBiggestNumber =arr => R.reduce(getBiggerNumber, 0, arr);
然后,把基本运算合成为一个函数(查看完整代码)。
var getLongestWordLength = R.pipe(splitBySpace,getLengthArr,findBiggestNumber);getLongestWordLength(str) // 11
可以看到,整个运算由三个步骤构成,每个步骤都有语义化的名称,非常的清晰。这就是 Pointfree 风格的优势。
Ramda 提供了很多现成的方法,可以直接使用这些方法,省得自己定义一些常用函数(查看完整代码)。
// 上面代码的另一种写法var getLongestWordLength = R.pipe(R.split(' '),R.map(R.length),R.reduce(R.max, 0));
六、Pointfree 示例二
最后,看一个实战的例子,拷贝自 Scott Sauyet 的文章《Favoring Curry》。那篇文章能帮助你深入理解柯里化,强烈推荐阅读。
下面是一段服务器返回的 JSON 数据。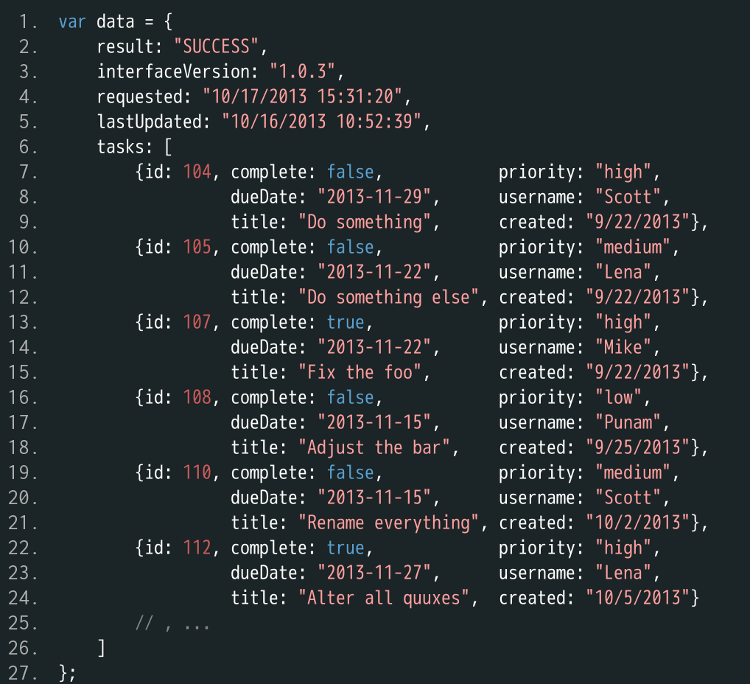
现在要求是,找到用户 Scott 的所有未完成任务,并按到期日期升序排列。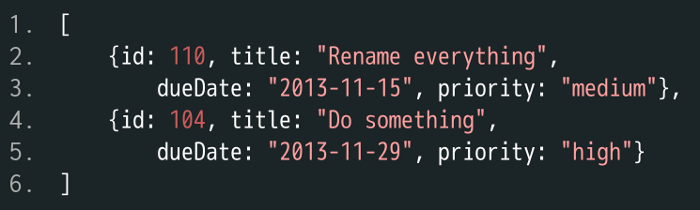
过程式编程的代码如下(查看完整代码)。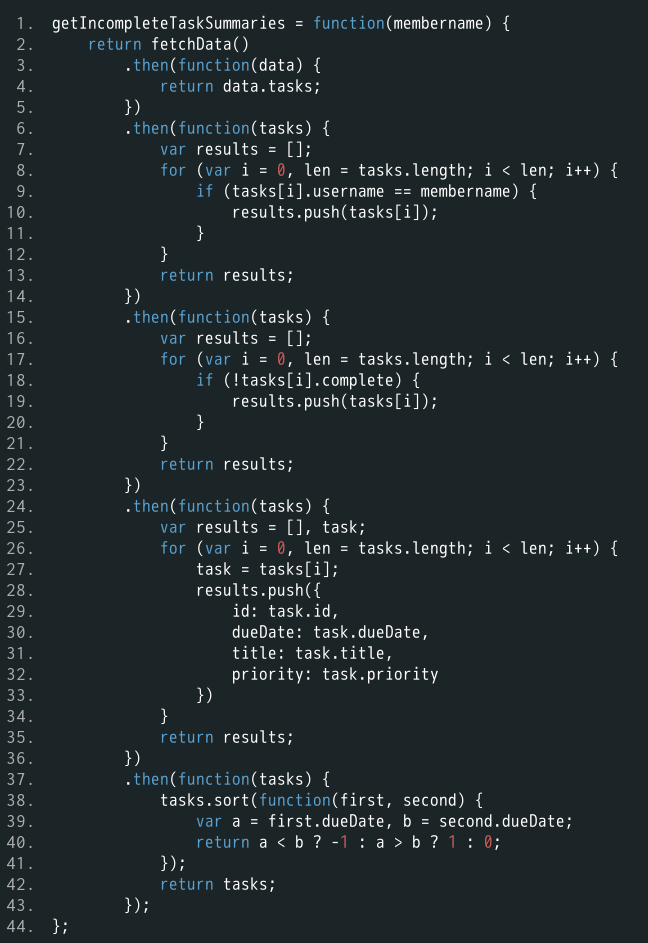
上面代码不易读,出错的可能性很大。
现在使用 Pointfree 风格改写(查看完整代码)。
var getIncompleteTaskSummaries = function(membername) {return fetchData().then(R.prop('tasks')).then(R.filter(R.propEq('username', membername))).then(R.reject(R.propEq('complete', true))).then(R.map(R.pick(['id', 'dueDate', 'title', 'priority']))).then(R.sortBy(R.prop('dueDate')));};
上面代码已经清晰很多了。
另一种写法是,把各个then里面的函数合成起来(查看完整代码)。
// 提取 tasks 属性var SelectTasks = R.prop('tasks');// 过滤出指定的用户var filterMember = member => R.filter(R.propEq('username', member));// 排除已经完成的任务var excludeCompletedTasks = R.reject(R.propEq('complete', true));// 选取指定属性var selectFields = R.map(R.pick(['id', 'dueDate', 'title', 'priority']));// 按照到期日期排序var sortByDueDate = R.sortBy(R.prop('dueDate'));// 合成函数var getIncompleteTaskSummaries = function(membername) {return fetchData().then(R.pipe(SelectTasks,filterMember(membername),excludeCompletedTasks,selectFields,sortByDueDate,));};
上面的代码跟过程式的写法一比较,孰优孰劣一目了然。
七、参考链接

若有收获,就点个赞吧
0 人点赞
