2.4Hive DQL: 数据查询语言
2.4.1 内置运算符
关系运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A = B |
所有基本类型 | 如果表达A等于表达B,结果TRUE ,否则FALSE。 |
| A != B |
所有基本类型 | 如果A不等于表达式B表达返回TRUE ,否则FALSE。 |
| A < B |
所有基本类型 | 如果表达式A小于表达式B为TRUE,否则FALSE。 |
| A <= B |
所有基本类型 | 如果表达式A小于或等于表达式B为TRUE,否则FALSE |
| A > B |
所有基本类型 | 如果表达式A大于表达式B为TRUE,否则FALSE。 |
| A >= B |
所有基本类型 | 如果表达式A大于或等于表达式B为TRUE,否则FALSE。 |
| A [NOT] BETWEEN B AND C |
基本数据类型 | 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且 小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可 达到相反的效果。 |
| 运算符 | 操作 | 描述 |
|---|---|---|
| A IS [NOT] NULL |
所有类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE, NOT 正好相反。 |
| A IN(数值1, 数值2) |
所有类型 | 如果A存在指定的数据中,则返回TRUE,反之返回FALSE |
| A [NOT] LIKE B |
字符串 | 如果A与B匹配的话,则返回TRUE;反之返回FALSE。%代表任意多个字符,代表一个字符 % |
| A RLIKE B |
字符串 | 如果A或B为NULL;如果A任何子字符串匹配Java正则表达式B;否则 FALSE。 |
| A REGEXP B |
字符串 | 等同于RLIKE. |
算术运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A + B | 所有数字类型 | A加B的结果 |
| A - B | 所有数字类型 | A减去B的结果 |
| A / B | 所有数字类型 | A除以B的结果 |
| A % B | 所有数字类型 | A除以B.产生的余数 |
逻辑运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A AND B | boolean | 如果A和B都是TRUE,否则FALSE。 |
| A && B | boolean | 类似于 A AND B. |
| A OR B | boolean | TRUE,如果A或B或两者都是TRUE,否则FALSE。 |
| A || B | boolean | 类似于 A OR B. |
| NOT A | boolean | TRUE,如果A是FALSE,否则FALSE。 |
| !A | boolean | 类似于 NOT A. |
复杂的运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A[n] |
A是一个数组,n是一个int | 它返回数组A的第n个元素,第一个元素的索引0。 |
| M[key] |
M 是一个 Map |
它返回对应于映射中关键字的值。 |
| S.x | S 是一个结构 | 它返回S的s字段 |
2.4.2 内置函数
数学函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| BIGINT DOUBLE | round(double a) round(double a, int d) | 返回double类型的整数值部分 (遵循四舍五入) 返回指定精度d的double类型 |
| BIGINT | floor(double a) | 返回等于或者小于该double变量的最大的整数 |
| BIGINT | ceil(double a) | 返回等于或者大于该double变量的最小的整数 |
| DOUBLE |
rand() rand(int seed) |
返回一个0到1范围内的随机数。如果指定种子seed, 则会等到一个稳定的随机数序列. |
| DOUBLE |
pow(double a, double p) | 返回a的p次幂 |
| DOUBLE | sqrt(double a) | 返回a的平方根 |
| DOUBLE INT | abs(double a) abs(int a) |
返回数值a的绝对值 |
日期函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| STRING |
from_unixtime(bigint unixtime[, string format]) | 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指 定时间的秒数) 到当前时区的时间格式 |
| BIGINT |
unix_timestamp() unix_timestamp(string date) unix_timestamp(string date, string pattern) | 获得当前时区的UNIX时间戳 转换格式为”yyyy-MM-dd HH:mm:ss”的日期到UNIX时间戳。如果转化失败,则返回0 转换pattern格式的日期到UNIX时间戳。如果转化失败,则返回0 |
| STRING |
to_date(string timestamp) | 返回日期时间字段中的日期部分 |
| INT |
year(string date) month (string date) day (string date) | 分别返回日期中的年 月 天 |
| INT |
hour (string date) minute (string date) second (string date) | 分别返回日期中的时 分 秒 |
| INT | weekofyear (string date) | 返回日期在当年的第几周 |
| INT |
datediff(string enddate, string startdate) | 返回结束日期减去开始日期的天数 日期有格式要求 yyyy-mm-dd hh:MM:ss 或 yyyy-mm-dd |
| STRING |
date_add(string startdate, int days) | 返回开始日期startdate增加days天后的日期 add_months(string startdate, int months) |
| STRING |
date_sub (string startdate, int days) | 返回开始日期startdate减少days天后的日期 |
条件判断函数
| 返回类型 | 签名 |
描述 |
|---|---|---|
| T |
if(boolean testCondition, T valueTrue, T valueFalseOrNull) | 当条件testCondition为TRUE时,返回 valueTrue;否则返回valueFalseOrNull |
| T |
coalesce(T v1, T v2, …) |
返回参数中的第一个非空值;如果所有值都为 NULL,那么返回NULL |
| T |
CASE a WHEN b THEN c [WHEN d THEN e] [ELSE f] END | 如果a等于b,那么返回c;如果a等于d,那么返回e;否则返回f |
| T |
CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | 如果a为TRUE,则返回b;如果c为TRUE,则返回 d;否则返回e |
字符串函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| INT | length(string A) | 返回字符串A的长度 |
| STRING | reverse(string A) | 返回字符串A的反转结果 |
| STRING |
concat(string A, string B…) |
返回输入字符串连接后的结果,支持任意个输入字符串 |
| STRING |
concat_ws(string SEP, string A, string B…) | 返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符 |
| STRING |
substr(string A, int start),substring(string A, int start) substr(string A, int start, int len),substring(string A, int start, int len) | 返回字符串A从start位置到结尾的字符串返回字符串A从start位置开始,长度为len的字符串 |
| STRING | upper(string A) ucase(string A) | 返回字符串A的大写格式 |
| STRING | lower(string A) lcase(string A) | 返回字符串A的小写格式 |
| STRING |
trim(string A) ltrim(string A) rtrim(string A) | 去除字符串两边的空格 除字符串左边的空格 去除字符串右边的空格 |
| STRING |
regexp_replace(string A, string B, string C) | 将字符串A中的符合java正则表达式B的部分替换为C |
| STRING |
regexp_extract(string subject, string pattern, int index) | 将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符 |
| STRING |
parse_url(string urlString, string partToExtract [, string keyToExtract]) |
返回URL中指定的部分。partToExtract 的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO. |
| STRING |
get_json_object(string json_string, string path) |
解析json的字符串json_string,返回path 指定的内容。如果输入的json字符串无效,那么返回NULL |
| STRING | space(int n) | 返回长度为n的空格字符串 |
| STRING | repeat(string str, int n) | 返回重复n次后的str字符串 |
| STRING |
lpad(string str, int len, string pad) rpad(string str, int len, string pad) | 将str进行用pad进行左补足到len位 将str 进行用pad进行右补足到len位 |
| ARRAY |
split(string str, string pat) |
按照pat字符串分割str,会返回分割后的字符串数组 |
| INT |
find_in_set(string str, string strList) find_in_set(‘ab’,’aa,ab,ac’) |
返回str在strlist第一次出现的位置, strlist是用逗号分割的字符串。如果没有找该str字符,则返回0 |
| 返回类型 | 签名 | 描述 |
|---|---|---|
| INT |
instr(string str, string substr) instr(“abcde”,”ab”) |
返回substr在str中第一次出现的位置, 未出现则返回0(如果参数为NULL则返回NULL;位置从1开始) |
统计函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| INT |
count(*), count(expr), count(DISTINCT expr[, expr_.]) | count(*)统计检索出的行的个数,包括NULL值的行; count(expr)返回指定字段的非空值的个数;count(DISTINCT expr[, expr_.])返回指定字段的不同的非空值的个数 |
| DOUBLE |
sum(col), sum(DISTINCT col) |
sum(col)统计结果集中col的相加的结果;sum(DISTINCT col)统计结果中col不同值相加的结果 |
| DOUBLE |
avg(col), avg(DISTINCT col) | avg(col)统计结果集中col的平均值;avg(DISTINCT col)统计结果中col不同值相加的平均值 |
| DOUBLE |
min(col) max(col) |
统计结果集中col字段的最小值 统计结果集中col字段的最大值 |
| DOUBLE |
var_pop(col) var_samp (col) | 统计结果集中col非空集合的总体方差 统计结果集中col非空集合的样本变量 |
| DOUBLE |
stddev_pop(col) stddev_samp (col) | 统计结果集中col非空集合的总体标准差 统计结果集中col非空集合的样本标准差 |
| DOUBLE |
percentile(BIGINT col, p) | 求准确的第p个百分位数,p必须介于0和1之间,但是col字段目前只支持整数,不支持浮点数类型 |
| ARRAY |
percentile(BIGINT col, array(p1 [, p2]…)) | 功能和上述类似,之后后面可以输入多个百分位数,返回类型也为array,其中为对应的百分位数 |
复合类型构建访问函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| MAP |
map (key1, value1, key2, value2, …) | 根据输入的key和value对构建map类型 |
| STRUCT | struct(val1, val2, val3, …) | 根据输入的参数构建结构体struct类型 |
| ARRAY | array(val1, val2, …) | 根据输入的参数构建数组array类型 |
| … |
A[n] |
返回数组A中的第n个变量值。数组的起始下标为0。 |
| … | M[key] | 返回map类型M中,key值为指定值的value值 |
| … | S.x | 返回结构体S中的x字段 |
| INT | size(Map |
返回map类型的长度 返回array类型的长度 |
| … | explode(map|array) | 列变行 |
| Array | collect_set ( col) | 对col行变列并 去重, |
| Array | collect_list ( col) | 对col行变列并 不去重, |
| Array | map_keys(map) | 取map类型的所有Key |
| Array | map_values(map) | 取map类型的所有value |
| T | array_contains(array,obj) | 判断指定的obj 是否村在数组中 |
2.4.3 Select 语句结构
语句执行顺序(explain )
一个Hive任务会包含一个或多个stage(阶段),不同的stage间会存在着依赖关系。 越复杂的查询通常会引入越多的stage,而stage越多就需要越多的时间时间来完成。
Reduce Output Operator #进行本地的计算key expressions: _col0 (type: int) sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 800 Basic stats: COMPLETE
Column stats: NONE
value expressions: _col1 (type: bigint)
Execution mode: vectorized
Reduce Operator Tree: #reduce过程Group By Operator
aggregations: count(VALUE._col0) keys: KEY._col0 (type: int) mode: mergepartial outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 800 Basic stats: COMPLETE Column stats: NONE
Filter Operator #Having 过滤
predicate: (_col1 > 1L) (type: boolean) #过滤条件
Statistics: Num rows: 1 Data size: 800 Basic stats: COMPLETE Column
stats: NONE
文本格式
File Output Operator #在reduce有File Output Operator,说明输出结果将是compressed: false
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat output format:
org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazybinary.LazyBinarySerDe
Stage: Stage-2 Map Reduce
Map Operator Tree: TableScan
Reduce Output Operator
key expressions: _col1 (type: bigint) sort order: - #排序
Statistics: Num rows: 1 Data size: 800 Basic stats: COMPLETE Column stats: NONE
value expressions: _col0 (type: int) Execution mode: vectorized
Reduce Operator Tree:
Select Operator
expressions: VALUE._col0 (type: int), KEY.reducesinkkey0 (type:
bigint)
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 800 Basic stats: COMPLETE Column
stats: NONE
File Output Operator compressed: false
Statistics: Num rows: 1 Data size: 800 Basic stats: COMPLETE Column
stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat output format:
org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
from —>where —> select —> group by —>聚合函数—> having —> order by —>limit
Hive 参数介绍
hive.mapred.mode 取值分为 nonstrict(非严格),strict(严格) 严格模式,限制三种查询:
| 如果为strict,会对三种情况的语句在compile环节做过滤 |
|---|
| 1. 笛卡尔积不能查询(表关联join不写关联条件) |
| 2. order by排序,必须加limit语句 |
| 3. 读取partitioned table,但没有指定partition |
Hive 3.0.0以上 hive.remove.orderby.in.subquery ( 设置为false)
在subqueries和views中没有limit的Order by将会被optimizer(优化器)移除,为了禁用它,
— 全表查询 (select * from 表名)
— 选择特定列查询(select col1,col2,… from 表名 )
— 列重命名(select col1 [as] ,… from 表名)
— 返回数组的第一个元素(索引从0开始)
— 查看数组中的每个元素
— 数组各元素分行显示,并要有与只对应的sku_id,sku_name
| select sku_id,sku_name, id_list from sales_info lateral view explode(id_array) ids as id_list; —lateral view explode(数组字段) 虚拟表名 as 虚拟表字段 |
|---|
— 把test_hv 表 以sku_id 分组 id_list 转一列显示
| select sku_id,collect_set(id_list) from test_HV group by sku_id; —set 集合去重 select sku_id,collect_list(id_list) from test_HV group by sku_id;—list 列表不去重 |
|---|
— 数组转与字符串互换
| select *, split(concat_ws(‘,’,id_array),’,’) from sales_info; |
|---|
— 返回Map中key 为 id 的值
| select state_map[‘id’] from mapkeys1 |
|---|
— 把map中Key ,value 分两列显示
| select explode(state_map) from mapkeys1 |
|---|
— map各元素分行显示,并要有与只对应的sku_id,sku_name
| select sku_id,sku_name, infokey,infovalue from mapkeys1 lateral view explode(state_map) infos as infokey,infovalue; |
|---|
— 查看所有map中的value
| select map_values(state_map) from mapkeys1; |
|---|
— map中不存在指定Key 时 显示 “无”
| select state_map[‘id’],if( state_map[‘user’] is null , ‘无’,state_map[‘user’]) from mapkeys1; |
|---|
— 返回结构体中为age元素值
| select basic_info.age from test_student; |
|---|
1.Select——Where
使用WHERE 子句,将不满足条件的行过滤掉。where 后是 关系运算 和 逻辑运算的不同组合。
— Sale_info表中Sku_Name 包含 字母A的
| select * from sales_info where sku_name like ‘%A%’; |
|---|
— Sale_info表中Sku_Name 为 小米6 或 小米5的
— Sale_info表中Sku_id为空的
— Sale_info 表 Sku_id 以0开头 并且 Sku_name 包含米字
—Sale_info 表 Sku_id 含有 4数字6 的记录
—Sale_info 表中 sku_name包含小写字母的
—Sale_info表中数组为空的
—Sale_info表中Sku_id在100~800之间的
—Sale_info表中 id_array 中有 89 的
—Sale_info表中 id_array 有id含有8的
—mapkeys1 表中 state_map 中key 含有id的
—mapkeys1 表中 state_map 中key 不含 token
—mapkeys1 表中 state_map user_name 中包含zhang的
—mapkeys1 表中姓张的并且名字只有两个字的
—mapkeys1 表中 state_map字段的 values 包含 A 的(不区分大小写)
2. Select——Group By & 聚合函数
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列对结果进行分组,然后对每个组执行聚合操作(统计函数)。
having与where不同点
| where | having |
|---|---|
| where针对表中的列发挥作用,查询数据 | having针对查询结果中的列发挥作用,筛选数据 |
| 不能写分组函数 | 可以使用分组函数 |
| 不受限制 | 只用于group by分组统计语句 |
注意: 使用Group by 后 ,select 后只能有 分组列名,或聚合函数
—统计test_partition1 表中各 sku_class 的个数
—统计test_student 表basic_info 各age的人数 并显示大于1 的年龄组
—mapkeys1 以map列中指定key 对应的值进行分组 并统计记录条数
—以数组中是否存在指定值进行分组计数统计
—统计test_partition1 表中各分区记录并且找到大于1的分区
—以sales_info 表中数组字段第一个元素进行分组,并列出sku_id的最大值,最小值,平均值 ,合计, 等
—统计order_data表每年每月的总销量,总销售额(保留两位小数点)
—统计order_data表每年每月的总销量,只显示销量不足1000 的年份 月份
—统计order_data表每年下半年的订单量
—统计单商品量大于2的,订单量大于10的年份 月份
hadoop的MR不患寡而患不均。数据倾斜将是MR计算的最大瓶颈。hive中可以设置分区、桶、distribute by等来控制分配数据给Reduce。
3. Select——Order By
| order by | sort by | distribute by | cluster by | |
|---|---|---|---|---|
| 作用 |
order by会对输入做全局排序 |
sort by 是单独在各自的reduce中进行排序 |
控制map 中的输出在 reduce中是如何进行划分的 |
相当于distribute by 和 sort by 合用 |
| 缺点 |
只有一个Reduce,当输入规模较大时,消耗较长的计算时间 | 不能保证全局有序 |
只是分,没有排序 |
只能做升序 |
 order by (全局排序asc ,desc)
order by (全局排序asc ,desc)
—单列排序
—多列排序
—别名排序
—默认的升序,默认是的NULLS FIRST
sort by(reduce 内排序)
—查看设置 reduce 个数
—验证sort 为reduce为reduce内排序,非全局排序
—自定reduce 个数 并 写为文件,一个reduce 一个文件,验证reduce 内是否正常排序
—对分区表进行排序
—对分桶表进行排序
Distribute by(分区排序)
Distribute 类似 MR 中的partition 进行分区,结合sort by 使用(要放到sort by 的前面)
—设置Reduce个数为6
—订单表中以订单年份进行分区,以订单金额进行降序
—把结果写到文件中
—订单表(order_data1)中以quantity进行分区 ,以金额进行升序
—订单表(order_data1)中以quantity进行分区 ,以quantity升序
—对order_data 分区表进行分区排序
—对test_buckets分桶表进行分区排序
Cluster By(当 distribute by 和 sorts by 字段相同时 ,可以使用 ) 除具有distribute by 的功能,还有 sort by的功能, 但只能升序
Cluster By 是 distribute by + sort by 的相同字段 升序的缩写
distribute by 只做分区不做排序(不受源数据分区影响)控制map 如何分配给reduce sort by 只做reduce 内排序 如过要全局排序 set mapred.reduce.tasks 设置为1 order by 与mysql 的order by 一致 进行全局排序
hive 的排序 普通表 ,分区表, 分桶表是无差异的,用法一致
2.4.4 表关联
Hive Join的限制
(1) 只支持等值连接
Hive支持类似 mysql 的大部分Join 操作,但是注意只支持等值连接,并不支持不等连接。原因是Hive 语句最终是要转换为MapReduce 程序来执行的,但是 MapReduce程序很难实现这种不等判断的连接方式。
(2) 连接谓词中不支持 or (on 后面的表达式不支持 or)
数据介绍
test_join_order 表的 多 谢雯-21700 , user_info 表中多黄雯-21715 ,高凤-12865

1 、Inner join
内连接同mysql 中的一样,连接的两个表中,只有同时满足连接条件的记录才会放入结果表中。

—统计2018年1月每个用户的订单量,购买量,购买总金额(保留两位小数点),用户性别,用户年龄
2、 Left join
同mysql中一样,两个表左连接时,符合 Where条件的左侧表的记录都会被保留下来,而符合On 条件的右侧的表的记录才会被保留下来。
—分区表join_order 表分区为year=2018 and month=1 与 user_info 表进行关联

—统计 join_order 2018年 1月, 用户表中不存在的用户
3、 Right join
同Left Join相反,两个表右边连接时,符合 Where条件的右侧表的记录都会被保留下来,而符合On条件的左侧的表的记录才会被保留下来。
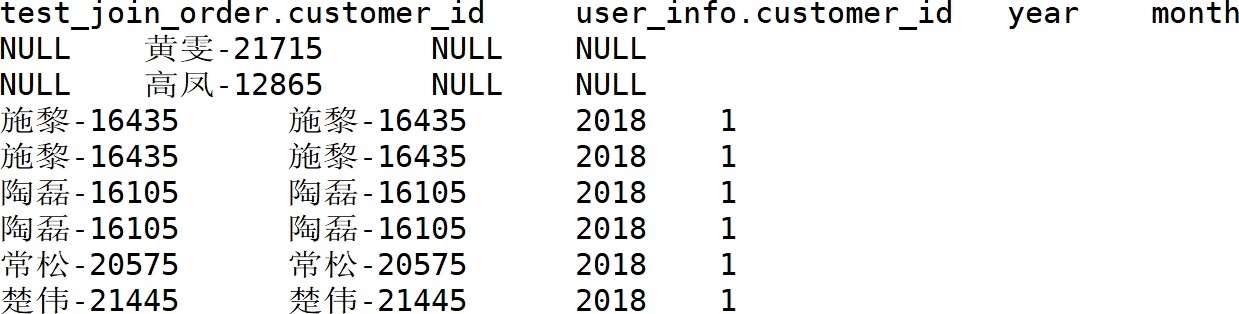
4、 Full join
Full Join会将连接的两个表中的记录都保留下来。
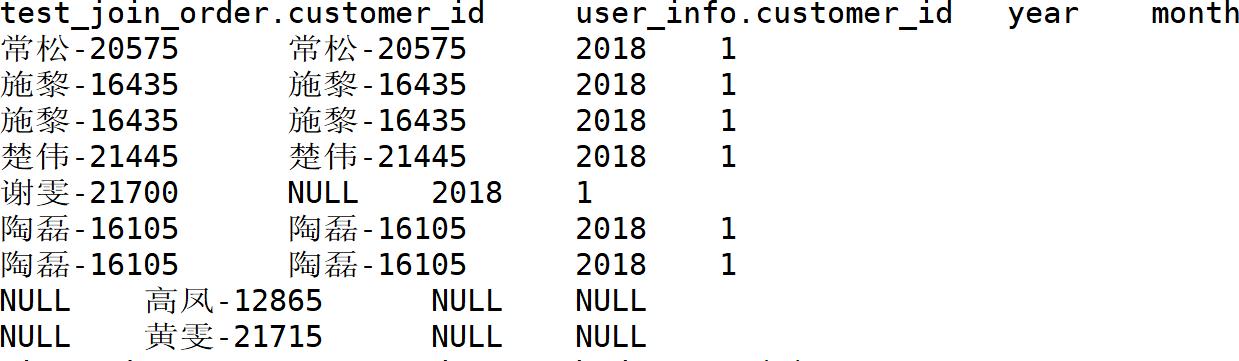

5、Union,对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
—看看所有用户id(customer_id),去掉重复值
6、Union All 对两个结果集进行并集操作,包括重复行,不进行排序;
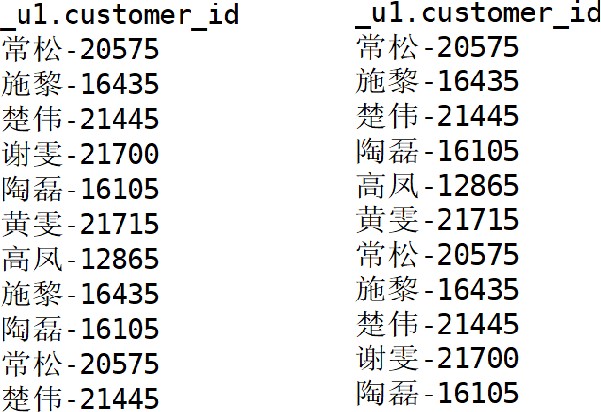
7、 Intersect 对两个结果集进行交集操作,不包括重复行,同时进行默认规则的排序;
8、 Minus 对两个结果集进行差操作(第一个减去第二个),不包括重复行,同时进行默认规则的排序。
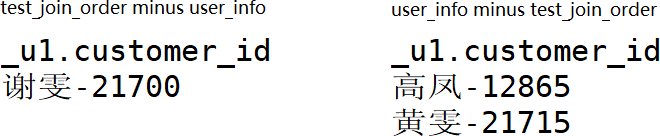
2.4.5 Hive视图
视图是一个虚表,一个逻辑概念,可以跨越多张表。表是物理概念,数据放在表中,视图是虚表, 操作视图和操作表是一样的,所谓虚,是指视图下不存数据。视图是建立在已有表的基础上,视图赖以建立的这些表称为基表视图也可以建立再已有的视图上视图可以简化复杂的查询
创建视图
语法
—不指定列创建视图

—以视图创建视图
查看视图
**
—查看视图是否创建成功
—查看test_view视图结构
删除视图
**
删除视图时,如果被删除的视图被其他视图所引用,删除时不会发出警告,但是引用该视图的其他视图 已经失效,需要进行重建或者删除。
—删除test_view 视图
—删除被引用的视图 并查看父视图

修改视图
语法
在修改指定列的视图后,指定的列名失效当基表的数据记录增删时,视图也会生变化当基表删除视图引用的列后,视图会失效
当基表添加列后,视图还是原有的列,对新列不做引用。当基表或基视图被删除后,此视图失效
—修改父视图test_fu_view(注意列名)
—为原有表添加数据 order_date 表 year=2018,month=1分区 加入高凤-12865 购买记录
—查看创建视图的查询语句
—查看视图数据是否有变化
—创建一个引用某表所有列的视图
—为原始表添加字段
—查看原始表数据
—查看视图数据
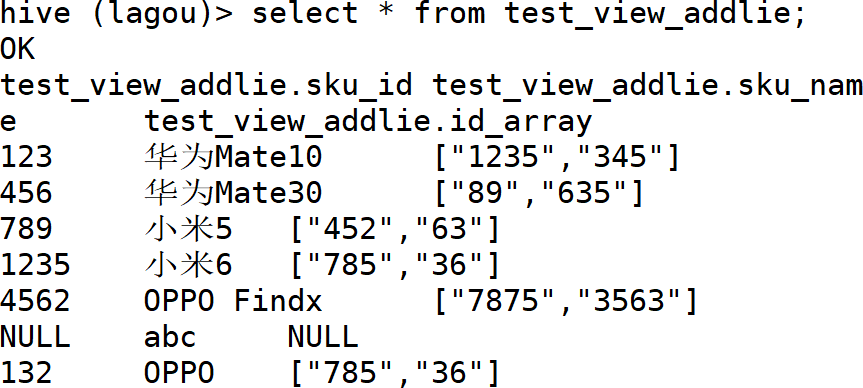
—验证删除原始表,视图是否存在或有效
视图总结
 视图是只读的,不能用作 LOAD / INSERT / ALTER 的目标;
视图是只读的,不能用作 LOAD / INSERT / ALTER 的目标; 在创建视图时候视图就已经固定,对基表的增加列操作将不会反映在视图,删除视图引用的列,视 图会失效;删除基表并不会删除视图,需要手动删除视图;
在创建视图时候视图就已经固定,对基表的增加列操作将不会反映在视图,删除视图引用的列,视 图会失效;删除基表并不会删除视图,需要手动删除视图; 视图可能包含 ORDER BY 和 LIMIT 子句。如果引用视图的查询语句也包含这类子句,其执行优先级低于视图对应字句创建视图时,如果未提供列名,则将从 SELECT 语句中自动派生列名;创建视图时,如果 SELECT 语句中包含其他表达式,例如 x + y,则列名称将以C0,C1 等形式生成;
视图可能包含 ORDER BY 和 LIMIT 子句。如果引用视图的查询语句也包含这类子句,其执行优先级低于视图对应字句创建视图时,如果未提供列名,则将从 SELECT 语句中自动派生列名;创建视图时,如果 SELECT 语句中包含其他表达式,例如 x + y,则列名称将以C0,C1 等形式生成;
2.4.6 开窗函数
Group by 普通聚合函数每组只有一条记录,而开窗函数则可以为窗口中的每行都返回一个值。普通聚合函数聚合的行集是组,开窗函数聚合的行集是窗口。
语法
over函数(指定分析函数工作的数据窗口大小)
over() 内部参数:
—统计test_join_order表中的订单数
—统计test_join_order表中各商品数的订单数,总销售额,平均销售额,最大金额,最小金额
—分析test_join_order表中各订单,金额大于平均金额的为高,否则为低
| 窗口子句 | 备注 |
|---|---|
| PRECEDING | 往前 n preceding 从当前行向前n行 |
| FOLLOWING | 往后 n following 从当前行向后n行 |
| CURRENT ROW | 当前行 |
| UNBOUNDED | 起点 |
| UNBOUNDED PRECEDING | 表示该窗口最前面的行(起点) |
| UNBOUNDED FOLLOWING | 表示该窗口最后面的行(终点) |
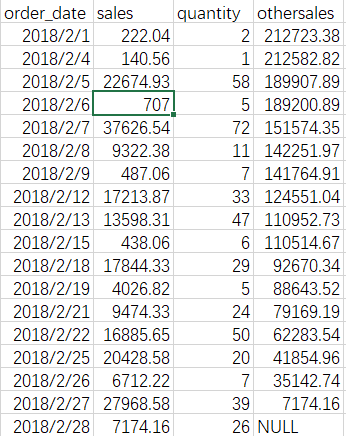
—分析test_join_order表中各记录对销售额累计求和(保留两位小数点),销售量累计求最大
—分析overData表中每三天(前一天,当前天,后一天)的销售额合计(保留两位小数点)
—利用 UNBOUNDED FOLLOWING 统计出 还有多少销售额待完成
| 偏移函数 | 备注 |
|---|---|
| LEAD(col,n,DEFAULT) | 用于统计窗口内往下第n行值 从当前行下移几行的值 |
| LAG(col,n,DEFAULT) | 用于统计窗口内往上第n行值 从当前行上移几行的值 |
| first_value(col, DEFAULT) | 取分组内排序后,截止到当前行,第一个值 |
| last_value(col, DEFAULT) | 取分组内排序后,截止到当前行,最后一个值 |
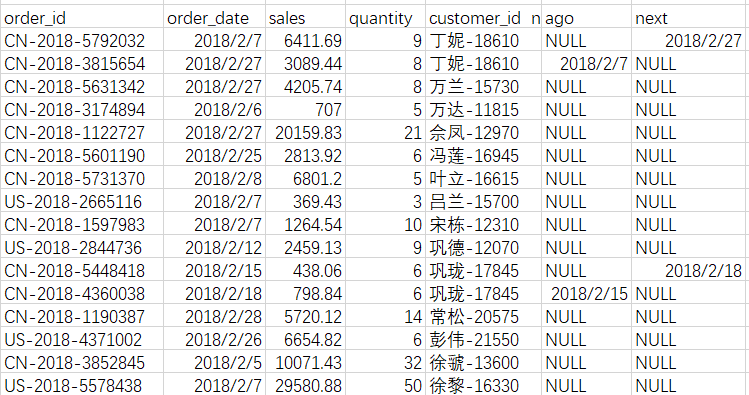
—统计Pianyi 表中每天金额最高,最低的订单号
—利用lead ,lag 找的每个用户上一次,下一次的购买时间
| 统计函数 | 备注 |
|---|---|
| COUNT(col) | 统计各分组内个数 |
| SUM(col) | 统计各分组内合计 |
| MIN(col) | 统计各分组内最小值 |
| MAX(col) | 统计各分组内最大值 |
| AVG(col) | 统计各分组内平均值 |
| 排序函数 | 备注 |
|---|---|
| ROW_NUMBER() | 从1开始,按照顺序,生成分组内记录的序列 |
| RANK() | 生成数据项在分组中的排名,排名相等会在名次中留下空位 |
| DENSE_RANK() | 生成数据项在分组中的排名,排名相等在名次中不会留下空位。 |
| CUME_DIST() | 小于等于当前值的行数/分组内总行数 |
| PERCENT_RANK() | 分组内当前行的RANK值-1/分组内总行数-1 |
| NTILE(n) | 用于将分组数据按照顺序切分成n片,返回当前切片值, 等频切片 |
—分析Pianyi表中 各记录, 按销量降序排序后标上上序号
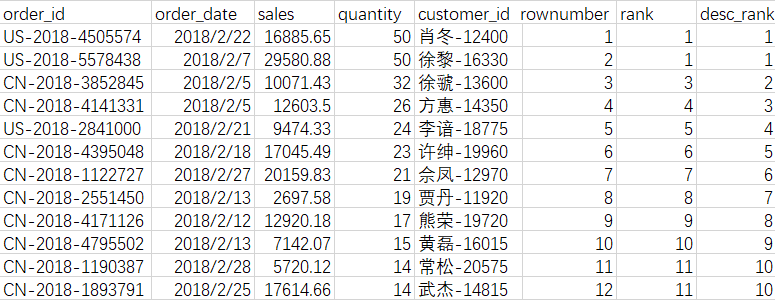
—把Pianyi表的销量分为4份
—统计小于等于当前金额的订单数 占总订单数的比例,
2.4.7 子查询
hive 3.1 支持select,from,where 子句中的子查询
select 子查询限制
不支持 if / case when 里的子查询
where 子查询限制
IN/NOT IN 子查询只能选择一列。
EXISTS/NOT EXISTS 必须有一个或多个相关谓词。对父查询的引用仅在子查询的WHERE子句中支持。集合中如果含null数据,不可使用not in, 可以使用in 主查询和子查询可以不是同一张表
select 关键字的子查询
—统计user_info 各用户的订单量 ( test_join_order 订单表)
where 关键字的子查询
—查找user_info 各用户的订单量大于0
—查找user_info 中有购买记录的用户
—sales_info 表中 id_array字段的 各元素都包含 3 的
—mapkeys1 表中 state_map 字段的每个Values 都包含2的
—sales_info 表中 id_array字段每个元素出现的次数
—分析join_order 分区表中 year=2018, month=1 分区中各订单,金额大于平均金额的为高,否则为低
FAILED: SemanticException org.apache.hadoop.hive.ql.optimizer.calcite.CalciteSubquerySemanticException: Unsupported SubQuery Expression Currently SubQuery expressions are only allowed as Where and Having Clause predicates
select 关键子后的子查寻不能存在于 if /case when 的语句中
2.4.8 抽样查询
在大规模数据量的数据分析及建模任务中,往往针对全量数据进行挖掘分析时会十分耗时和占用集群资 源,因此一般情况下只需要抽取一小部分数据进行分析及建模操作。
1. 随机抽样(rand()函数)
使用rand()函数与distribute by ,order by ,sort by 合用进行随机抽样,limit关键字限制抽样返回的数据
2. 数据块抽样(tablesample()函数)tablesample(n percent) 根据hive表数据的大小(不是行数,而是数据大小)按比例抽取数据,并保存到新的hive表中.
由于在HDFS块层级进行抽样,所以抽样粒度为块的大小,例如如果块大小为128MB,即使输入的
n%仅为50MB,也会得到128MB的数据.
如果希望在不同的块中抽取相同的数据,可以改变下面的参数:
tablesample(nM) 指定抽样数据的大小,单位为M
与PERCENT抽样具有一样的限制,因为该语法仅将百分比改为了具体值,但没有改变基于块抽样这一前提条件.
tablesample(n rows) 指定抽样数据的行数,其中n代表每个map任务均取n行数据
3. 分桶抽样
hive中分桶其实就是根据某一个字段Hash取模,放入指定数据的桶中.
语法:TABLESAMPLE(BUCKET x OUT OF y) y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例
未分桶的表
已分桶的表
2.4.9 自定义函数
查看系统内置函数 show functions;
显示内置函数用法 desc function 函数名;
详细显示内置函数用法 desc function extended 函数名;
自定义函数分为三个类别:
UDF(User Defined Function):一进一出(upper(), lower())
UDAF(User Defined Aggregation Function):聚集函数,多进一出(例如count/max/min) UDTF(User Defined Table Generating Function):一进多出,如lateral view explode()
创建自定义函数 需要用java来编写,而不是用传统的SQL来完成
2.4.10 HQL语句调优
去重技巧——⽤group by来替换distinct
在极⼤的数据量(且很多重复值)时,可以先group by去重,再count()计数,效率⾼于直接count(distinct col)
2. 聚合技巧——利⽤窗⼝函数grouping sets、cube、rollup
3. cube:根据group by 维度的所有组合进⾏聚合
4. rollup:以最左侧的维度为主,进⾏层级聚合,是cube的⼦集
5. 表连接优化⼩表在前,⼤表在后Hive假定查询中最后的⼀个表是⼤表,它会将其它表缓存起来,然后扫描最后那个表。使⽤相同的连接键
当对3个或者更多个表进⾏join连接时,如果每个on⼦句都使⽤相同的连接键的话,那么只会产⽣
⼀个 MapReduce job。尽早的过滤数据
减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使⽤到的字段。 逻辑过于复杂时,引⼊中间表 如何解决数据倾斜数据倾斜的表现:
如何解决数据倾斜数据倾斜的表现:
任务进度⻓时间维持在99%(或100%),查看任务监控⻚⾯,发现只有少量(1个或⼏个)reduce
⼦任务未完成。因为其处理的数据 量和其他reduce差异过⼤。数据倾斜的原因与解决办法:
1. 空值产⽣的数据倾斜
解决:如果两个表连接时,使⽤的连接条件有很多空值,建议在连接条件中增加过滤
2. ⼤⼩表连接(其中⼀张表很⼤,另⼀张表⾮常⼩)
解决:将⼩表放到内存⾥,在map端做Join
3. 两个表连接条件的字段数据类型不⼀致
解决:将连接条件的字段数据类型转换成⼀致的

若有收获,就点个赞吧
0 人点赞
