2.1 Hive简介
2.2 Hive DDL:数据定义语言
Hive 语句注意事项:
SQL 语言大小写不敏感。SQL 可以写在一行或者多行关键字不能被缩写也不能分行各子句一般要分行写
使用缩进提高语句的可读性
— 为注释符号
2.2.1 创建删除数据库
1) 创建数据库
3) 删除数据库
删除空数据库 drop database 数据库名;
如果删除的数据库不存在,最好采用 if exists判断数据库是否存在
如果数据库不为空,可以采用cascade命令,强制删除
4) 使用进入数据库
2.2.2 创建表——数据类型
1) Hive 数据类型数字类
| 类型 | 长度 | 备注 |
|---|---|---|
| TINYINT | 1字节 | 有符号整型 |
| SMALLINT | 2字节 | 有符号整型 |
| INT | 4字节 | 有符号整型 |
| BIGINT | 8字节 | 有符号整型 |
| FLOAT | 4字节 | 有符号单精度浮点数 |
| DOUBLE | 8字节 | 有符号双精度浮点数 |
| DECIMAL | — | 可带小数的精确数字字符串 |
日期时间类
| 类型 | 长度 | 备注 |
|---|---|---|
| TIMESTAMP | — | 时间戳,内容格式:yyyy-mm-dd hh:mm:ss[.f…] |
| DATE | — | 日期,内容格式:YYYY-MM-DD |
| INTERVAL | — | — |
字符串类
| 类型 | 长度 | 备注 |
|---|---|---|
| STRING | — | 字符串 |
| VARCHAR | 字符数范围1 - 65535 | 长度不定字符串 |
| CHAR | 最大的字符数:255 | 长度固定字符串 |
Misc类
| 类型 | 长度 | 备注 |
|---|---|---|
| BOOLEAN | — | 布尔类型 TRUE/FALSE |
| BINARY | — | 字节序列 |
复合类
| 类型 | 长度 | 备注 |
|---|---|---|
| ARRAY | — | 包含同类型元素的数组,索引从0开始 ARRAY |
| MAP | — | 字典 MAP |
| STRUCT |
— |
结构体 STRUCT |
| UNIONTYPE | — | 联合体 UNIONTYPE |
2) Hive建表
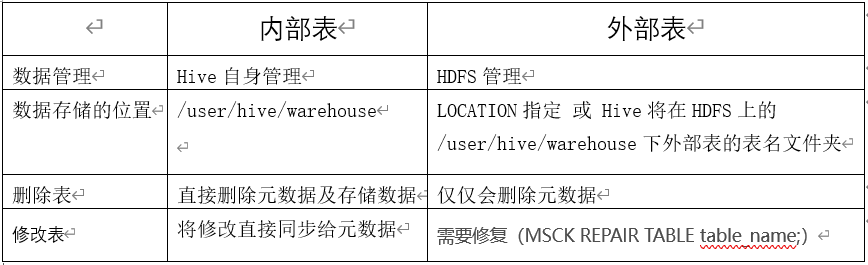
内部表与外部表的区别
1. 直接建表法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], …)] [COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], …)]
[CLUSTERED BY (col_name, col_name, …)
[SORTED BY (col_name [ASC|DESC], …)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
• CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;
查看表的相关信息
•IF NOT EXIST 忽略同名表的异常问题
• EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径
(LOCATION)
• LIKE 允许用户复制现有的表结构,但是不复制数据
• COMMENT可以为表与字段增加描述
• ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value, …)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,
用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
• STORED AS
SEQUENCEFILE //序列化文件
| TEXTFILE //普通的文本文件格式
| RCFILE //行列存储相结合的文件
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname //自定义文件格式
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。
• LOCATION指定表在HDFS的存储路径
• CLUSTERED表示的是按照某列聚类,例如在插入数据中有两项“张三,数学”和“张三,英语”
若是CLUSTERED BY name,则只会有一项,“张三,(数学,英语)”,这个机制也是为了加快查询的操作。
2. 查询建表法
create [EXTERNAL] table [IF NOT EXISTS] 表名 as select 语句;
 使用查询创建并填充表,select 中选取的列名会作为新表的列名(所以通常是要取别名),会改变表的属性、结构,比如只能是内部表、分区分桶也没了目标表不允许使用分区分桶的;对于旧表中的分区字段,如果通过 select * 的方式,新表会把它看作一个新的字段,这里要注意 ;目标表不允许使用外部表,会报错创建的表存储格式会变成默认的格式 TEXTFILE ,可以指定表的存储格式,行和列的分隔符等。
使用查询创建并填充表,select 中选取的列名会作为新表的列名(所以通常是要取别名),会改变表的属性、结构,比如只能是内部表、分区分桶也没了目标表不允许使用分区分桶的;对于旧表中的分区字段,如果通过 select * 的方式,新表会把它看作一个新的字段,这里要注意 ;目标表不允许使用外部表,会报错创建的表存储格式会变成默认的格式 TEXTFILE ,可以指定表的存储格式,行和列的分隔符等。
3. like建表法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name LIke old_talble_name用来复制表的结构需要外部表的话,通过 create external table like … 指定
扩展:数据类型转换
Hive也包括隐式转换(implicit conversions)和显式转换(explicitly conversions)。
任何整数类型都可以隐式地转换成一个范围更大的类型。TINYINT,SMALLINT,INT,BIGINT,FLOAT和
STRING都可以隐式地转换成DOUBLE;
隐式转换
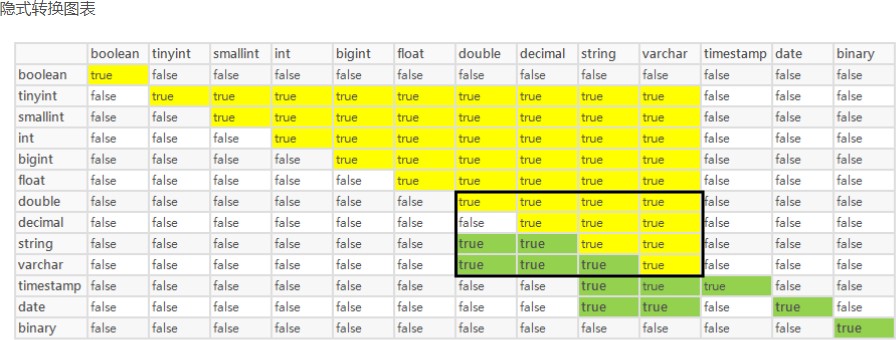
显式转换(CAST,convert)CAST的语法为cast(value AS TYPE)如果将浮点型的数据转换成int类型的,内部操作是通过round()或者floor()函数来实现的,而不是通过cast实现!对于BINARY类型的数据,只能将BINARY类型的数据转换成STRING类型。如果你确信BINARY类型数据是一个数字类型(a number),这时候你可以利用嵌套的cast操作。对于Date类型的数据,只能在Date、Timestamp以及String之间进行转换。下表将进行详细的说 明:
| 有效的转换 | 结果 |
|---|---|
| cast(date as date) | 返回date类型 |
| cast(timestamp as date) | timestamp中的年/月/日的值是依赖与当地的时区,结果返回date类型 |
| cast(string as date) | 如果string是YYYY-MM-DD格式的,则相应的年/月/日的date类型的数据将会 返回;但如果string不是YYYY-MM-DD格式的,结果则会返回NULL。 |
| cast(date as timestamp) | 基于当地的时区,生成一个对应date的年/月/日的时间戳值 |
| cast(date as string) | date所代表的年/月/日时间将会转换成YYYY-MM-DD的字符串。 |
convert(数据类型,表达式) 2.2.3创建表——分隔符特殊分隔符
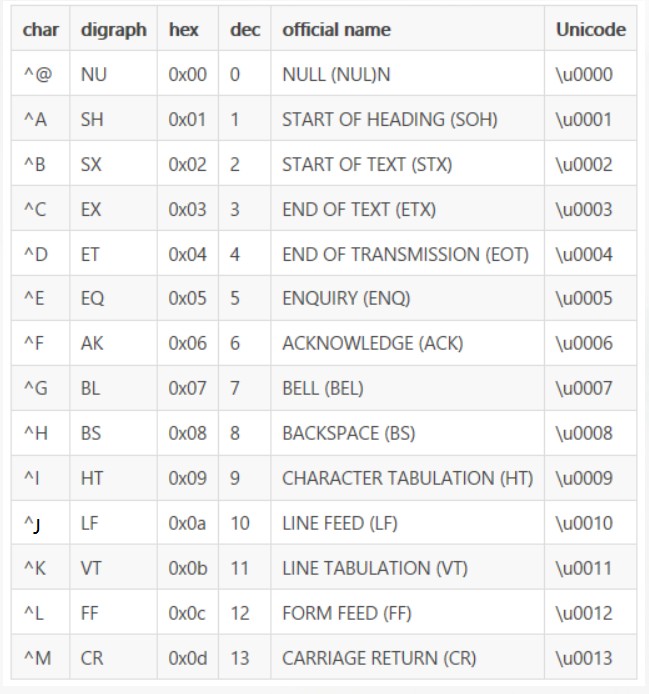
分隔符类型
字段分隔符
语法: fields terminated by ‘\t’ (hive 默认的字段分隔符为ascii码的控制符 \001 ctrl + V+A)
array 类型成员分隔符
语法:collection items terminated by ‘,’
map 的 Key 和 Value 之间的分隔符
语法:map keys terminated by ‘:’
行分隔符(必须放在最后,目前不支持其他分隔符 仅支持”\n”) 语法:lines terminated by ‘\n’
使用多字符作为分隔符
使用MultiDelimitSerDe的方法来实现
使用RegexSerDe的方法实现:

错误提示
2.2.4 创建表——分区表创建
1) 分区表技术与意义
避免hive全表扫描,提升查询效率。从而引进分区技术,使用分区技术,避免hive全表扫描,提升查询效率。减少数据冗余进而提高特定(指定分区)查询分析的效率。在逻辑上分区表与未分区表没有区别,在物理上分区表会将数据按照分区键的列值存储在表目录的 子目录中,目录名为“分区键=键值”。查询时尽量利用分区字段。如果不使用分区字段,就会全部扫描。
2) 分区表类型
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断
1. 静态分区
2. 动态分区
3) 建立分区
静态分区和动态分区的建表语句是一样的
查看表目录下的分区子目录

动态分区默认不开启,执行上面的语句会报错
可以通过多字段分区
通过HDFS文件系统查看
查看表目录下的分区子目录
4) 删除分区 drop
alter table 表名 drop partition(分区字段名=取值);
2.2.5 创建表——分桶表创建

create table 表名(字段1 类型1,字段2,类型2 ) clustered by(表内字段) sorted by(表内字段) into 分桶数 buckets
分桶结果如下

2.2.6 电商下单业务流程数据库搭建
把 shop_create.sql 上传到虚拟机 或者 在虚拟机上创建本文件
2.2.7 学员线上学习业务流程数据库搭建
把 online_edu_create.sql上传到虚拟机 或者 在虚拟机上创建本文件
Hdfs 下显示结果如下:

若有收获,就点个赞吧
0 人点赞
