1.1 大数据来源(大数据是如何产生的)
典型的数据分析系统,要分析的数据种类⽐较丰富,依据来源⼤体可以分为以下⼏部分:
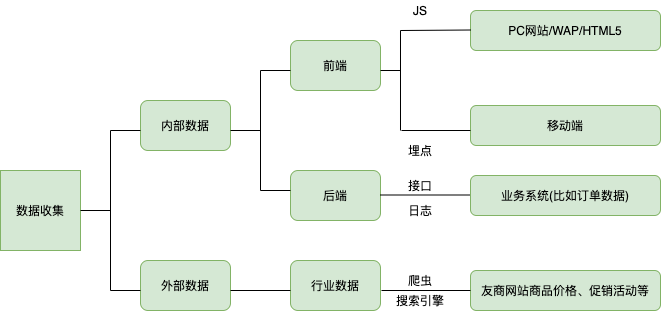
1.1.1 内部数据
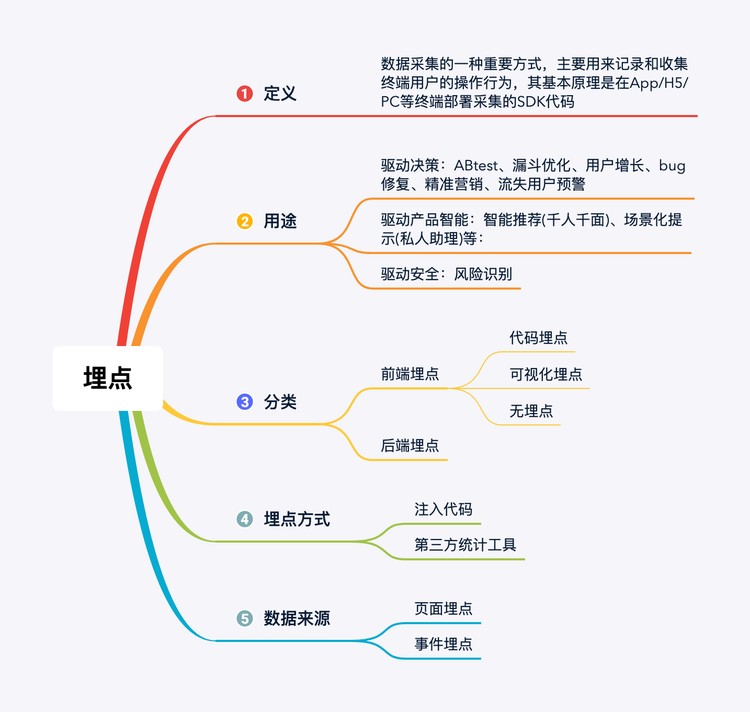
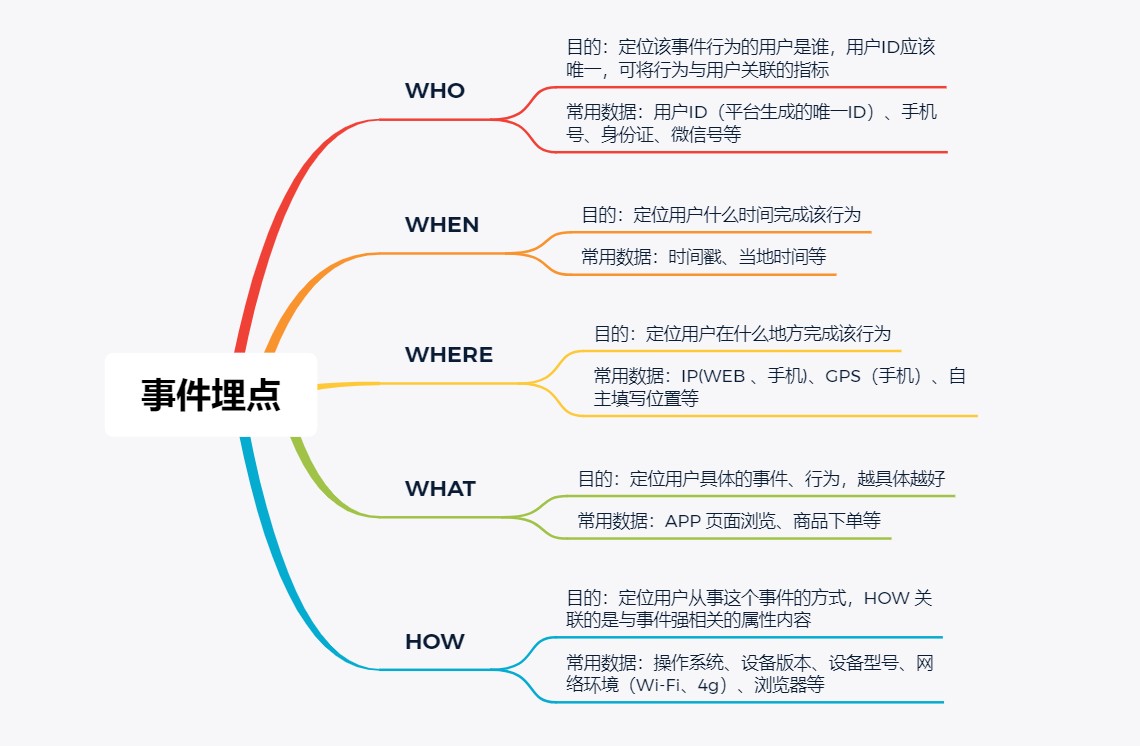
如何进⾏埋点
埋点原理
对基于⽤户⾏为的数据平台来说,发⽣在⽤户界⾯的,能获取⽤户信息的触点就是⽤户数据的直接来源,⽽建⽴这些触点的⽅式就是埋点。当这些触点获取到⽤户⾏为、身份数据后,会通过⽹络传输到服 务器端进⾏后续的处理。
埋点分类
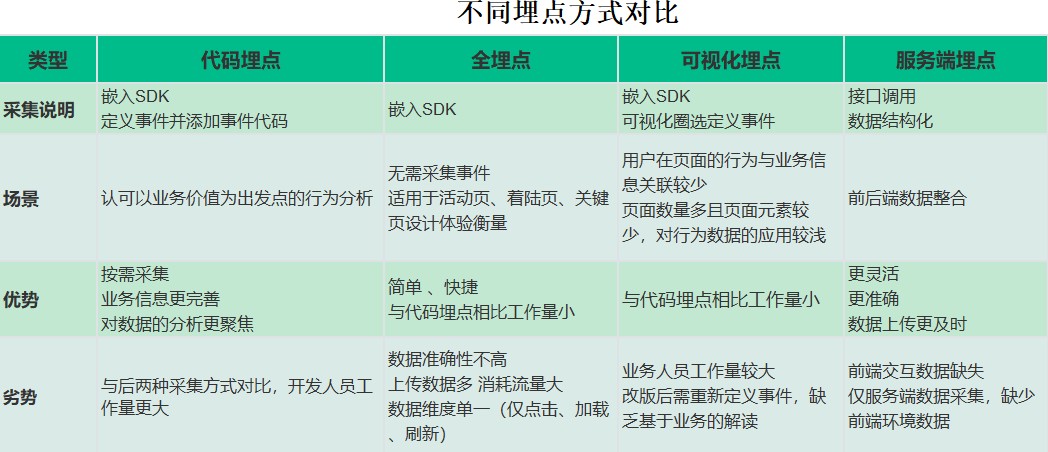
埋点从准确性⻆度考虑,分为客户端埋点和服务端埋点。客户端埋点,即客户操作界⾯中,在客户产⽣ 动作时对⽤户⾏为进⾏记录,这些⾏为只会在客户端发⽣,不会传输到服务器端;⽽服务端埋点则通常 是在程序和数据库交互的界⾯进⾏埋点,这时的埋点会更准确地记录数据的改变,同时也会减⼩由于⽹ 络传输等原因⽽带来的不确定性⻛险。
埋点采集⼯作流程
埋点数据采集维度
埋点⽂档输出 (⽂档必备要素包含以下⽅⾯):
| 要素 | 备注 |
|---|---|
| 事件名称 | 埋点的事件名称,如优惠卷领取/优惠卷使⽤ |
| 事件定义 | ⽤户点击领取优惠卷,则上报该事件 |
| 包含属性 | ⽤户进⾏了该⾏为,上报事件中需要传输那些内容,如⽤户ID、时间、应⽤版本、⽹络环境、⼿机型号、IP、内容ID等;如某些属性在所有事件中都需要上传,则可以整理公共属性 进⾏管理; |
| 属性定义 | 说明属性的定义,如⽤户地址: ⽤⽤户主动上传的地址,如没有则⽤⽤户IP代替 |
| 属性值类型 | 说明传输属性的类型,字符串、数值、bool |
| 开发名称 | 对应的开发变量名,可以由开发进⾏补充。如userID、contentID; |
| 当前状态 | 明当前该变量的状态。如待开发、开发中、验收中、已上线、已下线 |
| 上线版本 | 说明该内容在那个版本进⾏上线。如2.3.1 |
| 备注 | 备注中可记录该属性的变动情况和常⻅值等内容。 |
案例
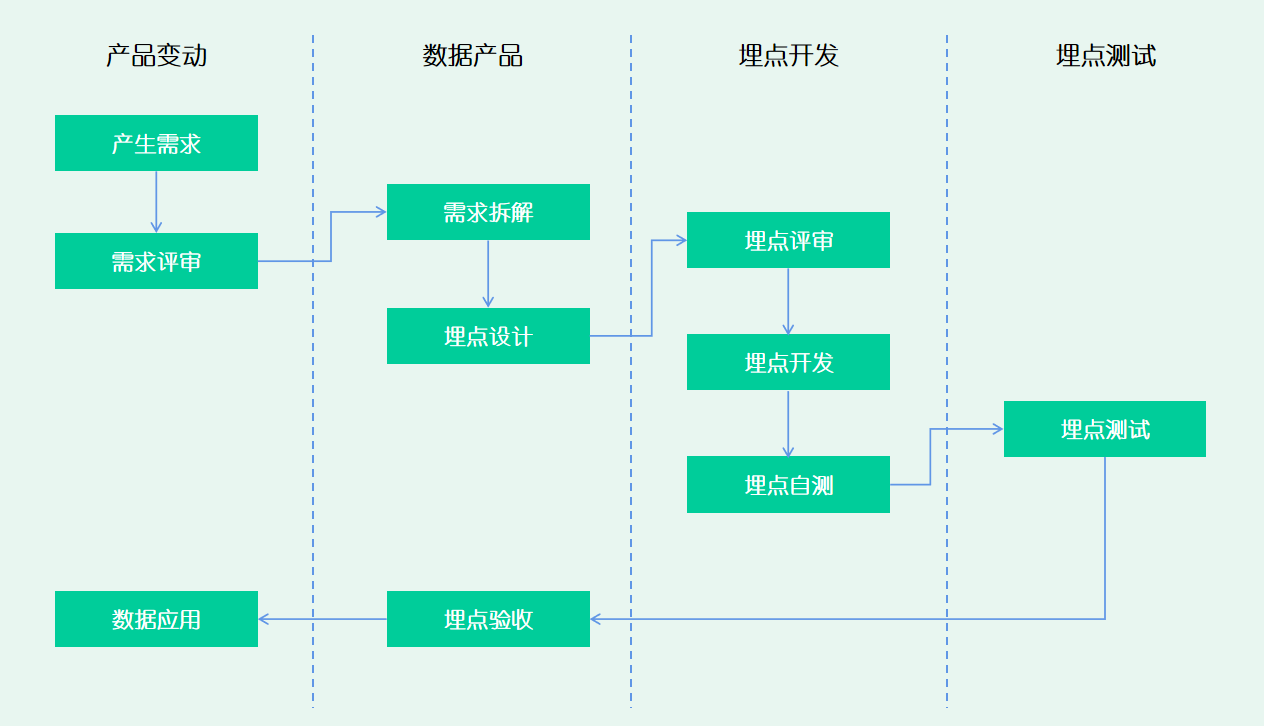
在整个埋点⼯作流程中,埋点设计环节是最关键的⼀环,在这个环节整体可以根据需求梳理和转化的路 径,分为业务分解、分析指标、事件设计、属性设计的四个阶段。其中,业务分解和分析指标,是事件 设计和属性设计的关键信息输⼊,通过对业务场景和分析需求的梳理,确认埋点的内容和范围, ⽽事件和属性设计,则是将这些业务分析诉求,转换成⾯向幵发的需求语⾔,让开发能看懂需要他在什么场景和 规则下采集哪些数据。接下来,我们以优惠券营销场景为案例,讲述该如何进⾏埋点设计。
案例:优惠券营销场景的事件设计

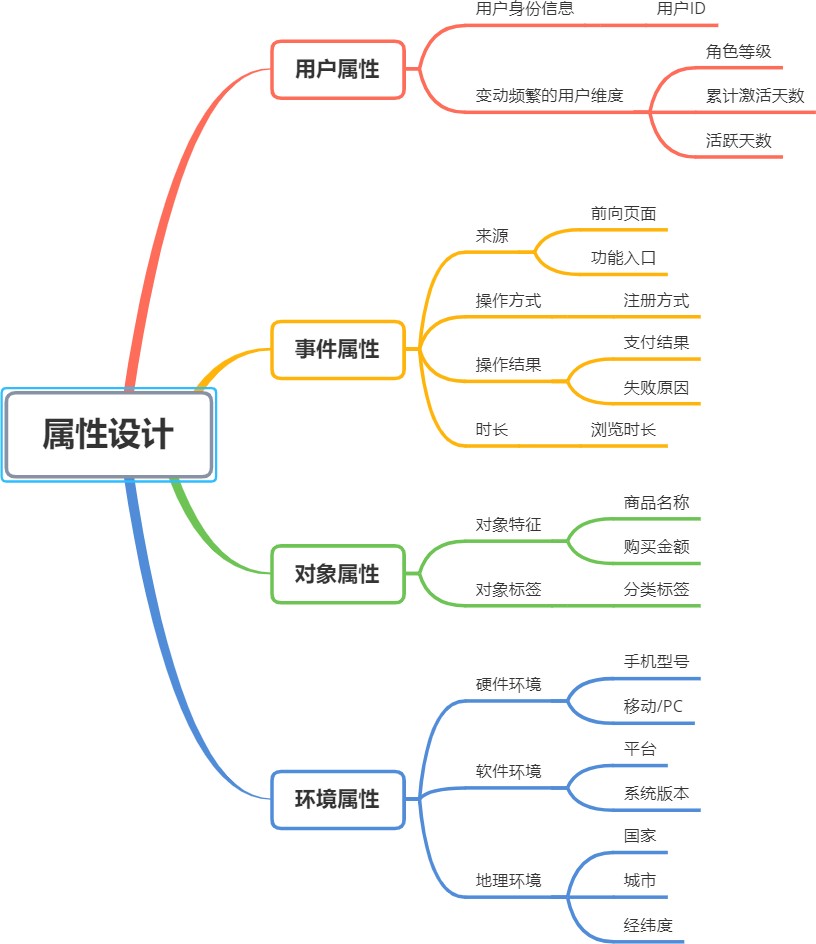
埋点采集中常⻅事件属性的类型举例,主要包含⽤户属性、事件属性、对象属性和环境属性四⼤类。
1.1.2 外部数据
竞争对⼿数据——爬取数据【电⼦商务⾏业最初对爬⾍的需求来源于⽐价(⽣意参谋,⽣e经)】
⽕⻋头,⼋⽖⻥,后羿等爬⾍软件

国家统计局——国家统计局

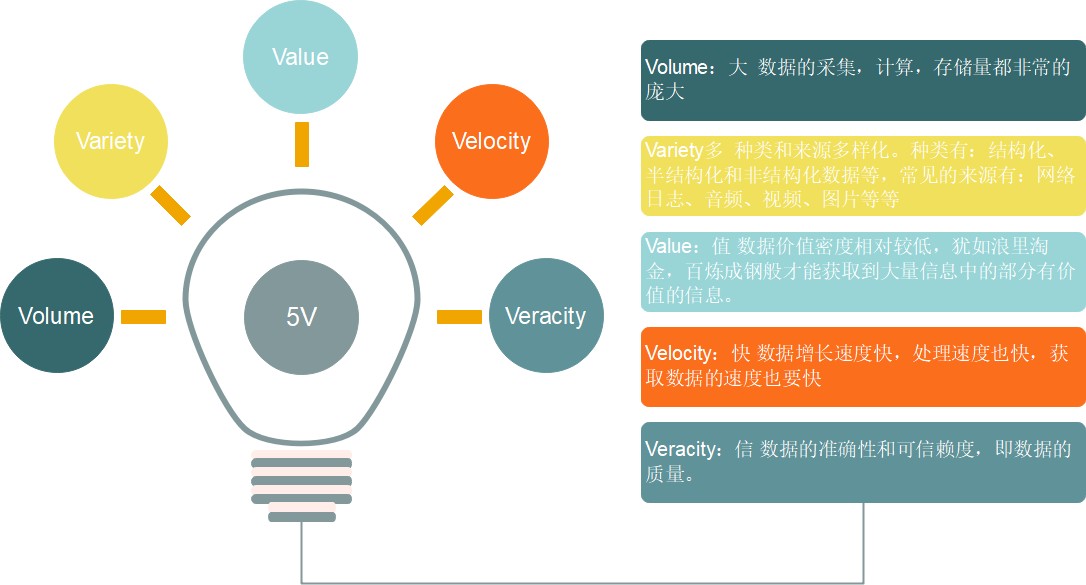
1.1.3 ⼤数据特点
1.2 数据仓库(数据是如何存储的)
数据仓库规模⼤、周期⻓,⼀些规模⽐较⼩的企业⽤户难以承担。因此,作为快速解决企业当前存在的 实际问题的⼀种有效⽅法,独⽴型数据集市成为⼀种既成事实。
数据集市(Data Mart) ,也叫数据市场,数据集市就是满⾜特定的部⻔或者⽤户的需求,按照多维的⽅式进⾏存储,包括定义维度、需要计算的指标、维度的层次等,⽣成⾯向决策分析需求的数据⽴⽅体。
数据集市主要是针对⼀组特定的某个主题域、部⻔或者特殊⽤户需求的数据集合。这些数据需要针对⽤ 户的快速访问和报表展示进⾏优化,优化的⽅式包括对数据进⾏轻量级汇总,在数据结构的基础上创建 索引。
数据集市的⽬标分析过程包括对数据集市的需求进⾏拆分,按照不同的业务规则进⾏组织,将与业务主 题相关的实体组织成主题域,并且对各类指标进⾏维度分析,从⽽形成数据集市⽬标说明书。内容包括 详细的业务主题、业务主题域和各项指标及其分析维度。
1.2.1 什么是数据仓库
数据仓库(Data Warehouse),简称DW。数据仓库顾名思义,是⼀个很⼤的数据存储集合,出于企业的分析性报告和决策⽀持⽬的⽽创建,对多样的业务数据进⾏筛选与整合。它为企业提供⼀定的BI(商业 智能)能⼒,指导业务流程改进。
1.2.2 数据仓库解决什么问题
数据仓库从⼤的⽅向来说解决三类问题 存储, 快速提取, 跨部⻔应⽤

1.2.3 数据仓库的主要特征
⾯向主题的集成的
稳定的(不易失的)
时变的(反映历史变化的)
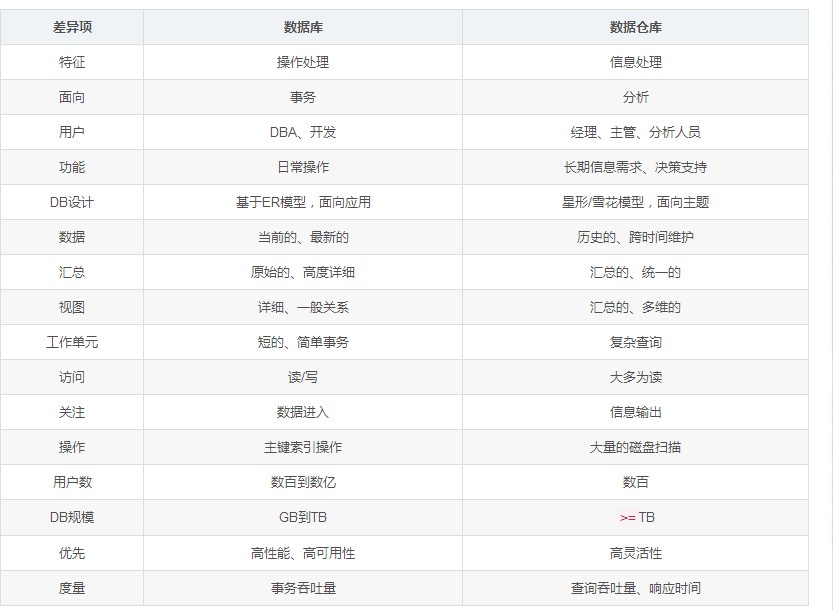
1.2.4 数据仓库与数据库区别
- 数据库与数据仓库的区别实际讲的是OLTP与OLAP的区别:
2. 数据仓库的出现,并不是要取代数据库:
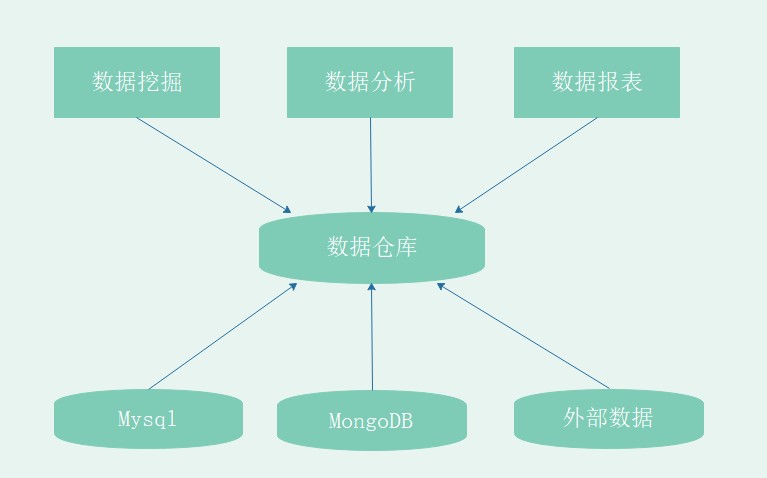
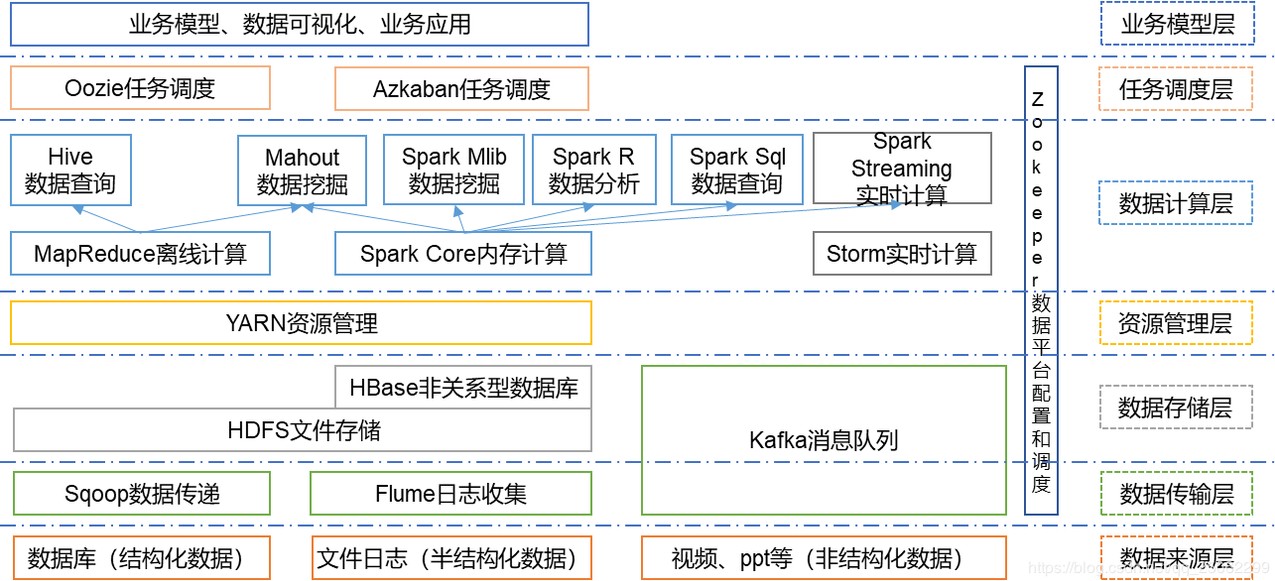
1.2.5 数据仓库架构
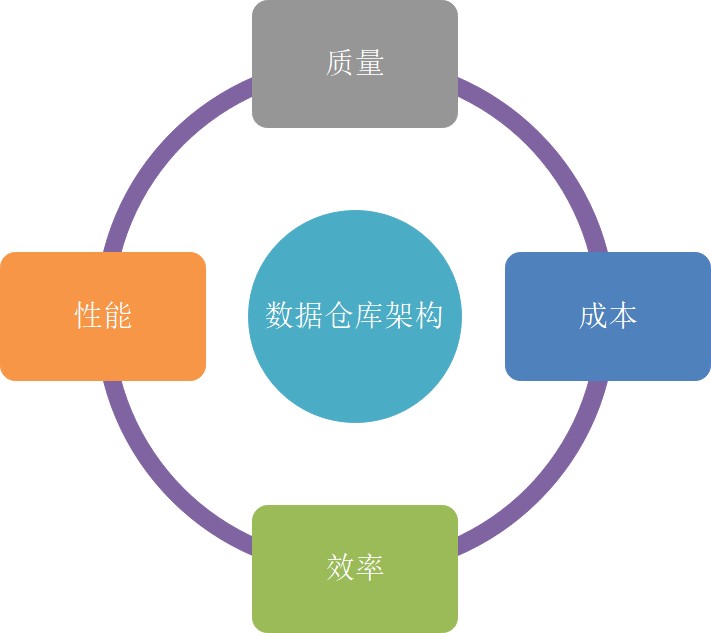
⼤数据系统需要数据模型⽅法来帮助更好地组织和存储数据,以便在性能、成本、效率和质量 之间取得最佳平衡,主流的⽅法是分层架构。
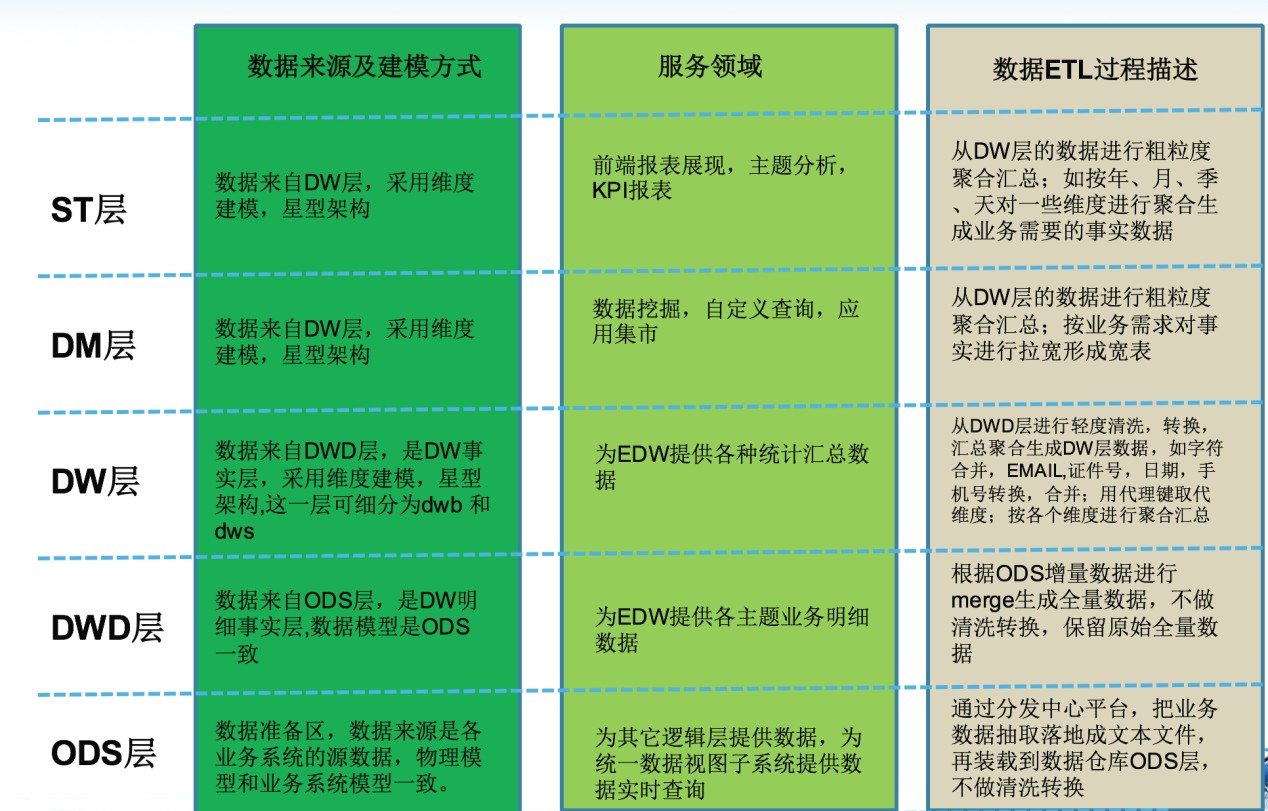
数据仓库的数据来源于不同的源数据,并提供多样的数据应⽤,数据⾃下层流⼊数据仓库后向上层开放 应⽤,⽽数据仓库只是中间集成化数据管理的⼀个平台
知名企业的数仓架构:
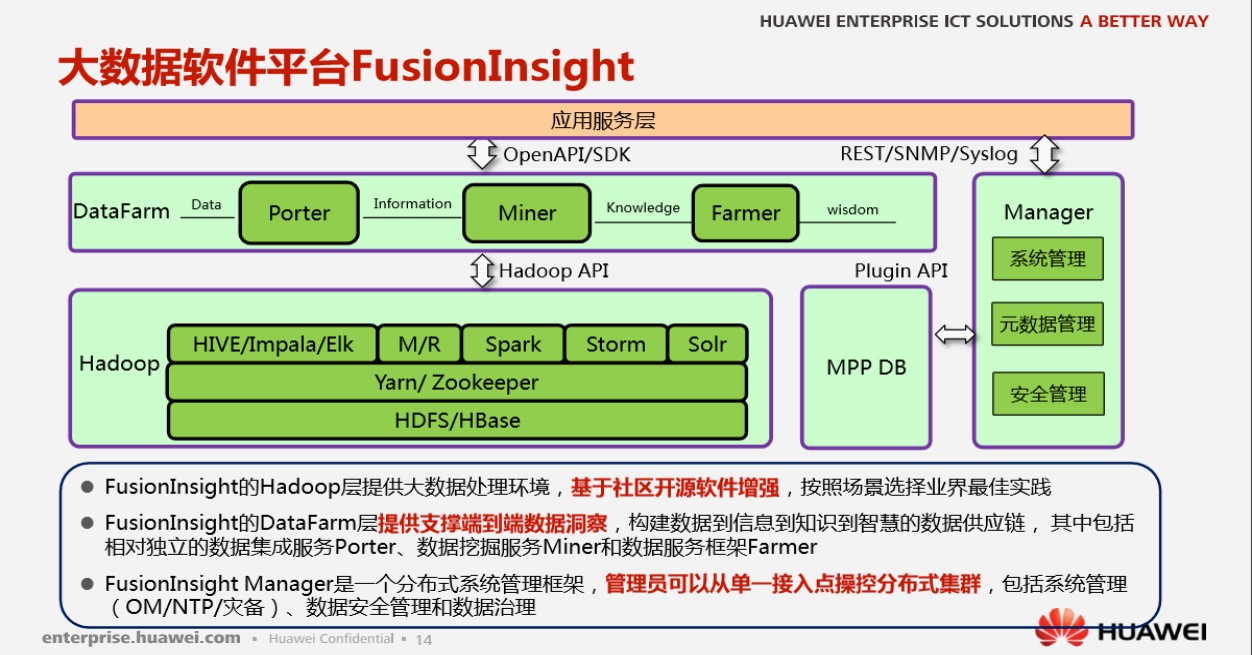
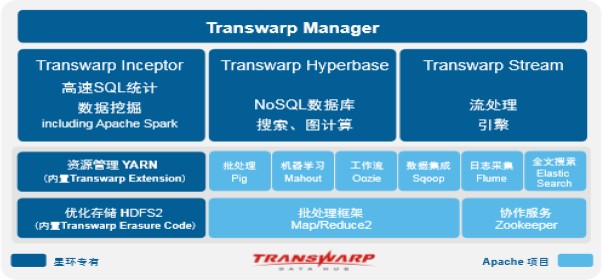
1.2.6 数据仓库元数据管理
元数据(MetaData),主要记录数据仓库中模型的定义,各层级间的映射关系、监控数据仓库的数据状态及ETL的任务运⾏状态,⼀般会通过元数据质量库(Metadata Repository)来统⼀地存储和管理元数据,其主要⽬的是使数据仓库的设计、部署、操作和管理能达成协同和⼀致,保证数据质量。
元数据是数据仓库管理系统的重要组成部分,元数据管理是企业级数据仓库中的关键组件,贯穿数据仓 库构建的整个过程,直接影响着数据仓库的构建、使⽤和维护。
构建数据仓库的主要步骤之⼀是ETL,这时元数据将要发挥重要的作⽤,它定义了源数据系统到数据仓库 的映射、数据转换的规则、数据仓库的逻辑结构、数据更新规则、数据导⼊历史记录以及装载周期等相关内容。数据抽取和转换的专家以及数据仓库管理员正是通过元数据⾼效地构建数据仓库。
⽤户在使⽤数据仓库时,通过元数据访问数据,明确数据项的含义以及定制报表数据仓库的规模及其复 杂性离不开正确的元数据管理,包括增加或移除外部数据源,改变数据清洗⽅法,控制出错的查询以及 安排备份等。
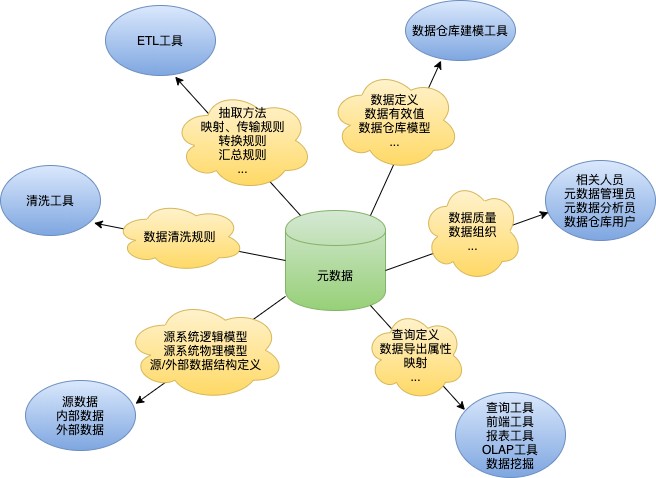
元数据分为技术元数据和业务元数据
1. 技术元数据为开发和管理数据仓库的IT⼈员使⽤, 描述了与数据仓库开发、管理和维护相关的数据, 包含数据源信息、数据转换描述、数据仓库模型、数据清洗与更新规则、数据映射和访问权限等
2. 业务元数据为管理层和业务分析⼈员服务,从业务⻆度描述数据包括商务术语、数据仓库中有什么数 据、数据的位置和数据的可⽤性等
元数据不仅定义了数据仓库中数据的模式、来源、抽取和转换规则等、⽽且是整个数据仓库系统运⾏的 基础,它把数据仓库系统中各个松散的组件联系起来,组成了⼀个有机的整体。
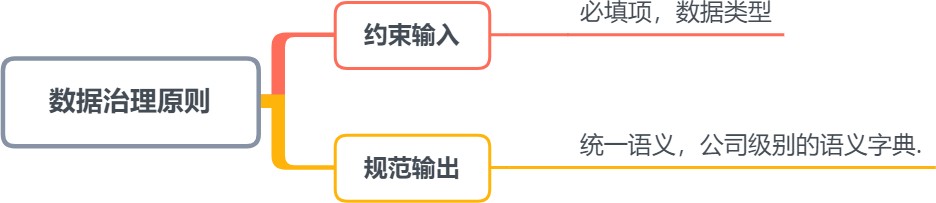
1.2.7 数据治理
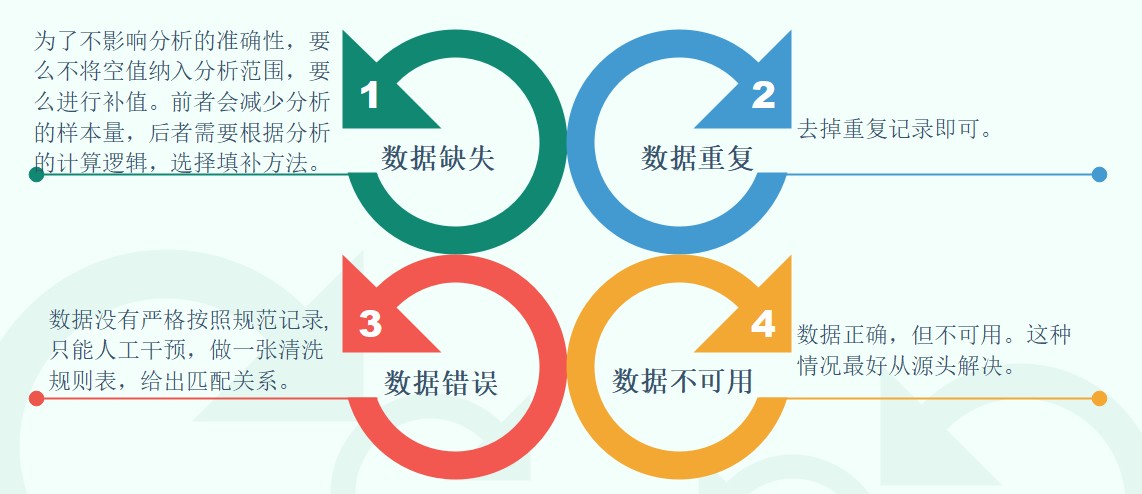
数据是企业 核⼼资产,数据治理能成就企业(特别是银⾏)的未来。它涉及数据质量、数据管理、数据政策、商业过程管理、⻛险管理等多个领域。
脏数据的种类
1.3 Hadoop概述
1.3.1 Hadoop简介

Hadoop是什么?简单来说,Hadoop就是解决⼤数据时代下海量数据的存储和分析计算问题。
Hadoop不是指具体的⼀个框架或者组件,它是Apache软件基⾦会下⽤Java语⾔开发的⼀个开源分布式计算平台,实现在⼤量计算机组成的集群中对海量数据进⾏分布式计算,适合⼤数据的分布式存储和计 算,从⽽有效弥补了传统数据库在海量数据下的不⾜。
1.3.2 Hadoop优点
⾼可靠性:Hadoop按位存储和处理数据的能⼒值得⼈们信赖
⾼扩展性:Hadoop是在可⽤的计算机集群间分配数据并完成计算任务,这些集群可以⽅便地扩展到数以千计的节点中
⾼效性:Hadoop能够在节点之间动态地移动数据,并保持各个节点的动态平衡,因此处理速度⾮常快
⾼容错性:Hadoop能够⾃动保存数据的多个副本,并且能够⾃动将失败的任务重新分配低成本:Hadoop是开源的,项⽬的软件成本因⽽得以⼤⼤降低
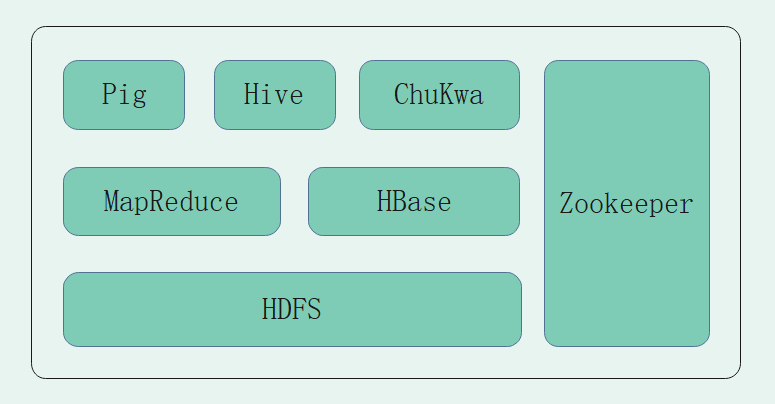
1.3.3 Hadoop⽣态圈
1.3.4 分布式存储(HDFS)
HDFS就是将⽂件切分成固定⼤⼩的数据块block(⽂件严格按照字节来切,所以若是最后切得省⼀点点,也算单独⼀块,hadoop2.x默认的固定⼤⼩是128MB,不同版本,默认值不同.可以通过Client端上传⽂件设置),

HDFS 的优点:
分布式存储
⽀持分布式和并⾏计算
⽔平可伸缩性
1.3.5 分布式计算(MapReduce)
MapReduce为海量的数据提供了计算.
MapReduce从它名字上来看就⼤致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将
⼀个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结 果。MapReduce采⽤”分⽽治之”的思想,简单地说,MapReduce就是”任务的分解与结果的汇总”。

若有收获,就点个赞吧
0 人点赞
