- 第⼗三部分 分组聚合
- 2、分组直接调⽤函数进⾏聚合# 按照性别分组,其他列均值聚合
df.groupby(by = ‘sex’).mean().round(1) # 保留1位⼩数
# 按照班级和性别进⾏分组,Python、Keras的最⼤值聚合
df.groupby(by = [‘class’,’sex’])[[‘Python’,’Keras’]].max() # 按照班级和性别进⾏分组,计数聚合。统计每个班,男⼥⼈数df.groupby(by = [‘class’,’sex’]).size()
# 基本描述性统计聚合
df.groupby(by = [‘class’,’sex’]).describe() - 5、透视表
# 透视表也是⼀种分组聚合运算
def count(x):
return len(x) df.pivot_table(values=[‘Python’,’Keras’,’Tensorflow’],# 要透视分组的值
index=[‘class’,’sex’], # 分组透视指标
aggfunc={‘Python’:[(‘最⼤值’,np.max)], # 聚合运算
‘Keras’:[(‘最⼩值’,np.min),(‘中位数’,np.median)],
‘Tensorflow’:[(‘最⼩值’,np.min),(‘平均值’,np.mean),(‘计
数’,count)]})
第⼗三部分 分组聚合

第⼀节 分组
import numpy as np import pandas as pd # 准备数据
df = pd.DataFrame(data = {‘sex’:np.random.randint(0,2,size = 300), # 0男,1⼥
‘class’:np.random.randint(1,9,size = 300),#1~8⼋个班
‘Python’:np.random.randint(0,151,size = 300),#Python
成绩
‘Keras’:np.random.randint(0,151,size =300),#Keras成绩
‘Tensorflow’:np.random.randint(0,151,size=300), ‘Java’:np.random.randint(0,151,size = 300),
‘C++’:np.random.randint(0,151,size = 300)})
df[‘sex’] = df[‘sex’].map({0:’男’,1:’⼥’}) # 将0,1映射成男⼥
# 1、分组->可迭代对象 # 1.1 先分组再获取数据
g = df.groupby(by = ‘sex’)[[‘Python’,’Java’]] # 单 分 组
for name,data in g: print(‘组名:’,name) print(‘数据:’,data)
df.groupby(by = [‘class’,’sex’])[[‘Python’]] # 多 分 组# 1.2 对⼀列值进⾏分组df[‘Python’].groupby(df[‘class’]) # 单分组df[‘Keras’].groupby([df[‘class’],df[‘sex’]]) # 多 分 组# 1.3 按数据类型分组
df.groupby(df.dtypes,axis = 1)
# 1.4 通过字典进⾏分组
m =
{‘sex’:’category’,’class’:’category’,’Python’:’IT’,’Keras’:’IT’,’Tensorflow’:’I T’,’Java’:’IT’,’C++’:’IT’}
for name,data in df.groupby(m,axis = 1): print(‘组名’,name)
print(‘数据’,data)
第⼆节 分组聚合
2、分组直接调⽤函数进⾏聚合# 按照性别分组,其他列均值聚合
df.groupby(by = ‘sex’).mean().round(1) # 保留1位⼩数
# 按照班级和性别进⾏分组,Python、Keras的最⼤值聚合
df.groupby(by = [‘class’,’sex’])[[‘Python’,’Keras’]].max() # 按照班级和性别进⾏分组,计数聚合。统计每个班,男⼥⼈数df.groupby(by = [‘class’,’sex’]).size()
# 基本描述性统计聚合
df.groupby(by = [‘class’,’sex’]).describe()
第三节 分组聚合apply、transform
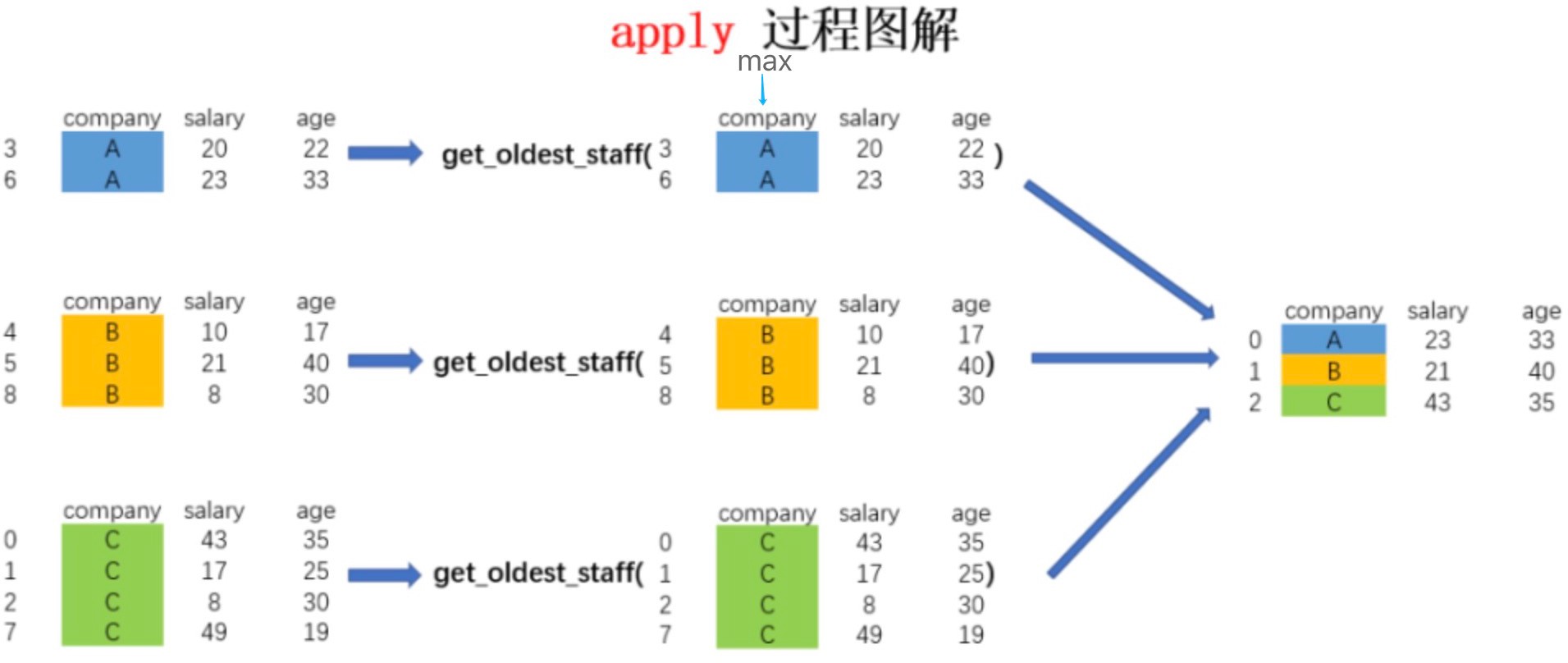
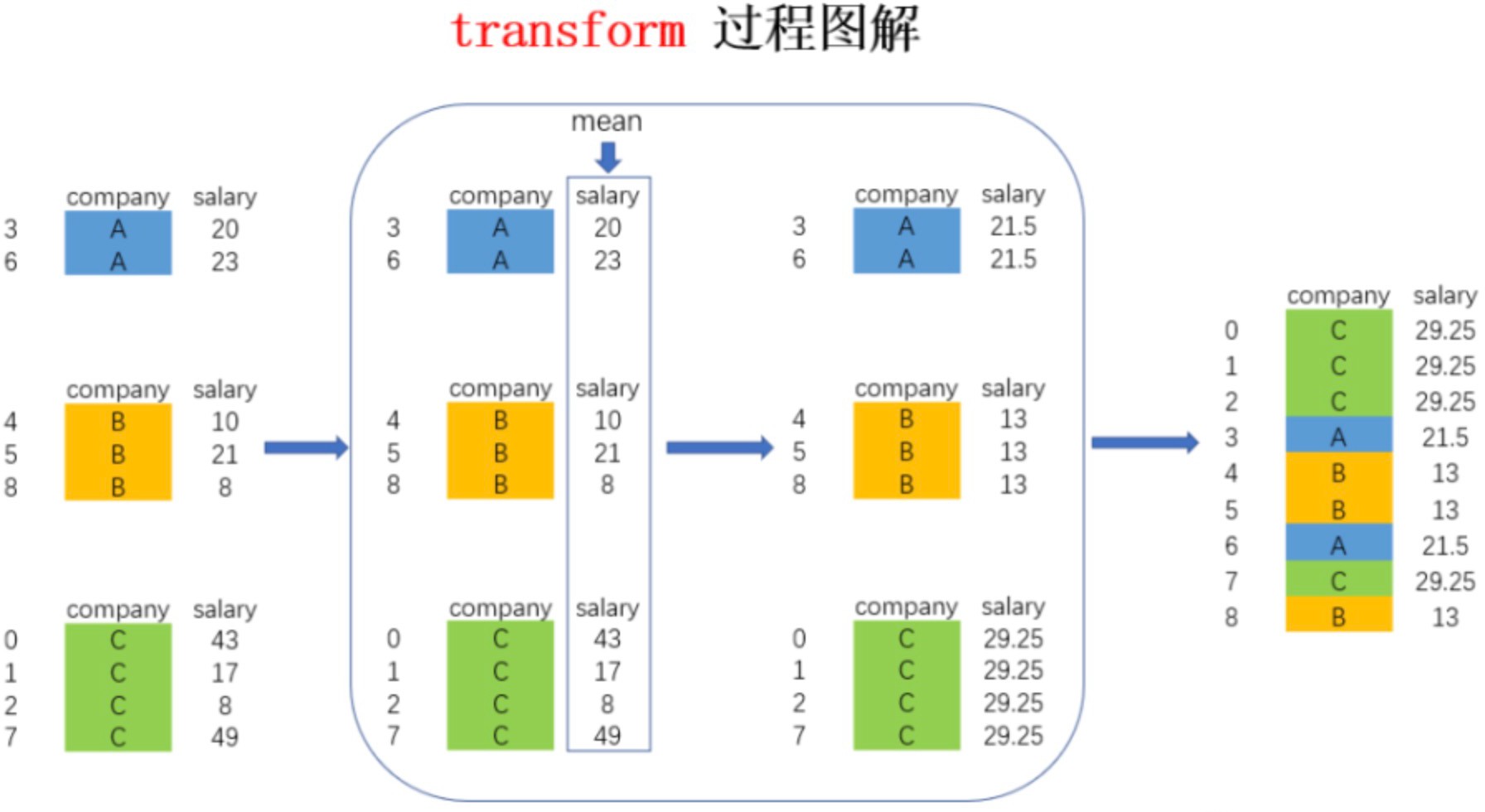
# 3、分组后调⽤apply,transform封装单⼀函数计算# 返回分组结果
df.groupby(by = [‘class’,’sex’])[[‘Python’,’Keras’]].apply(np.mean).round(1) def normalization(x):
return (x - x.min())/(x.max() - x.min()) # 最⼤值最⼩值归⼀化
# 返回全数据,返回DataFrame.shape和原DataFrame.shape⼀样。
df.groupby(by = [‘class’,’sex’]) [[‘Python’,’Tensorflow’]].transform(normalization).round(3)
第四节 分组聚合agg
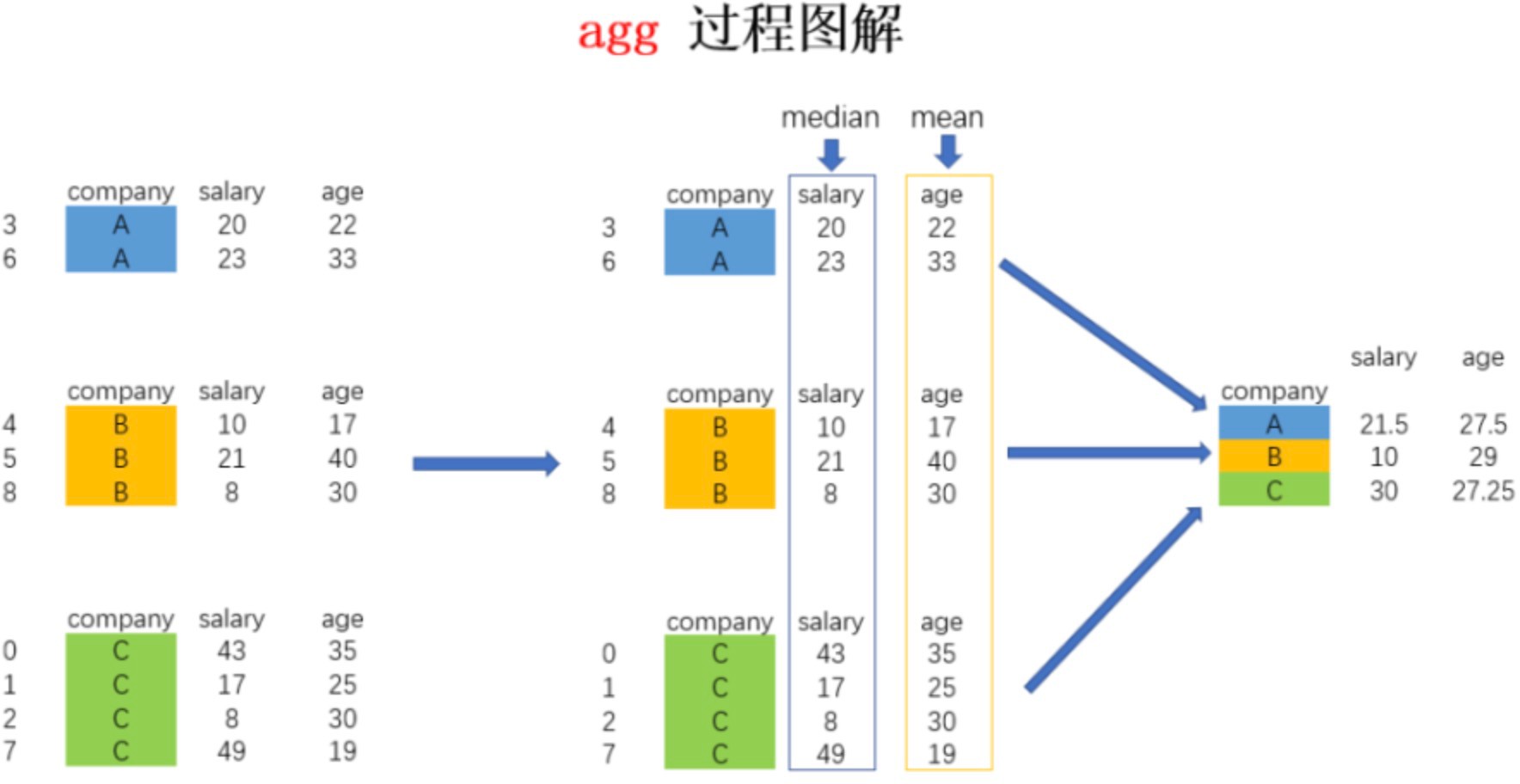
# 4、agg 多中统计汇总操作
# 分组后调⽤agg应⽤多种统计汇总
df.groupby(by = [‘class’,’sex’]) [[‘Tensorflow’,’Keras’]].agg([np.max,np.min,pd.Series.count])
# 分组后不同属性应⽤多种不同统计汇总
df.groupby(by = [‘class’,’sex’])[[‘Python’,’Keras’]].agg({‘Python’:[(‘最⼤值’,np.max),(‘最⼩值’,np.min)],
‘Keras’:[(‘计
数’,pd.Series.count),(‘中位数’,np.median)]})
第五节 透视表pivot_table
5、透视表
# 透视表也是⼀种分组聚合运算
def count(x):
return len(x) df.pivot_table(values=[‘Python’,’Keras’,’Tensorflow’],# 要透视分组的值
index=[‘class’,’sex’], # 分组透视指标
aggfunc={‘Python’:[(‘最⼤值’,np.max)], # 聚合运算
‘Keras’:[(‘最⼩值’,np.min),(‘中位数’,np.median)],
‘Tensorflow’:[(‘最⼩值’,np.min),(‘平均值’,np.mean),(‘计
数’,count)]})

若有收获,就点个赞吧
0 人点赞
