Yann LeCun等人挺系统地写了个博客聊self-supervised learning,大概读一遍。作者首先认为AI落后于人的点在common sense,也就是常识。而self-supervised learning可以帮助AI克服这个困难。作者认为SSL之于AI相当于常识之于人类,难以被意识到但无处不在而作用不可小觑,可谓AI界暗物质。先来看看什么是SSL。
图中表示的是input,绿色是可见部分,灰色是隐藏部分,SSL就是根据绿色预测灰色。
作者又给出了对SSL的统一认识。引入概念EBM,energy-based model。
EBM测量观测x和提出的预测y之间的兼容性。如果x和y是相容的,能量是一个小数字;如果它们不相容,能量会更大。训练一个EBM有两个要素,一个就是要相容的energy小,另一个就是不相容的energy要大。
比较熟悉的联合嵌入joint embedding就用到了EBM。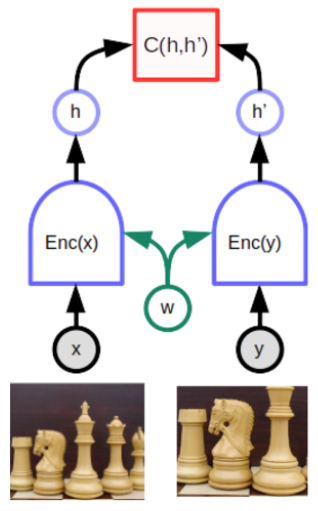
图中的C函数输出energy,也就是embedding的距离的计算,两个encoder采用了参数共享,使相似图片的embedding得以相近。有个概念叫collapse,就是如果不将不相容的x和y拉开的话,两边embedding就会不分敌我地接近。为了避免collapse有两个方法,contrastive方法和regularization方法。
contrastive方法很简单,就设计两个不兼容的x和y,训练让他们的energy很大。在NLP领域具体的contrastive方法为,制造一些corrupted的input,训练时对应的y是原始的。那些uncorrupted的文本重构回自身,而corrupted的那些重构为uncorrupted的版本。这个重构error可以看作EBM中的energy。energy大的时候就是重构得不够接近,反之就是重构得很接近。
上面介绍的叫denoising auto-encoder,构造如上图所示。y是完整的那个,x是corrupted version。
有一个值得注意的问题,就是一个input对应一个prediction,而我们想要的是模型能给出一些备选的prediction,如果是words可以给出一个vocabulary里各个word的score。当然这个trick对image是没用的,作者提了一个可取的方法叫latent-variable predictive architecture,如下图所示:
这个框架多了一个输入z,称为latent,即隐变量。z不同,prediction也不同。有隐变量模型采取了contrastive方法,比较广为人知的就是GAN。不过训练起来效率不高。
接下来介绍non-contrastive方法。作者说这个领域很promising,而且大概率需要隐变量的作用,其中的难点就是隐变量的容量空间需要最小化,从而控制energy(这段不是很懂)。比较成功的方法是VAE,但是在下游任务表现并不佳。
最后作者说了一些自己的research,就不多说了。
挺好的一篇科普文章,适合我这种废物入门。下一个目标读一下他提了好多遍的SwAV吧。

若有收获,就点个赞吧
0 人点赞
