这篇发到ICLR 2018了,组会讲这个。
题目中说知识库KB,以前读的都是关于知识图谱KG的。查了一下资料,KB是一种用于存储计算机系统使用的复杂的结构化和非结构化信息的技术。KG可以看作实现KB的对象模型。其实可以当成一种东西(至少这篇文章里是)。文章里有一个很简明的例子来说明要完成的任务,提问Who did Malala Yousafzai share her Nobel Peace prize with? 在知识图谱中就是一个链接预测任务(Malala Yousafzai, SharesNobelPrizeWith, ?),可以根据路径Malala Yousafzai -> WonAward -> Nobel Peace Prize 2014 -> AwardedTo -> Kailash Satyarthi来回答。
本文提出了一种基于输入问题的强化学习来有效地搜索提供答案路径的图的方法,消除了预先计算路径的需要。给定一个知识图谱,要学习一个policy,输入是一个查询(entity1, relation, ?),从entity1出发,每一步选择一个带标签的关系,以已知的relation和历史路径为条件,学习走到?的节点作为问题的回答。所以强化学习的目标就是找一条最优路径最大化期望奖励。作者将这个RL的agent叫MINERVA(Meandering In Networks of Entities to Reach Verisimilar Answers)。
看到这里就很疑惑,这和DeepPath有什么区别呢?作者也及时给出了解释。回忆DeepPath,它完成的是在一对实体中找路径的任务,其state里包括了\e_target也就是目标实体的embedding,所以验证算法中返回的是1和0也就是看DeepPath推出的路径对不对。这一点和MINERVA有本质区别,因为MINERVA干的是查询的工作,\e_target是未知的。在开始讲解模型之前明确这一点是很重要的。
1. Task and Model
知识图谱的设定不变。有一个额外操作就是在图中添加了逆关系,已经(e1, r, e2),加入代表(e2, r-1, e1)的边。
环境定义为马尔科夫决策过程。接下来做详细介绍。
1.1 Environment - States, Actions, Transitions and Rewards
环境是一个有限范围的,确定性的,部分可观测的MDP,是一个五元组(S, O, A, \delta, R)。
States
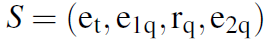 ,输入的查询为(e_1q, r_q),回答为(e_2q),当前探索位置为\e_t。
,输入的查询为(e_1q, r_q),回答为(e_2q),当前探索位置为\e_t。
Observations
state是无法观测到的,因为有回答存在。所以定义observation为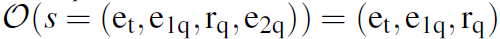 。
。
Actions
对于t时刻的state,其action为节点\e_t的所有出边。每个state的agent都会在已知边r的标签和通向节点v的前提下选择走哪条边。形式化表示就是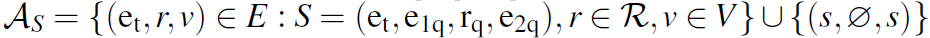 。
。
实践过程中,作者将计算图展开到确定的计算步骤数T。于是设置每个节点都会有一个特殊的action叫NO_OP,指自己到自己,为了让agent可以在某个节点处停下。当t
Transition
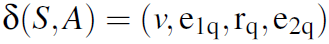 。
。
Rewards
1.2 Policy Network
设计policy为 。这里的
。这里的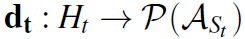 ,而
,而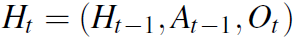 是已有的observation和action的序列。policy是由LSTM参数化的。agent将历史编码为连续的向量
是已有的observation和action的序列。policy是由LSTM参数化的。agent将历史编码为连续的向量 。关系和实体也有嵌入式矩阵表示,分别为
。关系和实体也有嵌入式矩阵表示,分别为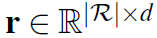 和
和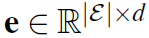 。通过动态LSTM来对历史进行更新:
。通过动态LSTM来对历史进行更新: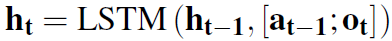
a和o分别代表action/edge和observation/entity,都是d维向量。[;]代表拼接操作。 ,即t-1时刻agent选择的标签对应的边的embedding,以及t时刻所处的实体的embedding。
,即t-1时刻agent选择的标签对应的边的embedding,以及t时刻所处的实体的embedding。
每个action的embedding用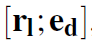 来表示。l是relation的标签,d是通往的节点。所有出边得到的action可以堆栈组成action矩阵A_t。policy网络是一个两层的向前传播网络,输出是一个概率分布。
来表示。l是relation的标签,d是通往的节点。所有出边得到的action可以堆栈组成action矩阵A_t。policy网络是一个两层的向前传播网络,输出是一个概率分布。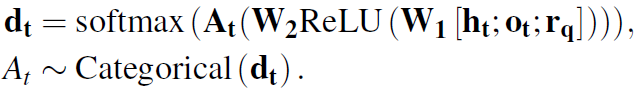
注意图中的节点没有固定顺序,出边数量也不定。A_t是一个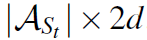 的矩阵,所以输出的概率分布是
的矩阵,所以输出的概率分布是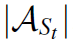 维的。
维的。
1.3 Training
上面提到的LSTM的参数以及W1和W2统称为policy网络的参数\theta。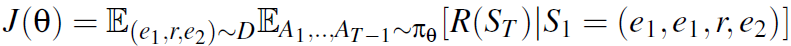
设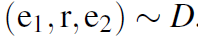 是一个潜在分布。
是一个潜在分布。
- 第一个期望用训练集中平均值代替(存疑,到底是个什么样的分布,如何计算,之后需要看代码)
- 第二个期望通过对每个训练示例运行多个rollout来进行近似。rollout=20。看了一下rollout在强化里是经验序列,可以理解成一条轨迹,跑一次实验的感觉。
- 为了减少方差,常用的策略是使用加性控制变量基线。作者使用累积折扣奖励的移动平均数作为基线,将这个移动平均值的权值作为超参数进行调整。实验发现使用习得的基线表现类似,但由于其简单性,最终以累积折扣奖励作为基线。
- 为了鼓励训练时策略所采样路径的多样性,将熵正则化项添加到以常数\beta为比例的代价函数中。
Loss部分代码解析
核心部分代码跳转。
计算强化学习的loss返回的total_loss由两个部分组成,很明显后一项是那个以\beta为系数的正则项,entropy_reg_loss是求熵H的函数。重点放在前一项。
初步感觉结合论文中提到了两个期望的实现,第一个用来tf.multinomial来采样一组最可能的action并以其值作为标签,第二个通过batch_size来实现。得到标签后与d_t结合,通过交叉熵计算loss。
再说详细一些免得以后忘了。
这个loss是一个reduce_sum的结果,也就是一个[B, 1]的数组的累加,这个B呢是在当前state有B种action的选择,是由MLP的输出定义的。计算这个loss的过程大致是,通过MLP可以得到一个[B, MAX_ACTION_NUM]的score,然后用tf.multinomial来采样,这个函数将每一行视作一个没有经过归一化的概率分布,按照这个概率进行随机采样,所以会得到一个[B, 1]的action_label序列。这里就比较奇怪,为什么在一个state要一个action序列呢?想想也很清楚,这是一个类似DP的事情,每步只选一个当然不合理,况且测试的时候还要拿前几名排序。再这样的基础上,我们有一个[B, 1]的action_label,有一个[B, MAX_ACTION_NUM]的score,再调用tf.nn.sparse_softmax_cross_entropy_with_logits这个函数,其中logits=score,label=action_label,也就是先对score每行进行softmax再求交叉熵,数学角度logits和label的对应关系有点像矩阵乘法,label那列和每行都进行一个熵H的求解。这个函数本来是用来做分类的,理解一下就是希望每一行对应的选择都尽量正确。
2. Experiments
实验展示了MINERVA的一些优势,大致分为:
- MINERVA在无论小型(2.1.1)还是大型(2.1.2)KB上的查询回答方面都具有竞争力
- MINERVA优于基于路径的模型,而且普通基于路径的模型还处理不了KB推理(2.2)
- MINERVA不仅可以用于格式良好的查询,还可以轻松处理部分结构化的自然语言查询(2.3)
- MINERVA在长链上具有很强的推理能力
- MINERVA训练稳健,推理时间快得多(2.5)
2.1 Knowledge Base Query Answering
注意因为提前不知道尾实体,所以链接预测和之前的不一样,是单向的。别的实验也会以同样的条件重跑对比。对于MINERVA在推理过程中生成答案实体的排序,我们进行束搜索(beam search),束宽为50,并根据模型所采取的轨迹到达实体的概率对实体进行排序,其余实体的排序为无穷。这里简单解释一下束搜索,大概是范围更大的贪心,知乎这个解释得就很好,大致意思就是因为是一个路径,所以每一步都有选择,当然每一步粗暴地选概率最大的action不一定是最佳选择,所以每一步选前50个大的。这样就能得到有顺序的50条路径以及其终点实体也就是回答了。2.1.1 Smaller Datasets
选用的小数据集为:COUNTRIES,KINSHIP和UMLS,一共三个任务,难度递增,前两个设置的最大路径长度T=2,第三个设置T=3。这是AUC-PR的结果,可以看到效果很不错。另外两个表现不太好,作者解释这些数据集不是为了测试模型的逻辑规则学习能力而设计的。
2.1.3 Larger Datasets
选用的大数据集为:WN18,FB15K,NELL。有2818个查询。显示的结果打不过一些baseline,作者也给了详细解释。一个原因是查询三元组只有一个答案,但有些1对N,N对1关系不止一个正确答案;另一个是存在一些并没有路径到达的答案。下面这张图纵轴代表路径类型数,横轴表示不同类型重复数。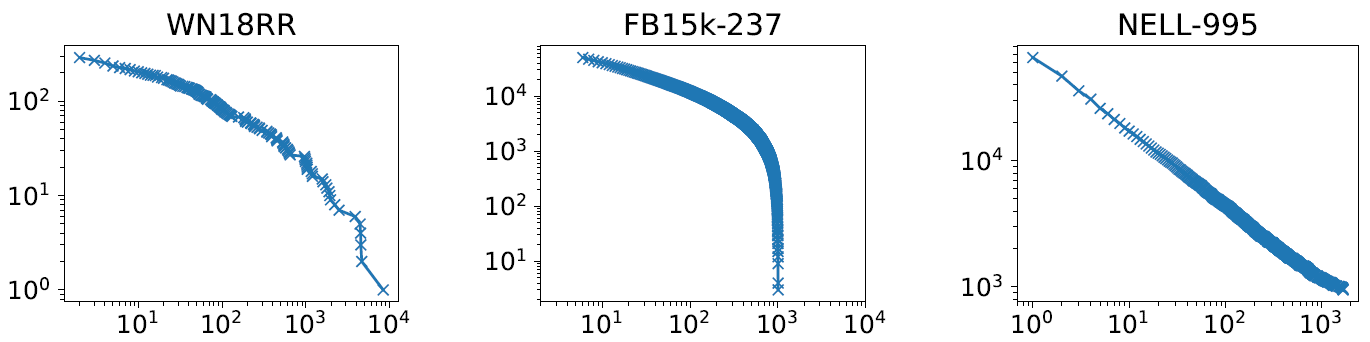
可以看到当FB15K有在1000次重复时类型数量急剧下降,说明这个路径重复并不多(原文:the path types do not repeat often)。而由于MINERVA无法找到经常重复的路径类型(原文:cannot find path types which repeat often),它发现很难学习一般化的路径类型。这也解释为什么FB15K效果最差。以上都是原文照搬,我理解了一下感觉挺矛盾的,既然FB15K里重复不多,而MINERVA找不到爱重复的,那么为什么就FB15K上效果不好了?之前的文章里也有提到,方差越小也就是越像,探索就会下降,所以道理上来说应该是FB15K重复不多就应该更好找。组会问一下。2.2 Comparison with Path Based Models
这个部分和Path-Baseline还有DeepPath做对比,效果都挺好。2.3 Partially Structured Queries
MINERVA可以处理非三元组的查询。譬如问题“Which is a film written by HerbFreed?”,可以从WikiMovies找到答案。通过简单的字符串匹配将问题中出现的实体链接到知识库中,并设计简单编码器计算问题的embedding的平均值。2.4 Grid World Path Finding
因为知识图谱需要走的步数不多,所以又补充了走网格的实验。从起点开始,定一个格子作为终点。这张图展示了MINERVA走网格,准确率很高。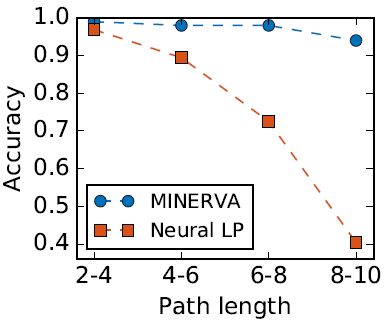
2.5 Further Analysis
MINERVA训练速度最快。测试时推断速度最快。会根据查询关系做决定。还有NO_OP,history,逆关系都是有效的要素。

若有收获,就点个赞吧
0 人点赞
