- 1. Introduction
- 2. Preliminaries
- 3. GPR-GNNS: Motivation and Contributions
- Generalized PageRanks
- Equivalence of the GPR method and polynomial graph filtering
- Universality with respect to node label patterns: Homophily versus heterophily
- The over-smoothing problem
- Mitigating graph heterophily and over-smoothing issues with the GPR-GNN model
- Placing GPR-GNNs in the context of related prior work
- 4. Theoretical Properties of GPR-GNNs
- 5. Results for New CSBM Synthetic and Real-world Datasets
《ADAPTIVE UNIVERSAL GENERALIZED PAGERANKGRAPH NEURAL NETWORK》
在许多重要的图形数据处理应用中,获取的信息包括两个:节点特征和图形拓扑。图形神经网络(GNNs)旨在利用两种证据来源,但它们不能最佳地权衡它们的效用,并以同样通用的方式整合它们。这里,普遍性指的是在同质或异质图形假设上的独立性。这篇文章通过引入一种新的Generalized PageRank GNN结构来解决这些问题,该结构自适应地学习广义预测权值,从而联合优化节点特征和拓扑信息提取,而不管节点标签是同质的还是异质的。学习的GPR权重自动调整到节点标签模式,与初始化的类型无关,从而保证了通常难以处理的标签模式的出色学习性能。此外,它们允许人们避免特征过度平滑,这一过程使得特征信息无歧视。GPR-GNN模型的伴随理论分析由上下文随机块模型完成。也进行了节点分类的对比。
1. Introduction
作者认为一个理想的学习方法应当能够同时和自适应地利用节点特征和图拓扑,因为可以充分利用二者的潜在联系。目前的很多GNN都是利用信息传递实现的,它们右堆叠的神经网络层构建,这些神经网络层本质上在给定的图拓扑上传播和变换节点特征。
然而大多数现有GNN都有两个基本弱点。
- 大多数GNN都是为同类(关联)图量身打造的。节点分类背景下的原则同质偏好认为同类节点之间更容易成边。图聚类以及许多GNN的设计中同质偏好都是常见的假设。这类方法对异类图并不友好。这里引入一下同类图和异类图的概念,论文中同类图叫homophic graph,异类图叫heterophilic graph,homophic这个词维基百科里的意思就是指个体更倾向于与他们相似的人交往和建立链结(即“物以类聚,人以群分”),而在某些特定的图比如dating图中,异性(不同类)更容易有连接。所以作者的意思就是很多GNN因为这个占了分类任务的便宜,处理同类图时某个节点的message都是通过其邻域譬如取均值来获取的,而对于异质图,领域信息的整合是更困难的。
- 现存大多GNN都不够“深”。理论上神经网络堆几层都行,但实践中往往2-4层表现出更好的效果。一个普遍接受的解释叫feature-over-smoothing。GNN特征传播的过程代表特征图上随机游走的一种形式,在适当的条件下,这些随机游走以指数速度收敛到平稳点。直白来说over-smooth的现象就是多次卷积后,同一连通分量内所有节点的特征都趋于一致了。
本文针对这两个问题提出GPR-GNN模型,结合了GNN和广义PageRank。GPR-GNN架构设计的目的是首先了解隐藏特征,然后通过GPR技术传播它们。这里来介绍一下PageRank。网络的重点组件就是GPR,它可以将每一步的特征传播和一个可学权重(learnable rate)相联系。这些权重取决于信息传播过程中不同步骤的贡献,它们可以是正的,也可以是负的。权值的幅值权衡了节点特征的平滑程度和拓扑特征的聚合能力。GNN-GPR模型可以同时学习不同类的节点标签,且避免特征过平滑。
模型将通过cSBM(contextual stochastic block model)验证节点和拓扑间的平衡以及处理同类异类两种图的特点。
2. Preliminaries
一些常规设置。G是无向图。有特征矩阵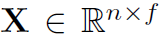 ,
,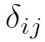 是kronecker delta函数(两个输入值,相等返回1,不等返回0)。A是图G的邻接矩阵,
是kronecker delta函数(两个输入值,相等返回1,不等返回0)。A是图G的邻接矩阵,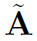 是加了self-loop的邻接矩阵,
是加了self-loop的邻接矩阵,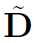 是其对角度矩阵,
是其对角度矩阵,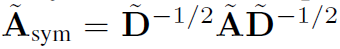 是带self-loop的对称归一化邻接矩阵。
是带self-loop的对称归一化邻接矩阵。
3. GPR-GNNS: Motivation and Contributions
Generalized PageRanks
熟知的PageRank就是用来计算不同网页影响力的算法,可视为节点的网络间存在互相影响,互相依赖。GPR用于无监督图聚类。选取一个种子节点s,使其为全为1的n维向量,其余节点为全为0的n维向量。GPR得分用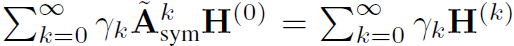 定义。参数\gamma_k是一个实数,称之为GPR权重。而图的聚类通过局部地为GPR得分设置阈值得到。另一种PPR,\gamma是固定的,不是学来的。
定义。参数\gamma_k是一个实数,称之为GPR权重。而图的聚类通过局部地为GPR得分设置阈值得到。另一种PPR,\gamma是固定的,不是学来的。
Equivalence of the GPR method and polynomial graph filtering
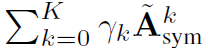 对应一个K阶的多项式filter。
对应一个K阶的多项式filter。
Universality with respect to node label patterns: Homophily versus heterophily
度量节点的同类程度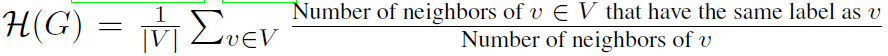 ,越接近1同类性越强,反之越弱。下面这张图,Cora是个同类图,Texas是个异类图。图b和图c展示的是它们习得的GPR权重。可以看到随着step的增加二者趋于稳定且差距很大,说明GPR对区分这两种图很有效。图a是GPR-GNN的模型结构图,红色的也就是GPR权重和\theta都是要训练学习的。
,越接近1同类性越强,反之越弱。下面这张图,Cora是个同类图,Texas是个异类图。图b和图c展示的是它们习得的GPR权重。可以看到随着step的增加二者趋于稳定且差距很大,说明GPR对区分这两种图很有效。图a是GPR-GNN的模型结构图,红色的也就是GPR权重和\theta都是要训练学习的。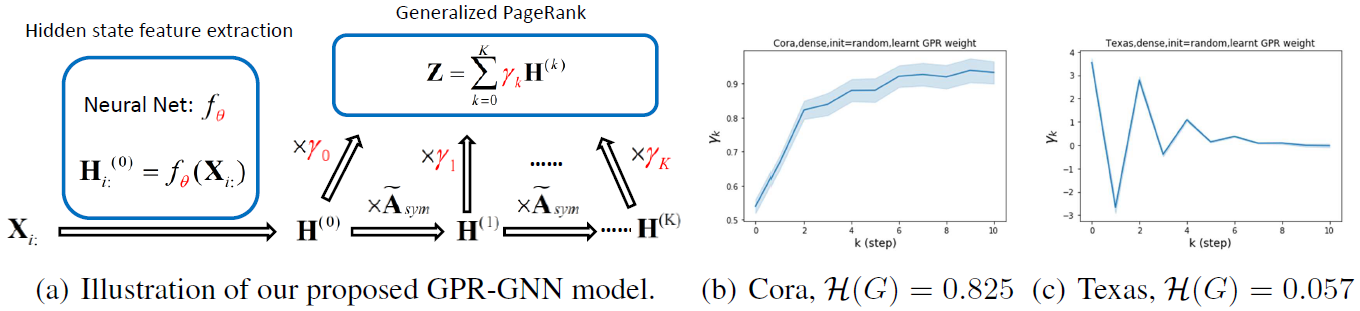
The over-smoothing problem
放上卷积公式: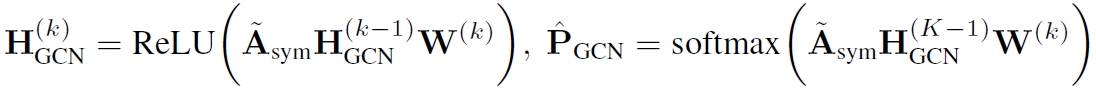
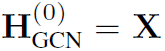 。如果去掉ReLU,便有
。如果去掉ReLU,便有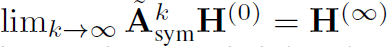 。说明随着层数的增加会丢失关键信息。
。说明随着层数的增加会丢失关键信息。
Mitigating graph heterophily and over-smoothing issues with the GPR-GNN model
GPR-GNN的整个流程: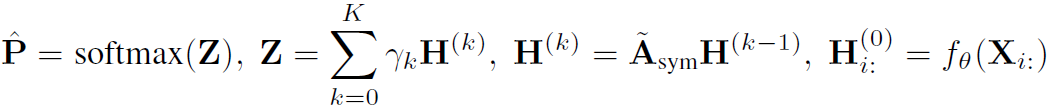
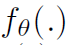 是参数集为\theta的神经网络,用来产生第0层。如前所述,GPR-GNN具有自适应控制每个传播步骤的贡献并将其调整到节点标签模式的能力。
是参数集为\theta的神经网络,用来产生第0层。如前所述,GPR-GNN具有自适应控制每个传播步骤的贡献并将其调整到节点标签模式的能力。
Placing GPR-GNNs in the context of related prior work
这里介绍两个相关工作,APPNP和SGC,它们都和GPR-GNNs有点像。APPNP是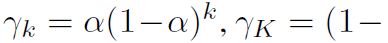
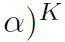 ,SGC比较简单粗暴
,SGC比较简单粗暴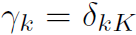 。
。
4. Theoretical Properties of GPR-GNNs
理论部分分析了两点,一个是图滤波器,一个是过平滑问题。GPR-GNN相比上文提到的APPNP和SGC(这两个越高频越压缩),允许\gamma_k小于0,所以高频信息可以通过滤波器,因此能处理异类图。
另一个平滑问题。倘若k超过k’时出现过平滑,可以让之后的\gamma趋于0,就可以消除过平滑。
5. Results for New CSBM Synthetic and Real-world Datasets
首先补充一个反复出现的概念置信区间confidence interval,一般用百分比表示,比如95%的置信区间。举例来说,如果在一次大选中某人的支持率为55%,而置信水平0.95上的置信区间是(50%,60%),那么他的真实支持率有百分之九十五的机率落在百分之五十和百分之六十之间,因此他的真实支持率不足一半的可能性小于百分之2.5(假设分布是对称的)。
Synthetic data
为了测试GNNs在任意水平同度图和异度图上的标签学习能力,作者提出使用cSBMs生成合成图,考虑两个大小相等的类的情况。cSBM中节点的特征是高斯随机向量。
实验设置检验了转导环境中的半监督节点分类任务。考虑了随机分裂成训练/验证/测试样本的两种不同选择,分别称之为稀疏分裂(2.5%/2.5%/95%)和密集分裂(60%/20%/20%)。稀疏分裂更类似于Kipf & Welling (2017)中考虑的原始半监督设置,而Pei等人(2019)中考虑的密集设置用于研究异度图。我们用多次随机拆分和不同的初始化将每个实验运行100次。
具体设置,K=10,2层MLP,64个hidden units,初始化包括PPR,\delta以及random初始化方法。
实验其他部分就不细看了,这里展示有图的地方。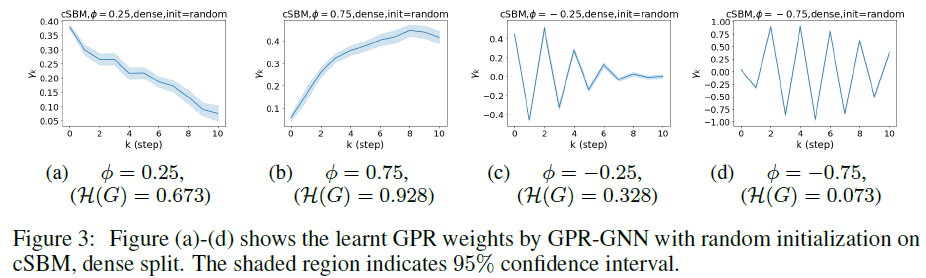
这张和前面那张很像,不加赘述。
这张需要说一下这个\phi是干嘛的。这个值等于1代表cSBM产生的图是完全同类的,而等于-1就是完全异类的。还可以说其绝对值等于1时只有图的拓扑是informative的,等于0时只有节点的特征是informative的。
Real world benchmark datasets

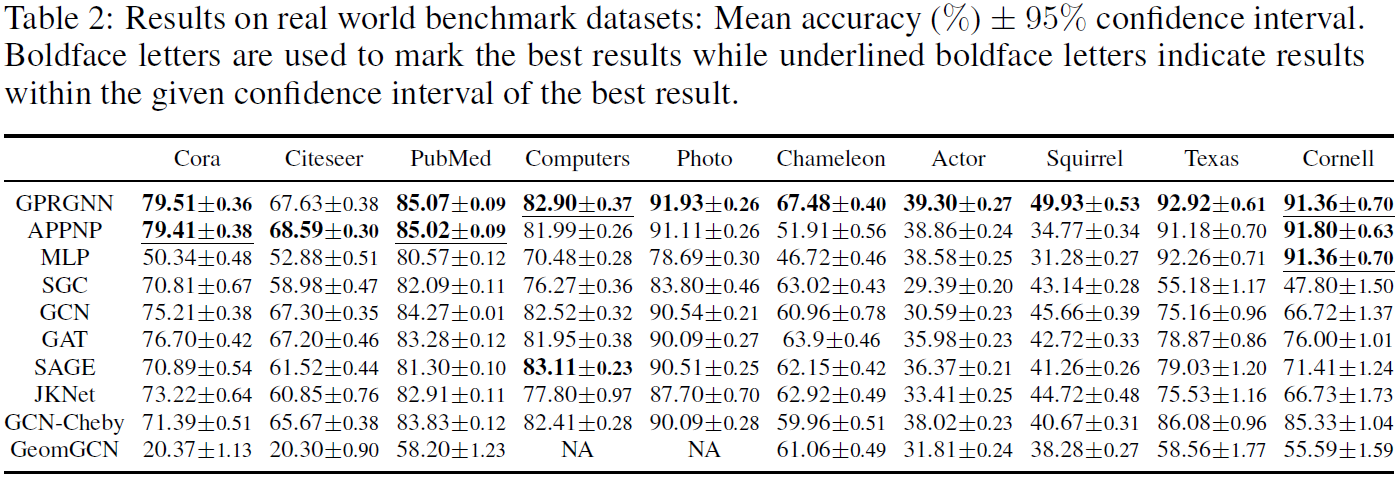
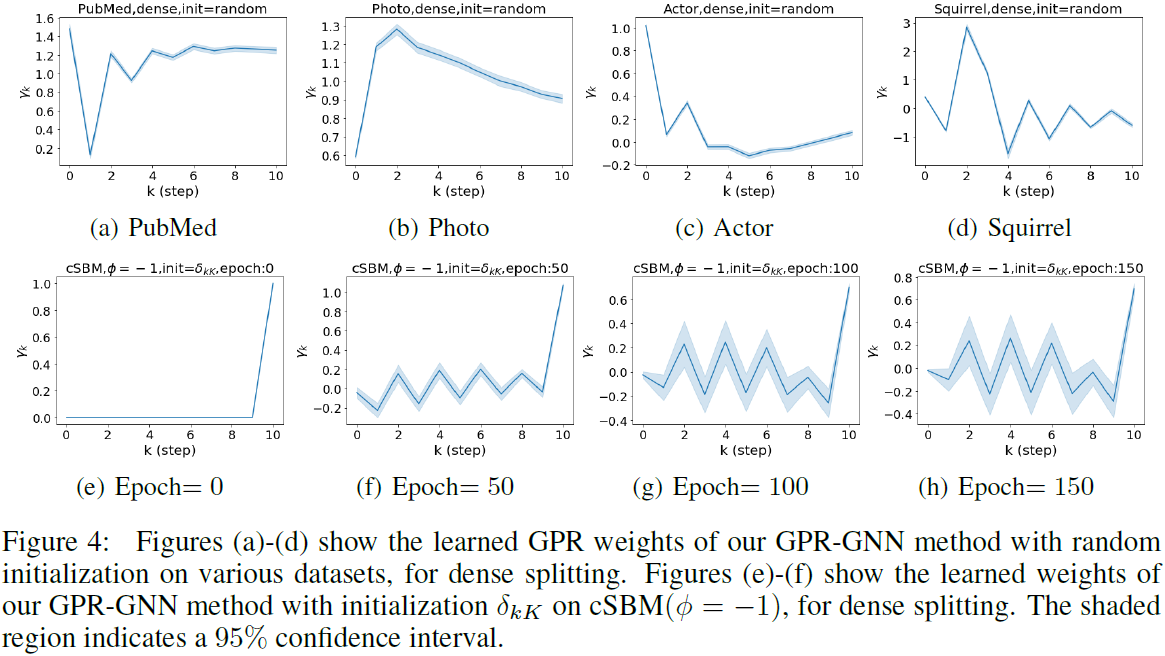
总得来说,GPR-GNN虽然结构简单,但是解决了异类图和层数变多就过平滑的问题,挺厉害的。

若有收获,就点个赞吧
0 人点赞
