《Nvae: A deep hierarchical variational autoencoder》
效果很不错,NVIDIA做的,可以让生成的图像很高清。
自VAE提出后,所有的改进都集中在统计学方面的修正,但是没有考虑模型网络结构方面的改进。所以这篇文章就在nn方面做了改进,mathematical的东西不多,也没太仔细研究,大致写一下收获。
首先看整体架构,是一个hierarchical的结构: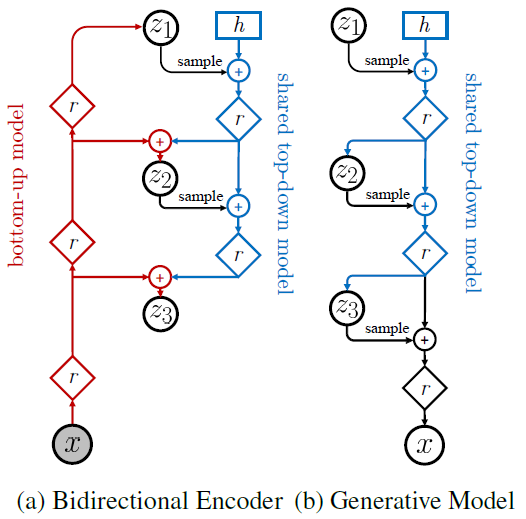
明确一下这里的隐变量z被分成了l个group,所以VAE的分布不管是先验还是后验都变成了联合分布。现在来看这个图,左半边是encoder,右半边是decoder。encoder是个双向的,输入x,通过这些被作者叫residual cell的东西,得到第一个符合某高斯分布的z1,然后又往下走,h是hidden state,sample后的zi与h做一个combination如拼接,又通过这个cell,如法炮制。decoder也差不多。现在就看看这些residual cell是什么。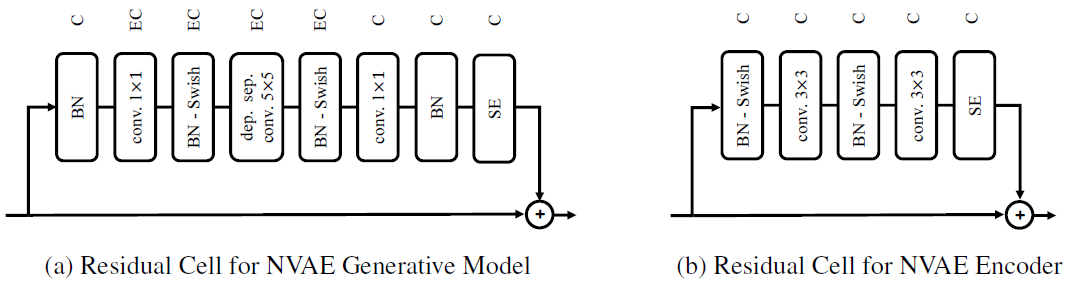
BN就是batch normalization,意为在神经网络的每一个layer中间再加一个BN layer,该layer就是对中间的输出做normalization,并且这个normalization的结果可以被做线性变换,w和b是可训练的。Swish是个激活函数。SE为Squeeze and Excitation,一个效果挺好的NN,不加赘述。
然后提一个trick,就是已知先验是一个正态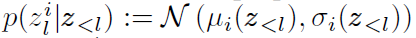 ,而后验在先验的基础上设置成
,而后验在先验的基础上设置成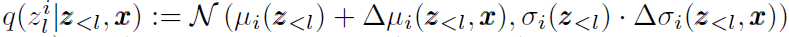 ,这样KL散度就很好算,写作:
,这样KL散度就很好算,写作: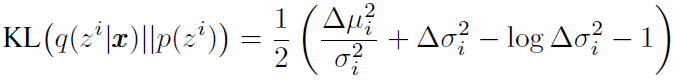
此外还有谱正则化等trick,感觉是一个集百家之长很炼丹的模型,不过效果好是毋庸置疑的,暂时就不dig了。

若有收获,就点个赞吧
0 人点赞
