《AUTOREGRESSIVE DIFFUSION MODELS》
这个模型的特点就是是order agnostic的,别的自回归模型会按序列顺序进行预测,而这个模型可以进行随机顺序的预测,不需要考虑因果关系,也可以并行进行预测,它还提出了一个upscaling方法。
下面的图就讲了预测过程,最左边一列都是未知的,以一个(3,1,2,4)的order进行预测。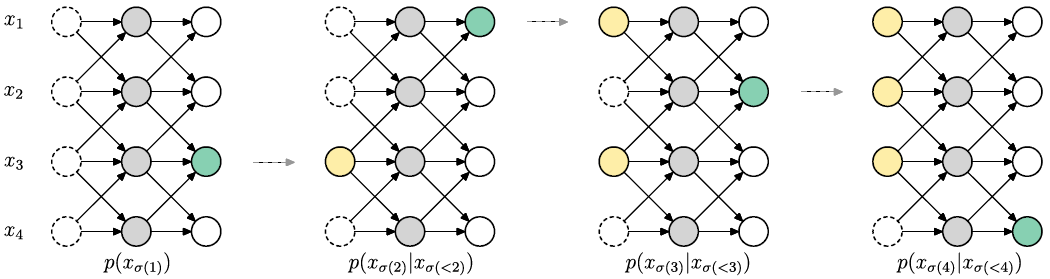
Order Agnostic ARDMs
先从OA-ARDMs开始。
首先在普通的ARM中,就是概率论知识,用前几步的连乘的结果代表最后一步: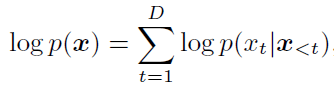
对于任意顺序,用期望表示,是用Jensen不等式推到的: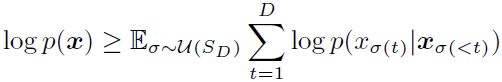
对于ARDMS的loss,作者是这么设计的,很简单的求和再平均的变形就不多说了: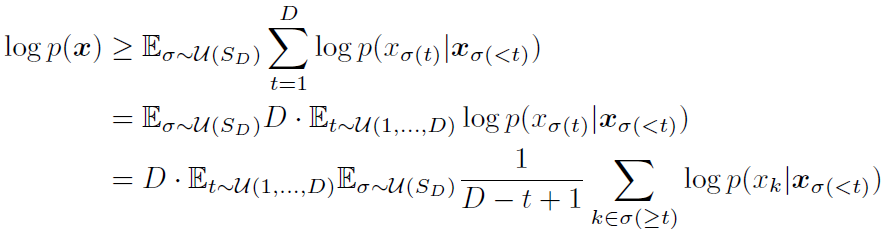
这里的D-t+1被mask掉。作者用D个Bert训练loss。
Parametrization
作者强调自己只用了一个神经网络,不因不同的sigma和t设计不同的神经网络。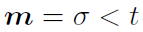 是一个boolean mask,神经网络的输入是D维向量X,每一维为1至K中一个数字,代表类别,训练时mask掉其中一部分,经过神经网络输出D乘K的矩阵,每一个entry代表对应位置(D)对应类别(K)的概率。令
是一个boolean mask,神经网络的输入是D维向量X,每一维为1至K中一个数字,代表类别,训练时mask掉其中一部分,经过神经网络输出D乘K的矩阵,每一个entry代表对应位置(D)对应类别(K)的概率。令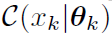 就是x在θ_k(为location概率)下的概率分布,即有
就是x在θ_k(为location概率)下的概率分布,即有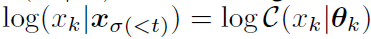 。算法如下,过程还是比较简单粗暴的,左边在sample,右边代公式计算loss。
。算法如下,过程还是比较简单粗暴的,左边在sample,右边代公式计算loss。
注意training时会一口气输出所有mask。对于不同的variable会输出不同的mask预测,所以有充足的signal来进行预测。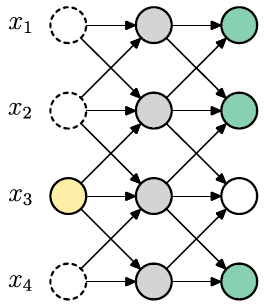
PARALLELIZED ARDMS
这里计算是并行的,可以提升计算速度,但相对也有trade off,就是精度会降低些。认为预测t后某几个步骤的loss和预测t时loss是一样的: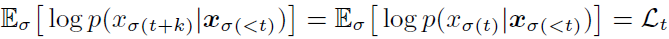
可以用动态规划的方法(作者没细说怎么规划),如下图:
黄色同样高度就是同时训练的。
DEPTH UPSCALING ARDMS
先解释一下upscaling在干嘛,其实就是对x先粗分类,再细分类。用transition matrix P来进行逆过程downscale,即为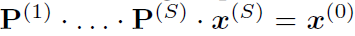 ,x0是个one-hot,也就是x最粗略的样子。有:
,x0是个one-hot,也就是x最粗略的样子。有: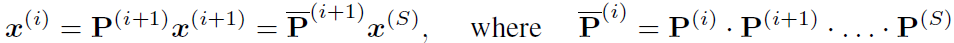
于是可以逆推upscaling,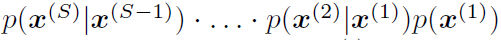 。在训练过程中加入sample一个stage的过程即可。
。在训练过程中加入sample一个stage的过程即可。
看看实验。完成的就是这种事情。over。

若有收获,就点个赞吧
0 人点赞
