ICLR 2020,论文名字如题。
首先了解KD,knowledge distillation,知识蒸馏,将teacher模型学到的东西给student模型,一般teacher是大型的,student是轻量的。一种方式的目标公式就是最小化teacher和student的输出的KL散度。但作者认为仅仅纵向对比输出是不够的,因为学到的表示保护结构信息,因此横向的依赖也需要被学习。
于是作者就提出解决方案,将对比学习的思想引入KD。论文主要贡献:
- 提出基于对比学习的深度网络之间的知识迁移方法。
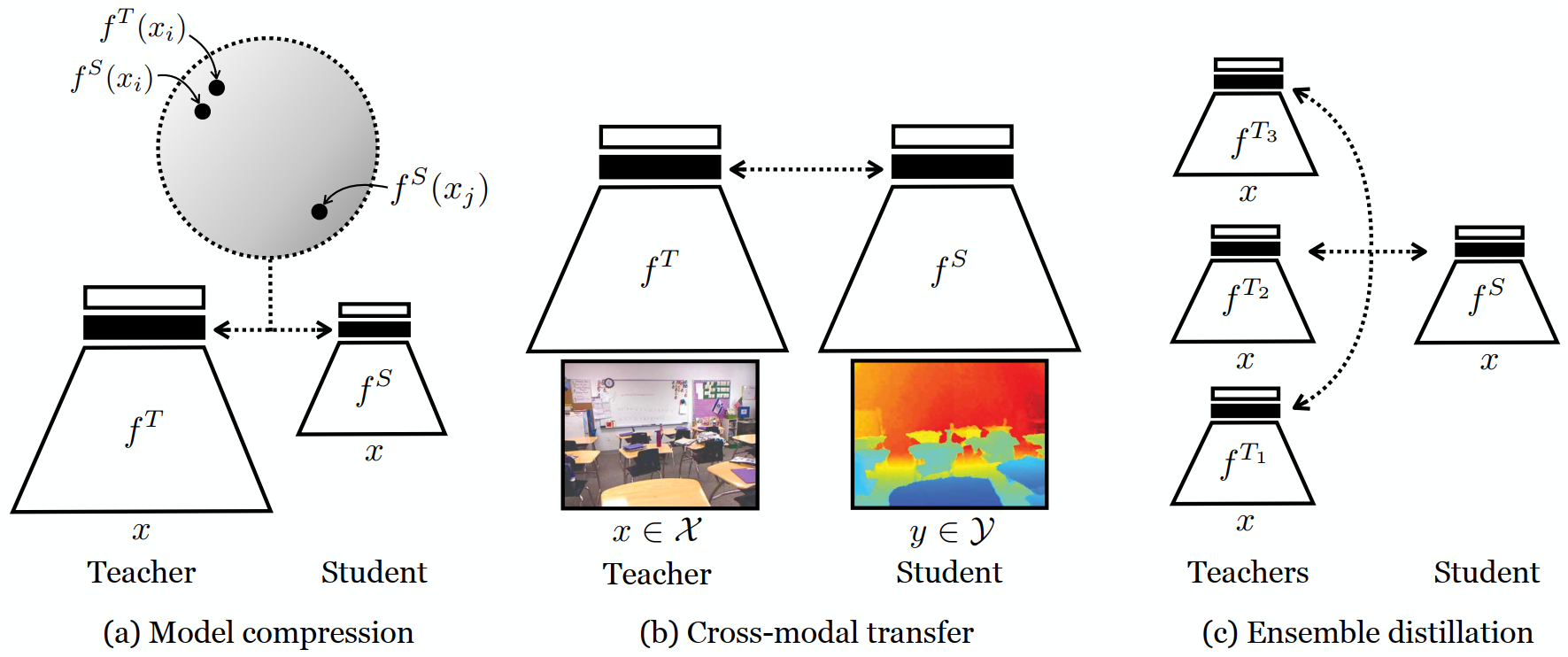
- 应用于模型压缩,跨模态传输和集成蒸馏。
- 实验好。
CONTRASTIVE LOSS
两个神经网络,一个teacher f^T,一个student f^S,x是网络的输入,倒数第二层是S和T,整体定义如下:
为了好算KL散度,又定义了分布q,里面包含隐变量C。C=0代表联合分布,C=1代表边缘分布乘积。作者说最大化这两种分布的KL散度可以最大化teacher和student之间的互信息。一开始想不通为什么这么说,来回归一下作者最初的思想——对比学习,原文如下:
就是说想不但想让对应x接近,还想让非对应x疏远,这就是对比学习的思想,而对比学习的公式是从最大化互信息的式子推出来的!于是就解释作者为什么这么做了:
假设一致的一对(正样本对)是来自联合分布的,不一致的(负样本对)来自边缘分布,前者1个对应后者N个。因此有C的先验: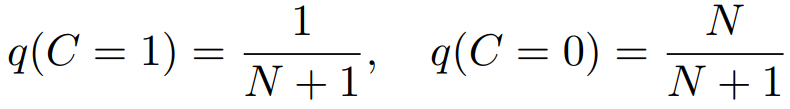
根据贝叶斯定律: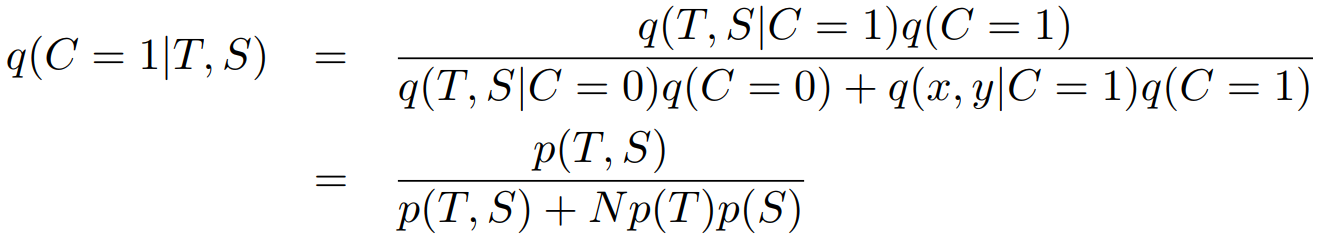
加log: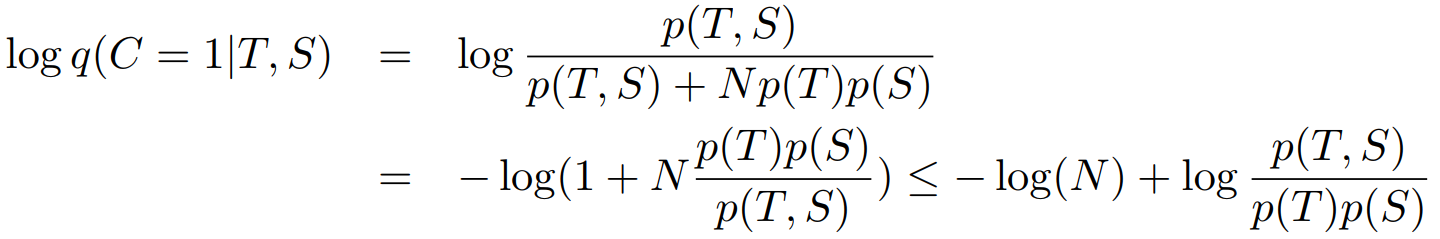
两边同时取期望:
这里的I是teacher和student的互信息。最大化后面的期望项就是提高下界。但是我们并不知道q分布,可以用模型来拟合。最大化对数似然作为模型的目标公式,也就是一个二分类模型。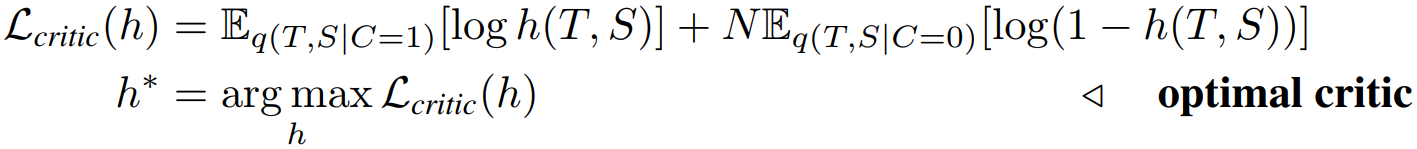
化简后得最终的目标: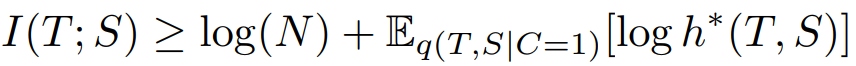
而我们想互信息最大化: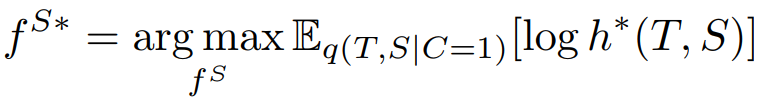
但这个式子最佳critic取决于当前student,所以松弛约束: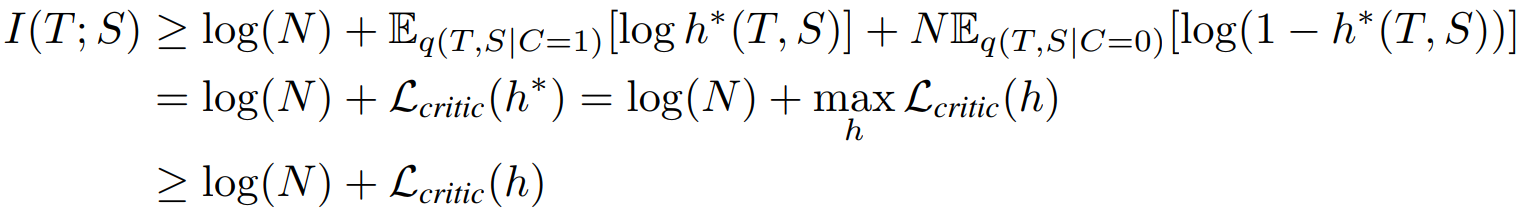
最终得到: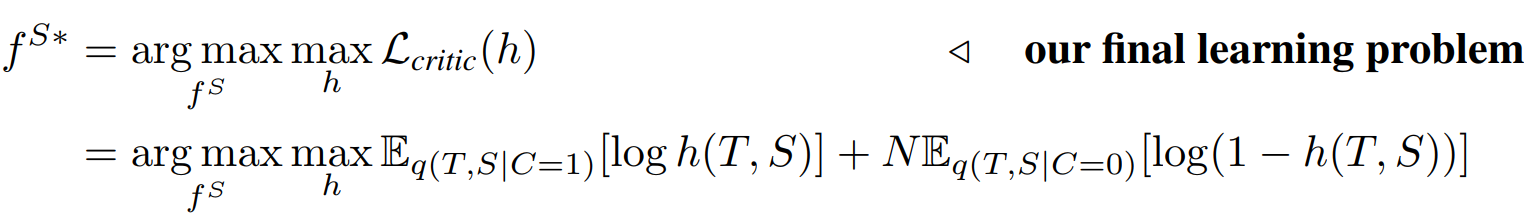
对h的定义: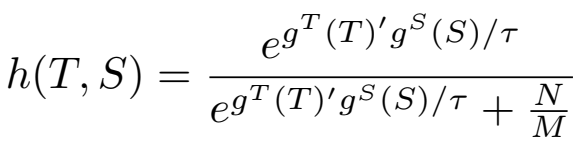
KNOWLEDGE DISTILLATION OBJECTIVE
知识蒸馏的loss,前一项是student和ground-truth,后一项是student和teacher,H就是交叉熵。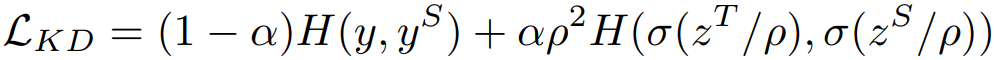
CROSS-MODAL TRANSFER LOSS
ENSEMBLE DISTILLATION LOSS
最后就是多个老师教一个学生: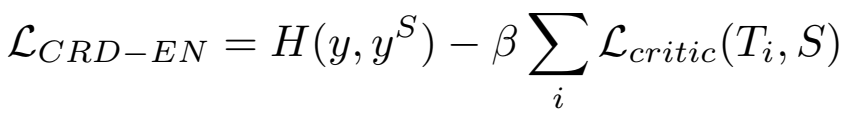
所以总体来看互信息和对比学习的思想很重要。

若有收获,就点个赞吧
0 人点赞
