ICLR 2022
作者估计关于模型有太多话要讲,所以连distribution alignment以及support alignment的背景和意义都不说,introduction里说为了实现更好的distribution alignment就要做support aligntment,fine。
这张图就对比了下distribution alignment和support alignment,首先什么是support,回忆一下支持向量机SVM,support其实就是点集,我们一般搞不到分布,但我们可以搞到分布中的数据,这些数据就叫support。这个图就说有两个分布,p和q,都是beta分布,q有个参数θ,可以shift。b和c是两种alignment的结果,W指wasserstain距离,另一个是本文用的SSD,可以看到support alignment的w距离和SSD散度还小很多。关于后两张图长得很怪,仔细看看其实就是分布图,只是q的位置不一样。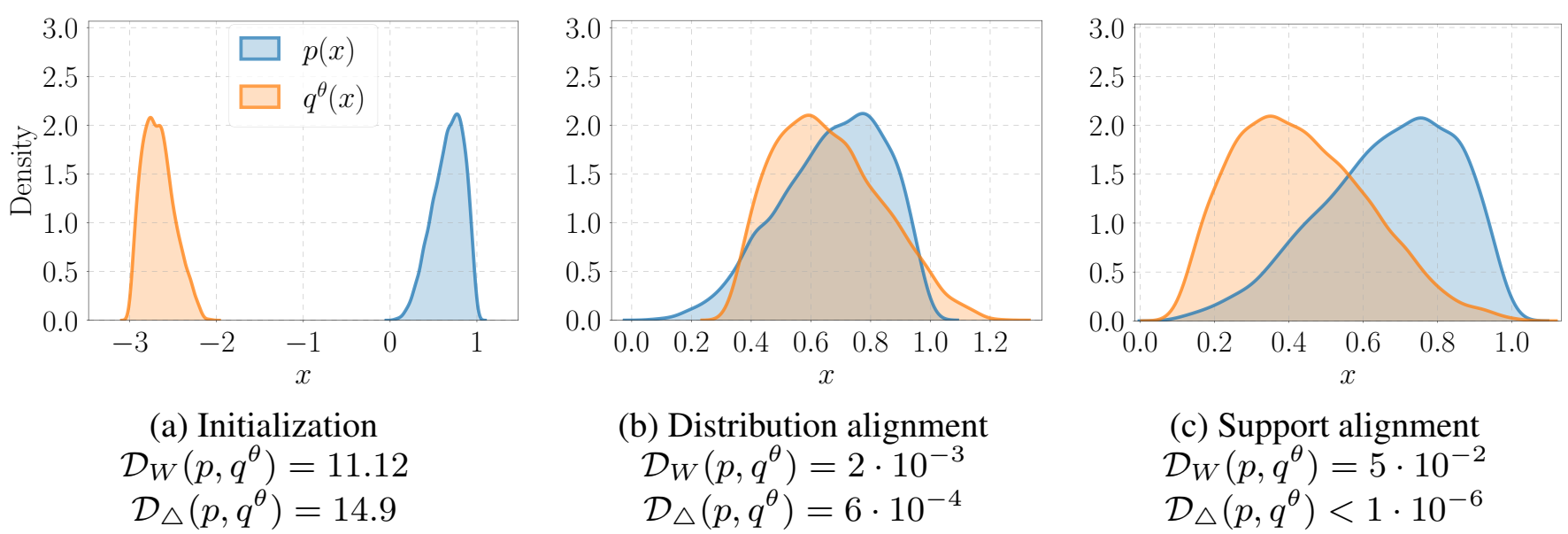
SSD DIVERGENCE AND SUPPORT ALIGNMENT
作者提出了SSD散度,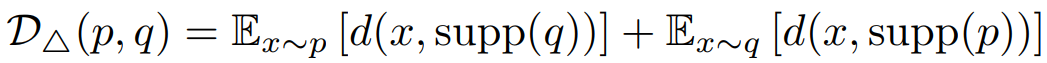
借用别人的工作,GAN中的discriminator可以用来计算p和q之间的Jensen-Shannon散度。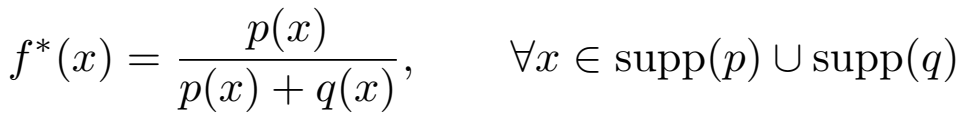

就是说可以对p和q做个f映射之后求距离,等价于求p和q的距离。
引出g,通过g表示f。
这里用了什么history buffer,
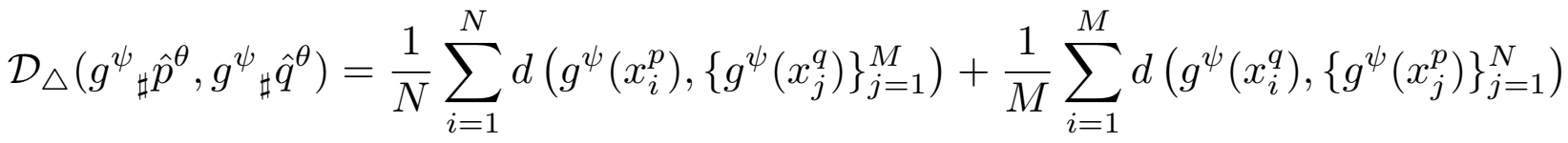
整个算法流程:
实验完成的是UDA,unsupervised domain adaption,就是用一个分布靠近另一个分布。
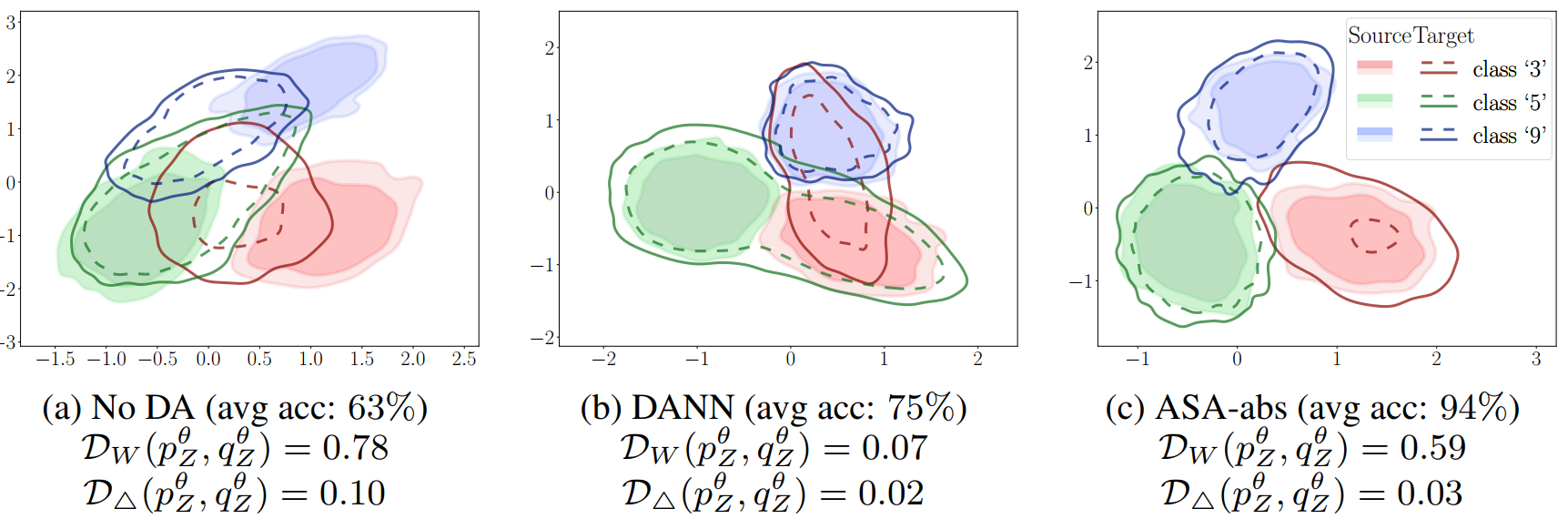
有点挠头,因为感觉核心在理论证明,就是提出了更好的算两个分布散度,用一个分布贴近另一个的方法。

若有收获,就点个赞吧
0 人点赞
