《Unsupervised Learning of Visual Features by Contrasting Cluster Assignments》
最近在看对比学习和自监督OTZ,这篇是nips上的,大概读了一下,希望早上能把这篇大致总结写完。
作者没有用自监督常用的contrastive learning,其特点可以总结为是一种oneline cluster-based self-supervised方法。下图是SwAV和contrastive learning的一个对比框架。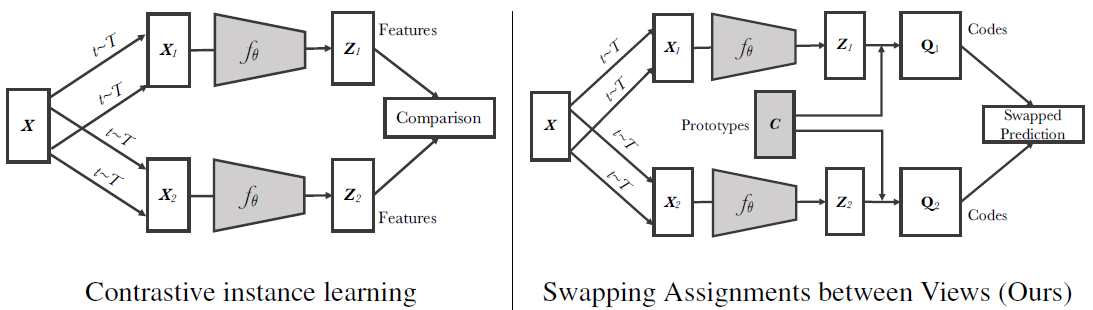
可以看到在encoder步骤之前都是一样的,先增强,再得到representation。对比学习接下来进行对比,而SwAV通过一个叫prototype的东西与z结合得到了codes。所以看这个图就很明确了,想彻底了解SwAV模型,我们要知道:
- 图中Z,C,和Q的关系,怎么求C,又怎么求Q;
- 最后那个Swapped Prediction怎么算。
我们梳理整体脉络,自上而下解决这两个问题,先看看swapped prediction步骤。要做自监督必有loss,先看看这个模型的loss function。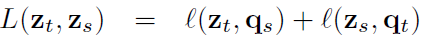
式子的意思就是正样本对的loss是特征与code(q)之间的loss,交换求之后加和。作者想让模型拥有通过z_s预测另一个q_t的能力,反之亦然。于是loss定义为交叉熵,里面是softmax。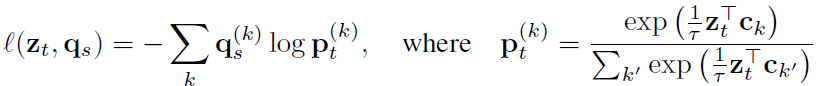
展开就是这样: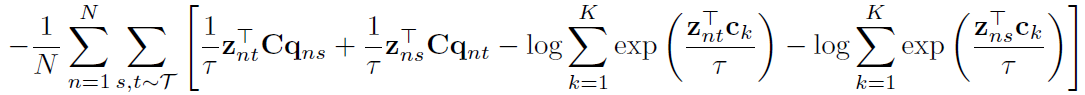
训练的时候C和θ都在被更新。
现在来看看第一个问题,也就是Q的计算,C已经知道是训练得到的了。
C也就是prototypes就是聚类。一共有K个类,作者想把B个Z归到这K个类里,优化B维向量Q,最大化Z和C的相似度。
Q的一个约束长这样,是引用别的工作的,不是很懂。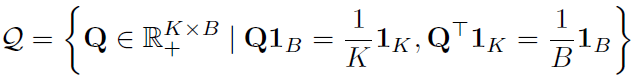
求Q的公式如下: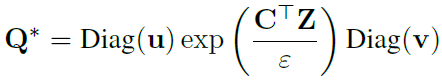
文章的另一个贡献是提出新的数据增强方法multi-crop。传统的crop越多越占内存。multi-crop的具体方法就是用两张正常分辨率的crop和V个低分辨率的crop。而loss可以写成这样: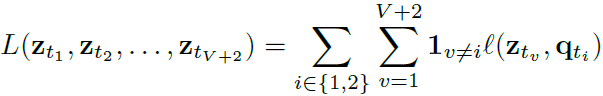
就是用低分辨率的V个和正常分辨率的一个feature预测正常的分辨率的code。
实验部分不加赘述。

若有收获,就点个赞吧
0 人点赞
