《Adversarial Graph Augmentation to Improve Graph Contrastive Learning》
链接:https://openreview.net/pdf?id=ioyq7NsR1KJ
nips 2021
模型的结构其实不难,从题目就可以看出来是对抗学习做图的对比学习的,文章难点也是强项就是理论部分,这里简要整理一下,理论证明部分如果要讲组会再说。
先看整体结构,也就是模型如何实现图的表示的对比学习的。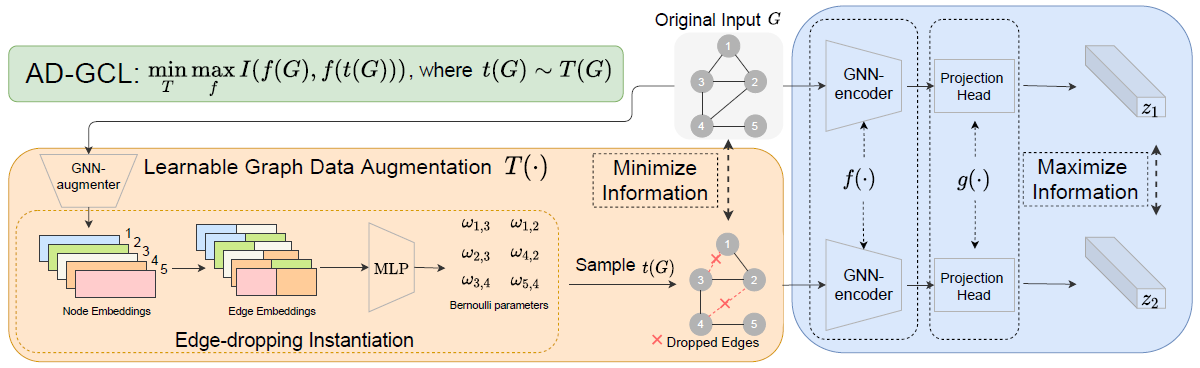
绿色框里的是目标函数,I为互信息,意为在做图的增强时对互信息进行minimize,在对比学习时对互信息进行maximize。橙色里的增强部分也很清晰,这个模型里图的增强其实去掉原图的边,就是用GNN得到节点的embedding之后,拼接作为两点之间边的embedding,再经过MLP得到一个概率,将这个概率放入伯努利分布来决定这个边是否留下,得到该图新的view。最右边就是最常规那套,一个encoder一个projection head,就做正样本的对比了。
接下来说说作者为什么要这么做。也就是增加一些实现的理论和细节部分。
首先作者注意到对比学习中一直在采用的InfoMax,也就是InfoNCE体现的思想,想要越多的互信息越好,但存在一个关键问题:会有冗余的信息被编码到representation中。因此引入一个与InfoMax对立的概念IB(information bottleneck),目标就是想要尽量小地获取信息。代入到图对比学习任务时,有: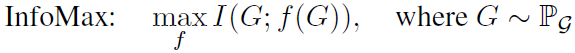
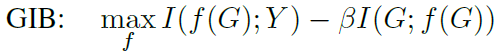
上面的InfoMax想要G的编码保留尽可能多的信息,下面的与下游任务相关联,Y代表G的标签,旨在最大化representation中保留最多的与下游任务相关的信息,剔除冗余信息。但接下来的问题就是没有标签信息怎么实现。作者给出了理论分析。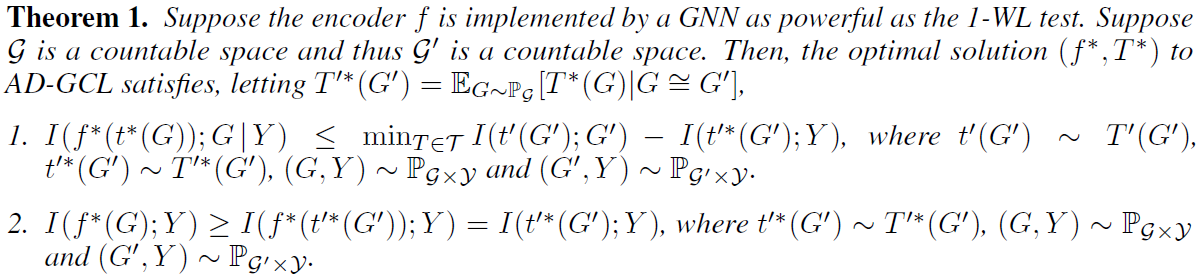
第一条保证了representation捕捉的信息是有上界的,且这个上界会剔除Y相关信息。这也是模型的目标,找出这个包含标签信息的上界,且不需要标签信息的获取。
第二条保证representation与下游任务标签之间的互信息有一个下界。进一步解释就是如果增强方式合适的话,就有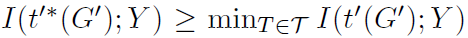 ,继而保证了
,继而保证了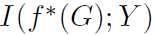 不会太小。作者也因此建议在学习\tau的时候不妨加入正则项。
不会太小。作者也因此建议在学习\tau的时候不妨加入正则项。
证明部分如果要讲组会再研究,哈哈。
理论部分之后就是模型的实例化。回到开头说的架构,首先计算去掉边的概率。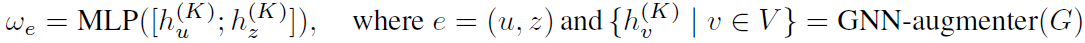
加了正则的loss: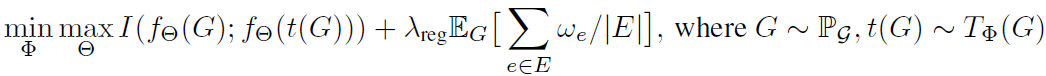
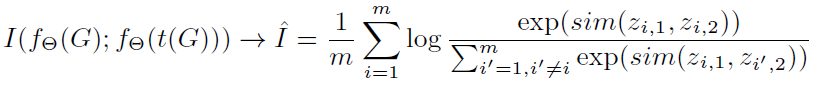
再简单了解一下实验部分。这里的AD-GCL的FIX和OPT版本是正则项的系数\lamda的值固定和有选择。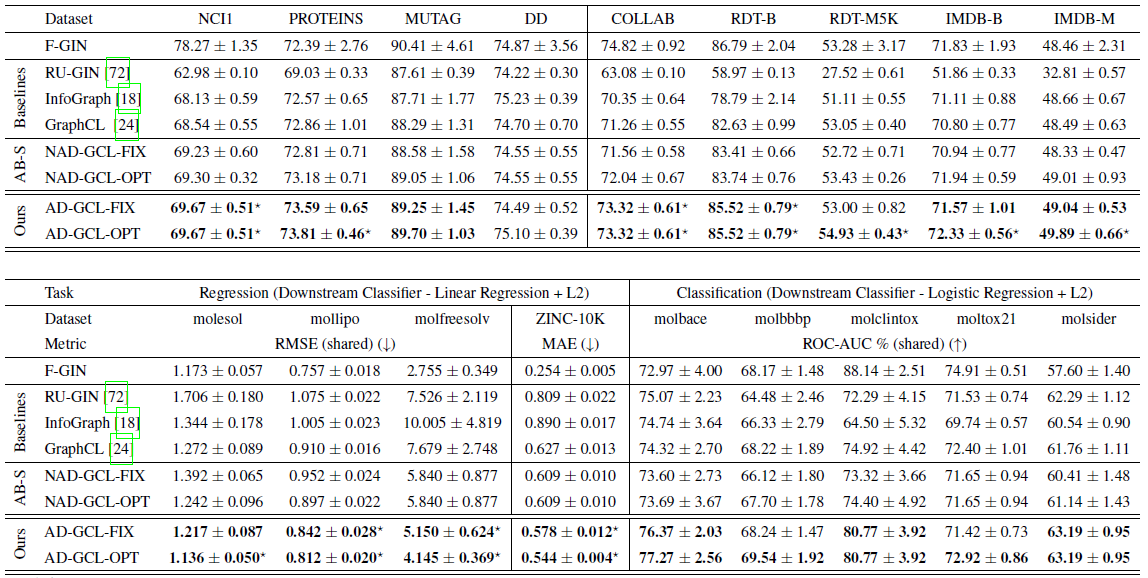
另有实验证明正则项的设置和edge drop rate有直接联系,就不多研究了。

若有收获,就点个赞吧
0 人点赞
