《DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning》
发现要审的那篇问题蛮多,紧急读了这个。简单总结一下顺便二刷,看是否会对用RL做KG reasoning有更多理解,呜呜。
用强化学习来做知识图谱推理(包括链接预测和真实预测),要明确只能通过多跳路径的学习来实现。所以跟用embedding做链接预测是很不一样的。通过多跳路径的学习要想预测A和B两个实体之间存在链接,知识图谱中一定会存在A到B的路径。这篇文章的亮点一个是首次用RL做KG推理,另一个是奖励函数的设置(同时考虑了accuracy,diversity,efficiency)。
一个比较有代表性的相关工作是PRA(Path Ranking Algorithm),PRA使用基于重启的随机游走推理机制来执行多个有界深度优先搜索过程,以找到关系路径。结合基于弹性网络的学习,PRA之后使用监督学习选择更合理的路径。然而,PRA在完全离散的空间中运行,这使得在KG中评估和比较相似的实体和关系变得困难。
接下来详细介绍一下DeepPath模型。
1. Methodology
模型的目的是找一条路径p,出发点是源实体e_s,走n步,每一步是一个关系r_i,最终走到目标e_t。
1.1 Reinforcement Learning for Relation Reasoning
RL系统由两部分组成。第一个部分是外部环境E,被建模成马尔科夫决策过程MDP,利用 是转移概率矩阵,R(s, a)是奖励函数。第二个部分是智能体agent,用策略网络
是转移概率矩阵,R(s, a)是奖励函数。第二个部分是智能体agent,用策略网络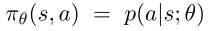 表示,将状态向量映射到随机策略。利用SGD更新\theta。下面这张图就是这个RL系统整体的介绍。接下来重点挨个解释。
表示,将状态向量映射到随机策略。利用SGD更新\theta。下面这张图就是这个RL系统整体的介绍。接下来重点挨个解释。
Actions
给出实体对(e_s, e_t)以及关系r。从源实体e_s开始,代理使用策略网络选择最有希望的关系,在每一步扩展其路径,直到到达目标实体e_t。为了保持策略网络的输出维度一致,动作空间被定义为KG中的所有关系。
States
KG中的实体和关系自然是离散的原子符号。为了捕捉这些符号的语义信息,使用基于翻译的嵌入来表示实体和关系,比如TransE。这些嵌入将所有符号映射到低维向量空间。在我们的框架中,每个状态捕获agent在KG中的位置。采取行动后,agent将从一个实体转移到另一个实体。两个实体通过agent刚刚采取的action即关系联系在一起。步骤t的状态向量为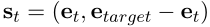 。e_t代表当前实体的embedding,e_target是目标实体的embedding。
。e_t代表当前实体的embedding,e_target是目标实体的embedding。
Rewards
有几个因素会影响agent发现的路径的质量。为了鼓励代理找到预测路径,奖励函数包括以下预测标准:
- 全局准确性:对于我们的环境设置,agent可以采取的action数量可能非常大。换句话说,不正确的顺序决策比正确的顺序决策多得多。这些错误决策序列的数量会随着路径的长度呈指数增长。鉴于这一挑战,添加到RL模型的第一个奖励函数定义如下。如果代理在一系列动作后到达目标,则给予离线正面奖励+1。

- 路径效率:对于关系推理任务,观察到短路径往往比长路径提供更可靠的推理证据。较短的关系链也可以通过限制RL与环境交互的长度来提高推理的效率。效率奖励的定义如下。p是关系序列
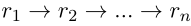 。
。
- 路径多样性:训练agent使用对于每个关系的正样本来寻找路径。这些训练样本(e_source,e_target)在向量空间中具有相似的状态表示。agent倾向于寻找语法和语义相似的路径。这些路径通常包含冗余信息,因为其中一些可能是相关的。为了鼓励agent找到不同的路径,使用当前路径和现有路径之间的余弦相似性(完全背离=-1,完全相同=1)定义了一个多样性奖励函数。其中
 表示关系链
表示关系链 的路径嵌入。
的路径嵌入。
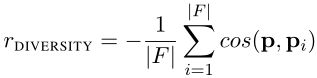
Policy Network
使用全连接神经网络来参数化策略函数π(s;θ),它将状态向量s映射为所有可能动作的概率分布。神经网络由两个hidden layer组成,每个hidden layer后面都有一个ReLU,输出之前进行softmax(可以参考上面那张图)。
1.2 Training Pipeline
对于一个典型的KG,agent经常面临成百上千个可能的action。换句话说,policy network的输出层往往维度很大。如果直接通过试错来训练RL模型,RL模型将表现出非常差的收敛特性。为了解决这个问题,作者从一个受监督的策略开始我们的培训,这个策略是由AlphaGo使用的模仿学习管道(Silver等人,2016)所启发的。在围棋游戏中,玩家在每一步都面临着近250种可能的合法走法。直接训练agent从原始动作空间中挑选动作可能是一项困难的任务。AlphaGo首先使用专家移动训练一个受监督的策略网络。而本模型的监督策略是用BFS训练的。
Supervised Policy Learning
对于每个正样本(e_source,e_target),进行双边BFS分析,以找到实体之间相同的正确路径。对于每条具有关系序列的路径p,我们使用蒙特卡罗策略梯度更新参数θ以最大化期望的累积报酬。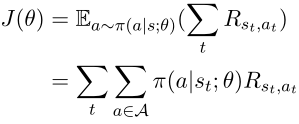
其中J(θ)是一个episode的预期总奖励。对于监督式学习,我们会对一个episode中成功的每一步给予+1的奖励。通过插入BFS发现的路径,用于更新策略网络的近似梯度如下所示,其中r_t在路径p中。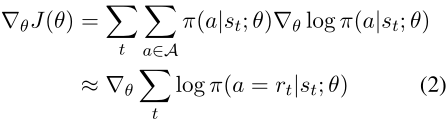
然而,普通的BFS算法是一种偏向于短路径的搜索算法。当插入这些有偏差的路径时,agent很难找到可能有用的较长路径。我们希望路径仅由定义的奖励函数控制。为了防止有偏见的搜索,我们采用了一个简单的技巧来添加一些随机机制到BFS。我们不直接搜索e_source和e_target间的路径,而是随机选择一个e_inter,然后在(e_source, e_inter)和(e_inter,e_target)之间进行两次BFS。拼接的路径用于训练agent。
Retraining with Rewards
为了找到由奖励函数控制的推理路径,使用奖励函数来重新训练受监督的策略网络。对于每个关系,一个实体对的推理被视为一个episode。代理从源节点e_source开始,根据随机策略π(a|s)选择一个关系,以扩展其推理路径,π(a|s)是所有关系的概率分布。失败的步骤将导致agent获得负面奖励。在这些失败的步骤之后,agent将保持当前的状态。由于agent遵循随机策略,不会因为重复错误的步骤而陷入困境。每个episode的长度有上限max_length。如果agent未能在最大长度步长内到达目标实体,则该episode结束。每个episode之后,策略网络使用以下梯度更新: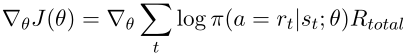
其中R_total是定义的奖励函数的线性组合。\theta是使用带有L2正则化的AdamOptimizer进行优化的。retraining的算法具体步骤如下:
1.3 Bi-directional Path-constrained Search
给定一个实体对,RL代理学习的推理路径可以作为逻辑公式来预测关系链接。使用双向搜索来验证每个公式。在典型的KG中,一个实体节点可以链接到大量具有相同关系链接的邻居。一个简单的例子是关系personality-1,它表示personality的反义词。通过这种联系,美国实体可以联系到许多邻近的实体。随着遵循推理公式,中间实体的数量可以呈指数级增长。对于这些公式,如果我们从反方向验证公式。中间节点的数量可以大大减少。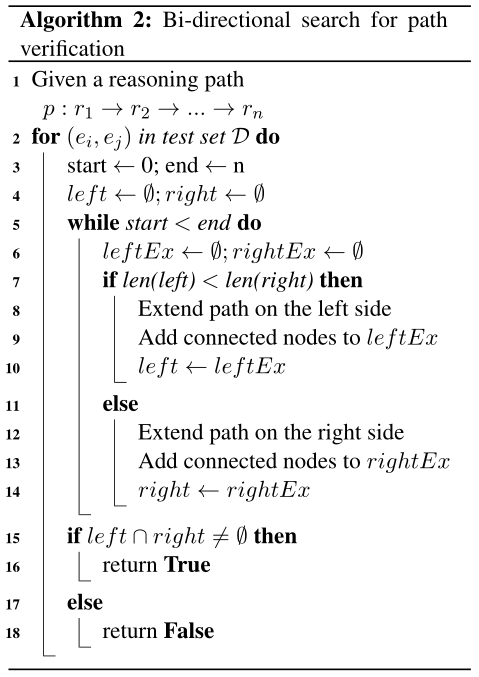
最后就是实验部分,这里就不多说了。比较好奇它的链接预测怎么排名,是根据每条路径总计的reward或许。在MINERVA里发现它是把路径输入到PRA里面进行了排序。详细来讲就是对于链接预测任务,会给一个关系一个实体作为查询,另一个实体是什么会有一个候选集,agent会得到源实体与各个候选实体之间的路径,然后给这些路径排序,从而达到给链接预测排序的效果。

若有收获,就点个赞吧
0 人点赞
