《gradients are not all you need》
跟随youtube大佬读读Google新发到arxiv上的文章,本来考虑放组会上但整体读下来感觉是个以实验为主的文章,中心思想就是gradient descent并不一定适用于chaotic system,使用需谨慎。来简要看看作者怎么说明这个东西的。
Iterated Dynamical Systems
首先简要介绍这种迭代变化的系统。s就是state,f就是神经网络或者别的东西,比如rnn。于是有下面这个式子: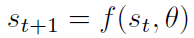
而loss就是每一步loss之和: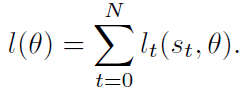
各种问题的符号对应: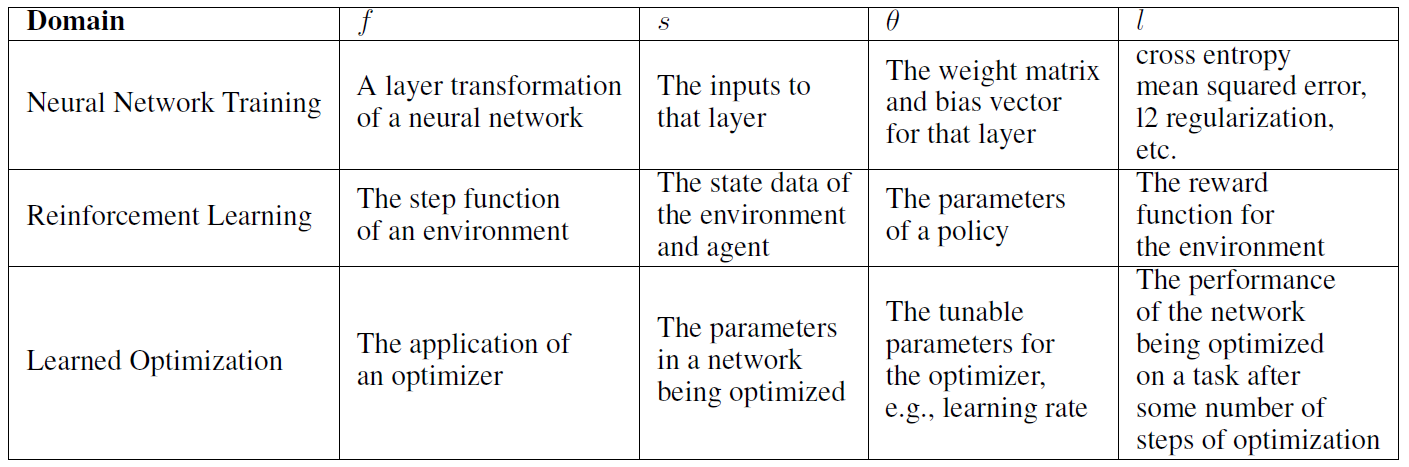
然后就是耳熟能详的梯度消失和梯度爆炸问题,就是公式里的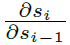 的迭代乘法导致的:
的迭代乘法导致的: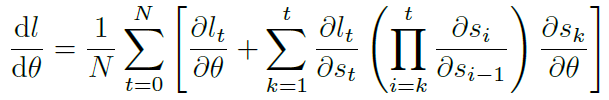
作者更关注的是gradient的方差,可以理解为稳定性。给了个图佐证: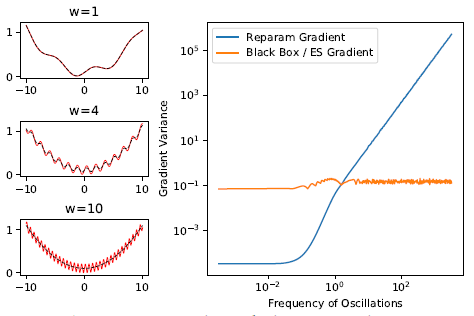
左边红线就是loss,如果用参数梯度来优化,在w极大的时候梯度会变得很不稳定,方差很大,而传统的黑盒梯度就可以一直保持平稳。
Chaotic loss across a variety of domains
下面三个例子都在说明gradient在有些领域里是不稳定的,依次就图看看。
Rigid Body Physics
感觉是一个类似强化学习的过程。这里的unroll感觉就是几个epoch之后进行一次梯度计算,而shift就是把得到的参数θ做一个多少的偏移,可以看到gradient很不稳定,尤其随着unroll length的增加。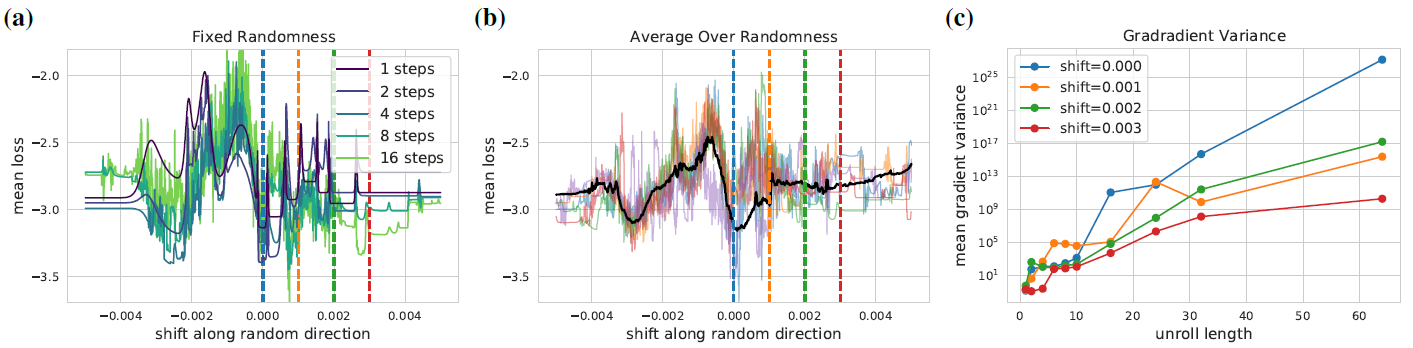
Meta-learning
元学习就是模型学外层的optimizer,学到的optimizer再自己给里面的θ调参,有套娃的感觉。可以看到loss还是在随着一点shift乱跑,很不稳定。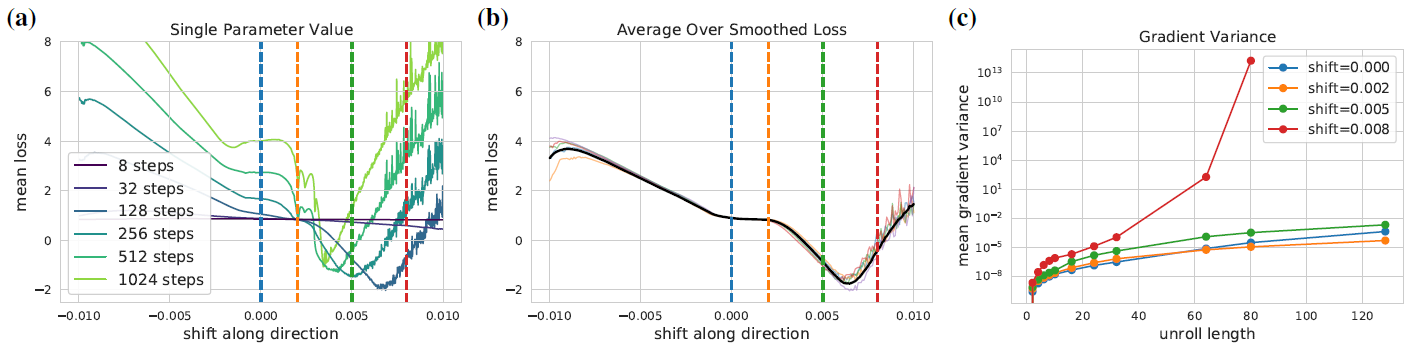
Packing Problem
利用back propagation解决的一个问题,可以看到随着step和unroll length增加也不怎么稳定。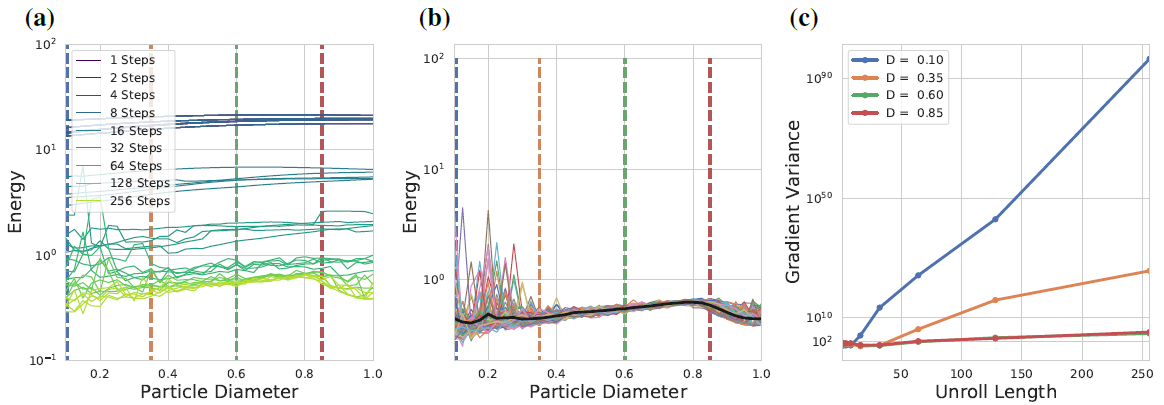
Jacobian
之前那个迭代中的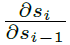 可以组合成雅克比矩阵。且该矩阵的特征值如果大于1就梯度爆炸,小于1就梯度消失,作者用图佐证了一下。蓝色点是来自不稳定系统的,可以看到特征值大于1,且出现梯度爆炸。
可以组合成雅克比矩阵。且该矩阵的特征值如果大于1就梯度爆炸,小于1就梯度消失,作者用图佐证了一下。蓝色点是来自不稳定系统的,可以看到特征值大于1,且出现梯度爆炸。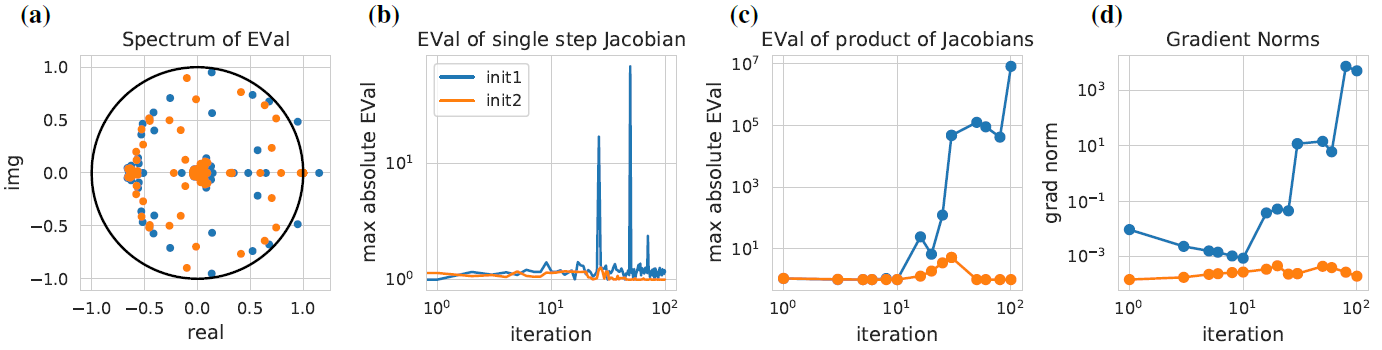
What can be done?
作者提出一些解决方案,简单说几个。
对于RNN,可以改变初始化,但是并不是长久之计。之后的LSTM和GRU改变了模型框架,从根本上解决了问题。
还有用truncated backpropagation和gradient clipping方法。
用黑盒模型算梯度也是一种方法。
总得来看就是通过实验证明别太依赖gradient,这个东西在chaotic system里会及其不稳定。

若有收获,就点个赞吧
0 人点赞
