之前组会老师说到医疗有个研究方向就是在不同的latent space做embedding,不仅仅看图的结构,可能用别的特点来进行embedding或辅助的embedding也会取得很好的效果,学姐就提到一个新的东西,叫LDA主题模型可以实现,于是找个了看起来挺靠谱的B站视频来学习一下,这篇就记录一下视频的内容,希望看完能有所收获,废话不多说gogogo。
作者说,模型的目的其实是找出一个machine,可以类比猴子随机敲键盘也能敲出莎士比亚,通过训练的machine更可以。先了解一下这个machine的内部构造: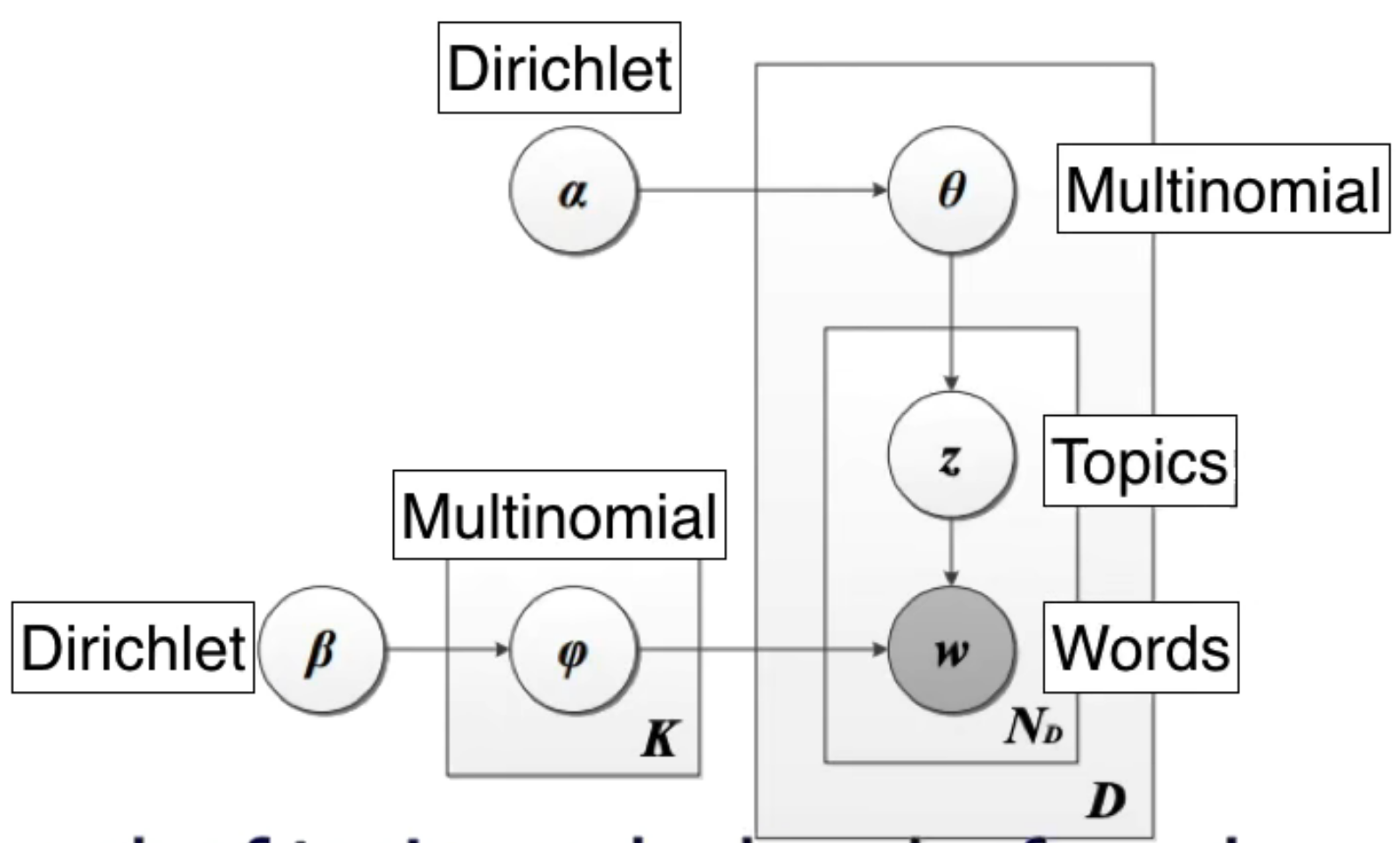
alpha和beta是dirichlet分布的参数,theta和phi是多项式分布的参数,生成topics和words,就可以得到document了。生成了document之后,看是否是我们需要的document,也就是下面这个公式的probability: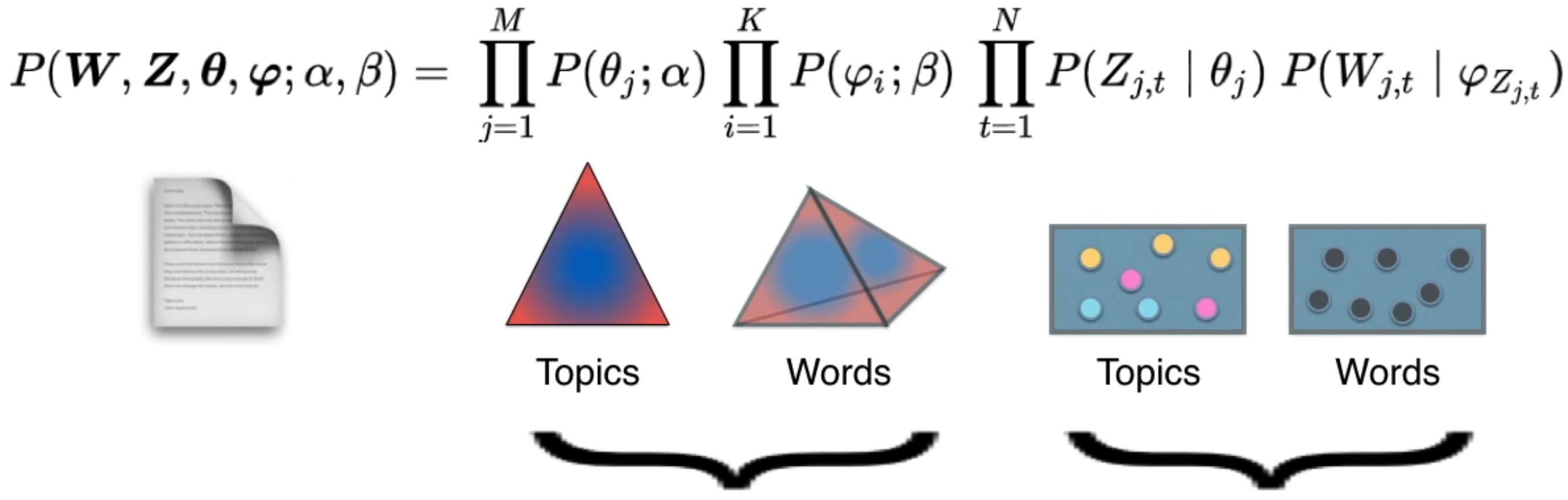
两个大括号被字幕盖住了,前一个是dirichlet分布,后一个是多项式分布。每一个factor都看作一个在空间中取点的过程。
先看看什么是dirichlet分布,作者说可以看作一个办在三角形屋子里的party,分布的变量就是参加party的客人,不同的角落放置不同的物品会让客人出现在角落和中心的概率有所变化。黄色的点是客人,颜色深浅代表概率大小,参数alpha起到的作用如下: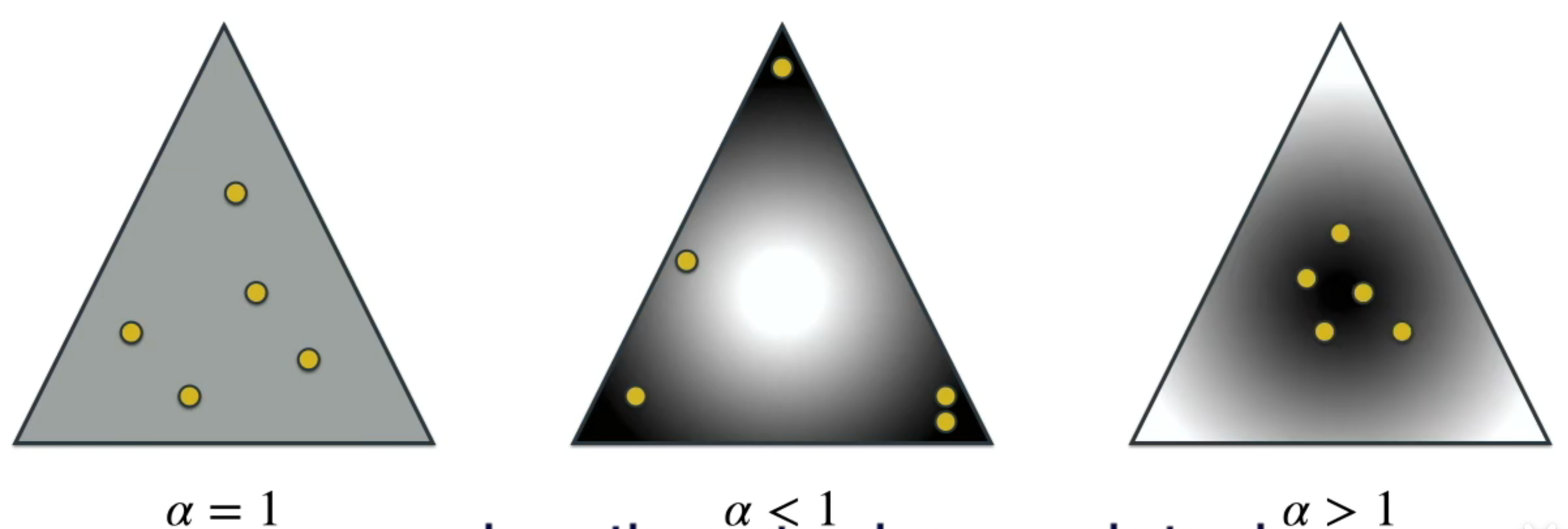
来一个更标准的多元dirichlet分布的表达: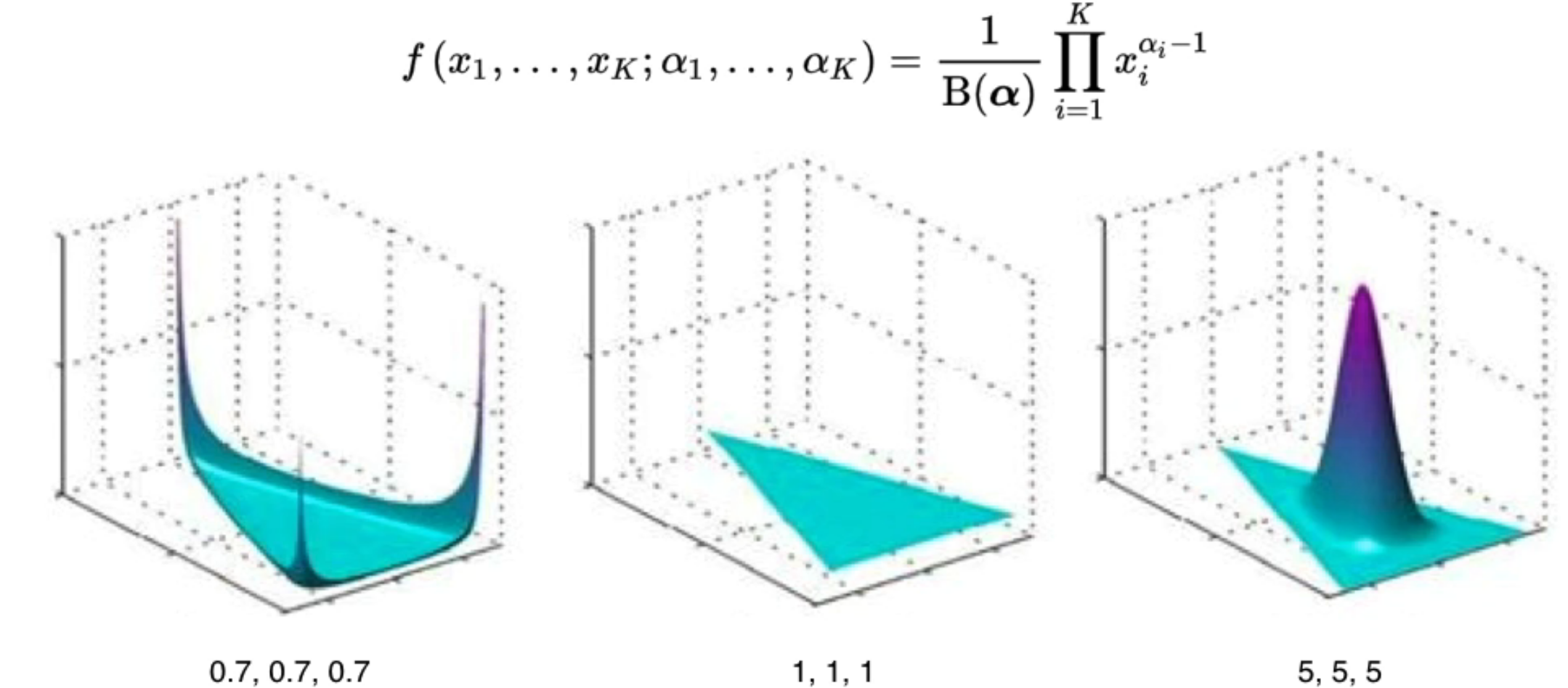
作者提出了两种dirichlet分布:
这张ppt集大成。前面个两个dirichlet分布,后面两个多项式分布,分别是words找对应topic和topic找对应words。
连乘这些factor可以输出一个document(右下角本本里的)。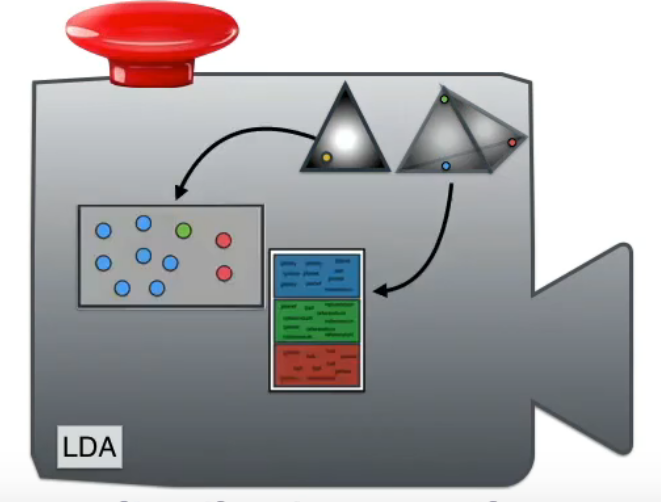
三角和四面体可以控制多项式的生成,可以看作setting,只有合适的setting才能给出靠谱的document,所以可以视为在很多台machine中选输出的document最靠谱的那台。
最后再看眼blueprint,清晰很多了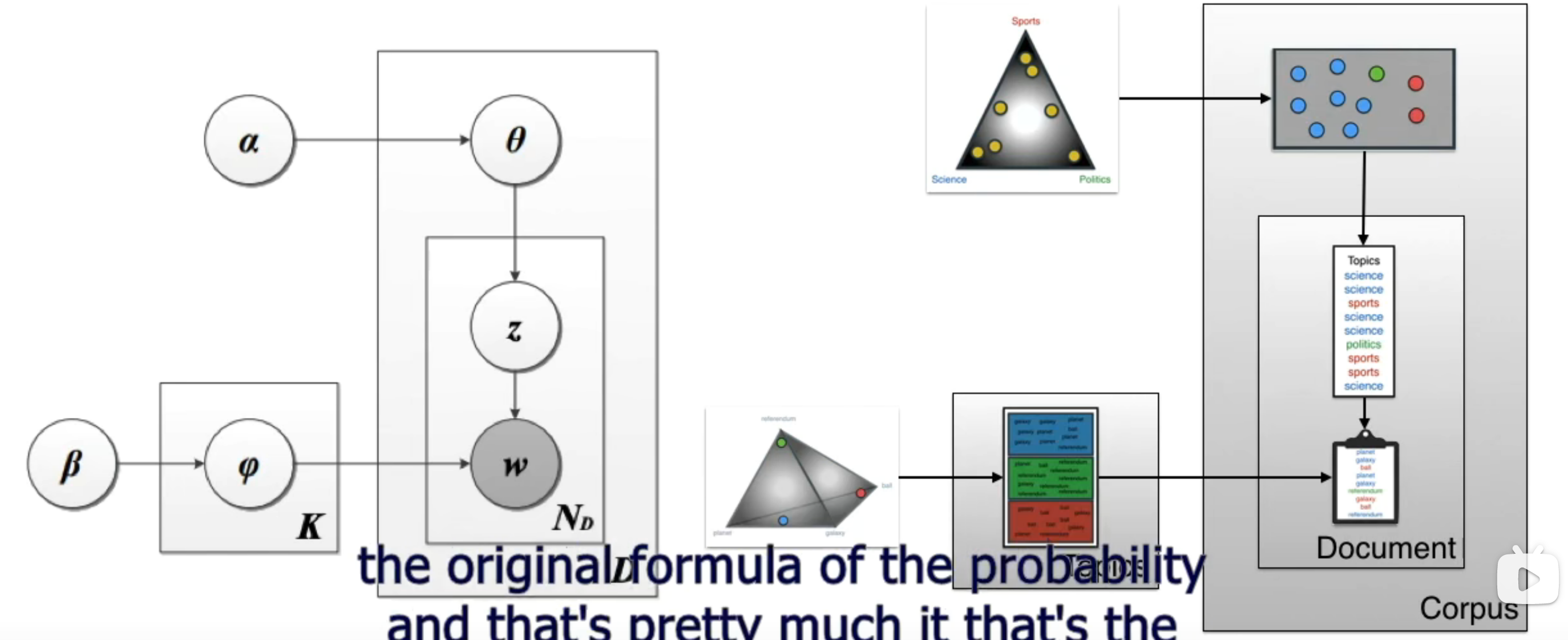
走第二节,具体到模型。首先回顾本质需求。我们有很多个documents,每个都有不同的topic,现在想机器来区分这些document的topic是什么。
具体步骤就是先给word选好topic,再根据words赋予article一个topic。、
专业知识来了!首先是进行一个gibb sampling,用来给word着色。gibbs sampling的思想很简单,就是在归类的时候给它已经倾向于归于的类别。
两节内容怎么联系起来呢,作者说讲第二节其实就是让大家知道,第一节那个公式其实只需要优化word的那一项就足够了,因为合适的word着色就可以带来合适的topic着色,over。

若有收获,就点个赞吧
0 人点赞
