了解了一遍很有名的Transformer,靠这篇博客明白了很多。
首先明确任务,Transformer的输入为序列,最初的任务就是搞句子翻译。每个encoder由两部分组成,一个是自注意力层,另一个是前馈神经网络。自注意力层在编码某个词时会考虑其他的词。看这个整体图,如果理解流程的话其实很清晰。这里的Nx就是有同样多的多个encoder和decoder的意思。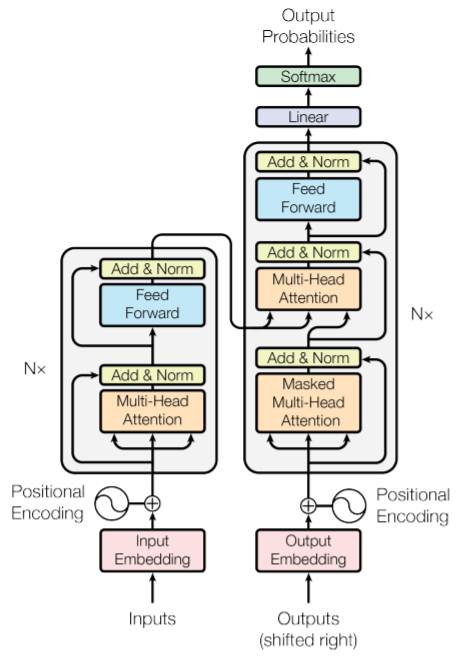
可以看到输入的句子首先会经过word embedding步骤,也就是每个词都会获得一个embedding,且有positional encoding的步骤,可以让输入的embedding携带位置信息。进入encoder后就首先进入核心部分,也就是注意力层。注意力层旨在找到句子内部词与词之间的关系。首先对每个输入的词向量产生三个向量,分别为Query,Key和Value,这些向量是词向量与可训练矩阵相乘得到的。用这三个向量进行注意力系数的计算,比如要计算第一个单词和其他单词的注意力系数,就用q_1和k_i进行点乘,除以维度的开方,最后进行softmax处理得到注意力系数。最后用value与注意力系数相乘,将每个position对于position1的value相加即为注意力层的输出z。此外,这里是多头注意力,因此会有不止一个Q,K和V向量,得到的不同的z会进行一个拼接操作。关于encoder剩下的细节可以看图,已经展现得很充分了。
接下来看decoder那边。可以注意到decoder那边也有注意力层,但这个注意力是encoder和decoder之间的。最顶层的encoder会输出Key和Query,输入到每个decoder中计算注意力,个人认为可以理解为整个句子和已翻译完成的部分之间的注意力。注意已经翻译完成的部分会成为decoder的下层输入。decoder输出一个probability,选择当前要翻译的词是vocabulary中的哪一个。
Transformer没有很难的理论部分,正如题目的attention is all u need,但是它的结构很复杂很精妙,我理解了好久才大致疏通了其中关系。看完之后有点好奇视觉领域怎么用到Transformer的,就去稍微了解了一下VIT,是把图像分成好几个patch,就像句子翻译一样可以作为序列输入了。
TransGCN 《TransGCN:Coupling Transformation Assumptions with Graph Convolutional Networks for Link Prediction》K-CAP 2019
为了审稿读到的一篇,感觉其实有点过时,就是在讲怎么把transe和rotate的两种transformation假设和gcn结合起来的,在这里还是梳理一遍。直接走模型。TransGCN的核心思想如下,意思就是用邻居和关系来对中心实体进行表示。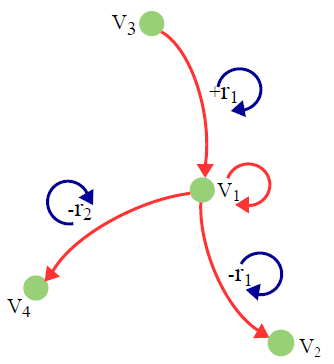
节点更新公式这个样子: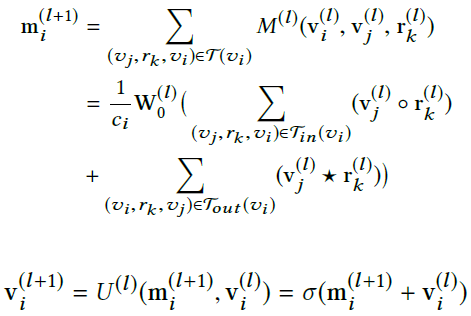
模型结构如下(其实很有vr-gcn既视感,考虑了头尾实体):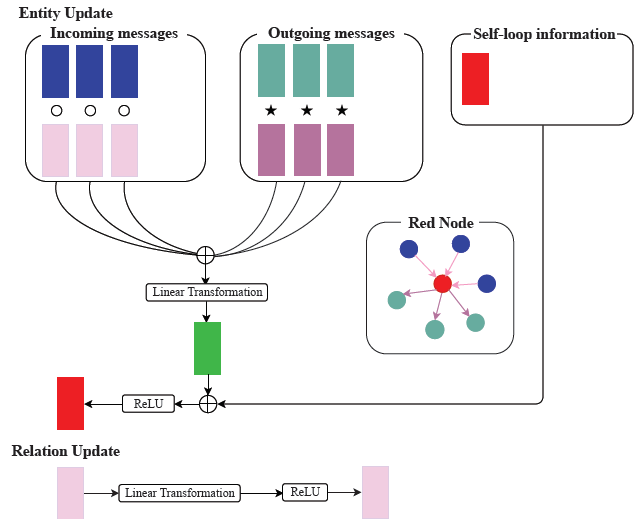
模型有个关系每一层的更新公式: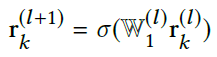 ,作者说是个软约束。接下来分别介绍TransE-GCN和RotatE-GCN,二者的区别就是上面图的○和☆的运算和损失函数。TransE的是:
,作者说是个软约束。接下来分别介绍TransE-GCN和RotatE-GCN,二者的区别就是上面图的○和☆的运算和损失函数。TransE的是: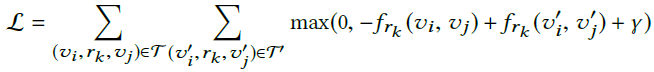
RotatE的是: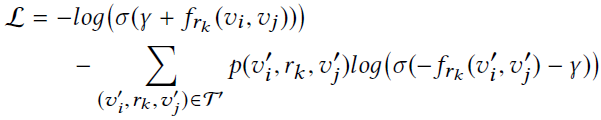

若有收获,就点个赞吧
0 人点赞
