《AutoGCL: Automated Graph Contrastive Learning via Learnable View Generators》
链接:https://arxiv.org/abs/2109.10259
AAAI 2022
是的我又看了一篇对比学习相关,讲的是对图结构通过对比学习进行一个embedding的学习,设计了一个挺别出心裁的增强方法。收获就是更深地理解了一下reparameterization trick,知道了gumbel softmax方法。直接上模型。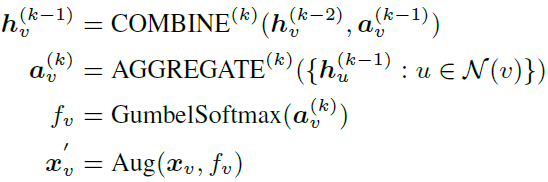
前两个式子就是用k层GIN后得到的节点v的embedding。接下来两步的目的就是选一种节点的处理方法生成新的view(keep,drop和mask),采用了gumbel softmax就是通过重参数实现端到端。f是个one-hot,选出来应该对x做什么处理,后面的Aug就是个可导操作,比如乘法。为什么这里不直接用softmax呢,因为softmax给出的结果缺少依照概率选择的这个步骤,我们只能选概率最大的那个,可以说是缺少exploration,是并不合理的,加入了gumbel softmax就可以给出更合理的分布以及选择,这个解释得很好。上面四个式子就是文章的核心view generator。这个图画得很清晰,不过这里的other node是在干什么文章没有解释,个人认为是max的概率没达到某个阈值就不做任何处理,和keep的区别就是keep会觉得这些点很重要(所以是key)。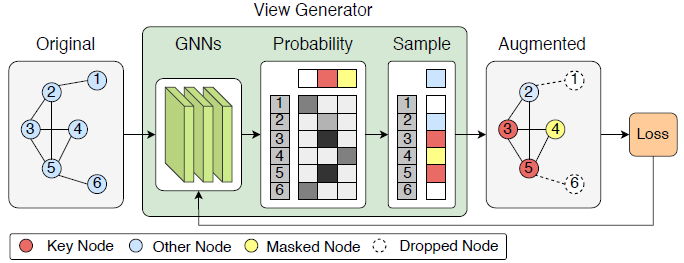
然后就是作者构造的loss,得到了整个模型: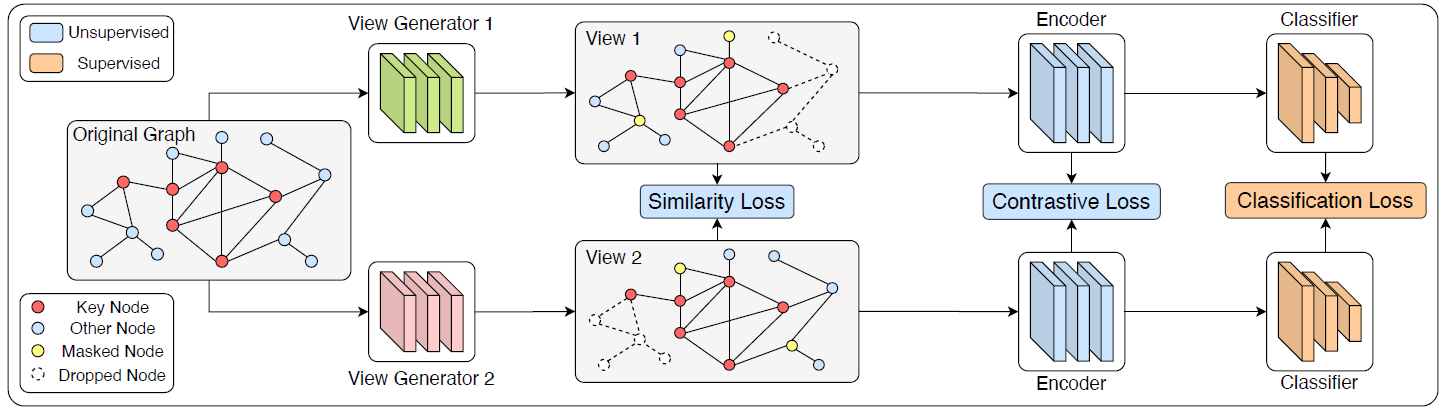
整体流程就是过两个view generator,得到两个不同的正样本,再用两个encoder(GIN)得到新view的representation,再进入分类器(SVM)得到图像的类别。这里有三种loss,一种是两种增强方式的loss,作者说这种在没标签的时候没用,因为他的增强方式是基于节点标签的;一种是对比学习的loss,就是一个正样本和另一个正样本以及其它负样本的loss,一种是分类的交叉熵loss。在分类器之前的学习有无监督和半监督两种,作者给出两种算法:
其中L就是上面提到的三种loss。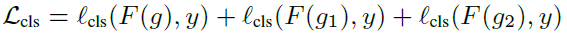
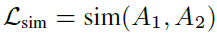
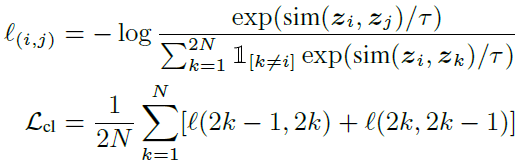
总体还是比较简单的。感觉这个模型还能给人些启发的,比如给节点赋予latent的prototype再做mask会不会实现更好的增强效果。

若有收获,就点个赞吧
0 人点赞
