《PROTOTYPICAL CONTRASTIVE LEARNING OF UNSUPERVISED REPRESENTATIONS》
文章链接:https://arxiv.org/abs/2005.04966
ICLR 2021
感觉现在一个比较火的操作就是加隐变量,尤其是prototype,搞聚类那种,这篇就挺典型的。作者在MoC哦对InfoNCE的基础上提出了加入聚类的ProtoNCE,长这样: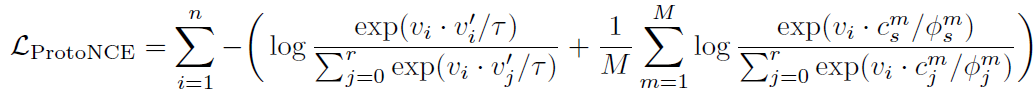
其实就是在InfoNCE的基础上加上了后面一项引入c和φ的,看起来很简单,推理过程想法也不难,就是EM。
要确定模型的参数就是求极大似然: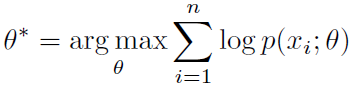
加入聚类参数: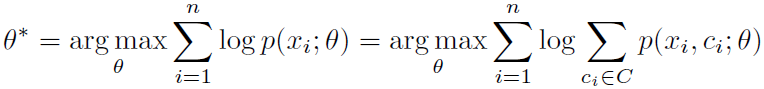
再处理一下,用到了Jensen不等式: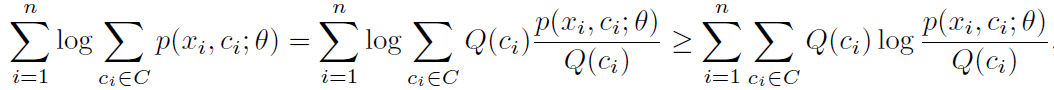
最大化这个下界就可以得到解。Q(c_i)的最优解可以用拉普拉斯算子证明,这里不赘述了:
代入之后最终最大化的目标变成,本来log里的除号变减号,作为常数项被忽略: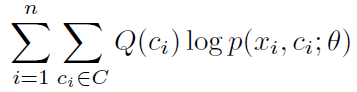
现在回忆一下EM算法。E步就是在根据当前情况划分类别,把最像属于c的点放进属于该类的类;M步就根据之前划分的情况重新计算这个类别的参数。M步如下,这里的指示函数代表x是否属于c类: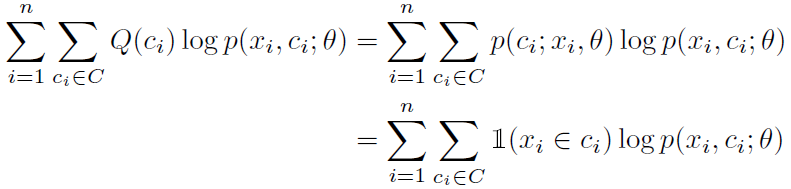
作者假设类别分布式均匀分布,于是有: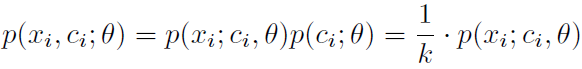
代入各向同性的高斯分布(这里不懂为什么高斯分布有两项但前一项不要了):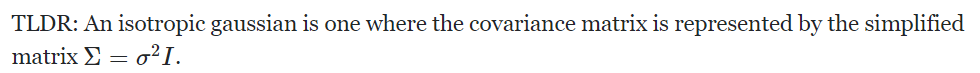
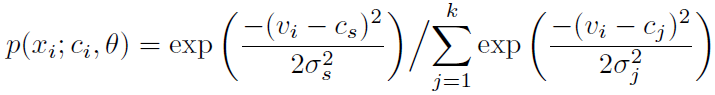
对v和c归一化有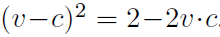 ,结合前面的式子最终得到。这里的φ与标准差的平方成正比。
,结合前面的式子最终得到。这里的φ与标准差的平方成正比。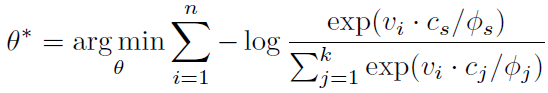
c就是中心,v的平均。φ代表集中程度,可以这么算(Z是一个类中个体的数量):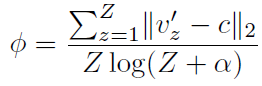
作者还分析模型的好处就是增加了个体与类别之间的互信息。
实验重点参数设置: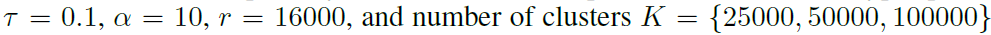
结果虽然打不过有些模型,但用的epoch很少,而且因为在MoCo的基础上,用队列维持dictionary占内存很少,也没有用那些crop之类的augmentation。很是很不错的。放其中一个结果在这里: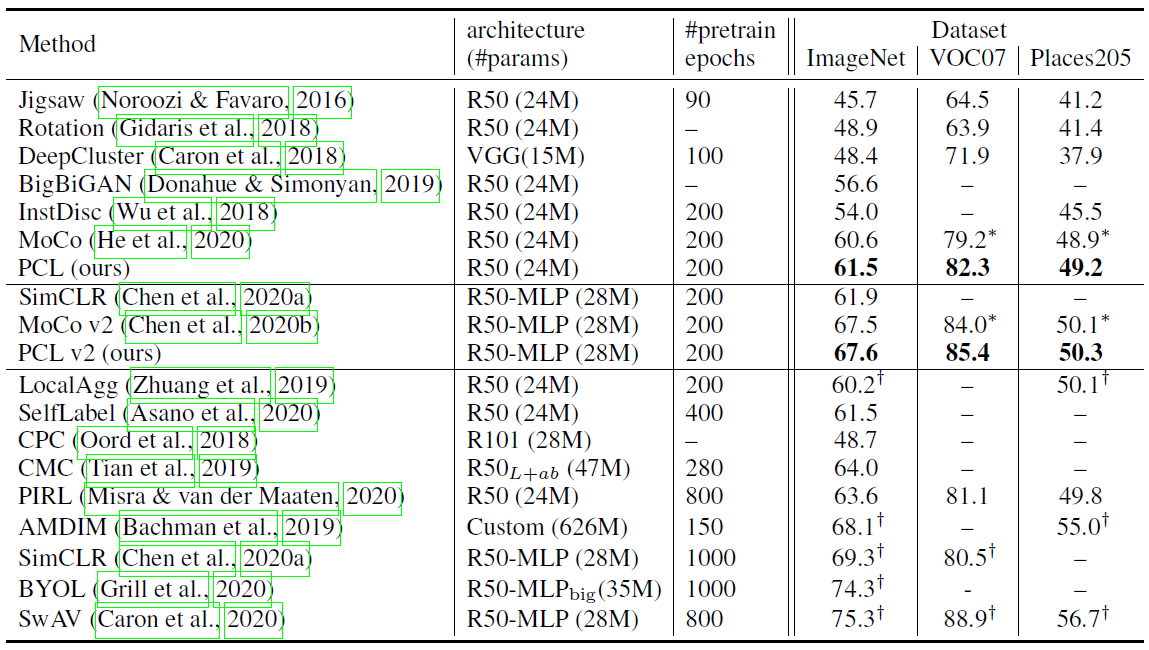
over。

若有收获,就点个赞吧
0 人点赞
