1. HTTPS客户端和服务端如何沟通(SSL双向认证握手)
通信流程
加密方式:包含非对称加密和对称加密 相关技术: 公钥,私钥,数字证书 服务器的公钥私钥,用来进行非对称加密, 客户端的随机密钥,用来进行对称加密
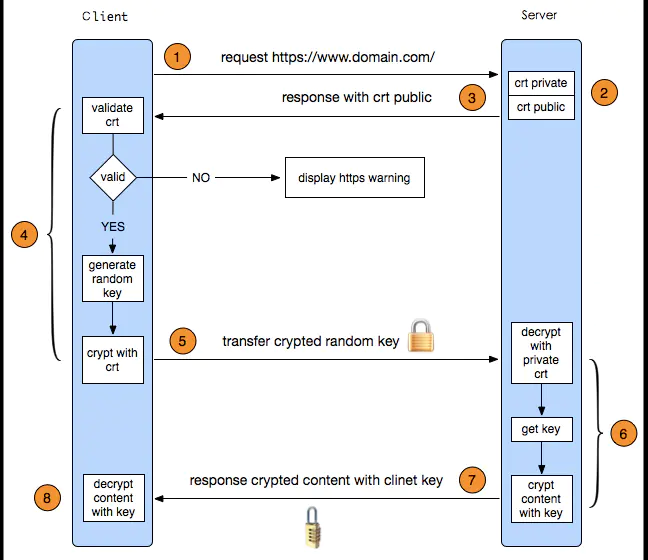
- 客户端发起HTTPS请求到服务器443端口
- 服务器收到客户端的请求,将公钥发送给客户端
- 客户端收到服务端的证书后,验证其合法性,若无效,则HTTPS链接会失效,否则转4
- 验证证书合法,客户端生成一个随机密钥,即客户端密钥。
- 用公钥将随机密钥加密,发起HTTPS请求,将加密的客户端密钥发送给服务端
- 服务端通过私钥解密加密的客户端密钥,获得对称密钥
- 服务端使用对称私钥对数据进行加密后,发送HTTPS相应报文到客户端
- 客户端通过对称私钥对传输来的密文解密,获得数据明文
如何验证证书的有效性
证书:用来验证公钥持有者身份的电子文档,防止第三方进行冒充。 一个证书中主要包含:
- 公钥
- 持有者信息
- 证明证书内容有效的签名(由CA(证书中心Certificate authority)提供)
- 证书有效期
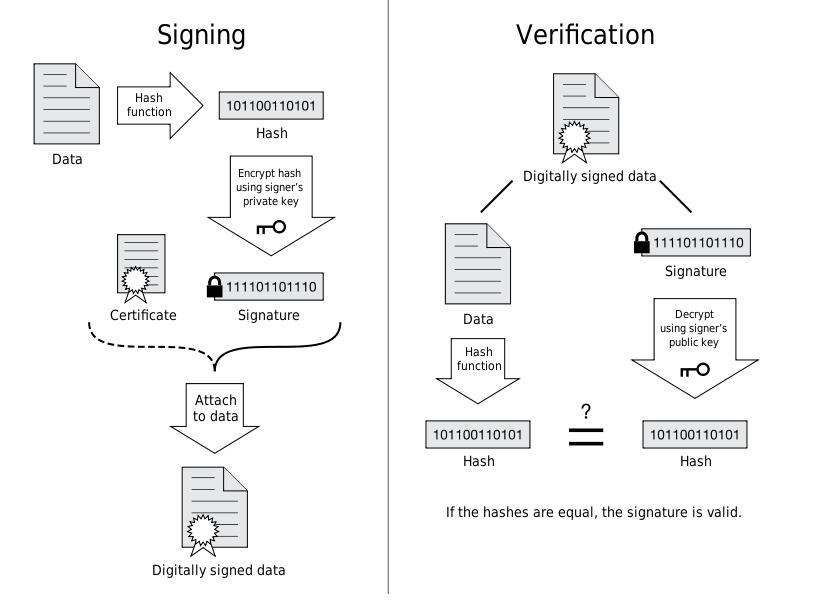
证书签发过程(由CA的私钥参与非对称加密)
“元信息”+“签名密文” -> 数字证书
- 撰写证书的元信息:签发人,地址,签发时间,失效时间,持有者信息等等
- CA通过指定的hash算法将摘要提取出来
- Hash摘要通过CA私钥进行非对称加密,生成签名密文
-
证书验证过程(由CA公钥参与非对称解密)
“签名密文”+”CA公钥”+解密算法 -> 摘要B
“元信息” + “CA指定hash算法” -> 摘要A 当A=B时,数字证书验证合法。 浏览器获得服务端发来的证书,包括“元信息”和“签名密文”
- “元信息”通过CA证书指定的Hash算法获得摘要A;
- “签名密文”通过CA公钥获取摘要B;
- 比较摘要A 、B是否匹配,若匹配,则说明证书合法
HTTPS有什么加密方式
算法选择:
- 对称加密 AES 128位
- 非对称加密: EEC 160位 或 RSA 1024
- 消息摘要(HASH算法): MD5
- 数字签名(由CA通过私钥加密摘要获得): DSA(速度慢,但安全性高,只适用于数字签名加解密)
非对称加密算法安全性高,但速度慢,适合小数据量的加解密。
MD5
- 一段信息对应一个hash值,且不能通过hash值逆推回原信息。
- 保证两段不同的信息不会生成同一个hash值。
2. linux系统中find和grep的区别
find根据文件的属性进行查找,包括文件名,文件大小,所属者,是否为空,访问时间等等,也可混合查找 grep根据文件的内容进行查找,会对文件的每一行按照给定的pattern进行匹配
命令使用上的区别:
find path expression#例子find / -name http.conf #在根目录下寻找文件http.conffind . -name 'srm*' #当前目录下寻找文件名前缀为srm的文件find / -amin -10 #查找系统最后10分钟访问的文件find / -group root #查找属于group为root的文件#混合查找find /tmp -size +10000c -and -mtime +2 #在/tmp目录下查找大于10000字节并在最后2分钟内修改的文件grep expression filename#例子grep 'test' d* #显示所有以d开头的文件中包含 test的行grep ‘test’ aa bb cc #显示在aa,bb,cc文件中包含test的行grep ‘[a-z]\{5\}’ aa #显示所有包含每行字符串至少有5个连续小写字符的字符串的行grep magic /usr/src #显示/usr/src目录下的文件(不含子目录)包含magic的行grep -r magic /usr/src #显示/usr/src目录下的文件(包含子目录)包含magic的行grep -w pattern files :只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’),
3. rebase和merge的区别
- 在分支commit节点表现的区别:
merge的主分支不会保留**merge**分支的commit!而rebase会保留分支的commit
- 在操作方面:
- merge:一股脑的合并所有分支上的commit,解决完冲突执行
git add . ; git commit -m 'fix conflict',这时候产生一个commit;- rebase: 交互式合并分支上的commit,解决完冲突后提交,不会产生多余的commit;
举例
初始状态
包含两个分支:master和dev
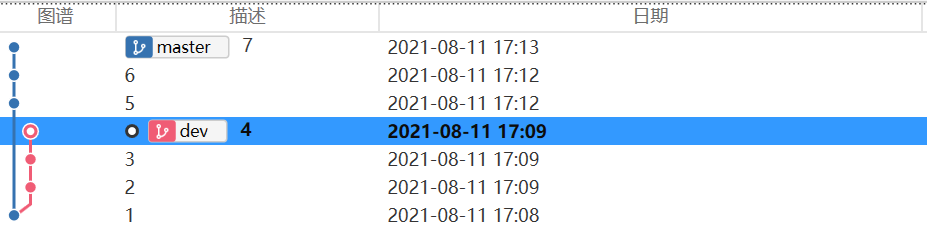
merge后节点状态
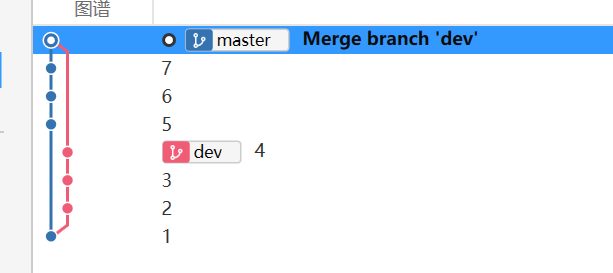
rebase后节点状态
- 第一二次rebase后的状态
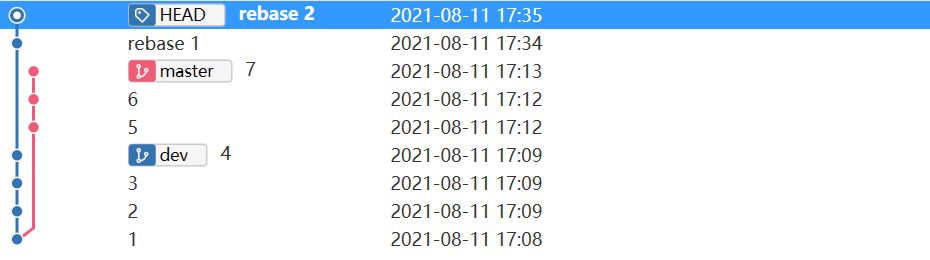
- 最终rebase后的状态


4. TDD开发的思想,如何确定测试数据
主要流程:
test failed->test passed->refactoring
- 核心是写出满足当前测试的代码,不做过多的设计(往往多余的设计可能后续用不到,对阅读代码也会造成困惑)!尽快通过所写的测试
- 之后不断循环上述步骤!
一份代码主要有两种品质
- 外部品质:保证程序按需求执行,不出错
- 内部品质:可维护性,稳定性,可扩展性等等。
TDD主要保证的是外部品质的存在,在TDD开发的过程中来不断完善产品的内部品质。
依照TDD的开发思路进行开发,不仅可以保证重构后的代码适应原有的测试,也可以让其适应新加入的测试。
TDD的编码方式
先分解任务,分离关注点
编写程序时。关注点主要包含:需求,设计和实现。TDD通过三步,每个步骤只关注一个方面:
- 写一个失败的测试,其为一个对小需求的描述,只需要关心输入输出!
- 专注用最快的方式实现当前这个小需求,不关心其他需求,也不关心代码的品质
- 重构:专注于移除代码中的坏味道!【不用考虑需求和实现】
列Example,实例化需求,澄清需求细节
- 写测试,不考虑中间过程,只考虑输入输出!
- 写实现,不考虑别的需求,用最简单的方式通过所有测试
- 重构,消除代码中的坏味道
- 写完,手动测试一下,有问题补充用例,重复上述步骤
- 转测试,有问题就继续修复
注意点
关于到底先设计还是先测试,正确点应该是先分离需求,将大需求分离成小需求,比如说JSON解析库解析字符串,是个大需求,将其分离成一个个小需求,如解析数字,解析字符,解析数组,解析对象啊,然后对每个需求再进一步划分成更小的需求。
比如说数字啊,包含解析浮点数,正负数等等。
需求分离完后,根据当前的需求写测试代码,测试代码要尽量简洁明了【必须包含断言!可迅速定位出错位置】,当出错时,就能大概率认为是产品代码出错,排除测试代码出错的可能。!
也不用每个需求,或每段代码都要写测试,对于信心不足的需求,最好写测试
测试数据如何确定
根据需求来确定不同的测试数据,测试的通过和不通过两种结果都需要考虑。在明知失败的情况下去测试,要的是看失败的原因是否符合预期。
5. 文本生成可执行文件的步骤以及内容
预处理(*.i):完全对源程序的替换,生成一个没有宏定义,头文件包含指令,注释,以及特殊符号的文件
- 宏替换,头文件展开,取消注释,特殊符号的处理
特殊符号:__LINE__,__FILE___,预处理时将对这些值进行替换- 编译(*.s):词法分析和语法分析,在所有指令都符合语法规则后,将文件编译成汇编代码
- 优化:主要有两种优化
- 对中间代码的优化:删除公共表达式,循环优化,删除无用赋值等等;
- 针对目标代码生成的优化:如何充分利用寄存器来存储变量的值,减少内存访问次数,或根据指令的特点进行修改,比如说流水线啊,提高代码执行效率
- 汇编(*.o):将汇编代码翻译成目标机器指令的过程,从而得到目标文件。
- 目标文件由段组成,通常包含两个段:
- 代码段:主要是程序的指令。该段一般可读,可执行,不可写;
- 数据段:主要存放各种全局变量和静态变量,可读可写可执行;
UNIX环境下,由三种类型目标文件
- 可重定位文件:包含由适合于其他目标文件链接来创建一个可执行文件或共享的目标文件代码和数据
- 共享的目标文件:存放了适合在两种上下文链接的代码和数据;可与其他可重定位文件或共享的目标文件链接创建另一个目标文件;或动态链接到可执行文件及其他共享目标文件,创建一个进程映像;
- 可执行文件:可被OS创建一个进程来执行的文件
链接(可执行文件):将有关的目标文件彼此链接,即将在一个文件中引用的符号同其在另一个文件中的定义链接起来。使该目标文件成为一个可被OS创建一个进程来执行的文件。
主要包括两种映射:
- 文件映射:【通过文件描述符标识】,磁盘文件映射到虚拟空间,使文件内容初始化;
- 匿名映射:初始化全为0的空间
注意:mmap首次使用只是在虚拟地址分配了空间,只有在第一次访问时,才会在物理内存中分配空间,将磁盘的内容拷贝到内存中
ftok:创建唯一IPC资源标识符来让不同进程实现通信
需要通过ftok生成key标识,标识系统的唯一IPC资源 ftok:函数ftok把一个已存在的路径名和一个整数标识符转换成一个key_t值
int shmget(key_t key, size_t size, int shmflg);:创建共享内存shmflg:IPC_CREAT,IPC_EXCL等- 成功时返回一个新建或已经存在的的共享内存标识符
void *shmat(int shmid, const void *shmaddr, int shmflg);: 挂载共享内存- 此处返回内存地址
int shmdt(const void *shmaddr);卸载共享内存7. MMU(memory management unit)的作用
作用:
- 访问控制权限
- 将虚拟地址翻译成物理地址,然后访问实际的物理地址
MMU将虚拟地址分为两个部分
- 页号索引
- 页首地址偏移量
一般来说MMU是通过分页机制来实现虚拟地址到物理地址的转换。虚拟地址空间以页划分,物理地址空间也以页来划分,即页帧。页和页帧大小相同,因为内存与外部存储器之间的传输单元为一页。
页表记录了VA到PA之间的转换信息,MMU通过遍历页表来实现VA到PA之间的转换。
另外,页表中可设置每个页的访问权限(包括特权模式或用户模式,读或写等权限),当CPU要访问一个VA时,MMU会检查当前CPU处于何种权限状态,而决定返回PA或返回异常
设计模式相关工厂模式
状态模式
代理模式

若有收获,就点个赞吧
0 人点赞
