new和malloc有什么区别
- 属性
new为C++关键字,需要编译器支持,malloc为C/C++关键字,可支持C代码
- 参数
当使用new operator时,不需要传size参数,编译器会根据参数类型自动计算size的大小并传入operator new。
使用malloc必须手动传入size参数
- 返回值
new可直接返回对应参数类型的指针。
malloc返回的是void* 指针
- 功能差别
new不仅仅分配内存空间,针对自定义类型,还会构造对象。
malloc仅仅分配内存空间。
- 内存分配位置
new分配的内存空间位于自由存储区 。使用new分配的区域均为自由存储区,是C++上基于new的一个抽象概念。malloc分配的空间则位于堆,是操作系统的概念。
一般情况下,自由存储区均通过堆实现。但若是重载了operator new,则该区域可能为混合内存区
- 重载
可通过重载operator new来实现定制化的内存分配工作;
- placement new
可通过placement new来实现堆已有空闲区块的使用。
//new 底层实现1. void *memory=::operator new(sizeof(T));2. 在memory上调用T();3. T *ptr=static_cast<T*>(memory);
vector内存管理
由两级配置器完成vector的内存分配 对于已分配大内存的vector,仅可使用swap对其进行内存释放 vector
.swap(old_vector); //临时对象在该行后析构
- 第一级配置器__malloc_alloc_template
对malloc,realloc,free等操作的封装
- 第二级配置器__default_alloc_template
由16个自由链表头地址组成的数组组成,该链表所代表的空闲区块大小分别为
8,16,24,….,128.为小内存需求服务
内存分配方法:
1. 申请内存大于128b,调用第一级配置器;否则转2
- 对所申请内存对齐至8*n的大小,并以索引n来寻找合适区块
- 若成功找到一个空闲区块,则返回;否则转4
- 尝试调用_s_chunk_alloc()分配20*n的内存,若申请成功转6,否则转5
- 若仅申请到8*n的空间,返回给用户
- 将申请到的的空间取出一块返回给用户,其余内存块链到自由链表中
内存释放过程:
函数接收两个参数,大小和位置
- 若size>128b,则交由第一级配置器处理。
- 否则,将该内存块加入对应的自由链表中
Windows pagefile.sys (linux swap)
pagefile.sys
虚拟内存,属于系统文件,受保护的系统文件
作用:
内存不足时把系统需要的预读文件的数据先放到硬盘上保存,
swap文件
类似windows下的虚拟内存,当物理内存不足 时,拿出部分硬盘空间当swap分区(虚拟成内存)使用,从而解决内存容量不足的问题 主要目的:缓解物理内存用尽而选择直接粗暴OOM-killer(out of memory,内存溢出)进程的尴尬
- 当进程向OS请求内存发现不足时,OS将内存中暂时不用的数据交换出去,SWAP OUT
- 当某进程又需要这些数据且OS发现还有空闲物理内存时,把SWAP分区中的数据交换到物理内存中,SWAP IN
当然,swap大小是有上限的,一旦swap用完,OS会触发OOM-Killer机制,把消耗内存最多的进程kill掉以释放内存。
OOM-Killer: 当内存不足时,选择一个占用内存较大的进程并kill掉这个进程,以满足内存申请的需求。
Linux内存回收
回收原因:
- 内核需要为任何时刻突发而来的内存申请提供足够的内存,以不至于让系统的剩余内存长期处于很少的状态
- 当内存申请大于空闲内存时,会触发强制回收
两个场景触发:
- 内存分配时发现没有足够空闲内存时会立刻触发内存回收
- 开启了一个守护进程(swapd进程)周期性的对系统内存进行检查,在可用内存降低到特定阈值之后主动触发内存回收。
虚拟内存(间接操作内存或硬盘)
不让用户直接操作内存,而是让用户把内存想象为一个非常大的字节数组,即为虚拟内存,操作系统负责虚拟地址与**真实内存或磁盘**地址之间的映射工作
虚拟内存结构
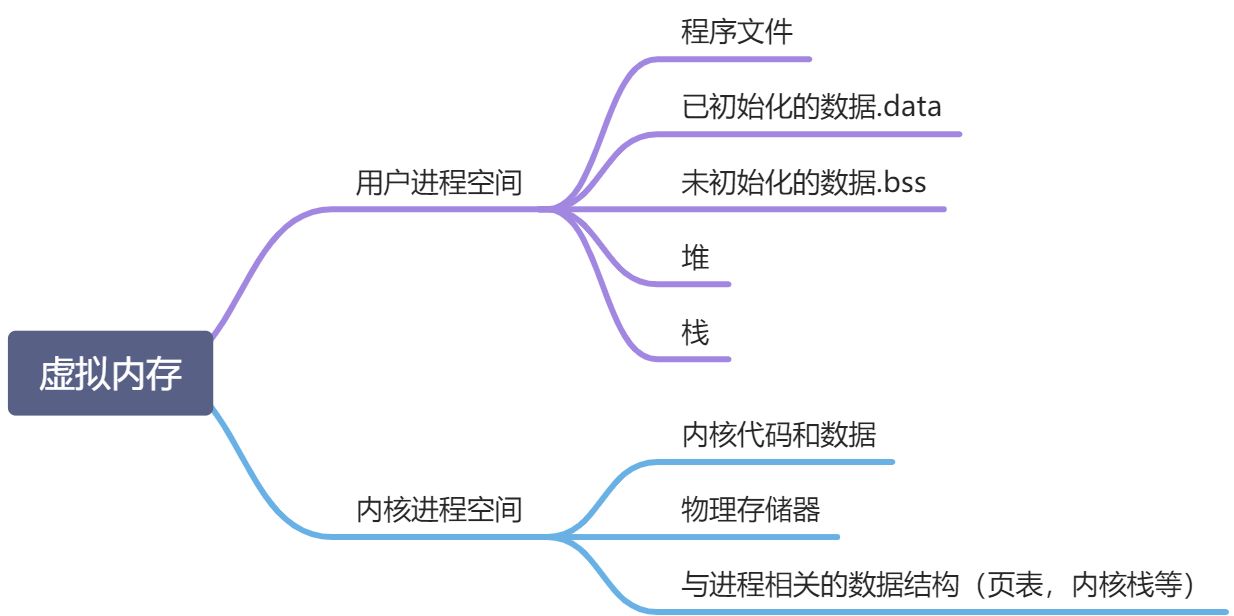
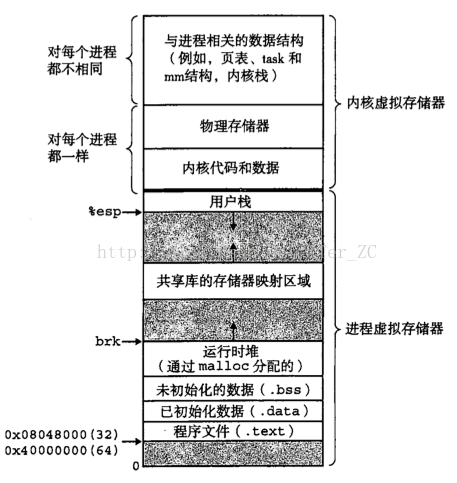
在缓存原理中,换入/换出的数据以块为最小单位;在内存管理时,页是地址空间的最小单位
虚拟地址空间划分多个固定大小的虚拟页VP,物理空间地址则划分为多个固定大小的物理页PP,和VP大小相同,一般为4kb
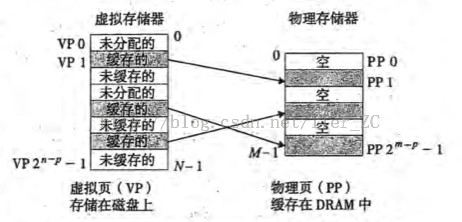
虚拟页和物理页的关系
虚拟页和磁盘文件映射,然后缓存到物理页。 根据是否映射,是否缓存,有如下三种状态:
- 未映射
- 未缓存
虚拟页映射了磁盘文件,但未缓存到内存上
- 已缓存
虚拟地址工作原理
进程使用的均为虚拟地址。每个进程维护一个单独的页表;
- 页表为一种数据结构,存储虚拟页的状态
- 数组的索引号:虚拟页号
- 数组的值:
- null——未映射
- 非null——第一位表示有效位,为1,缓存;为0,未缓存;其余位表示物理页号
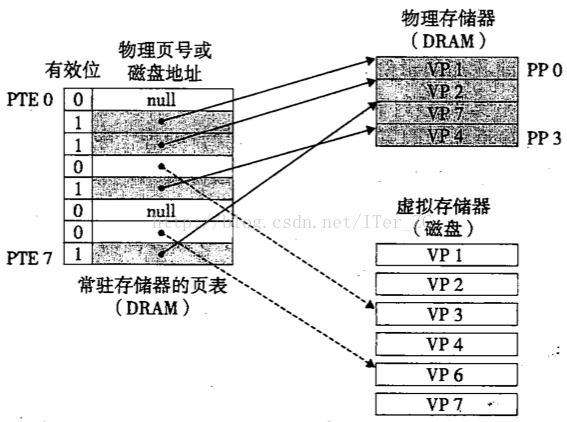
进程访问虚拟地址步骤:
- CPU根据虚拟地址找到虚拟页,并查找虚拟页上对应条目的信息,有效位1转2,否则转3
- DRAM命中,根据物理页号,找到物理页中的内容,返回
- 未命中,产生缺页异常,调用内核缺页异常处理程序
- 判断是否存在空闲的物理页,若有,则将磁盘中的映射文件缓存到该物理页,否则选取一牺牲页(根据页置换算法),将该页内容映射至磁盘
- 修改虚拟页表中的表项
- 缺页异常处理完毕,中断返回,重新执行,此时缓存命中,执行1
- 将找到的内容映射到告诉缓存,CPU从高速缓存中取出该值
虚拟内存使用问题
- 磁盘和主存传送页的活动为页面调度。若程序局部性不好,会频繁进行页面调度,造成”缓存颠簸“;
- 一般采用多级页表,即一级页表指向二级页表,来压缩页表的大小
地址翻译
DRAM缓存命中后,由虚拟地址找到物理地址的过程
- 将逻辑内存和物理内存分离
- 虚拟内存允许文件和内存通过共享页被多个进程共享
通过将共享对象映射到虚拟地址空间,系统库可为多个进程所共享。 虽然每个进程都认为共享库为其虚拟空间的一部分,而共享库所使用的物理页是所有进程共享的
- 类似的,虚拟内存允许进程通过共享内存来通信

按需调页
并非将整个程序直接加载入内存,二十将进程驻留在次级存储器上,当需要执行进程时,将其换入内存【懒惰交换:仅在需要页时,才将其调入内存】
- 页表
-
页面置换算法
FIFO(先进先出)
- 最优页置换opt:置换最长时间不会使用的页(预知)
- LRU(Least Recently used)
系统颠簸:频繁的页调度操作
当程序的局部性不好时,可能会发生系统颠簸
进程间通信的方式
管道
- 半双工,数据单向流动
- 仅能有血缘关系的进程间通信
- 管道对于两端通信的进程而言,只是一种文件,不属于文件系统仅存于内存中的”伪文件“
- 没有名称
- 管道缓冲区大小有限
- 先入先出
实质: 利用环形队列的数据结构在内核缓冲区中的一个实现,故一个数据仅能被读取一次
- 读管道
- 管道中有数据,read返回实际字节数
- 管道中无数据:
- 管道写端被全部关闭,管道中数据读完后,read返回0(好像读到文件结尾)
- 写端没有全部关闭,read阻塞等待
- 写管道
信号
- Linux系统中进程间相互通信或操作的一种机制,信号可在任何时候发给某一进程,而无需知道该进程状态
- 若该进程处于未执行状态,则该信号由内核保存,直到该进程恢复执行
- 若该进程将该信号设置为阻塞,则该信号的传递被延迟直到该进程取消阻塞
- 如果一个信号被进程设置为阻塞,则该信号的传递被延迟,直到其阻塞被取消是才被传递给进程。
Linux系统中常用信号:
- SIGHUP:用户从终端注销,所有已启动进程都将收到该进程。系统缺省状态下对该信号的处理是终止进程。
- SIGINT:程序终止信号。程序运行过程中,按
Ctrl+C键将产生该信号。 - SIGQUIT:程序退出信号。程序运行过程中,按
Ctrl+\键将产生该信号。 - SIGBUS和SIGSEGV:进程访问非法地址。
- SIGFPE:运算中出现致命错误,如除零操作、数据溢出等。
- SIGKILL:用户终止进程执行信号。shell下执行
kill -9发送该信号。 - SIGTERM:结束进程信号。shell下执行
kill 进程pid发送该信号。 - SIGALRM:定时器信号。
- SIGCLD:子进程退出信号。如果其父进程没有忽略该信号也没有处理该信号,则子进程退出后将形成僵尸进程。
可以使用kill -l查看当前系统可用信号有哪些
处理步骤
- 信号被某个进程产生,并设置此信号传递的对象(一般为对应进程的pid),然后传递给操作系统;
- 操作系统根据接收进程的设置(是否阻塞)而选择性的发送给接收者,如果接收者阻塞该信号(且该信号是可以阻塞的),操作系统将暂时保留该信号,而不传递,直到该进程解除了对此信号的阻塞(如果对应进程已经退出,则丢弃此信号),如果对应进程没有阻塞,操作系统将传递此信号。
- 目的进程接收到此信号后,将根据当前进程对此信号设置的预处理方式,暂时终止当前代码的执行,保护上下文(主要包括临时寄存器数据,当前程序位置以及当前CPU的状态)、转而执行中断服务程序,执行完成后在回复到中断的位置。当然,对于抢占式内核,在中断返回时还将引发新的调度。

消息队列
- 消息队列是存放内核的消息链表,每个消息队列由消息标识符表示
- 与管道不同的是,消息队列存放再内核中,只有内核重启或显示地删除一个消息队列时,其才被删除
- 某一进程在往消息队列写数据时,不需要另一个进程在该队列上等待消息的到达。
- 另外与管道不同的是,消息队列在某个进程往一个队列写入消息之前,并不需要另外某个进程在该队列上等待消息的到达
消息队列特点总结:
- 消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识.
- 消息队列允许一个或多个进程向它写入与读取消息
- 管道和消息队列的通信数据都是先进先出的原则。
- 消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比FIFO更有优势。
- 消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺。
- 目前主要有两种类型的消息队列:POSIX消息队列以及System V消息队列,System V消息队列目前被大量使用。System V消息队列是随内核持续的,只有在内核重起或者人工删除时,该消息队列才会被删除。
- SOCK_STREAM(流套接字)
- 不会丢失
- 按序传输
- 发送接收端不同步
SOCK_DGRAM(数据包套接字)
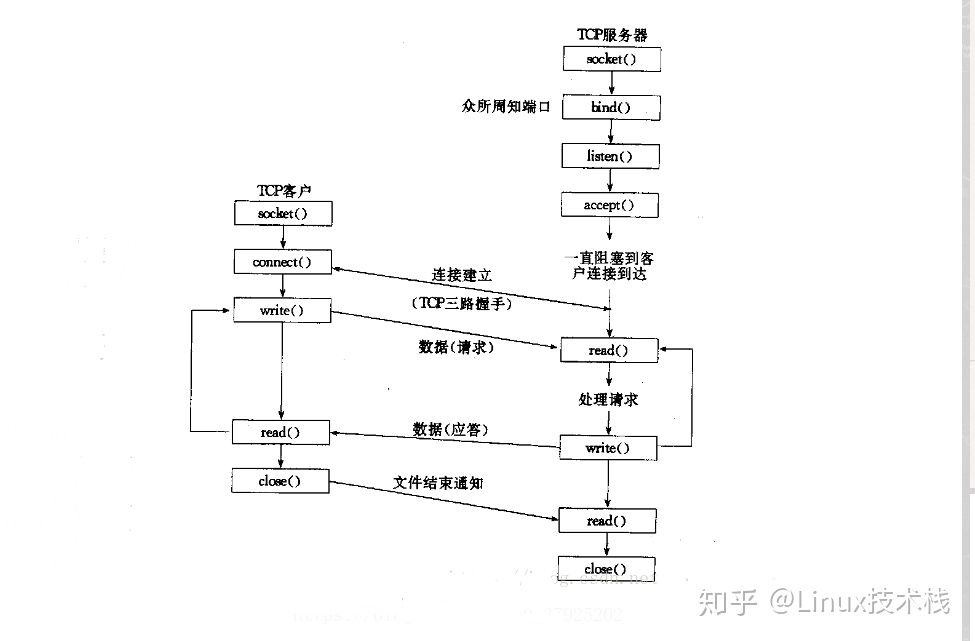
TCP网络程序
- 服务端
- socket()创建套接字
- setsockopt()设置端口复用,多个客户端可同时连接同一个端口
- bind()绑定端口号
- listen()监听端口队列是否有连接请求
- accept()接受请求
- close()关闭套接字
- 客户端
- socket()创建套接字
- bind()绑定端口号
- connect()请求连接服务器
- 发送数据write
- 请求数据read
- close()关闭套接字
- 服务端
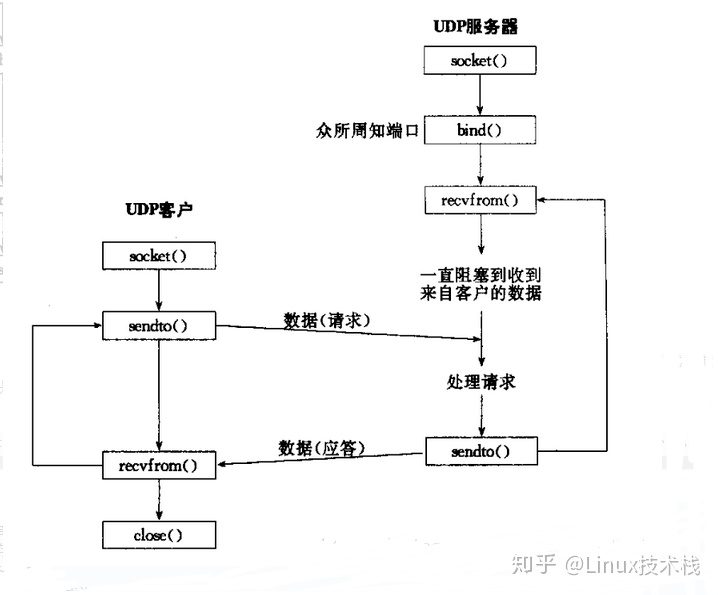
- UDP网络程序
- 服务端
- 少了listen()和connect()
- 客户端
- 少了connect()
- 服务端
TCP三次握手
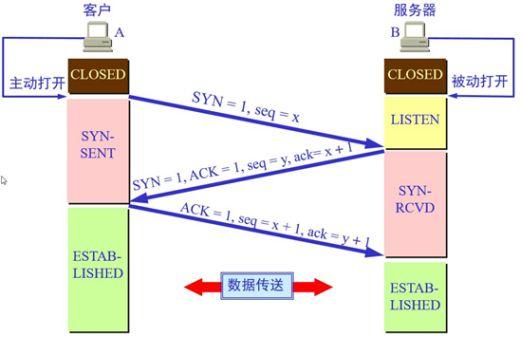
- 客户端向服务器发送一段TCP报文:
- 置SYN标志位,表示”请求建立连接”
- 序号为x
- 客户端进入SYN-SENT状态
- 处于监听状态的服务器接收到客户端发来的报文,结束LISTEN阶段,并返回一段TCP报文:
- 置SYN与ACK,表示”确认客户端的报文seq有效,服务器可正常接收客户端发送的数据,同意建立连接”
- 序号设置y;
- 服务器进入SYN-RECV阶段
- 客户端接收到服务器发来的报文,明确了客户端到服务器之间的连接正常,结束SYN-SENT阶段,进入ESTABLISHED阶段
- 置ACK,表示”确认服务端报文seq有效,客户端可正常接收服务端数据”
- 序号设置为x+1,表示”正确收到服务端ack”
- ack置为y+1,表示”收到服务端seq”
为什么需要三次握手?
防止失效的连接请求报文段被服务器接受,从而产生错误。
两次握手时,服务端在收到客户端的请求连接报文时,就进入ESTABLISHED阶段(无需经历SYN-RECV),这回导致失效的请求连接报文激活服务器,导致服务器一直等待的问题。 即当客户端发送的报文被服务器接收后,服务器回复一条TCP报文,若此时网络拥塞,客户端迟迟未收到服务器的应答,则客户端重发连接报文,服务端接收后建立连接、发送数据并断开连接。 断开连接后,服务器收到【客户端第一次发来的请求连接报文】,进入ESTABLISHED状态,等待接收数据(若是等待发送数据或发送数据(因为对端已经关闭,有写无读),会收到内核触发的reset导致连接关闭)。而此时客户端已处于closed状态,故服务器会一直等待下去,浪费服务器资源。
边沿触发(核心是变化!)与水平触发(有内容就频繁触发)的区别
ET模式下,仅在监视的描述符状态发生改变,才会传送事件
ET模式的建议方法:
- 非阻塞的文件描述符
-
边沿触发下,假设缓冲区中有数据,读了一半不读了,这时候又来了数据,句柄处于触发态还是非触发态?
以得出ET模式下被唤醒(返回就绪)的条件为:
空->不空 内容变多 满->不满 内容变少
对于读取操作:
(1) 当buffer由不可读状态变为可读的时候,即由**空变为不空**的时候。
(2) 当有新数据到达时,即buffer中的待读**内容变多**的时候。
另外补充一点:
(3) 当buffer中有**数据可读(即buffer不空)且用户对相应fd进行epoll_mod IN**事件时(具体见下节内容)。
对于情况(1)(2)分别对应图1(a),图1(b)。
- 对于写操作:
(1) 当buffer由不可写变为可写的时候,即由**满状态变为不满状态**的时候。
(2) 当有旧数据被发送走时,即buffer中待写的**内容变少**得时候。
另外补充一点:
(3) 当buffer中有**可写空间(即buffer不满)且用户对相应fd进行epoll_mod OUT事件时**
LT
LT模式下进程被唤醒(描述符就绪)的条件就简单多了,它包含ET模式的所有条件,也就是上述列出的六中读写被唤醒的条件都是用于LT模式。此外,还有更普通的情况LT可以被唤醒,而ET则不理会,这也是我们需要注意的情况。
l 对于读操作
当buffer中有数据,且数据被读出一部分后buffer还不空的时候,即buffer中的内容减少的时候,LT模式返回读就绪。如下图所示。 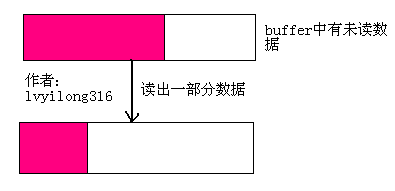
l 对于写操作
当buffer不满,又写了一部分数据后扔然不满的的时候,即由于写操作的速度大于发送速度造成buffer中的内容增多的时候,LT模式会返回就绪。如下图所示。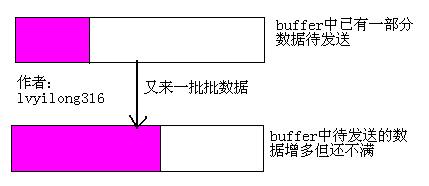
注:poll和select都是LT模式。
TCP如何实现流量控制和拥塞控制
流量控制
滑动窗口来实现流量控制。
- 第一次发送数据的窗口大小由【链路带宽】决定
- 数据重传:由于捎带确认,即使确认应答包丢失,也不用重传确认应答报
- 三次重复ACK:通知发送端立即重发数据包
- 发送窗口
- 最左端的数据收到确认后,向右滑动
接收窗口
cwnd: 拥塞窗口
- ssthresh: 慢开始门限
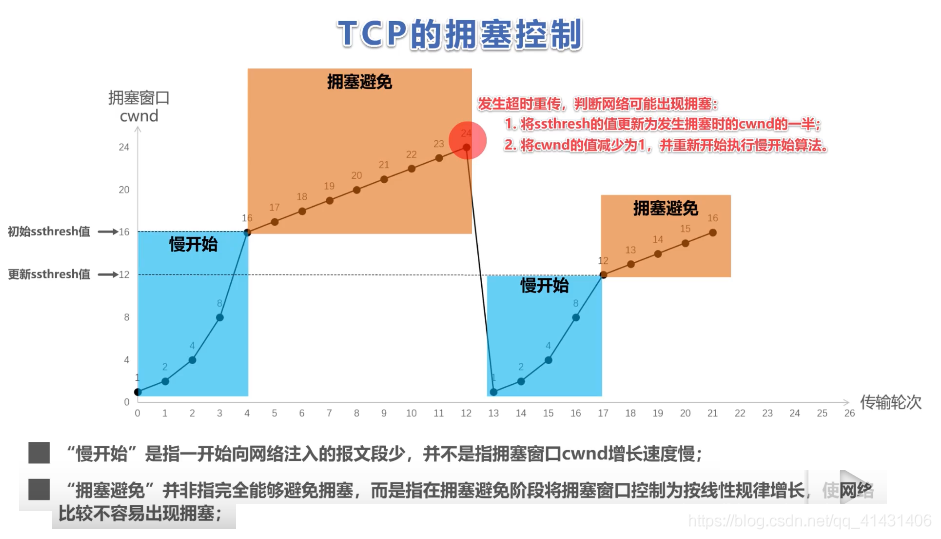
快恢复
触发条件:发送端接收到3个重复ACK,即丢失个别报文段。 结果:不启动慢开始,将cwnd和慢开始门限设置为当前窗口的一半,并进行拥塞避免算法;
- 为什么有的快恢复会把cwnd设置为new_sshresh+3?
答:既然发送端接收到3个重复ACK,说明有3个ACK离开了网络,整个网络中减少了3个报文段,所以此处+3;
什么是快重传?
重传有2中方式:
- 超时重传计时器
- 三次重复ACK
接收端连续发送三个重复ACK,以告知发送端尽快进行重传,而不是等待超时重传计时器超时再重传!
对接收端有什么要求?
- 避免等待捎带确认,而是立即发送确认
- 即使收到失序的报文段,也要立即发出对已收到报文段的重复确认
SQL注入
HTTP协议,GET和POST区别
HTTP定义了与服务器交互的不同方法,最基本的四种,为GET,POST,PUT,DELETE,对应查改增删,
- GET:获取/查询资源
- POST:更新资源信息
PUT:让服务器用请求的主体部分创建一个由所请求URL命名的新文档,是幂等的
PUT和POST的主要区别在于PUT是幂等的,POST重复请求具有多次创建相同资源的副作用
DELETE: 请求服务器删除URL所对应的资源【客户端无法保证删除操作一定会执行,因为HTTP规范允许服务器在不通知客户端的情况下撤销请求】
GET
通常用于请求服务器发送某个资源,安全和幂等的
安全:指该操作仅用于获取信息而非修改信息
- 幂等:对同一个URL请求返回相同的结果
特征:
特征:
答:GET请求的数据会附在URL之后,以?分隔URL和传输数据,参数之间以&分隔。例如login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0%E5%A5%BD。
而POST
| GET | POST | |
|---|---|---|
| 后退按钮/刷新 | 无害 | 数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 |
| 书签 | 可 | 不可 |
| 缓存 | 能 | 不能 |
| 编码类型 | application/x-www-form-urlencoded | application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。 |
| (参数保存)浏览器历史 | 保留 | 不保留 |
| 对数据长度的限制 | 是的。当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。 | 无限制。 |
| 对数据类型的限制 | 只允许 ASCII 字符。 | 没有限制。也允许二进制数据。 |
| 安全性 | 与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。 在发送密码或其他敏感信息时绝不要使用 GET ! |
POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。 |
| 可见性 | 数据在 URL 中对所有人都是可见的。 | 数据不会显示在 URL 中。 |
#include <atomic>#include <cstdio>#include <thread>#include <vector>using namespace std;atomic<int> cnt_;atomic<int> who; // who 用于判断轮到哪个线程输出void threadFun(int i, int end_, int N){while(cnt_ <= end_){if(who.load() == i){printf("Thread%d-%d\n",i, cnt_.load() % i);cnt_++;who++; // next thread to printfif(who == N) // reset , let thread0 to printfwho = 0;}}}// 下面的for生成的thread要加入vector中,然后在main返回前join// 不能定义的时候给初始值// 在main里赋值为0!!!!!!!!!!!!!!!!!!!!!!!!!!// !!!!!!!!!!!!!!!int main(){cnt_ = 0;who = 0;int N_ =4, M_ = 7;vector<std::thread> mythreads;for(int i = 0; i < N_; i++){mythreads.push_back(std::thread(threadFun, i, M_, N_));}for(std::thread& t : mythreads)t.join();return 0;}
需要改进的地方:
- 找项目里面更深入的点进行挖掘!

若有收获,就点个赞吧
0 人点赞
