并发模型
程序使用Reactor模型,并使用多线程提高并发度。为避免线程频繁创建和销毁带来的开销,使用线程池,在程序的开始创建固定数量的线程。使用epoll作为IO多路复用的实现方式。
线程
一般而言,多线程服务器中的线程可分为以下几类:
- IO线程(负责网络IO)
- 计算线程(负责复杂计算)
- 第三方库所用线程
本程序中的Log线程属于第三种,其它线程属于IO线程,因为Web静态服务器计算量较小,所以没有分配计算线程,减少跨线程分配的开销,让IO线程兼顾计算任务。除Log线程外,每个线程一个事件循环,遵循One loop per thread。
并发模型
本程序使用的并发模型如下图所示: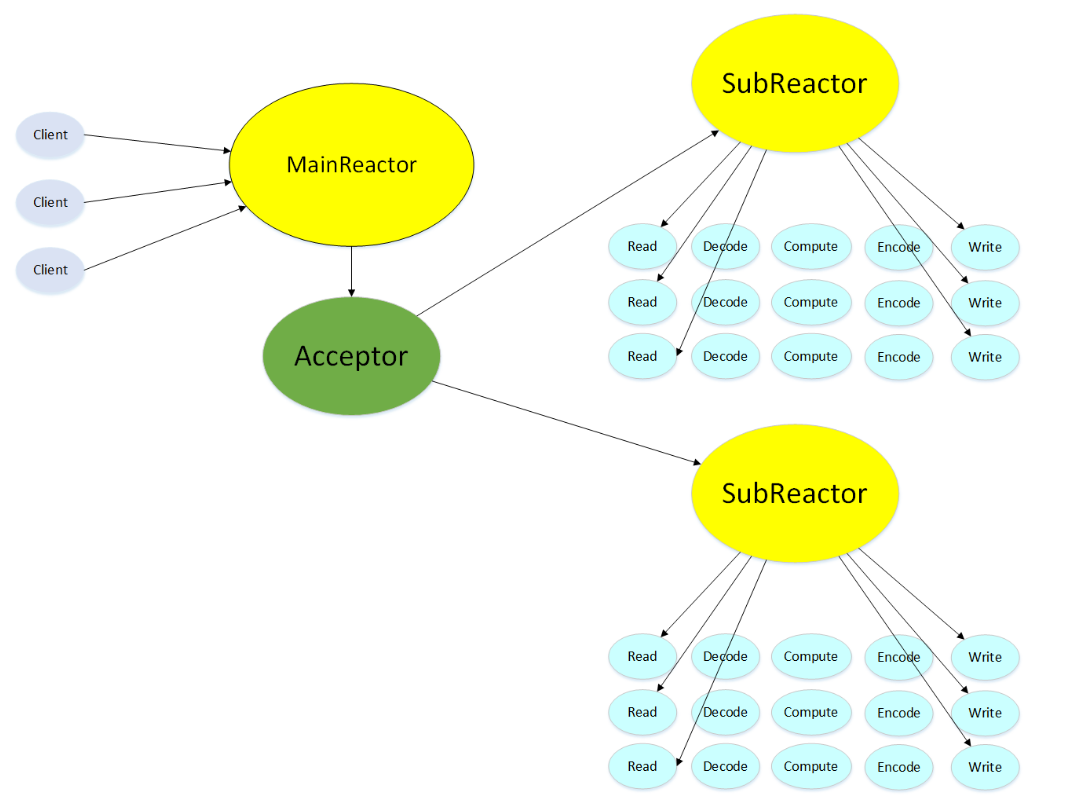
MainReactor只有一个,负责响应client的连接请求,并建立连接,它使用一个NIO Selector。在建立连接后用Round Robin的方式分配给某个SubReactor,因为涉及到跨线程任务分配,需要加锁,这里的锁由某个特定线程中的loop创建,只会被该线程和主线程竞争。
SubReactor可以有一个或者多个,每个subReactor都会在一个独立线程中运行,并且维护一个独立的NIO Selector。
当主线程把新连接分配给了某个SubReactor,该线程此时可能正阻塞在多路选择器(epoll)的等待中,怎么得知新连接的到来呢?这里使用了eventfd进行异步唤醒,线程会从epoll_wait中醒来,得到活跃事件,进行处理。
我学习了muduo库中的runInLoop和queueInLoop的设计方法,这两个方法主要用来执行用户的某个回调函数,queueInLoop是跨进程调用的精髓所在,具有极大的灵活性,我们只需要绑定好回调函数就可以了,我仿照muduo实现了这一点。
epoll工作模式
epoll的触发模式在这里我选择了ET模式,muduo使用的是LT,这两者IO处理上有很大的不同。ET模式要比LE复杂许多,它对用户提出了更高的要求,即每次读,必须读到不能再读(出现EAGAIN),每次写,写到不能再写(出现EAGAIN)。而LT则简单的多,可以选择也这样做,也可以为编程方便,比如每次只read一次(muduo就是这样做的,这样可以减少系统调用次数)。
定时器
每个SubReactor持有一个定时器,用于处理超时请求和长时间不活跃的连接。muduo中介绍了时间轮的实现和用stl里set的实现,这里我的实现直接使用了stl里的priority_queue,底层是小根堆,并采用惰性删除的方式,时间的到来不会唤醒线程,而是每次循环的最后进行检查,如果超时了再删,因为这里对超时的要求并不会很高,如果此时线程忙,那么检查时间队列的间隔也会短,如果不忙,也给了超时请求更长的等待时间。
核心结构
程序中的每一个类和结构体当然都必不可少,其中能体现并发模型和整体架构的,我认为是有两个:
- Channel类:Channel是Reactor结构中的“事件”,它自始至终都属于一个EventLoop,负责一个文件描述符的IO事件,在Channel类中保存这IO事件的类型以及对应的回调函数,当IO事件发生时,最终会调用到Channel类中的回调函数。因此,程序中所有带有读写时间的对象都会和一个Channel关联,包括loop中的eventfd,listenfd,HttpData等。
EventLoop:One loop per thread意味着每个线程只能有一个EventLoop对象,EventLoop即是时间循环,每次从poller里拿活跃事件,并给到Channel里分发处理。EventLoop中的loop函数会在最底层(Thread)中被真正调用,开始无限的循环,直到某一轮的检查到退出状态后从底层一层一层的退出。
Log
Log的实现了学习了muduo,Log的实现分为前端和后端,前端往后端写,后端往磁盘写。为什么要这样区分前端和后端呢?因为只要涉及到IO,无论是网络IO还是磁盘IO,肯定是慢的,慢就会影响其它操作,必须让它快才行。
这里的Log前端是前面所述的IO线程,负责产生log,后端是Log线程,设计了多个缓冲区,负责收集前端产生的log,集中往磁盘写。这样,Log写到后端是没有障碍的,把慢的动作交给后端去做好了。
后端主要是由多个缓冲区构成的,集满了或者时间到了就向文件写一次。采用了muduo介绍了“双缓冲区”的思想,实际采用4个多的缓冲区(为什么说多呢?为什么4个可能不够用啊,要有备无患)。4个缓冲区分两组,每组的两个一个主要的,另一个防止第一个写满了没地方写,写满或者时间到了就和另外两个交换指针,然后把满的往文件里写。
与Log相关的类包括FileUtil、LogFile、AsyncLogging、LogStream、Logging。 其中前4个类每一个类都含有一个append函数,Log的设计也是主要围绕这个append函数展开的。FileUtil是最底层的文件类,封装了Log文件的打开、写入并在类析构的时候关闭文件,底层使用了标准IO,该append函数直接向文件写。
- LogFile进一步封装了FileUtil,并设置了一个循环次数,每过这么多次就flush一次。
- AsyncLogging是核心,它负责启动一个log线程,专门用来将log写入LogFile,应用了“双缓冲技术”,其实有4个以上的缓冲区,但思想是一样的。AsyncLogging负责(定时到或被填满时)将缓冲区中的数据写入LogFile中。
- LogStream主要用来格式化输出,重载了<<运算符,同时也有自己的一块缓冲区,这里缓冲区的存在是为了缓存一行,把多个<<的结果连成一块。
- Logging是对外接口,Logging类内涵一个LogStream对象,主要是为了每次打log的时候在log之前和之后加上固定的格式化的信息,比如打log的行、文件名等信息。

若有收获,就点个赞吧
0 人点赞
