一面
详细说一下epoll
插播:socket 的本质是一种资源,它包含了端到端的四元组信息,用来标识数据包的归属。
讲概念
epoll是IO多路复用的一种,其他包括select和poll。IO可以分为三种,分别是阻塞IO、非阻塞IO、IO多路复用。
IO多路复用指的是同时监控多个描述符,一旦某个描述符就绪,就通知程序进行读写。
select,poll,epoll区别
IO多路复用(multiplexing): 单个线程通过记录跟踪每一个socket(IO流)的状态来同时管理多个IO流

select:
每次调用select,都需要把fd集合再用户态和内核态来回拷贝,耗时! 每次调用select都会在内核遍历fd集合,耗时
- 函数会修改传入参数
- 需要轮询查找触发的事件
- 最多监视1024个套接字描述符
- 非线程安全(若某个被select监听的fd被其他进程关闭,结果不可预测)
- select为什么会慢?
- 需要轮询查找触发的描述符
- 通知事件给用户进程,需要将整个bitmap拷贝到用户空间,让用户查询
- poll:
相较于select,其管理fd集合的方式仍未轮询,耗时! 过程:它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。
- epoll:
- 解决了select和poll的缺点
- 无最大并发连接限制,socket描述符限制
- 不采用轮询的方式,查询触发事件的效率 为O(1)
- 内存拷贝,利用mmap文件映射加速与内核空间的消息传递
如何使用epoll

主要有如下3个函数服务与epoll机制;
- 调用epoll_create,其会在epoll文件系统中创建file对象,并在内核中开辟cache用于存储红黑树和双向链表(就绪列表)。
- 调用epoll_ctl,会将socket添加epoll文件系统创建的file对象的红黑树上,还会给内核中断处理程序注册一个回调函数,当该句柄的中断事件发生,则将其添加至file对象的双向链表上。
- 调用epoll_wait,当有事件发生时,则返回事件发生的次数,事件的句柄存储在双向链表上;若epoll_wait无事件发生,则一直阻塞或等待一段时间后返回0,或被中断。
说说epoll的触发模式
epoll触发模式主要分为LT和ET,LT为水平触发模式,是默认模式,ET为边沿触发模式。
LT和ET的区别便在触发机制上,LT模式很简单,我来先讲讲LT模式把。
LT水平触发,顾名思义,只要缓冲区里有数据,就回触发epoll_wait返回。主要的步骤逻辑是:
对于读事件,若缓冲区第一次没读完,LT模式下内核会频繁检测该句柄状态,若检测到该句柄未读完,则将其从新加入EPOLL的双向链表中,状态为读就绪。
对于写事件,若缓冲区一次没写完,即缓冲区中还剩下数据,则将其新加入EPOLL的双向链表中,状态为写就绪。
ET模式,确实比较难理解,linux 自带的manual中也没有将ET模式的触发问题叙述清楚。一般来说,ET的触发模式如下:
对于读事件,当缓冲区由空到非空时,读事件触发;
对于写事件,当缓冲区由满到不满时,写事件触发;
但经过我的代码测试,还有如下两种情况会触发ET模式下的事件,我的代码时在内核版本为4.18的机器上运行的。
对于读事件,当缓冲区数据变多时,读事件触发;
对于写事件,当缓冲区数据变少时,写事件触发;
我简单描述一下我的代码实现:
- 创建一个客户端和一个服务器
- 客户端往缓冲区中写入8个字节数据,比如aaaabbbb
- 服务器从缓冲区每次拿4个字节数据,服务器通过epoll实现,注册了客户端的连接描述符
从我的测试结果来看,客户端每次写时,服务器才拿数据,说明了,
对于读事件,当缓冲区数据增多时,读事件会触发。
epoll为什么高效
减少了用户态和内核态的文件句柄拷贝
减少了对可读、可写句柄的遍历
mmap加速了内核与用户空间的信息传递,epoll通过内核与用户mmap同一块内存,避免了无谓的内存拷贝。IO性能不会随着监听的文件描述符数量增加而下降
使用红黑树来存储注册的句柄,增删的性能都非常好
mmap深度剖析
【深入浅出Linux】关于mmap的解析
mmap:在进程虚拟地址空间分配地址空间,创建和物理内存的映射关系。
- 映射关系
- 文件映射:磁盘文件映射进程的虚拟空间,使文件内容初始化物理内存。
- 匿名映射:初始化全为0的内存空间
- 映射关系是否共享
- 私有映射:多进程数据共享,修改不反映到磁盘文件【写时复制】
- 共享映射:多进程数据共享,修改反映到磁盘文件。
- 总结(四种组合)
- 私有文件映射:多个进程共享相同的物理页,但各个进程对内存文件的修改不会共享,也不会反映到磁盘文件
- 私有匿名映射:mmap会创建一个新的映射(虚拟地址到物理地址),各个进程不共享,这种使用主要用于分配内存(malloc分配大内存会调用mmap)。例如开辟新进程时,会为每个进程分配虚拟的地址空间,这些虚拟地址映射的物理内存空间各个进程间【读共享、写复制】
- 共享文件映射:多个进程共享同样的物理内存空间,对内存空间的修改反映到实际文件中,【IPC的一种】
- 共享匿名映射:这种机制在fork时不会【写时复制】,父子进程完全共享相同的物理内存也,实现了父子进程间通信【IPC】
注意:
- mmap只是在虚拟内存分配了空间,只有在第一次访问虚拟内存时才分配物理页
在mmap之后,并没有将文件内容加载到物理页上,仅在虚拟内存中分配了地址空间。当进程在访问这段虚拟地址映射的物理地址时,通过查找页表,发现虚拟地址对应的页没有在物理内存中缓存,触发“缺页中断”,由内核的缺页异常处理程序处理,将该文件内容,以页为单位(4K)加载到物理内存。
- mmap只是在虚拟内存分配了空间,只有在第一次访问虚拟内存时才分配物理页
mmap在write和read时的情况
- write
- 进程(用户态)将需要写入的数据copy到对应的mmap地址(内存copy)
- 若mmap未对应物理内存,则产生缺页异常,由内核处理
- 若对应,则直接copy到对应内存
- 由操作系统调用,将脏页写回磁盘(一般异步)
- read
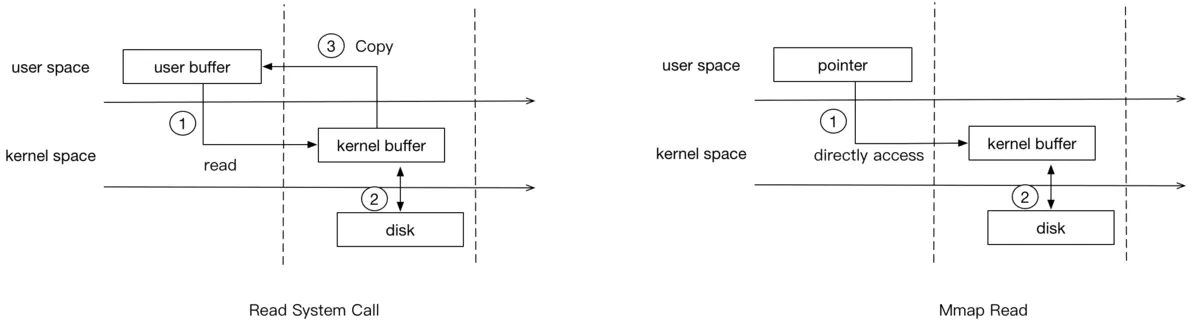
- 图1,由于进程无法直接访问内核,内核需要将数据copy给用户态的buffer(需要2次用户态内核态之间的切换)
- 图2,mmap之后,进程可以直接访问mmap的数据
- write
Nagle算法(收集小分组并合并)
减少需要发送包的数量来提高TCP/IP传输的效率,即避免发送小的数据包 如何实现:
- TCP连接上只能有一个未被确认的小分组,在该分组的确认到达之前,不能发送其他的小分组。
- TCP收集这些小分组,并在确认到来时以一个分组的方式发送出去
small packet problem
Telnet存在一个字节发送的场景,每次发送一个字节数据,会产生41字节(20TCP+20IP)长度的分组,开销巨大,也会增加广域网的拥塞
if there is new data to sendif the window size >= MSS and available data is >= MSSsend complete MSS segment nowelseif there is unconfirmed data still in the pipeenqueue data in the buffer until an acknowledge is receivedelsesend data immediatelyend ifend ifend if
服务器端accept后创建的connfd,其socket的ip和端口如何?
从磁盘打开一个文件,并通过网络发送出去,本地需要几次拷贝?(即一次读写和发送)
传统read,write
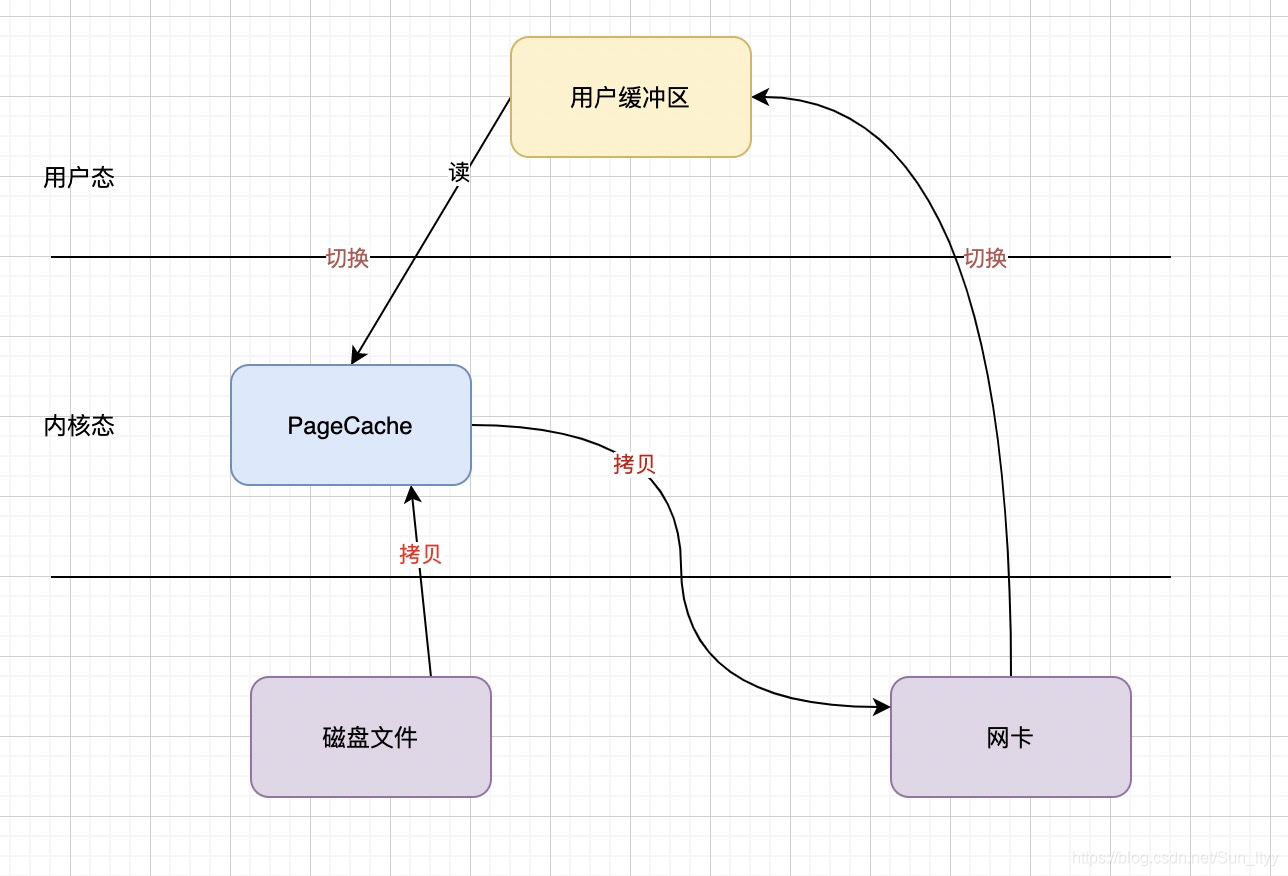
4次拷贝!4次用户态和内核态的切换

- 通过DMA将数据从磁盘读入内核
- CPU把内核数据拷贝到用户缓冲区(堆外内存)
- CPU把用户缓冲区的数据拷贝到socket缓冲区
- DMA把socket缓冲区的数据拷贝到网卡发送
“零拷贝”技术(指的是用户态到内核态的两次拷贝免了)
“零拷贝”技术又称作【缓存IO->PageCache】 pageCache会预读一部分内容缓存到高速缓冲区,采用LRU算法,故只适用于小文件
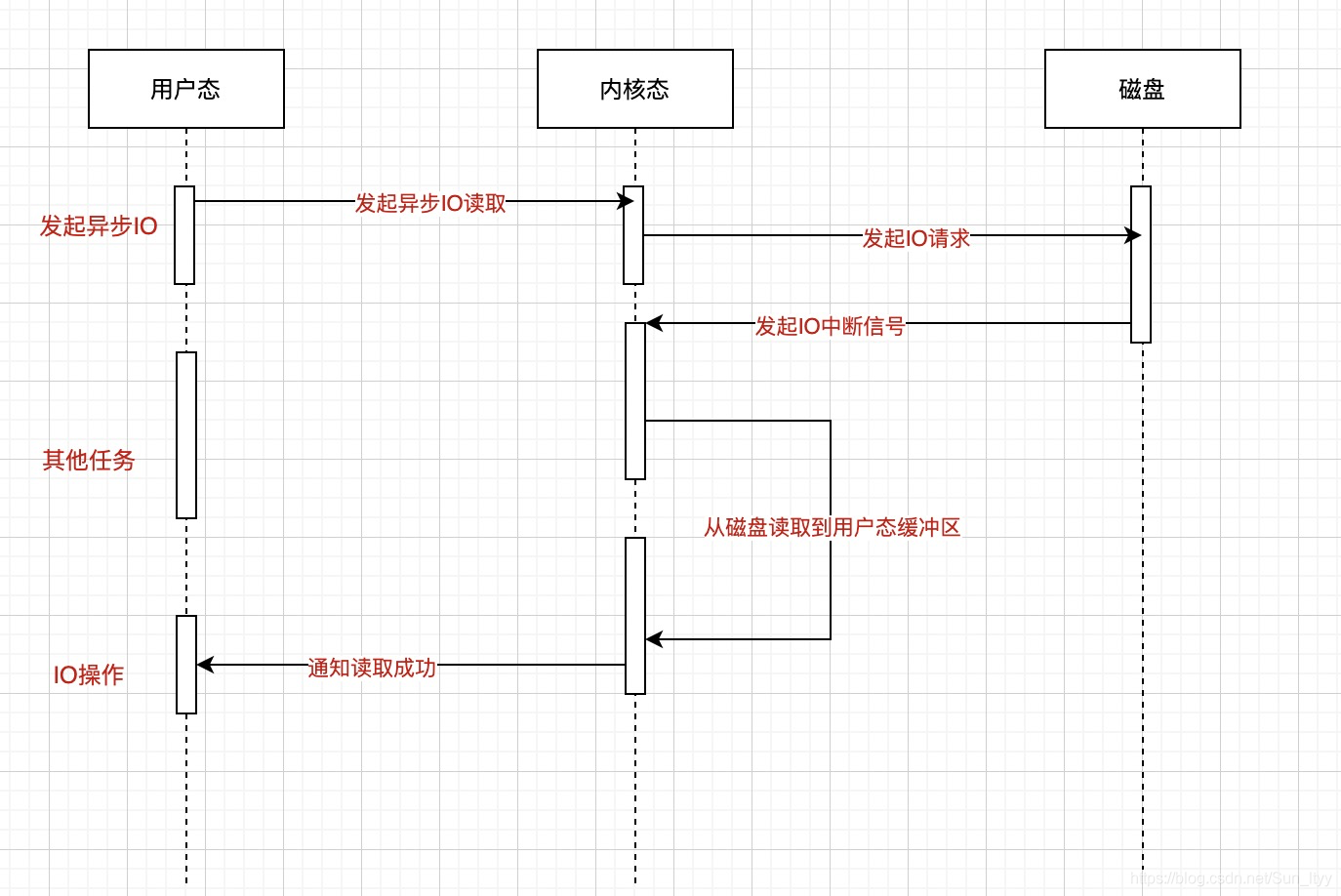
异步IO
异步IO绕过了PageCache,故又称作直接IO 适合大文件传输
C++生成可执行性文件步骤,动态库与静态库区别
- 预处理
- 编译(生成*.s)
- 优化阶段:
- 汇编(生成*.o):汇编语言翻译程机器指令
链接 (生成*.out):将有关的目标文件彼此相连接
LIBRARY_PATH 编译器查找动态链接库路径
LD_LIBRARY_PATH 运行期查找动态链接库的路径,会在系统默认路径之前查找。
-fPIC
告诉编译器产生与位置无关的代码
则产生的代码中,没有绝对地址,全部使用相对地址,故而代码可以被加载到内存的任意位置,都可以正确执行注意:
不加fPIC编译出的动态库,加载时,根据加载到的位置需要重定位(因为代码并非位置无关)
如果被多个应用程序共同使用该库,那么每个程序都必须维护一份so的代码副本(因为so被每个程序加载的位置都不同,显示这些重定位后的代码也不同,不可共享)动态库在哪里?
在链接器创建共享库时,并不预先知道动态库将在哪里载入。解决这个问题有两个方法:
载入时重定位(它需要时间执行,并且它使得库的代码节不可共享。)- 位置无关代码(PIC)
PIC介绍
核心思想:对代码中访问的所有全局数据和函数添加一层额外的抽象,巧妙的利用链接与载入过程中的某些工件,使得共享库的代码真正位置无关。
僵尸进程是什么?如何避免僵尸进程
给进程设置僵尸状态的原因:
维护子进程信息,以便父进程在以后某个时间获取。
信息包括:进程ID,终止状态及资源利用信息
产生僵尸进程的原因:
子进程先于父进程退出,同时父进程又没有调用wait/waitpid
如何避免僵尸进程:
- 建立一个捕获SIGCHLD的信号处理函数
- 问题:若多个子进程同时发SIGCHLD信号怎么办?(UNIX信号不排队)
- 答:waitpid配合WNOHANG选项。
- 问题:若多个子进程同时发SIGCHLD信号怎么办?(UNIX信号不排队)
-
c++11有哪些新特性
auto
- std::unordered_map、unordered_set
- std::thread,std::atomic,std::condition_variable
- std::shared_ptr,std::weakptr
- std::function,std::bing
-
unique_ptr如何实现仅有一份
指针离开作用域是不会析构的,但类离开作用域时会自动析构;智能指针实际上是一种通过类来管理指针的一种实现。
如何实现独占指针呢?
在类中把拷贝构造函数和赋值构造函数deleted掉就可以了,这样便不可对指针指向进行拷贝,也不能产生指向同一个对象的指针。
说说shared_ptr
shared_ptr是智能指针模板类的一种模板,能实现多个对象管理同一个指针。
其管理的指针指向动态分配对象,用于生存期控制,能够确保自动销毁动态分配的对象,防止内存泄漏。
其实现技术为:引用计数。
- 每次拷贝构造函数都会对引用技术+1;
- 每次赋值构造函数会对原对象引用计数-1,新对象引用计数+1;
-
创建一个自定义数据的map
创建一个比较类,重载operator()
- 自定义类中实现重载operator<
```cpp
template
, class A = allocator > map
class Person(){ public: int year; int height; bool operator<(const Person& rhs){ if(year==rhs.year){ return height<_rhs.height; } return year<rhs.year; } };
class Cmp(){ bool operator()(const Person& lhs,const Person& _rhs){ if(_lhs.year==rhs.year){ return lhs.height<rhs.height; } return lhs.year<rhs.year_; } };
<a name="q5VVT"></a>## 延伸:创建一个自定义数据的unordered_map```cpptemplate<class Key,class Ty,class Hash = std::hash<Key>,class Pred = std::equal_to<Key>, /* operator== 或重载operator()*/class Alloc = std::allocator<std::pair<const Key, Ty> > >class unordered_map;> class unordered_mapclass Person(){public:int year_;int height_;string name_;bool operator==(const Person& _rhs){return height_==_rhs.height_ && year_==rhs.year_ && name_=_rhs.name_;}};size_t person_hash(const Person& p){return hash<string>()(p.name_)^hash<int>()(p.year_);}std::function<size_t (const Person&)> hash_;/* 第一种方式 */unordered_map<Person,int,hash_> umap(100,person_hash);/* 第二种方式 */unordered_map<Person,int,decltype(&person_hash)> umap(100,person_hash);/* decltype 用于查询表达式的数据类型 */
二面
面试比较简单,突击面试,电话面试
UDP和TCP可以共用同一端口吗?为什么?
EPOLL相关,ET和LT
虚拟内存相关,进程虚拟地址有哪些部分组成,各有什么作用
问项目,WebServer,如何实现的,并发量是多少,瓶颈在哪里,如何解决,下一步是怎么规划的?
虚拟继承是什么?
算法题:二维平面存在多个坐标点,找出共线最多的点的数量。

若有收获,就点个赞吧
0 人点赞
