- 一、集合容器概述
- 二、Collection接口
- 1、List接口
- 1.1 迭代器Iterator是什么?
- 1.2 Iterator怎么使用?有什么特点?
- 1.3 如何边遍历边移除Collection中的元素?
- 1.4 Iterator和ListIterator有什么区别?
- 1.5 遍历一个List有哪些不同的方式?每种方法的实现原理是什么?Java中List遍历的最佳实践是什么?
- 1.6 说一下ArrayList的优缺点
- 1.7 如何实现数组和List之间的转换?
- 1.8 ArrayList和LinkedList的区别是什么?
- 1.9 ArrayList和Vector的区别是什么?
- 1.10 插入数据时,ArrayList、LinkedList、Vector谁速度较快?阐述ArrayList、Vector、LinkedList的存储性能和特性?
- 1.11 多线程场景下如何使用ArrayList?
- 1.13 List和Set的区别
- 2、Set接口
- 4、Map接口
- 4.1 说一下HashMap的实现原理?
- 4.2 HashMap在JDK1.7和JDK1.8中有哪些不同?HashMap的底层实现
- 4.3 HashMap的put方法的具体流程?
- 4.4 HashMap的扩容操作是怎么实现的?
- 4.5 HashMap是怎么解决哈希冲突的?
- 4.6 能否使用任何类作为Map的key?
- 4.7 为什么HashMap中String、Integer这样的包装类适合作为K?
- 4.8 如果使用Object作为HashMap的Key,应该怎么办呢?
- 4.9 HashMap为什么不直接使用hashCode()处理后的哈希值直接作为table的下标?
- 4.10 HashMap的长度为什么是2的幂次方
- 4.11 HashMap与HashTable有什么区别?
- 4.12 如何决定使用HashMap还是TreeMap?
- 4.13 ConcurrentHashMap底层具体实现知道吗?实现原理是什么?
- 5、辅助工具类
- 1、List接口
一、集合容器概述
1、什么是集合
集合框架:用于存储数据的容器。
集合框架是为表示和操作集合而规定的一种统一的标准的体系结构。任何集合框架都包含三大块内容:对外的接口、接口的实现和对集合运算的算法。
接口:表示集合的抽象数据类型。接口允许我们操作集合时不必关注具体实现,从而达到“多态”。在面向对象编程语言中,接口通常用来形成规范。
实现:集合接口的具体实现,是重用性很高的数据结构。
算法:在一个实现了某个集合框架中的接口的对象身上完成某种有用的计算的方法,例如查找、排序等。这些算法通常是多态的,因为相同的方法可以在同一个接口被多个类实现时有不同的表现。事实上,算法是可复用的函数。它减少了程序设计的辛劳。
集合框架通过提供有用的数据结构和算法使你能集中注意力于你的程序的重要部分上,而不是为了让程序能正常运转而将注意力于底层设计上。
通过这些在无关API之间的简易的互用性,使你免除了为改编对象或转换代码以便联合这些API而去写大量的代码。它提高了程序速度和质量。
2、集合的特点
集合的特点主要有如下两点:
- 数组是固定长度的;集合可变长度的。
- 数组可以存储基本数据类型,也可以存储引用数据类型;集合只能存储引用数据类型。
- 数组存储的元素必须是同一个数据类型;集合存储的对象可以是不同数据类型。
数据结构:就是容器中存储数据的方式。
对于集合容器,有很多种。因为每一个容器的自身特点不同,其实原理在于每个容器的内部数据结构不同
集合容器在不断向上抽取过程中,出现了集合体系。在使用一个体系的原则:参阅顶层内容。建立底层对象。
4、使用集合框架的好处
- 容量自增长;
- 提供了高性能的数据结构和算法,使编码更轻松,提高了程序速度和质量;
- 允许不同API之间的互操作,API之间可以来回传递集合;
- 可以方便地扩展或改写集合,提高代码复用性和可操作性。
通过使用JDK自带的集合类,可以降低代码维护和学习新API成本。
5、常用的集合类有哪些?
Map接口和Collection接口是所有集合框架的父接口:
Collection接口的子接口包括:Set接口和List接口
- Map接口的实现类主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap以及Properties等
- Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
6、List,Set,Map三者的区别?List、Set、Map是否继承自Collection接口?List、Map、Set三个接口存取元素时,各有什么特点?
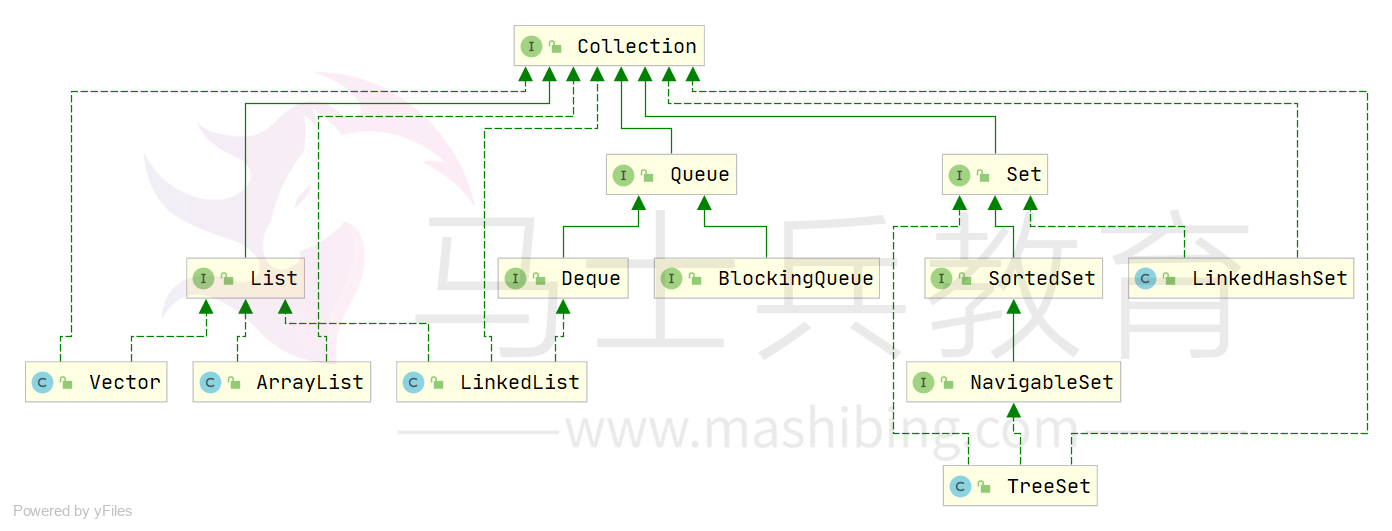
Java容器分为Collection和Map两大类,Collection集合的子接口有Set、List、Queue三种子接口。我们比较常用的是Set、List,Map接口不是collection的子接口。
Collection集合主要有List和Set两大接口:- List:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个null元素,元素都有索引。常用的实现类有ArrayList、LinkedList和Vector。
- Set:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。Set接口常用实现类是HashSet、LinkedHashSet以及TreeSet。
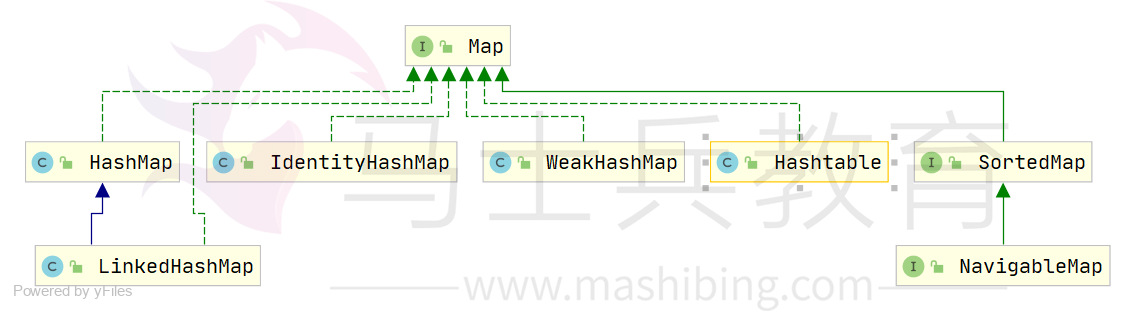
Map是一个键值对集合,存储键、值和之间的映射。Key无序,唯一;value不要求有序,允许重复。Map没有继承于Collection接口,从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
Map的常用实现类:HashMap、TreeMap、HashTable、LinkedHashMap、ConcurrentHashMap
7、集合框架底层数据结构
Collection
- List:
- Arraylist:Object数组
- Vector:Object数组
- LinkedList:双向循环链表
- Set:
- HashSet(无序、唯一):基于HashMap实现的,底层采用HashMap来保存元素
- LinkedHashSet:LinkedHashSet继承与HashSet,并且其内部是通过LinkedHashMap来实现的。有点类似于我们之前说的LinkedHashMap其内部是基于Hashmap实现一样,不过还是有一点点区别的。
- TreeSet(有序、唯一):红黑树(自平衡的排序二叉树)
Map:
- HashMap:JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间
- LinkedHashMap:LinkedHashMap继承自HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
- HashTable:数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的
- TreeMap:红黑树(自平衡的排序二叉树)
8、哪些集合类是线程安全的?
vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的。
- statck:堆栈类,先进后出。
- hashtable:就比hashmap多了个线程安全。
-
9、Java集合的快速失败机制“fail-fast”?
是Java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast机制。
例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出ConcurrentModificationException异常,从而产生fail-fast机制。
原因:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个modCount变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
解决办法:- 在遍历过程中,所有涉及到改变modCount值得地方全部加上synchronized。
- 使用CopyOnWriteArrayList来替换ArrayList
10、怎么确保一个集合不能被修改?
可以使用Collections.unmodifiableCollection(Collectionc)方法来创建一个只读集合,这样改变集合的任何操作都会抛出Java.lang.UnsupportedOperationException异常。示例代码如下:List<String> list = new ArrayList<>();list. add("x");Collection<String> clist = Collections. unmodifiableCollection(list);clist.add("y"); // 运行时此行报错System.out.println(list. size());
二、Collection接口
1、List接口
1.1 迭代器Iterator是什么?
Iterator接口提供遍历任何Collection的接口。我们可以从一个Collection中使用迭代器方法来获取迭代器实例。迭代器取代了Java集合框架中的Enumeration,迭代器允许调用者在迭代过程中移除元素。1.2 Iterator怎么使用?有什么特点?
Iterator使用代码如下:
Iterator的特点是只能单向遍历,但是更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出ConcurrentModificationException异常。List<String> list = new ArrayListIterator<String> it = list.iteratorwhile(it. hasNext()){String obj = it.next();System. out. println(obj);}
1.3 如何边遍历边移除Collection中的元素?
边遍历边修改Collection的唯一正确方式是使用Iterator.remove()方法,如下:
一种常见的错误代码如下:Iterator<Integer> it = list.iterator();while(it.hasNext()){it.remove();}
运行以上错误代码会报ConcurrentModificationException异常。这是因为当使用foreach(for(Integeri:list))语句时,会自动生成一个iterator来遍历该list,但同时该list正在被Iterator.remove()修改。Java一般不允许一个线程在遍历Collection时另一个线程修改它。for(Integer i : list){list.remove(i);}
1.4 Iterator和ListIterator有什么区别?
Iterator可以遍历Set和List集合,而ListIterator只能遍历List。
- Iterator只能单向遍历,而ListIterator可以双向遍历(向前/后遍历)。
ListIterator实现Iterator接口,然后添加了一些额外的功能,比如添加一个元素、替换一个元素、获取前面或后面元素的索引位置。
1.5 遍历一个List有哪些不同的方式?每种方法的实现原理是什么?Java中List遍历的最佳实践是什么?
遍历方式有以下几种:
for循环遍历,基于计数器。在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到后一个元素后停止。
- 迭代器遍历,Iterator。Iterator是面向对象的一个设计模式,目的是屏蔽不同数据集合的特点,统一遍历集合的接口。Java在Collections中支持了Iterator模式。
- foreach循环遍历。foreach内部也是采用了Iterator的方式实现,使用时不需要显式声明Iterator或计数器。优点是代码简洁,不易出错;缺点是只能做简单的遍历,不能在遍历过程中操作数据集合,例如删除、替换。
最佳实践:Java Collections框架中提供了一个RandomAccess接口,用来标记List实现是否支持RandomAccess。
- 如果一个数据集合实现了该接口,就意味着它支持RandomAccess,按位置读取元素的平均时间复杂度为O(1),如ArrayList。
如果没有实现该接口,表示不支持RandomAccess,如LinkedList。推荐的做法就是,支持RandomAccess的列表可用for循环遍历,否则建议用Iterator或foreach遍历。
1.6 说一下ArrayList的优缺点
ArrayList的优点如下:
- ArrayList底层以数组实现,是一种随机访问模式。ArrayList实现了RandomAccess接口,因此查找的时候非常快。
- ArrayList在顺序添加一个元素的时候非常方便。
ArrayList的缺点如下:
- 删除元素的时候,需要做一次元素复制操作。如果要复制的元素很多,那么就会比较耗费性能。
- 插入元素的时候,也需要做一次元素复制操作,缺点同上。
1.7 如何实现数组和List之间的转换?
数组转List:使用Arrays.asList(array)进行转换。
List转数组:使用List自带的toArray()方法。代码示例:
// list to arrayList<String> list = new ArrayList<String>();list.add("123");list.add("456");list.toArray();// array to listString[] array = new String[]{"123","456"};Arrays.asList(array);
1.8 ArrayList和LinkedList的区别是什么?
- 数据结构实现:
- ArrayList是动态数组的数据结构实现,
- LinkedList是双向链表的数据结构实现。
- 随机访问效率:ArrayList比LinkedList在随机访问的时候效率要高,因为LinkedList是线性的数据存储方式,所以需要移动指针从前往后依次查找。
- 增加和删除效率:在非首尾的增加和删除操作,LinkedList要比ArrayList效率要高,因为ArrayList增删操作要影响数组内的其他数据的下标。
- 内存空间占用:LinkedList比ArrayList更占内存,因为LinkedList的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
- 线程安全:ArrayList和LinkedList都是不同步的,也就是不保证线程安全;
综合来说,在需要频繁读取集合中的元素时,更推荐使用ArrayList,而在插入和删除操作较多时,更推荐使用LinkedList。
补充:数据结构基础之双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
1.9 ArrayList和Vector的区别是什么?
这两个类都实现了List接口(List接口继承了Collection接口),他们都是有序集合
- 线程安全:
- Vector 使用了 Synchronized 来实现线程同步,是线程安全的,
- 而ArrayList是非线程安全的。
- 性能:ArrayList在性能方面要优于Vector。
- 扩容:ArrayList和Vector都会根据实际的需要动态的调整容量,只不过在Vector扩容每次会增加1倍,而ArrayList只会增加50%。
- 同步:
- Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
- Arraylist不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。
1.10 插入数据时,ArrayList、LinkedList、Vector谁速度较快?阐述ArrayList、Vector、LinkedList的存储性能和特性?
ArrayList、LinkedList、Vector底层的实现都是使用数组方式存储数据。数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢。
Vector中的方法由于加了synchronized修饰,因此Vector是线程安全容器,但性能上较ArrayList差。
LinkedList使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但插入数据时只需要记录当前项的前后项即可,所以LinkedList插入速度较快。1.11 多线程场景下如何使用ArrayList?
ArrayList不是线程安全的,如果遇到多线程场景,可以通过Collections的synchronizedList方法将其转换成线程安全的容器后再使用。例如像下面这样: ```java ListsynchronizedList = Collections.synchronizedList(list); synchronizedList.add(“aaa”); synchronizedList.add(“bbb”);
for (int i = 0; i < synchronizedList.size(); i++) { System.out.println(synchronizedList.get(i)); }
<a name="kFAuz"></a>### 1.12 为什么ArrayList的elementData加上transient修饰?ArrayList中的数组定义如下:```javaprivate transient Object[] elementData;
再看一下ArrayList的定义:
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable
可以看到ArrayList实现了Serializable接口,这意味着ArrayList支持序列化。transient的作用是说不希望elementData数组被序列化,重写了writeObject实现:
每次序列化时,先调用defaultWriteObject()方法序列化ArrayList中的非transient元素,然后遍历elementData,只序列化已存入的元素,这样既加快了序列化的速度,又减小了序列化之后的文件大小。
1.13 List和Set的区别
- List、Set都是继承自Collection接口
- List特点:一个有序(元素存入集合的顺序和取出的顺序一致)容器
- 元素可以重复,可以插入多个null元素,元素都有索引。
- 常用的实现类有ArrayList、LinkedList和Vector。
- Set特点:一个无序(存入和取出顺序有可能不一致)容器
- 不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。
- Set接口常用实现类是HashSet、LinkedHashSet以及TreeSet。
- 另外List支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值。
- Set和List对比:
- Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
- List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变
2、Set接口
2.1 说一下HashSet的实现原理?
HashSet是基于HashMap实现的,HashSet的值存放于HashMap的key上,HashMap的value统一为PRESENT,因此HashSet的实现比较简单,相关HashSet的操作,基本上都是直接调用底层HashMap的相关方法来完成,HashSet不允许重复的值。2.2 HashSet如何检查重复?HashSet是如何保证数据不可重复的?
向HashSet中add()元素时,判断元素是否存在的依据,不仅要比较hash值,同时还要结合equles方法比较。
HashSet中的add()方法会使用HashMap的put()方法。
HashMap的key是唯一的,由源码可以看出HashSet添加进去的值就是作为HashMap的key,并且在HashMap中如果K/V相同时,会用新的V覆盖掉旧的V,然后返回旧的V。所以不会重复(HashMap比较key是否相等是先比较hashcode再比较equals)。
以下是HashSet部分源码: ```java private static final Object PRESENT = new Object(); private transient HashMap
public HashSet() { <> map = new HashMap(); }
public boolean add(E e) { // 调用HashMap的put方法, PRESENT是一个至始至终都相同的虚值 return map.put(e, PRESENT) == null; }
hashCode()与equals()的相关规定:1. 如果两个对象相等,则hashcode一定也是相同的1. 两个对象相等,对两个equals方法返回true1. 两个对象有相同的hashcode值,它们也不一定是相等的1. 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖1. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。==与equals的区别1. ==是判断两个变量或实例是不是指向同一个内存空间1. equals是判断两个变量或实例所指向的内存空间的值是不是相同1. ==是指对内存地址进行比较1. equals()是对字符串的内容进行比较1. ==指引用是否相同1. equals()指的是值是否相同<a name="elN9d"></a>### 2.3 HashSet与HashMap的区别| **HashMap** | **HashSet** || --- | --- || 实现了Map接口 | 实现了Set接口 || 存储键值对 | 仅存储对象 || 调用put()向map中添加元素 | 调用add()方法向Set中添加元素 || HashMap使用键 (Key)计算Hashcode | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false || HashMap相对于HashSet较快,因为它是使用唯一的键获取对象 | HashSet较HashMap来说比较慢 |<a name="cval9"></a>## 3、Queue3.1 BlockingQueue是什么?<br />Java.util.concurrent.BlockingQueue是一个队列,在进行检索或移除一个元素的时候,它会等待队列变为非空;当在添加一个元素时,它会等待队列中的可用空间。BlockingQueue接口是Java集合框架的一部分,主要用于实现生产者 - 消费者模式。我们不需要担心等待生产者有可用的空间,或消费者有可用的对象,因为它都在BlockingQueue的实现类中被处理了。Java提供了集中BlockingQueue的实现,比如ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,、SynchronousQueue等。<br />在Queue中poll()和remove()有什么区别?<br />相同点:都是返回第一个元素,并在队列中删除返回的对象。<br />不同点:如果没有元素poll()会返回null,而remove()会直接抛出NoSuchElementException异常。<br />代码示例:```javaQueue<String> queue = new LinkedList<String>();queue. offer("string"); // addSystem. out. println(queue. poll());System. out. println(queue. remove());System. out. println(queue. size());
4、Map接口
4.1 说一下HashMap的实现原理?
HashMap概述:HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap的数据结构:在Java编程语言中,基本的结构就是两种,一个是数组,另外一个是模拟指针 (引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
HashMap基于Hash算法实现的
- 当我们往Hashmap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
- 存储时,如果出现hash值相同的key,此时有两种情况。
- 如果key相同,则覆盖原始值;
- 如果key不同(出现冲突),则将当前的key-value放入链表中
- 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
- 理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
需要注意Jdk1.8中对HashMap的实现做了优化,当链表中的节点数据超过八个之后,该链表会转为红黑树来提高查询效率,从原来的O(n)到O(logn)
4.2 HashMap在JDK1.7和JDK1.8中有哪些不同?HashMap的底层实现
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,但插入和删除容易;所以我们将数组和链表结合在一起,发挥两者各自的优势,使用一种叫做拉链法的方式可以解决哈希冲突。
JDK1.8之前:
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
JDK1.8之后:
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
JDK1.7 VS JDK1.8比较
JDK1.8主要解决或优化了一下问题:
- resize扩容优化
- 引入了红黑树,目的是避免单条链表过长而影响查询效率,红黑树算法请参考
- 解决了多线程死循环问题,但仍是非线程安全的,多线程时可能会造成数据丢失问题。 | 不同点 | JDK1.7 | JDK1.8 | | —- | —- | —- | | 存储结构 | 数组+链表 | 数组+链表+红黑树 | | 初始化方式 | 单独函数:inflateTable() | 直接集成到了扩容函数resize()中 | | hash值计算方式 | 扰动处理=9次扰动=4次位运算+5次异或运算 | 扰动处理=2次扰动=1次位运算+1次异或运算 | | 存放数据的规则 | 无冲突时,存放数组;冲突时,存放链表 | 无冲突时,存放数组;冲突&链表长度<8:存放单链表;冲突&链表长度>8:树化并存放红黑树 | | 插入数据方式 | 头插法(先讲原位置的数据移到后1位,再插入数据到该位置) | 尾插法(直接插入到链表尾部/红黑树) | | 扩容后存储位置的计算方式 | 全部按照原来方法进行计算(即hashCode->>扰动函数->>(h&length-1)) | 按照扩容后的规律计算(即扩容后的位置=原位置or原位置+旧容量) |
4.3 HashMap的put方法的具体流程?
当我们put的时候,首先计算key的hash值,这里调用了hash方法,hash方法实际是让key.hashCode()与key.hashCode()>>>16进行异或操作,高16bit补0,一个数和0异或不变,所以hash函数大概的作用就是:高16bit不变,低16bit和高16bit做了一个异或,目的是减少碰撞。按照函数注释,因为bucket数组大小是2的幂,计算下标index=(table.length-1)&hash,如果不做hash处理,相当于散列生效的只有几个低bit位,为了减少散列的碰撞,设计者综合考虑了速度、作用、质量之后,使用高16bit和低16bit异或来简单处理减少碰撞,而且JDK8中用了复杂度O(logn)的树结构来提升碰撞下的性能。
putVal方法执行流程图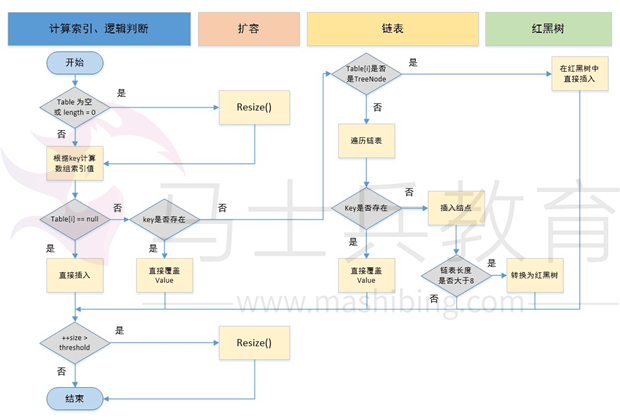
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}//实现Map.put和相关方法final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 步骤①:tab为空则创建// table未初始化或者长度为0,进行扩容if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 步骤②:计算index,并对null做处理// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);// 桶中已经存在元素else {Node<K,V> e; K k;// 步骤③:节点key存在,直接覆盖value// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))// 将第一个元素赋值给e,用e来记录e = p;// 步骤④:判断该链为红黑树// hash值不相等,即key不相等;为红黑树结点// 如果当前元素类型为TreeNode,表示为红黑树,putTreeVal返回待存放的node, e可能为nullelse if (p instanceof TreeNode)// 放入树中e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 步骤⑤:该链为链表// 为链表结点else {// 在链表最末插入结点for (int binCount = 0; ; ++binCount) {// 到达链表的尾部//判断该链表尾部指针是不是空的if ((e = p.next) == null) {// 在尾部插入新结点p.next = newNode(hash, key, value, null);//判断链表的长度是否达到转化红黑树的临界值,临界值为8if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//链表结构转树形结构treeifyBin(tab, hash);// 跳出循环break;}// 判断链表中结点的key值与插入的元素的key值是否相等if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))// 相等,跳出循环break;// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表p = e;}}//判断当前的key已经存在的情况下,再来一个相同的hash值、key值时,返回新来的value这个值if (e != null) {// 记录e的valueV oldValue = e.value;// onlyIfAbsent为false或者旧值为nullif (!onlyIfAbsent || oldValue == null)//用新值替换旧值e.value = value;// 访问后回调afterNodeAccess(e);// 返回旧值return oldValue;}}// 结构性修改++modCount;// 步骤⑥:超过最大容量就扩容// 实际大小大于阈值则扩容if (++size > threshold)resize();// 插入后回调afterNodeInsertion(evict);return null;}
① 判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
② 根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③ 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④ 这里的相同指的是hashCode以及equals;
④ 判断table[i]是否为treeNode,即table[i]是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤ 遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥ 插入成功后,判断实际存在的键值对数量size是否超多了大容量threshold,如果超过,进行扩容。
4.4 HashMap的扩容操作是怎么实现的?
① 在jdk1.8中,resize方法是在hashmap中的键值对大于阀值时或者初始化时,就调用resize方法进行扩容;
② 每次扩展的时候,都是扩展2倍;
③ 扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍的位置。在putVal()中,我们看到在这个函数里面使用到了2次resize()方法,resize()方法表示的在进行第一次初始化时会对其进行扩容,或者当该数组的实际大小大于其临界值值(第一次为12),这个时候在扩容的同时也会伴随的桶上面的元素进行重新分发,这也是JDK1.8版本的一个优化的地方,在1.7中,扩容之后需要重新去计算其Hash值,根据Hash值对其进行分发,但在1.8版本中,则是根据在同一个桶的位置中进行判断(e.hash&oldCap)是否为0,重新进行hash分配后,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;//oldTab指向hash桶数组int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {//如果oldCap不为空的话,就是hash桶数组不为空if (oldCap >= MAXIMUM_CAPACITY) {//如果大于最大容量了,就赋值为整数最大的阀值threshold = Integer.MAX_VALUE;return oldTab;//返回}//如果当前hash桶数组的长度在扩容后仍然小于最大容量 并且oldCap大于默认值16else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold 双倍扩容阀值threshold}// 旧的容量为0,但threshold大于零,代表有参构造有cap传入,threshold已经被初始化成最小2的n次幂// 直接将该值赋给新的容量else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;// 无参构造创建的map,给出默认容量和threshold 16, 16*0.75else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}// 新的threshold = 新的cap * 0.75if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;// 计算出新的数组长度后赋给当前成员变量table@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//新建hash桶数组table = newTab;//将新数组的值复制给旧的hash桶数组// 如果原先的数组没有初始化,那么resize的初始化工作到此结束,否则进入扩容元素重排逻辑,使其均匀的分散if (oldTab != null) {// 遍历新数组的所有桶下标for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {// 旧数组的桶下标赋给临时变量e,并且解除旧数组中的引用,否则就数组无法被GC回收oldTab[j] = null;// 如果e.next==null,代表桶中就一个元素,不存在链表或者红黑树if (e.next == null)// 用同样的hash映射算法把该元素加入新的数组newTab[e.hash & (newCap - 1)] = e;// 如果e是TreeNode并且e.next!=null,那么处理树中元素的重排else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);// e是链表的头并且e.next!=null,那么处理链表中元素重排else { // preserve order// loHead,loTail 代表扩容后不用变换下标,见注1Node<K,V> loHead = null, loTail = null;// hiHead,hiTail 代表扩容后变换下标,见注1Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;// 遍历链表do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)// 初始化head指向链表当前元素e,e不一定是链表的第一个元素,初始化后loHead// 代表下标保持不变的链表的头元素loHead = e;else// loTail.next指向当前eloTail.next = e;// loTail指向当前的元素e// 初始化后,loTail和loHead指向相同的内存,所以当loTail.next指向下一个元素时,// 底层数组中的元素的next引用也相应发生变化,造成lowHead.next.next.....// 跟随loTail同步,使得lowHead可以链接到所有属于该链表的元素。loTail = e;}else {if (hiTail == null)// 初始化head指向链表当前元素e, 初始化后hiHead代表下标更改的链表头元素hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);// 遍历结束, 将tail指向null,并把链表头放入新数组的相应下标,形成新的映射。if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
4.5 HashMap是怎么解决哈希冲突的?
答:在解决这个问题之前,我们首先需要知道什么是哈希冲突,而在了解哈希冲突之前我们还要知道什么是哈希才行;
什么是哈希?Hash,一般翻译为“散列”,也有直接音译为“哈希”的,这就是把任意长度的输入通过散列算法,变换成固定长度的输出,该输出就是散列值(哈希值);这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
所有散列函数都有如下一个基本特性:根据同一散列函数计算出的散列值如果不同,那么输入值肯定也不同。但是,根据同一散列函数计算出的散列值如果相同,输入值不一定相同。
什么是哈希冲突?
当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,我们就把它叫做碰撞(哈希碰撞)。
HashMap的数据结构
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,但插入和删除容易;所以我们将数组和链表结合在一起,发挥两者各自的优势,使用一种叫做链地址法的方式可以解决哈希冲突: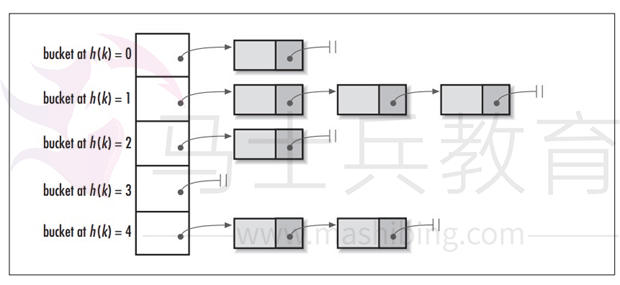
这样我们就可以将拥有相同哈希值的对象(img)组织成一个链表放在hash值所对应的bucket下,但相比于hashCode返回的int类型,我们HashMap初始的容量大小DEFAULT_INITIAL_CAPACITY=1<<4(即2的四次方16)要远小于int类型的范围,所以我们如果只是单纯的用hashCode取余来获取对应的bucket这将会大大增加哈希碰撞的概率,并且最坏情况下还会将HashMap变成一个单链表,所以我们还需要对hashCode作一定的优化hash()函数
上面提到的问题,主要是因为如果使用hashCode取余,那么相当于参与运算的只有hashCode的低位,高位是没有起到任何作用的,所以我们的思路就是让hashCode取值出的高位也参与运算,进一步降低hash碰撞的概率,使得数据分布更平均,我们把这样的操作称为扰动,在JDK1.8中的hash()函数如下:
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);// 与自己右移16位 进行异或运算(高低位异或)}
这比在JDK1.7中,更为简洁,相比在1.7中的4次位运算,5次异或运算(9次扰动),在1.8中,只进行了1次位运算和1次异或运算(2次扰动);
JDK1.8新增红黑树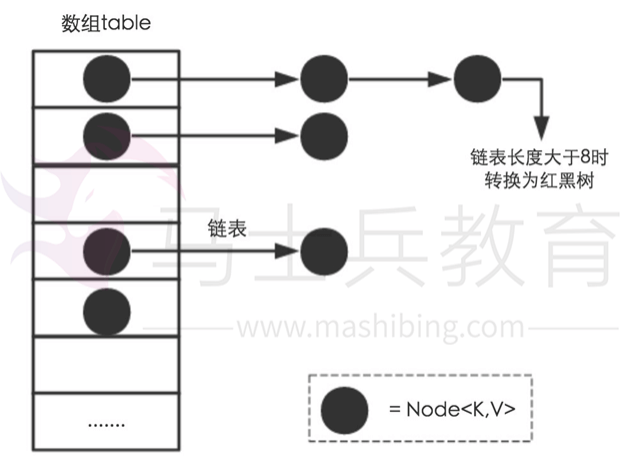
通过上面的链地址法(使用散列表)和扰(img)动函数我们成功让我们的数据分布更平均,哈希碰撞减少,但是当我们的HashMap中存在大量数据时,加入我们某个bucket下对应的链表有n个元素,那么遍历时间复杂度就为O(n),为了针对这个问题,JDK1.8在HashMap中新增了红黑树的数据结构,进一步使得遍历复杂度降低至O(logn);
简单总结一下HashMap是使用了哪些方法来有效解决哈希冲突的:
- 使用链地址法(使用散列表)来链接拥有相同hash值的数据;
- 使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均;
-
4.6 能否使用任何类作为Map的key?
可以使用任何类作为Map的key,然而在使用之前,需要考虑以下几点:如果类重写了equals()方法,也应该重写hashCode()方法。类的所有实例需要遵循与equals()和hashCode()相关的规则。
如果一个类没有使用equals(),不应该在hashCode()中使用它。
用户自定义Key类佳实践是使之为不可变的,这样hashCode()值可以被缓存起来,拥有更好的性能。不可变的类也可以确保hashCode()和equals()在未来不会改变,这样就会解决与可变相关的问题了。4.7 为什么HashMap中String、Integer这样的包装类适合作为K?
答:String、Integer等包装类的特性能够保证Hash值的不可更改性和计算准确性,能够有效的减少Hash碰撞的几率
都是final类型,即不可变性,保证key的不可更改性,不会存在获取hash值不同的情况
内部已重写了equals()、hashCode()等方法,遵守了HashMap内部的规范(不清楚可以去上面看看putValue的过程),不容易出现Hash值计算错误的情况4.8 如果使用Object作为HashMap的Key,应该怎么办呢?
答:重写hashCode()和equals()方法
重写hashCode()是因为需要计算存储数据的存储位置,需要注意不要试图从散列码计算中排除掉一个对象的关键部分来提高性能,这样虽然能更快但可能会导致更多的Hash碰撞;
重写equals()方法,需要遵守自反性、对称性、传递性、一致性以及对于任何非null的引用值x,x.equals(null)必须返回false的这几个特性,目的是为了保证key在哈希表中的唯一性
4.9 HashMap为什么不直接使用hashCode()处理后的哈希值直接作为table的下标?
答:hashCode()方法返回的是int整数类型,其范围为-(2^31)~(2^31-1),约有40亿个映射空间,而HashMap的容量范围是在16(初始化默认值)~2^30,HashMap通常情况下是取不到大值的,并且设备上也难以提供这么多的存储空间,从而导致通过hashCode()计算出的哈希值可能不在数组大小范围内,进而无法匹配存储位置;
那怎么解决呢?HashMap自己实现了自己的hash()方法,通过两次扰动使得它自己的哈希值高低位自行进行异或运算,降低哈希碰撞概率也使得数据分布更平均;
在保证数组长度为2的幂次方的时候,使用hash()运算之后的值与运算(&)(数组长度-1)来获取数组下标的方式进行存储,这样一来是比取余操作更加有效率,二来也是因为只有当数组长度为2的幂次方时,h&(length-1)才等价于h%length,三来解决了“哈希值与数组大小范围不匹配”的问题
4.10 HashMap的长度为什么是2的幂次方
为了能让HashMap存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀,每个链表/红黑树长度大致相同。这个实现就是把数据存到哪个链表/红黑树中的算法。
这个算法应该如何设计呢?我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说hash%length==hash&(length-1)的前提是length是2的n次方;)。”并且采用二进制位操作&,相对于%能够提高运算效率,这就解释HashMap的长度为什么是2的幂次方。
那为什么是两次扰动呢?答:这样就是加大哈希值低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性&均匀性,终减少Hash冲突,两次就够了,已经达到了高位低位同时参与运算的目的4.11 HashMap与HashTable有什么区别?
线程安全:HashMap是非线程安全的,HashTable是线程安全的;HashTable内部的方法基本都经过synchronized修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap吧!);
- 效率:因为线程安全的问题,HashMap要比HashTable效率高一点。另外,HashTable基本被淘汰,不要在代码中使用它;
- 对Null key和Null value的支持:HashMap中,null可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为null。但是在HashTable中put进的键值只要有一个null,直接抛NullPointerException。
- 初始容量大小和每次扩充容量大小的不同:
- 创建时如果不指定容量初始值,Hashtable默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。
- 创建时如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充为2的幂次方大小。也就是说HashMap总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
- 底层数据结构:JDK1.8以后的HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable没有这样的机制。
- 推荐使用:在Hashtable的类注释可以看到,Hashtable是保留类不建议使用,推荐在单线程环境下使用HashMap替代,如果需要多线程使用则用ConcurrentHashMap替代。
4.12 如何决定使用HashMap还是TreeMap?
对于在Map中插入、删除和定位元素这类操作,HashMap是好的选择。然而,假如你需要对一个有序的key集合进行遍历,TreeMap是更好的选择。基于你的collection的大小,也许向HashMap中添加元素会更快,将map换为TreeMap进行有序key的遍历
HashMap和ConcurrentHashMap的区别
- ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的synchronized锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。(JDK1.8之后ConcurrentHashMap启了一种全新的方式实现,利用CAS算法。)
- HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
ConcurrentHashMap和Hashtable的区别?
ConcurrentHashMap和Hashtable的区别主要体现在实现线程安全的方式上不同。底层数据结构:JDK1.7的ConcurrentHashMap底层采用分段的数组+链表实现,JDK1.8采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable和JDK1.8之前的HashMap的底层数据结构类似都是采用数组+链表的形式,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的;
实现线程安全的方式(重要):
① 在JDK1.7的时候,ConcurrentHashMap(分段锁)对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。)到了JDK1.8的时候已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized和CAS来操作。(JDK1.6以后对synchronized锁做了很多优化)整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本;
②Hashtable(同一把锁):使用synchronized来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用put添加元素,另一个线程不能使用put添加元素,也不能使用get,竞争会越来越激烈效率越低。
两者的对比图:
HashTable: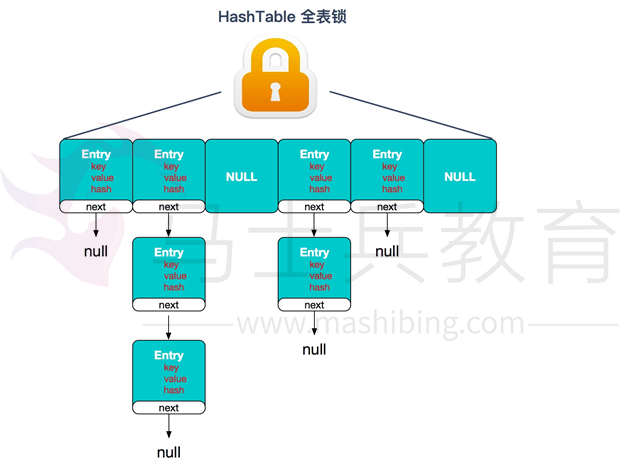
JDK1.7的ConcurrentHashMap: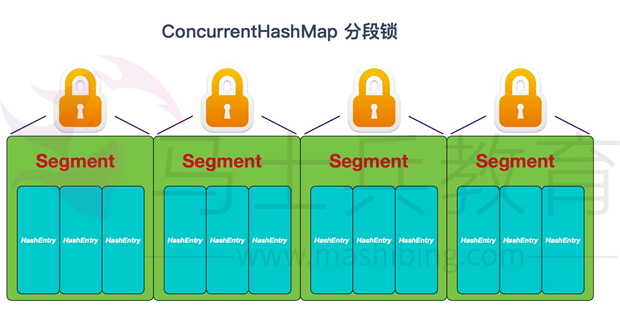
JDK1.8的ConcurrentHashMap(TreeBi(img)n:红黑二叉树节点Node:链表节点):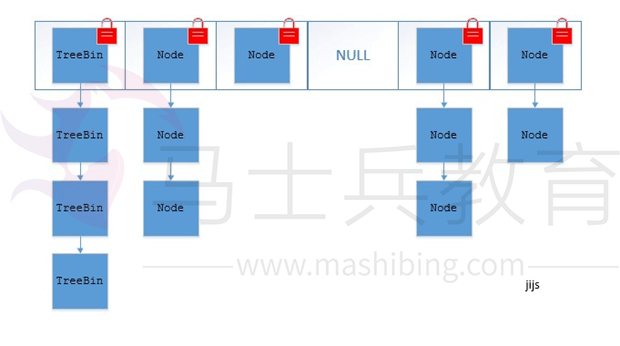
答:ConcurrentHashMap结合了Hash(img)Map和HashTable二者的优势。HashMap没有考虑同步,HashTable考虑了同步的问题。但是HashTable在每次同步执行时都要锁住整个结构。ConcurrentHashMap锁的方式是稍微细粒度的。
4.13 ConcurrentHashMap底层具体实现知道吗?实现原理是什么?
JDK1.7:
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
在JDK1.7中,ConcurrentHashMap采用Segment+HashEntry的方式进行实现,结构如下:一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashMap类似,是一种数组和链表结构,一个Segment包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得对应的Segment的锁。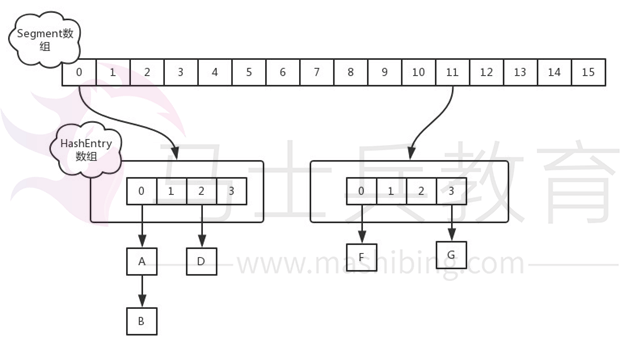
- 该类包含两个静态内部类HashE(img)ntry和Segment;前者用来封装映射表的键值对,后者用来充当锁的角色;
- Segment是一种可重入的锁ReentrantLock,每个Segment守护一个HashEntry数组里得元素,当对HashEntry数组的数据进行修改时,必须首先获得对应的Segment锁。
JDK1.8:
在JDK1.8中,放弃了Segment臃肿的设计,取而代之的是采用Node+CAS+Synchronized来保证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
结构如下: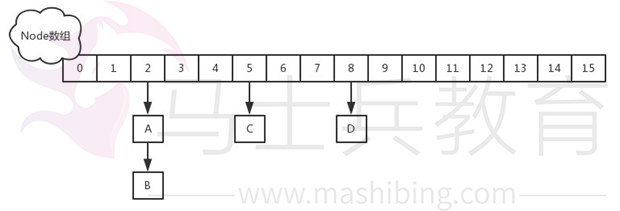
看插入元素过程(建议去看看源码):
如果相应位置的Node还没有初始化,则调用CAS插入相应的数据;
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}
如果相应位置的Node不为空,且当前该节点不处于移动状态,则对该节点加synchronized锁,如果该节点的hash不小于0,则遍历链表更新节点或插入新节点;
1、如果该节点是TreeBin类型的节点,说明是红黑树结构,则通过putTreeVal方法往红黑树中插入节点;如果binCount不为0,说明put操作对数据产生了影响,如果当前链表的个数达到8个,则通过
treeifyBin方法转化为红黑树,如果oldVal不为空,说明是一次更新操作,没有对元素个数产生影响,则直接返回旧值;
2、如果插入的是一个新节点,则执行addCount()方法尝试更新元素个数baseCount;
5、辅助工具类
Array和ArrayList有何区别?
Array可以存储基本数据类型和对象,ArrayList只能存储对象。
Array是指定固定大小的,而ArrayList大小是自动扩展的。
Array内置方法没有ArrayList多,比如addAll、removeAll、iteration等方法只有ArrayList有。
对于基本类型数据,集合使用自动装箱来减少编码工作量。但是,当处理固定大小的基本数据类型的时候,这种方式相对比较慢。
如何实现Array和List之间的转换?
Array转List:Arrays.asList(array);
List转Array:List的toArray()方法。
comparable和comparator的区别?
comparable接口实际上是出自Java.lang包,它有一个compareTo(Objectobj)方法用来排序comparator接口实际上是出自Java.util包,它有一个compare(Objectobj1,Objectobj2)方法用来排序
一般我们需要对一个集合使用自定义排序时,我们就要重写compareTo方法或compare方法,当我们需要对某一个集合实现两种排序方式,比如一个song对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo方法和使用自制的Comparator方法或者以两个Comparator来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的Collections.sort().
<br />
Collection和Collections有什么区别?
Java.util.Collection是一个集合接口(集合类的一个顶级接口)。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java类库中有很多具体的实现。Collection接口的意义是为
各种具体的集合提供了大化的统一操作方式,其直接继承接口有List与Set。
Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进
行排序、搜索以及线程安全等各种操作。
TreeMap和TreeSet在排序时如何比较元素?Collections工具类中的sort()方
法如何比较元素?
TreeSet要求存放的对象所属的类必须实现Comparable接口,该接口提供了比较元素的compareTo()方法,当插入元素时会回调该方法比较元素的大小。
TreeMap要求存放的键值对映射的键必须实现Comparable接口从而根据键对元素进行排序。Collections工具类的sort方法有两种重载的形式,
第一种要求传入的待排序容器中存放的对象比较实现Comparable接口以实现元素的比较;
第二种不强制性的要求容器中的元素必须可比较,但是要求传入第二个参数,参数是Comparator接口的子类型(需要重写compare方法实现元素的比较),相当于一个临时定义的排序规则,其实就是通过接口注入比较元素大小的算法,也是对回调模式的应用(Java中对函数式编程的支持)。
Vector,ArrayList,LinkedList的区别是什么?
答:
1.Vector、ArrayList都是以类似数组的形式存储在内存中,LinkedList则以链表的形式进行存储。
2.List中的元素有序、允许有重复的元素,Set中的元素无序、不允许有重复元素。
3.Vector线程同步,ArrayList、LinkedList线程不同步。
4.LinkedList适合指定位置插入、删除操作,不适合查找;ArrayList、Vector适合查找,不适合指定位置的插入、删除操作。
5.ArrayList在元素填满容器时会自动扩充容器大小的50%,而Vector则是100%,因此ArrayList更节省空间。
HashTable,HashMap,TreeMap区别?
答:
1.HashTable线程同步,HashMap非线程同步。
2.HashTable不允许<键,值>有空值,HashMap允许<键,值>有空值。
3.HashTable使用Enumeration,HashMap使用Iterator。
4.HashTable中hash数组的默认大小是11,增加方式的old*2+1,HashMap中hash数组的默认大小是16,增长方式一定是2的指数倍。
5.TreeMap能够把它保存的记录根据键排序,默认是按升序排序。
HashMap的数据结构
jdk1.8之前list+链表
jdk1.8之后list+链表(当链表长度到8时,转化为红黑树)
HashMap的扩容因子
默认0.75,也就是会浪费1/4的空间,达到扩容因子时,会将list扩容一倍,0.75是时间与空间一个平衡值;
多线程修改HashMap
多线程同时写入,同时执行扩容操作,多线程扩容可能死锁、丢数据;可以对HashMap加入同步锁Collections.synchronizedMap(hashMap),但是效率很低,因为该锁是互斥锁,同一时刻只能有一个线程执行读写操作,这时候应该使用ConcurrentHashMap
注意:在使用Iterator遍历的时候,LinkedHashMap会产生
Java.util.ConcurrentModificationException。
扩展HashMap增加双向链表的实现,号称是最占内存的数据结构。支持iterator()时按Entry的插入顺序来排序(但是更新不算,如果设置accessOrder属性为true,则所有读写访问都算)。实现上是在Entry上再增加属性before/after指针,插入时把自己加到HeaderEntry的前面去。如果所有读写访问都要排序,还要把前后Entry的before/after拼接起来以在链表中删除掉自己。
说说你知道的几个Java集合类:list、set、queue、map
实现类
Java中的队列都有哪些,有什么区别
1.ArrayDeque,(数组双端队列)
2.PriorityQueue,(优先级队列)
3.ConcurrentLinkedQueue,(基于链表的并发队列)
4.DelayQueue,(延期阻塞队列)(阻塞队列实现了BlockingQueue接口)
5.ArrayBlockingQueue,(基于数组的并发阻塞队列)
6.LinkedBlockingQueue,(基于链表的FIFO阻塞队列)
7.LinkedBlockingDeque,(基于链表的FIFO双端阻塞队列)
8.PriorityBlockingQueue,(带优先级的无界阻塞队列)
9.SynchronousQueue(并发同步阻塞队列)
反射中,Class.forName和classloader的区别
Java中class.forName()和classLoader都可用来对类进行加载。
class.forName()前者除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。
而classLoader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
Class.forName(name,initialize,loader)带参函数也可控制是否加载static块。并且只有调用了newInstance()方法采用调用构造函数,创建类的对象
看下Class.forName()源码
//Class.forName(StringclassName)这是1.8的源码
publicstaticClass<?>forName(StringclassName)throws
ClassNotFoundException{
Class<?>caller=Reflection.getCallerClass();
returnforName0(className,true,ClassLoader.getClassLoader(caller),caller);
}
//注意第二个参数,是指Class被loading后是不是必须被初始化。不初始化就是不执行static的代
码即静态代码
然后就是,测试代码证明上面的结论是OK的,如下:
packagecom.lxk.Reflect;
/*
Createdbylxkon2017/2/21
*/
publicclassLine{
static{
System.out.println(“静态代码块执行:loadingline”);
}
}
packagecom.lxk.Reflect;
/*
Createdbylxkon2017/2/21
*/
publicclassPoint{
static{
System.out.println(“静态代码块执行:loadingpoint”);
}
}
执行结果如下:
备注:
根据运行结果,可以看到,classloader并没有执行静态代码块,如开头的理论所说。
而下面的Class.forName则是夹在完之后,就里面执行了静态代码块,可以看到,2个类,line和point的静态代码块执行结果是一起的,然后才是各自的打印结果。
也说明上面理论是OK的。
更新于2017/06/20
因为看到有小伙伴有疑问,我就把自己以前的代码拿出来再次测试一遍,发现结果仍然是相同的。但是,因为我的Javabeanmodel又经历了其他的测试,所以,两个model内部的代码稍有变化,然后,还真就测试出来了不一样的地方。
这估计是其他理论所没有的。具体看下面的代码吧。
只是修改了Line的代码,添加了几个静态的方法和变量。
可以看到,除了原来的简单的一个静态代码块以外,我又添加了构造方法,静态方法,以及静态变量,且,静态变量被一个静态方法赋值。
然后,看执行结果。
稍有不同。
除了,静态代码块的执行外,竟然还有一个静态方法被执行,就是给静态变量赋值的静态方法被执行了。
这个估计是以前没人发现的吧。
所以
上面的结论,就可以进一步的修改啦。
也许,这个执行的也叫,static块呢。
JavaIO流详解(二)——IO流的框架体系
一、IO流的概念
Java的IO流是实现输入/输出的基础,它可以方便地实现数据的输入/输出操作,在Java中把不同的输入/输出源抽象表述为”流”。流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
流有输入和输出,输入时是流从数据源流向程序。输出时是流从程序传向数据源,而数据源可以是内存,文件,网络或程序等。
二、IO流的分类
1.输入流和输出流
根据数据流向不同分为:输入流和输出流。
输入流:只能从中读取数据,而不能向其写入数据。
如下如所示:对程序而言,向右的箭头,表示输入,向左的箭头,表示输出。
<br /><br />
2.字节流和字符流
字节流和字符流和用法几乎完全一样,区别在于字节流和字符流所操作的数据单元不同。
字符流的由来:因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。字节流和字符流的区别:
(1)读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
(2)处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。<br />只要是处理纯文本数据,就优先考虑使用字符流。除此之外都使用字节流。<br />3.节点流和处理流<br />按照流的角色来分,可以分为节点流和处理流。<br />可以从/向一个特定的IO设备(如磁盘、网络)读/写数据的流,称为节点流,节点流也被成为低级流。<br />处理流是对一个已存在的流进行连接或封装,通过封装后的流来实现数据读/写功能,处理流也被称为<br />高级流。
//节点流,直接传入的参数是IO设备
FileInputStreamfis=newFileInputStream(“test.txt”);
//处理流,直接传入的参数是流对象
BufferedInputStreambis=newBufferedInputStream(fis);
当使用处理流进行输入/输出时,程序并不会直接连接到实际的数据源,没有和实际的输入/输出节点连接。使用处理流的一个明显好处是,只要使用相同的处理流,程序就可以采用完全相同的输入/输出代码来访问不同的数据源,随着处理流所包装节点流的变化,程序实际所访问的数据源也相应地发生变化。
实际上,Java使用处理流来包装节点流是一种典型的装饰器设计模式,通过使用处理流来包装不同的节点流,既可以消除不同节点流的实现差异,也可以提供更方便的方法来完成输入/输出功能。
三、IO流的四大基类
根据流的流向以及操作的数据单元不同,将流分为了四种类型,每种类型对应一种抽象基类。这四种抽象基类分别为:InputStream,Reader,OutputStream以及Writer。四种基类下,对应不同的实现类,具有不同的特性。在这些实现类中,又可以分为节点流和处理流。下面就是整个由着四大基类支撑下,整个IO流的框架图。
InputStream,Reader,OutputStream以及Writer,这四大抽象基类,本身并不能创建实例来执行输入/输出,但它们将成为所有输入/输出流的模版,所以它们的方法是所有输入/输出流都可以使用的方法。类似于集合中的Collection接口。
1.InputStream
InputStream是所有的输入字节流的父类,它是一个抽象类,主要包含三个方法:
//读取一个字节并以整数的形式返回(0~255),如果返回-1已到输入流的末尾。
intread();
//读取一系列字节并存储到一个数组buffer,返回实际读取的字节数,如果读取前已到输入流的末尾返回-1。
intread(byte[]buffer);
//读取length个字节并存储到一个字节数组buffer,从off位置开始存,最多len,返回实际读取的字节
数,如果读取前以到输入流的末尾返回-1。
intread(byte[]buffer,intoff,intlen);
2.Reader
Reader是所有的输入字符流的父类,它是一个抽象类,主要包含三个方法:
//读取一个字符并以整数的形式返回(0~255),如果返回-1已到输入流的末尾。
intread();
//读取一系列字符并存储到一个数组buffer,返回实际读取的字符数,如果读取前已到输入流的末尾返回-1。
intread(char[]cbuf);
//读取length个字符,并存储到一个数组buffer,从off位置开始存,最多读取len,返回实际读取的字符数,如果读取前以到输入流的末尾返回-1。
intread(char[]cbuf,intoff,intlen)
对比InputStream和Reader所提供的方法,就不难发现两个基类的功能基本一样的,只不过读取的数据单元不同。
在执行完流操作后,要调用close()方法来关系输入流,因为程序里打开的IO资源不属于内存资源,垃圾回收机制无法回收该资源,所以应该显式关闭文件IO资源。
除此之外,InputStream和Reader还支持如下方法来移动流中的指针位置:
//在此输入流中标记当前的位置
//readlimit-在标记位置失效前可以读取字节的最大限制。
voidmark(intreadlimit)
//测试此输入流是否支持mark方法
booleanmarkSupported()
//跳过和丢弃此输入流中数据的n个字节/字符
longskip(longn)
//将此流重新定位到最后一次对此输入流调用mark方法时的位置
voidreset()
3.OutputStream
OutputStream是所有的输出字节流的父类,它是一个抽象类,主要包含如下四个方法:
//向输出流中写入一个字节数据,该字节数据为参数b的低8位。
voidwrite(intb);
//将一个字节类型的数组中的数据写入输出流。
voidwrite(byte[]b);
//将一个字节类型的数组中的从指定位置(off)开始的,len个字节写入到输出流。
voidwrite(byte[]b,intoff,intlen);
//将输出流中缓冲的数据全部写出到目的地。
voidflush();
4.Writer
Writer是所有的输出字符流的父类,它是一个抽象类,主要包含如下六个方法:
//向输出流中写入一个字符数据,该字节数据为参数b的低16位。
voidwrite(intc);
//将一个字符类型的数组中的数据写入输出流,
voidwrite(char[]cbuf)
//将一个字符类型的数组中的从指定位置(offset)开始的,length个字符写入到输出流。
voidwrite(char[]cbuf,intoffset,intlength);
//将一个字符串中的字符写入到输出流。
voidwrite(StringString);
//将一个字符串从offset开始的length个字符写入到输出流。
voidwrite(StringString,intoffset,intlength);
//将输出流中缓冲的数据全部写出到目的地。
voidflush()
可以看出,Writer比OutputStream多出两个方法,主要是支持写入字符和字符串类型的数据。
使用Java的IO流执行输出时,不要忘记关闭输出流,关闭输出流除了可以保证流的物理资源被回收之外,还能将输出流缓冲区的数据flush到物理节点里(因为在执行close()方法之前,自动执行输出流的flush()方法)
以上内容就是整个IO流的框架介绍。
讲讲NIO
NIO技术概览
NIO(Non-blockingI/O,在Java领域,也称为NewI/O),是一种同步非阻塞的I/O模型,也是I/O多路复用的基础,已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O处理问题的有效方式。
IO模型的分类
按照《Unix网络编程》的划分,I/O模型可以分为:阻塞I/O模型、非阻塞I/O模型、I/O复用模型、信号驱动式I/O模型和异步I/O模型,按照POSIX标准来划分只分为两类:同步I/O和异步I/O。
如何区分呢?首先一个I/O操作其实分成了两个步骤:发起IO请求和实际的IO操作。同步I/O和异步I/O的区别就在于第二个步骤是否阻塞,如果实际的I/O读写阻塞请求进程,那么就是同步I/O,因此阻塞I/O、非阻塞I/O、I/O复用、信号驱动I/O都是同步I/O,如果不阻塞,而是操作系统帮你做完I/O操作再将结果返回给你,那么就是异步I/O。
阻塞I/O和非阻塞I/O的区别在于第一步,发起I/O请求是否会被阻塞,如果阻塞直到完成那么就是传统的阻塞I/O,如果不阻塞,那么就是非阻塞I/O。
阻塞I/O模型:在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
非阻塞I/O模型:linux下,可以通过设置socket使其变为non-blocking。当对一个non-blockingsocket执行读操作时,流程是这个样子:
I/O复用模型:我们可以调用select或poll,阻塞在这两个系统调用中的某一个之上,而不是真正的IO系统调用上:
信号驱动式I/O模型:我们可以用信号,让内核在描述符就绪时发送SIGIO信号通知我们:
异步I/O模型:用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从内核
的角度,当它受到一个asynchronousread之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,内核会给用户进程发送一个signal,告诉它read操作完成了:
以上参考自:《UNIX网络编程》
从前面I/O模型的分类中,我们可以看出AIO的动机。阻塞模型需要在I/O操作开始时阻塞应用程序。这意味着不可能同时重叠进行处理和I/O操作。非阻塞模型允许处理和I/O操作重叠进行,但是这需要应用程序来检查I/O操作的状态。对于异步I/O,它允许处理和I/O操作重叠进行,包括I/O操作完成的通知。除了需要阻塞之外,select函数所提供的功能(异步阻塞I/O)与AIO类似。不过,它是对通知事件进行阻塞,而不是对I/O调用进行阻塞。
参考下知乎上的回答:
同步与异步:同步和异步关注的是消息通信机制(synchronouscommunication/
asynchronouscommunication)。所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动
等待这个调用的结果;
阻塞与非阻塞:阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态。阻
塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回;而非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
两种IO多路复用方案:Reactor和Proactor
一般地,I/O多路复用机制都依赖于一个事件多路分离器(EventDemultiplexer)。分离器对象可将来自事件源的I/O事件分离出来,并分发到对应的read/write事件处理器(EventHandler)。开发人员预先注册需要处理的事件及其事件处理器(或回调函数);事件分离器负责将请求事件传递给事件处理器。
两个与事件分离器有关的模式是Reactor和Proactor。Reactor模式采用同步I/O,而Proactor采用异步I/O。在Reactor中,事件分离器负责等待文件描述符或socket为读写操作准备就绪,然后将就绪事件传递给对应的处理器,最后由处理器负责完成实际的读写工作。
而在Proactor模式中,处理器或者兼任处理器的事件分离器,只负责发起异步读写操作。I/O操作本身由操作系统来完成。传递给操作系统的参数需要包括用户定义的数据缓冲区地址和数据大小,操作系统才能从中得到写出操作所需数据,或写入从socket读到的数据。事件分离器捕获I/O操作完成事件,然后将事件传递给对应处理器。比如,在windows上,处理器发起一个异步I/O操作,再由事件分离器等待
IOCompletion事件。典型的异步模式实现,都建立在操作系统支持异步API的基础之上,我们将这种实现称为“系统级”异步或“真”异步,因为应用程序完全依赖操作系统执行真正的I/O工作。
举个例子,将有助于理解Reactor与Proactor二者的差异,以读操作为例(写操作类似)。在Reactor中实现读:
注册读就绪事件和相应的事件处理器;
事件分离器等待事件;
事件到来,激活分离器,分离器调用事件对应的处理器;
事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
在Proactor中实现读:
处理器发起异步读操作(注意:操作系统必须支持异步I/O)。在这种情况下,处理器无视I/O就绪事件,它关注的是完成事件;
事件分离器等待操作完成事件;
在分离器等待过程中,操作系统利用并行的内核线程执行实际的读操作,并将结果数据存入用户自定义缓冲区,最后通知事件分离器读操作完成;
事件分离器呼唤处理器;
事件处理器处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分离器。
可以看出,两个模式的相同点,都是对某个I/O事件的事件通知(即告诉某个模块,这个I/O操作可以进行或已经完成)。在结构上,两者的相同点和不同点如下:
相同点:demultiplexor负责提交I/O操作(异步)、查询设备是否可操作(同步),然后当条件满
足时,就回调handler;
不同点:异步情况下(Proactor),当回调handler时,表示I/O操作已经完成;同步情况下 (Reactor),回调handler时,表示I/O设备可以进行某个操作(canreadorcanwrite)。
传统BIO模型
BIO是同步阻塞式IO,通常在while循环中服务端会调用accept方法等待接收客户端的连接请求,一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成。
如果BIO要能够同时处理多个客户端请求,就必须使用多线程,即每次accept阻塞等待来自客户端请求,一旦受到连接请求就建立通信套接字同时开启一个新的线程来处理这个套接字的数据读写请求,然后立刻又继续accept等待其他客户端连接请求,即为每一个客户端连接请求都创建一个线程来单独处理。
我们看下传统的BIO方式下的编程模型大致如下:
publicstaticvoidmain(String[]args)throwsIOException{
ExecutorServiceexecutor=Executors.newFixedThreadPool(128);
ServerSocketserverSocket=newServerSocket();
serverSocket.bind(newInetSocketAddress(1234));
//循环等待新连接
while(true){
Socketsocket=serverSocket.accept();
//为新的连接创建线程执行任务
executor.submit(newConnectionTask(socket));
}
}
}
classConnectionTaskextendsThread{
privateSocketsocket;
publicConnectionTask(Socketsocket){
this.socket=socket;
}
publicvoidrun(){
while(true){
InputStreaminputStream=null;
OutputStreamoutputStream=null;
try{
inputStream=socket.getInputStream();
//readfromsocket…
inputStream.read();
outputStream=socket.getOutputStream();
//writetosocket…
outputStream.write();
}catch(IOExceptione){
e.printStackTrace();
}finally{
//关闭资源…
}
}
}
}
这里之所以使用多线程,是因为socket.accept()、inputStream.read()、outputStream.write()都是同步阻塞的,当一个连接在处理I/O的时候,系统是阻塞的,如果是单线程的话在阻塞的期间不能接受任何请求。所以,使用多线程,就可以让CPU去处理更多的事情。其实这也是所有使用多线程的本质:
利用多核。
当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。
使用线程池能够让线程的创建和回收成本相对较低。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的I/O并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池可以缓冲一些过多的连接或请求。
但这个模型最本质的问题在于,严重依赖于线程。但线程是很”贵”的资源,主要表现在:
1.线程的创建和销毁成本很高,在Linux这样的操作系统中,线程本质上就是一个进程。创建和销毁都是重量级的系统函数;
2.线程本身占用较大内存,像Java的线程栈,一般至少分配512K~1M的空间,如果系统中的线程数过千,恐怕整个JVM的内存都会被吃掉一半;
3.线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统load偏高、CPUsy使用率特别高(超过20%以上),导致系统几乎陷入不可用的状态;
4.容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
所以,当面对十万甚至百万级连接的时候,传统的BIO模型是无能为力的。随着移动端应用的兴起和各种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的I/O处理模型。
NIO的实现原理
NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题,即在使用同步I/O的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。
NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知应用程序进行处理,应用再将流读取到缓冲区或写入操作系统。
也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,
当连接没有数据时,是没有工作线程来处理的。
下面看下代码的实现:
NIO服务端代码(新建连接):
//获取一个ServerSocket通道
ServerSocketChannelserverChannel=ServerSocketChannel.open();
serverChannel.configureBlocking(false);
serverChannel.socket().bind(newInetSocketAddress(port));
//获取通道管理器
selector=Selector.open();
//将通道管理器与通道绑定,并为该通道注册SelectionKey.OP_ACCEPT事件,
serverChannel.register(selector,SelectionKey.OP_ACCEPT);
NIO服务端代码(监听):
NIO模型示例如下:
Acceptor注册Selector,监听accept事件;
当客户端连接后,触发accept事件;
服务器构建对应的Channel,并在其上注册Selector,监听读写事件;
当发生读写事件后,进行相应的读写处理。
Reactor模型
有关Reactor模型结构,可以参考DougLea在ScalableIOinJava中的介绍。这里简单介绍一下Reactor模式的典型实现:
Reactor单线程模型
这是最简单的单Reactor单线程模型。Reactor线程负责多路分离套接字、accept新连接,并分派请求到处理器链中。该模型适用于处理器链中业务处理组件能快速完成的场景。不过,这种单线程模型不能充分利用多核资源,所以实际使用的不多。
这个模型和上面的NIO流程很类似,只是将消息相关处理独立到了Handler中去了。
代码实现如下:
publicclassReactorimplementsRunnable{
finalSelectorselector;
finalServerSocketChannelserverSocketChannel;
publicstaticvoidmain(String[]args)throwsIOException{
newThread(newReactor(1234)).start();
}
publicReactor(intport)throwsIOException{
selector=Selector.open();
serverSocketChannel=ServerSocketChannel.open();serverSocketChannel.socket().bind(newInetSocketAddress(port));serverSocketChannel.configureBlocking(false);
SelectionKeykey=serverSocketChannel.register(selector,
SelectionKey.OP_ACCEPT);
key.attach(newAcceptor());
}
@Override
publicvoidrun(){
while(!Thread.interrupted()){
try{
selector.select();
Set
dispatch(selectionKey);
}
selectionKeys.clear();
}catch(IOExceptione){
e.printStackTrace();
}
}
}
privatevoiddispatch(SelectionKeyselectionKey){
Runnablerun=(Runnable)selectionKey.attachment();
if(run!=null){
run.run();
}
}
classAcceptorimplementsRunnable{
@Override
publicvoidrun(){
try{
SocketChannelchannel=serverSocketChannel.accept();if(channel!=null){
newHandler(selector,channel);
}
}catch(IOExceptione){
e.printStackTrace();
}
}
}
}
classHandlerimplementsRunnable{
privatefinalstaticintDEFAULT_SIZE=1024;
privatefinalSocketChannelsocketChannel;
privatefinalSelectionKeyseletionKey;
privatestaticfinalintREADING=0;
privatestaticfinalintSENDING=1;
privateintstate=READING;
ByteBufferinputBuffer=ByteBuffer.allocate(DEFAULT_SIZE);
ByteBufferoutputBuffer=ByteBuffer.allocate(DEFAULT_SIZE);
publicHandler(Selectorselector,SocketChannelchannel)throwsIOException{
this.socketChannel=channel;
socketChannel.configureBlocking(false);
this.seletionKey=socketChannel.register(selector,0);
seletionKey.attach(this);
seletionKey.interestOps(SelectionKey.OP_READ);
selector.wakeup();
}
@Override
publicvoidrun(){
if(state==READING){
read();
}elseif(state==SENDING){
write();
}
}
classSenderimplementsRunnable{
@Override
publicvoidrun(){
try{
socketChannel.write(outputBuffer);
}catch(IOExceptione){
e.printStackTrace();
}
if(outIsComplete()){
seletionKey.cancel();
}
}
}
privatevoidwrite(){
try{
socketChannel.write(outputBuffer);
}catch(IOExceptione){
e.printStackTrace();
}
while(outIsComplete()){
seletionKey.cancel();
}
}
privatevoidread(){
try{
socketChannel.read(inputBuffer);
if(inputIsComplete()){
process();
System.out.println(“接收到来自客户端(“+
socketChannel.socket().getInetAddress().getHostAddress()
+”)的消息:”+newString(inputBuffer.array()));seletionKey.attach(newSender());
seletionKey.interestOps(SelectionKey.OP_WRITE);
seletionKey.selector().wakeup();
}
}catch(IOExceptione){
e.printStackTrace();
}
}
publicbooleaninputIsComplete(){
returntrue;
}
publicbooleanoutIsComplete(){
returntrue;
}
publicvoidprocess(){
//dosomething…
}
}
虽然上面说到NIO一个线程就可以支持所有的IO处理。但是瓶颈也是显而易见的。我们看一个客户端的情况,如果这个客户端多次进行请求,如果在Handler中的处理速度较慢,那么后续的客户端请求都会被积压,导致响应变慢!所以引入了Reactor多线程模型。
Reactor多线程模型
相比上一种模型,该模型在处理器链部分采用了多线程(线程池):
Reactor多线程模型就是将Handler中的IO操作和非IO操作分开,操作IO的线程称为IO线程,非IO操作的线程称为工作线程。这样的话,客户端的请求会直接被丢到线程池中,客户端发送请求就不会堵塞。
可以将Handler做如下修改:
classHandlerimplementsRunnable{
privatefinalstaticintDEFAULT_SIZE=1024;
privatefinalSocketChannelsocketChannel;
privatefinalSelectionKeyseletionKey;
privatestaticfinalintREADING=0;
privatestaticfinalintSENDING=1;
privateintstate=READING;
ByteBufferinputBuffer=ByteBuffer.allocate(DEFAULT_SIZE);
ByteBufferoutputBuffer=ByteBuffer.allocate(DEFAULT_SIZE);
privateSelectorselector;
privatestaticExecutorServiceexecutorService=
Executors.newFixedThreadPool(Runtime.getRuntime()
.availableProcessors());
privatestaticfinalintPROCESSING=3;
publicHandler(Selectorselector,SocketChannelchannel)throwsIOException{
this.selector=selector;
this.socketChannel=channel;
socketChannel.configureBlocking(false);
this.seletionKey=socketChannel.register(selector,0);
seletionKey.attach(this);
seletionKey.interestOps(SelectionKey.OP_READ);
selector.wakeup();
}
@Override
publicvoidrun(){
if(state==READING){
read();
}elseif(state==SENDING){
write();
}
}
classSenderimplementsRunnable{
@Override
publicvoidrun(){
try{
socketChannel.write(outputBuffer);
}catch(IOExceptione){
e.printStackTrace();
}
if(outIsComplete()){
seletionKey.cancel();
}
}
}
privatevoidwrite(){
try{
socketChannel.write(outputBuffer);
}catch(IOExceptione){
e.printStackTrace();
}
if(outIsComplete()){
seletionKey.cancel();
}
}
privatevoidread(){
try{
socketChannel.read(inputBuffer);
if(inputIsComplete()){
process();
executorService.execute(newProcesser());
}
}catch(IOExceptione){
e.printStackTrace();
}
}
publicbooleaninputIsComplete(){
returntrue;
}
publicbooleanoutIsComplete(){
returntrue;
}
publicvoidprocess(){
}
synchronizedvoidprocessAndHandOff(){
process();
state=SENDING;//orrebindattachment
seletionKey.interestOps(SelectionKey.OP_WRITE);
selector.wakeup();
}
classProcesserimplementsRunnable{
publicvoidrun(){
processAndHandOff();
}
}
}
但是当用户进一步增加的时候,Reactor会出现瓶颈!因为Reactor既要处理IO操作请求,又要响应连接请求。为了分担Reactor的负担,所以引入了主从Reactor模型。
主从Reactor多线程模型
主从Reactor多线程模型是将Reactor分成两部分,mainReactor负责监听serversocket,accept新连接,并将建立的socket分派给subReactor。subReactor负责多路分离已连接的socket,读写网络数据,对业务处理功能,其扔给worker线程池完成。通常,subReactor个数上可与CPU个数等同:
这时可以把Reactor做如下修改:
publicclassReactor{
finalServerSocketChannelserverSocketChannel;
Selector[]selectors;//alsocreatethreads
AtomicIntegernext=newAtomicInteger(0);
ExecutorServicesunReactors=
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
publicstaticvoidmain(String[]args)throwsIOException{
newReactor(1234);
}
publicReactor(intport)throwsIOException{
serverSocketChannel=ServerSocketChannel.open();serverSocketChannel.socket().bind(newInetSocketAddress(port));serverSocketChannel.configureBlocking(false);
selectors=newSelector[4];
for(inti=0;i<4;i++){
Selectorselector=Selector.open();
selectors[i]=selector;
SelectionKeykey=serverSocketChannel.register(selector,SelectionKey.OP_ACCEPT);
key.attach(newAcceptor());
newThread(()->{
while(!Thread.interrupted()){
try{
selector.select();
Set
selector.selectedKeys();
for(SelectionKeyselectionKey:selectionKeys){
dispatch(selectionKey);
}
selectionKeys.clear();
}catch(IOExceptione){
e.printStackTrace();
}
}
}).start();
}
}
privatevoiddispatch(SelectionKeyselectionKey){
Runnablerun=(Runnable)selectionKey.attachment();
if(run!=null){
run.run();
}
}
classAcceptorimplementsRunnable{
@Override
publicvoidrun(){
try{
SocketChannelconnection=serverSocketChannel.accept();if(connection!=null)
sunReactors.execute(new
Handler(selectors[next.getAndIncrement()%selectors.length],connection));}catch(IOExceptione){
e.printStackTrace();
}
}
}
}
可见,主Reactor用于响应连接请求,从Reactor用于处理IO操作请求。
AIO是一种接口标准,各家操作系统可以实现也可以不实现。在不同操作系统上在高并发情况下最好都采用操作系统推荐的方式。Linux上还没有真正实现网络方式的AIO。
select和epoll的区别
当需要读两个以上的I/O的时候,如果使用阻塞式的I/O,那么可能长时间的阻塞在一个描述符上面,另外的描述符虽然有数据但是不能读出来,这样实时性不能满足要求,大概的解决方案有以下几种:
1.使用多进程或者多线程,但是这种方法会造成程序的复杂,而且对与进程与线程的创建维护也需要很多的开销(Apache服务器是用的子进程的方式,优点可以隔离用户);
2.用一个进程,但是使用非阻塞的I/O读取数据,当一个I/O不可读的时候立刻返回,检查下一个是否可读,这种形式的循环为轮询(polling),这种方法比较浪费CPU时间,因为大多数时间是不可读,但是仍花费时间不断反复执行read系统调用;
3.异步I/O,当一个描述符准备好的时候用一个信号告诉进程,但是由于信号个数有限,多个描述符时不适用;
4.一种较好的方式为I/O多路复用,先构造一张有关描述符的列表(epoll中为队列),然后调用一个函数,直到这些描述符中的一个准备好时才返回,返回时告诉进程哪些I/O就绪。select和epoll这两个机制都是多路I/O机制的解决方案,select为POSIX标准中的,而epoll为Linux所特有的。
它们的区别主要有三点:
1.select的句柄数目受限,在linux/posix_types.h头文件有这样的声明:
1024表示select最多同时监听1024个fd。而epoll没有,它的限制是最大的打开文件句柄数目;
2.epoll的最大好处是不会随着FD的数目增长而降低效率,在selec中采用轮询处理,其中的数据结构类似一个数组的数据结构,而epoll是维护一个队列,直接看队列是不是空就可以了。epoll只会对”活跃”的socket进行操作—这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有”活跃”的socket才会主动的去调用callback函数(把这个句柄加入队列),其他idle状态句柄则不会,在这点上,epoll实现了一个”伪”AIO。但是如果绝大部分的I/O都是“活跃的”,每个I/O端口使用率很高的话,epoll效率不一定比select高(可能是要维护队列复杂);
3.使用mmap加速内核与用户空间的消息传递。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间
mmap同一块内存实现的。
上文说到了select与epoll的区别,再总结一下JavaNIO与select和epoll:
Linux2.6之后支持epoll
windows支持select而不支持epoll
不同系统下nio的实现是不一样的,包括Sunoslinux和windows
select的复杂度为O(N)
select有最大fd限制,默认为1024
修改sys/select.h可以改变select的fd数量限制
epoll的事件模型,无fd数量限制,复杂度O(1),不需要遍历fd
以下代码基于Java8。
下面看下在NIO中Selector的open方法:
在linux中的实现如下:
其上操作看上去只有两个简单的调用,但是其内部过程却要经历四次用户态和内核态的切换以及四次的数据复制操作:
上图展示了数据从文件到socket的内部流程。
下面看下用户态和内核态的切换过程:
步骤如下:
1.read()的调用引起了从用户态到内核态的切换(看图二),内部是通过sys_read()(或者类似的方法)发起对文件数据的读取。数据的第一次复制是通过DMA(直接内存访问)将磁盘上的数据复制到内核空间的缓冲区中;
2.数据从内核空间的缓冲区复制到用户空间的缓冲区后,read()方法也就返回了。此时内核态又切换回用户态,现在数据也已经复制到了用户地址空间的缓存中;
3.socket的send()方法的调用又会引起用户态到内核的切换,第三次数据复制又将数据从用户空间缓冲区复制到了内核空间的缓冲区,这次数据被放在了不同于之前的内核缓冲区中,这个缓冲区与数据将要被传输到的socket关联;
4.send()系统调用返回后,就产生了第四次用户态和内核态的切换。随着DMA单独异步的将数据从内核态的缓冲区中传输到协议引擎发送到网络上,有了第四次数据复制。
Java.nio.channels.FileChannel中定义了两个方法:transferTo()和transferFrom()。
channel-to-channel传输中通道之一必须是FileChannel。您不能在socket通道之间直接传输数据,不过socket通道实现
方法传输给一个socket通道,或者也可以用transferFrom()方法将数据从一个socket通道直接读取到一个文件中。
方法来说明。
方法可以把bytes直接从调用它的channel传输到另一个WritableByteChannel,中间不经过应用程序。
下面看下该方法的定义:
下图展示了通过transferTo实现数据传输的路径:
下图展示了内核态、用户态的切换情况:
使用transferTo()方式所经历的步骤:
1.transferTo调用会引起DMA将文件内容复制到读缓冲区(内核空间的缓冲区),然后数据从这个缓冲区复制到另一个与socket输出相关的内核缓冲区中;
2.第三次数据复制就是DMA把socket关联的缓冲区中的数据复制到协议引擎上发送到网络上。
这次改善,我们是通过将内核、用户态切换的次数从四次减少到两次,将数据的复制次数从四次减少到三次(只有一次用到cpu资源)。但这并没有达到我们零复制的目标。如果底层网络适配器支持收集操作的话,我们可以进一步减少内核对数据的复制次数。在内核为2.4或者以上版本的linux系统上,socket缓冲区描述符将被用来满足这个需求。这个方式不仅减少了内核用户态间的切换,而且也省去了那次需要cpu参与的复制过程。从用户角度来看依旧是调用transferTo()方法,但是其本质发生了变化:
1.调用transferTo方法后数据被DMA从文件复制到了内核的一个缓冲区中;
2.数据不再被复制到socket关联的缓冲区中了,仅仅是将一个描述符(包含了数据的位置和长度等信息)追加到socket关联的缓冲区中。DMA直接将内核中的缓冲区中的数据传输给协议引擎,消除了仅剩的一次需要cpu周期的数据复制。
NIO存在的问题
使用NIO!=高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。
NIO并没有完全屏蔽平台差异,它仍然是基于各个操作系统的I/O系统实现的,差异仍然存在。使用NIO做网络编程构建事件驱动模型并不容易,陷阱重重。
推荐大家使用成熟的NIO框架,如Netty,MINA等。解决了很多NIO的陷阱,并屏蔽了操作系统的差异,有较好的性能和编程模型。
总结
最后总结一下NIO有哪些优势:
事件驱动模型
避免多线程
单线程处理多任务
非阻塞I/O,I/O读写不再阻塞
基于block的传输,通常比基于流的传输更高效
更高级的IO函数,ZeroCopy
I/O多路复用大大提高了Java网络应用的可伸缩性和实用性
三个channel使用
ServerSocketChannel||SocketChannel||FileChanne
l
JavaNIO系列教程FileChannel
JavaNIO中的FileChannel是一个连接到文件的通道。可以通过文件通道读写文件。
FileChannel无法设置为非阻塞模式,它总是运行在阻塞模式下。
打开FileChannel
在使用FileChannel之前,必须先打开它。但是,我们无法直接打开一个FileChannel,需要通过使用一个InputStream、OutputStream或RandomAccessFile来获取一个FileChannel实例。下面是通过RandomAccessFile打开FileChannel的示例:
从FileChannel读取数据
调用多个read()方法之一从FileChannel中读取数据。如:
ByteBufferbuf=ByteBuffer.allocate(48);
intbytesRead=inChannel.read(buf);
首先,分配一个Buffer。从FileChannel中读取的数据将被读到Buffer中。
然后,调用FileChannel.read()方法。该方法将数据从FileChannel读取到Buffer中。read()方法返回的int值表示了有多少字节被读到了Buffer中。如果返回-1,表示到了文件末尾。
向FileChannel写数据
使用FileChannel.write()方法向FileChannel写数据,该方法的参数是一个Buffer。如:
StringnewData=”NewStringtowritetofile…”+System.currentTimeMillis();
ByteBufferbuf=ByteBuffer.allocate(48);
buf.clear();
buf.put(newData.getBytes());
buf.flip();
while(buf.hasRemaining()){
channel.write(buf);
}
注意FileChannel.write()是在while循环中调用的。因为无法保证write()方法一次能向FileChannel写入多少字节,因此需要重复调用write()方法,直到Buffer中已经没有尚未写入通道的字节。
关闭SocketChannel
当用完SocketChannel之后调用SocketChannel.close()关闭SocketChannel:
socketChannel.close();
从SocketChannel读取数据
要从SocketChannel中读取数据,调用一个read()的方法之一。以下是例子:
ByteBufferbuf=ByteBuffer.allocate(48);
intbytesRead=socketChannel.read(buf);
首先,分配一个Buffer。从SocketChannel读取到的数据将会放到这个Buffer中。
然后,调用SocketChannel.read()。该方法将数据从SocketChannel读到Buffer中。read()方法返回的int值表示读了多少字节进Buffer里。如果返回的是-1,表示已经读到了流的末尾(连接关闭了)。
写入SocketChannel
写数据到SocketChannel用的是SocketChannel.write()方法,该方法以一个Buffer作为参数。示例如下:
StringnewData=”NewStringtowritetofile…”+System.currentTimeMillis();
ByteBufferbuf=ByteBuffer.allocate(48);
buf.clear();
buf.put(newData.getBytes());
buf.flip();
while(buf.hasRemaining()){
channel.write(buf);
}
注意SocketChannel.write()方法的调用是在一个while循环中的。Write()方法无法保证能写多少字节到SocketChannel。所以,我们重复调用write()直到Buffer没有要写的字节为止。
非阻塞模式
可以设置SocketChannel为非阻塞模式(non-blockingmode).设置之后,就可以在异步模式下调用connect(),read()和write()了。
connect()
如果SocketChannel在非阻塞模式下,此时调用connect(),该方法可能在连接建立之前就返回了。为了确定连接是否建立,可以调用finishConnect()的方法。像这样:
socketChannel.configureBlocking(false);
socketChannel.connect(newInetSocketAddress(“http://jenkov.com”,80));
while(!socketChannel.finishConnect()){
//wait,ordosomethingelse…
}
write()
非阻塞模式下,write()方法在尚未写出任何内容时可能就返回了。所以需要在循环中调用write()。前面已经有例子了,这里就不赘述了。
read()
非阻塞模式下,read()方法在尚未读取到任何数据时可能就返回了。所以需要关注它的int返回值,它会告诉你读取了多少字节。
非阻塞模式与选择器
非阻塞模式与选择器搭配会工作的更好,通过将一或多个SocketChannel注册到Selector,可以询问选择器哪个通道已经准备好了读取,写入等。Selector与SocketChannel的搭配使用会在后面详讲。
JavaNIO系列教程ServerSocketChannel
JavaNIO中的ServerSocketChannel是一个可以监听新进来的TCP连接的通道,就像标准IO中的ServerSocket一样。ServerSocketChannel类在Java.nio.channels包中。
这里有个例子:
ServerSocketChannelserverSocketChannel=ServerSocketChannel.open();
serverSocketChannel.socket().bind(newInetSocketAddress(9999));
while(true){
SocketChannelsocketChannel=
serverSocketChannel.accept();
//dosomethingwithsocketChannel…
}
监听新进来的连接
通过ServerSocketChannel.accept()方法监听新进来的连接。当accept()方法返回的时候,它返回一个包含新进来的连接的SocketChannel。因此,accept()方法会一直阻塞到有新连接到达。
通常不会仅仅只监听一个连接,在while循环中调用accept()方法.如下面的例子:
String编码UTF-8和GBK的区别
GBK编码:是指中国的中文字符,其实它包含了简体中文与繁体中文字符,另外还有一种字符“gb2312”,这种字符仅能存储简体中文字符。UTF-8编码:它是一种全国家通过的一种编码,如果你的网站涉及到多个国家的语言,那么建议你选择UTF-8编码。
GBK和UTF8有什么区别?
UTF8编码格式很强大,支持所有国家的语言,正是因为它的强大,才会导致它占用的空间大小要比GBK大,对于网站打开速度而言,也是有一定影响的。
GBK编码格式,它的功能少,仅限于中文字符,当然它所占用的空间大小会随着它的功能而减少,打开网页的速度比较快。
什么时候使用字节流、什么时候使用字符流
什么时候使用字节流、什么时候使用字符流,二者的区别
先来看一下流的概念:
在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成。
InputStream和OutputStream,两个是为字节流设计的,主要用来处理字节或二进制对象,Reader和Writer.两个是为字符流(一个字符占两个字节)设计的,主要用来处理字符或字符串.
字符流处理的单元为2个字节的Unicode字符,操作字符、字符数组或字符串,
字节流处理单元为1个字节,操作字节和字节数组。
所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,所以它对多国语言支持性比较好!
如果是音频文件、图片、歌曲,就用字节流好点,
如果是关系到中文(文本)的,用字符流好点
所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。在读取文件(特别是文本文件)时,也是一个字节一个字节地读取以形成字节序列
字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串;
字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以
字节流是最基本的,所有的InputStrem和OutputStream的子类都是,主要用在处理二进制数据,它是按字节来处理的
但实际中很多的数据是文本,
又提出了字符流的概念,
它是按虚拟机的encode来处理,也就是要进行字符集的转化
这两个之间通过InputStreamReader,OutputStreamWriter来关联,
实际上是通过byte[]和String来关联
在实际开发中出现的汉字问题实际上都是在字符流和字节流之间转化不统一而造成的
Reader类的read()方法返回类型为int:作为整数读取的字符(占两个字节共16位),范围在0到65535之间(0x00-0xffff),如果已到达流的末尾,则返回-1
inputStream的read()虽然也返回int,但由于此类是面向字节流的,一个字节占8个位,所以返回0到255范围内的int字节值。如果因为已经到达流末尾而没有可用的字节,则返回值-1。因此对于不能用0-255来表示的值就得用字符流来读取!比如说汉字.
字节流和字符流的主要区别是什么呢?
一.字节流在操作时不会用到缓冲区(内存),是直接对文件本身进行操作的。而字符流在操作时使用了缓冲区,通过缓冲区再操作文件。
二.在硬盘上的所有文件都是以字节形式存在的(图片,声音,视频),而字符值在内存中才会形成。
上面两点能说明什么呢?
针对第一点,
我们知道,如果一个程序频繁对一个资源进行IO操作,效率会非常低。此时,通过缓冲区,先把需要操作的数据暂时放入内存中,以后直接从内存中读取数据,则可以避免多次的IO操作,提高效率
针对第二点,
真正存储和传输数据时都是以字节为单位的,字符只是存在与内存当中的,所以,字节流适用范围更为宽广
递归读取文件夹下的文件,代码怎么实现
/*
递归读取文件夹下的所有文件
@paramtestFileDir文件名或目录名*/
privatestaticvoidtestLoopOutAllFileName(StringtestFileDir){
if(testFileDir==null){
//因为newFile(null)会空指针异常,所以要判断下
return;
}
File[]testFile=newFile(testFileDir).listFiles();
if(testFile==null){
return;
}
for(Filefile:testFile){
if(file.isFile()){
System.out.println(file.getName());
}elseif(file.isDirectory()){
System.out.println(“———-thisisadirectory,anditsfilesareasfollows:———-“);
testLoopOutAllFileName(file.getPath());
}else{
System.out.println(“文件读入有误!”);
}
}
SynchronousQueue实现原理
前言
SynchronousQueue是一个比较特别的队列,由于在线程池方面有所应用,为了更好的理解线程池的实现原理,笔者花了些时间学习了一下该队列源码(JDK1.8),此队列源码中充斥着大量的CAS语句,理解起来是有些难度的,为了方便日后回顾,本篇文章会以简洁的图形化方式展示该队列底层的实现原理。
SynchronousQueue简单使用
经典的生产者-消费者模式,操作流程是这样的:
有多个生产者,可以并发生产产品,把产品置入队列中,如果队列满了,生产者就会阻塞;
有多个消费者,并发从队列中获取产品,如果队列空了,消费者就会阻塞;
如下面的示意图所示:
SynchronousQueue
也是一个队列来的,但它的特别之处在于它内部没有容器,一个生产线程,当它生产产品(即put的时候),如果当前没有人想要消费产品(即当前没有线程执行take),此生产线程必须阻塞,等待一个消费线程调用take操作,take操作将会唤醒该生产线程,同时消费线程会获取生产线程的产品(即数据传递),这样的一个过程称为一次配对过程(当然也可以先take后put,原理是一样的)。
我们用一个简单的代码来验证一下,如下所示:
packagecom.concurrent;
importJava.util.concurrent.SynchronousQueue;
publicclassSynchronousQueueDemo{
publicstaticvoidmain(String[]args)throwsInterruptedException{
finalSynchronousQueue
ThreadputThread=newThread(newRunnable(){
@Override
publicvoidrun(){
System.out.println(“putthreadstart”);
try{
queue.put(1);
}catch(InterruptedExceptione){
}
System.out.println(“putthreadend”);
}
});
ThreadtakeThread=newThread(newRunnable(){
@Override
publicvoidrun(){
System.out.println(“takethreadstart”);
try{
System.out.println(“takefromputThread:”+queue.take());}catch(InterruptedExceptione){
}
System.out.println(“takethreadend”);
}
});
putThread.start();
Thread.sleep(1000);
takeThread.start();
}
}
一种输出结果如下:
putthreadstart
takethreadstart
takefromputThread:1
putthreadend
takethreadend
从结果可以看出,put线程执行queue.put(1)后就被阻塞了,只有take线程进行了消费,put线程才可以返回。可以认为这是一种线程与线程间一对一传递消息的模型。
SynchronousQueue实现原理
不像ArrayBlockingQueue、LinkedBlockingDeque之类的阻塞队列依赖AQS实现并发操作,SynchronousQueue直接使用CAS实现线程的安全访问。由于源码中充斥着大量的CAS代码,不易于理解,所以按照笔者的风格,接下来会使用简单的示例来描述背后的实现模型。
队列的实现策略通常分为公平模式和非公平模式,接下来将分别进行说明。
公平模式下的模型:
公平模式下,底层实现使用的是TransferQueue这个内部队列,它有一个head和tail指针,用于指向当前正在等待匹配的线程节点。
初始化时,TransferQueue的状态如下:
接着我们进行一些操作:
1、线程put1执行put(1)操作,由于当前没有配对的消费线程,所以put1线程入队列,自旋一小会后睡眠等待,这时队列状态如下:
2、接着,线程put2执行了put(2)操作,跟前面一样,put2线程入队列,自旋一小会后睡眠等待,这时队列状态如下:
3、这时候,来了一个线程take1,执行了
take操作,由于tail指向put2线程,put2线程跟take1线程配对了(一put一take),这时take1线程不需要入队,但是请注意了,这时候,要唤醒的线程并不是put2,而是put1。为何?
大家应该知道我们现在讲的是公平策略,所谓公平就是谁先入队了,谁就优先被唤醒,我们的例子明显是put1应该优先被唤醒。至于读者可能会有一个疑问,明明是take1线程跟put2线程匹配上了,结果是put1线程被唤醒消费,怎么确保take1线程一定可以和次首节点(head.next)也是匹配的呢?其实大家可以拿个纸画一画,就会发现真的就是这样的。
公平策略总结下来就是:队尾匹配队头出队。
执行后put1线程被唤醒,take1线程的take()方法返回了1(put1线程的数据),这样就实现了线程间的一对一通信,这时候内部状态如下:
4、最后,再来一个线程take2,执行take操作,这时候只有put2线程在等候,而且两个线程匹配上了,线程put2被唤醒,
take2线程take操作返回了2(线程put2的数据),这时候队列又回到了起点,如下所示:
以上便是公平模式下,SynchronousQueue的实现模型。总结下来就是:队尾匹配队头出队,先进先出,体现公平原则。
非公平模式下的模型:
我们还是使用跟公平模式下一样的操作流程,对比两种策略下有何不同。非公平模式底层的实现使用的是TransferStack,
一个栈,实现中用head指针指向栈顶,接着我们看看它的实现模型:
1、线程put1执行put(1)操作,由于当前没有配对的消费线程,所以put1线程入栈,自旋一小会后睡眠等待,这时栈状态如下:
2、接着,线程put2再次执行了put(2)操作,跟前面一样,put2线程入栈,自旋一小会后睡眠等待,这时栈状态如下:
3、这时候,来了一个线程take1,执行了take操作,这时候发现栈顶为put2线程,匹配成功,但是实现会先把take1线程入栈,然后take1线程循环执行匹配put2线程逻辑,一旦发现没有并发冲突,就会把栈顶指针直接指向put1线程
4、最后,再来一个线程take2,执行take操作,这跟步骤3的逻辑基本是一致的,take2线程入栈,然后在循环中匹配put1线程,最终全部匹配完毕,栈变为空,恢复初始状态,如下图所示:
可以从上面流程看出,虽然put1线程先入栈了,但是却是后匹配,这就是非公平的由来。
总结
SynchronousQueue由于其独有的线程一一配对通信机制,在大部分平常开发中,可能都不太会用到,但线程池技术中会有所使用,由于内部没有使用AQS,而是直接使用CAS,所以代码理解起来会比较困难,但这并不妨碍我们理解底层的实现模型,在理解了模型的基础上,有兴趣的话再查阅源码,就会有方向感,看起来也会比较容易,希望本文有所借鉴意义。
自定义类加载器
为什么需要自定义类加载器
网上的大部分自定义类加载器文章,几乎都是贴一段实现代码,然后分析一两句自定义ClassLoader的原理。但是我觉得首先得把为什么需要自定义加载器这个问题搞清楚,因为如果不明白它的作用的情况下,还要去学习它显然是很让人困惑的。
首先介绍自定义类的应用场景:
(1)加密:Java代码可以轻易的被反编译,如果你需要把自己的代码进行加密以防止反编译,可以先将编译后的代码用某种加密算法加密,类加密后就不能再用Java的ClassLoader去加载类了,这时就需要自定义ClassLoader在加载类的时候先解密类,然后再加载。
(2)从非标准的来源加载代码:如果你的字节码是放在数据库、甚至是在云端,就可以自定义类加载器,从指定的来源加载类。
(3)以上两种情况在实际中的综合运用:比如你的应用需要通过网络来传输Java类的字节码,为了安全性,这些字节码经过了加密处理。这个时候你就需要自定义类加载器来从某个网络地址上读取加密后的字节代码,接着进行解密和验证,最后定义出在Java虚拟机中运行的类。
1.双亲委派模型
在实现自己的ClassLoader之前,我们先了解一下系统是如何加载类的,那么就不得不介绍双亲委派模型的实现过程。
//双亲委派模型的工作过程源码
protectedsynchronizedClass<?>loadClass(Stringname,booleanresolve)throwsClassNotFoundException{
//First,checkiftheclasshasalreadybeenloaded
Classc=findLoadedClass(name);
if(c==null){
try{
if(parent!=null){
c=parent.loadClass(name,false);
}else{
c=findBootstrapClassOrNull(name);
}
}
catch(ClassNotFoundExceptione){
//ClassNotFoundExceptionthrownifclassnotfound
//fromthenon-nullparentclassloader
//父类加载器无法完成类加载请求
}
if(c==null){
//Ifstillnotfound,theninvokefindClassinordertofindthe
class
//子加载器进行类加载
c=findClass(name);
}
}
if(resolve){
//判断是否需要链接过程,参数传入
resolveClass(c);
}
returnc;
}
双亲委派模型的工作过程如下:
(1)当前类加载器从自己已经加载的类中查询是否此类已经加载,如果已经加载则直接返回原来已经加载的类。
(2)如果没有找到,就去委托父类加载器去加载(如代码c=parent.loadClass(name,false)所示)。父类加载器也会采用同样的策略,查看自己已经加载过的类中是否包含这个类,有就返回,没有就委托父类的父类去加载,一直到启动类加载器。因为如果父加载器为空了,就代表使用启动类加载器作为父加载器去加载。
(3)如果启动类加载器加载失败(例如在$Java_HOME/jre/lib里未查找到该class),则会抛出一个异常ClassNotFoundException,然后再调用当前加载器的findClass()方法进行加载。
双亲委派模型的好处:
(1)主要是为了安全性,避免用户自己编写的类动态替换Java的一些核心类,比如String。
(2)同时也避免了类的重复加载,因为JVM中区分不同类,不仅仅是根据类名,相同的class文件被不同的ClassLoader加载就是不同的两个类。
2.自定义类加载器
(1)从上面源码看出,调用loadClass时会先根据委派模型在父加载器中加载,如果加载失败,则会调用当前加载器的findClass来完成加载。
(2)因此我们自定义的类加载器只需要继承ClassLoader,并覆盖findClass方法,下面是一个实际例子,在该例中我们用自定义的类加载器去加载我们事先准备好的class文件。
2.1自定义一个People.Java类做例子
publicclassPeople{
//该类写在记事本里,在用Javac命令行编译成class文件,放在d盘根目录下
privateStringname;
publicPeople(){}
publicPeople(Stringname){
this.name=name;
}
publicStringgetName(){
returnname;
}
publicvoidsetName(Stringname){
this.name=name;
}
publicStringtoString(){
return”Iamapeople,mynameis”+name;
}
}
2.2自定义类加载器
自定义一个类加载器,需要继承ClassLoader类,并实现findClass方法。其中defineClass方法可以把二进制流字节组成的文件转换为一个Java.lang.Class(只要二进制字节流的内容符合Class文件规范)。
importJava.io.ByteArrayOutputStream;
importJava.io.File;
importJava.io.FileInputStream;
importJava.nio.ByteBuffer;
importJava.nio.channels.Channels;
importJava.nio.channels.FileChannel;
importJava.nio.channels.WritableByteChannel;
publicclassMyClassLoaderextendsClassLoader
{
publicMyClassLoader()
{
}
publicMyClassLoader(ClassLoaderparent)
{
super(parent);
}
protectedClass<?>findClass(Stringname)throwsClassNotFoundException{
Filefile=newFile(“D:/People.class”);
try{
byte[]bytes=getClassBytes(file);
//defineClass方法可以把二进制流字节组成的文件转换为一个Java.lang.Class
Class<?>c=this.defineClass(name,bytes,0,bytes.length);returnc;
}
catch(Exceptione)
{
e.printStackTrace();
}
returnsuper.findClass(name);
}
privatebyte[]getClassBytes(Filefile)throwsException
{
//这里要读入.class的字节,因此要使用字节流
FileInputStreamfis=newFileInputStream(file);
FileChannelfc=fis.getChannel();
ByteArrayOutputStreambaos=newByteArrayOutputStream();
WritableByteChannelwbc=Channels.newChannel(baos);
ByteBufferby=ByteBuffer.allocate(1024);
while(true){
2.4运行结果
至此关于自定义ClassLoader的内容总结完毕。
面向对象和面向过程的区别
面向过程
优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗
资源;比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。缺点:没有面向对象易维护、易复用、易扩展
面向对象
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
缺点:性能比面向过程低
Java语言有哪些特点
1.简单易学;
2.面向对象(封装,继承,多态);
3.平台无关性(Java虚拟机实现平台无关性);
4.可靠性;
5.安全性;
6.支持多线程(C++语言没有内置的多线程机制,因此必须调用操作系
统的多线程功能来进行多线程程序设计,而Java语言却提供了多线程支持);
7.支持网络编程并且很方便(Java语言诞生本身就是为简化网络编程设
计的,因此Java语言不仅支持网络编程而且很方便);
8.编译与解释并存;
关于JVMJDK和JRE最详细通俗的解答
JVM
Java虚拟机(JVM)是运行Java字节码的虚拟机。JVM有针对不同系统的特
定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
什么是字节码?采用字节码的好处是什么?
在Java中,JVM可以理解的代码就叫做字节码(即扩展名为.class的文
件),它不面向任何特定的处理器,只面向虚拟机。Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码
并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。
Java程序从源代码到运行一般有下面3步:
我们需要格外注意的是.class->机器码这一步。在这一步jvm类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的,也就是所谓的热点代码,所以后面引进了JIT编译器,JIT属于运行时编译。当JIT编译器完成第一
次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率
肯定是高于Java解释器的。这也解释了我们为什
么经常会说Java是编译与解释共存的语言。
HotSpot采用了惰性评估(LazyEvaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是JIT所需要编译
的部分。JVM会根据代码每次被执行的情况收集信息并相应地做出一些优化,
因此执行的次数越多,它的速度就越快。JDK9引入了一种新的编译模式
AOT(AheadofTimeCompilation),它是直接将字节码编译成机器码,这样就
避免了JIT预热等各方面的开销。JDK支持分层编译和AOT协作使用。但是,
AOT编译器的编译质量是肯定比不上JIT编译器的。
总结:Java虚拟机(JVM)是运行Java字节码的虚拟机。JVM有针对不同系
统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们
都会给出相同的结果。字节码和不同系统的JVM实现是Java语言“一次编译,随处可以运行”的关键所在。
JDK和JRE
JDK是JavaDevelopmentKit,它是功能齐全的JavaSDK。它拥有JRE所拥有
的一切,还有编译器(Javac)和工具(如Javadoc和jdb)。它能够创建和编译程序。
JRE是Java运行时环境。它是运行已编译Java程序所需的所有内容的集合,
包括Java虚拟机(JVM),Java类库,Java命令和其他的一些基础构件。但是,它不能用于创建新程序。
如果你只是为了运行一下Java程序的话,那么你只需要安装JRE就可以了。
如果你需要进行一些Java编程方面的工作,那么你就需要安装JDK了。但是,这不是绝对的。有时,即使您不打算在计算机上进行任何Java开发,仍然需要安装JDK。例如,如果要使用JSP部署Web应用程序,那么从技术上讲,您只是在应用程序服务器中运行Java程序。那你为什么需要JDK呢?因为应用
程序服务器会将JSP转换为Javaservlet,并且需要使用JDK来编译
servlet。
OracleJDK和OpenJDK的对比
可能在看这个问题之前很多人和我一样并没有接触和使用过OpenJDK。那么
Oracle和OpenJDK之间是否存在重大差异?下面通过我通过我收集到一些资料对你解答这个被很多人忽视的问题。
对于Java7,没什么关键的地方。OpenJDK项目主要基于Sun捐赠的HotSpot
源代码。此外,OpenJDK被选为Java7的参考实现,由Oracle工程师维护。
关于JVM,JDK,JRE和OpenJDK之间的区别,Oracle博客帖子在2012年有一个更详细的答案:问:OpenJDK存储库中的源代码与用于构建OracleJDK的代码之间有什么区别?
答:非常接近-我们的OracleJDK版本构建过程基于OpenJDK7构建,只添
加了几个部分,例如部署代码,其中包括Oracle的Java插件和JavaWebStart的实现,以及一些封闭的源代码派对组件,如图形光栅化器,一些开源的第三方组件,如Rhino,以及一些零碎的东西,如附加文档或第三方字体。展望未
来,我们的目的是开源OracleJDK的所有部分,除了我们考虑商业功能的部
分。
总结:
1.OracleJDK版本将每三年发布一次,而OpenJDK版本每三个月发布一
次;
2.OpenJDK是一个参考模型并且是完全开源的,而OracleJDK是
OpenJDK的一个实现,并不是完全开源的;
3.OracleJDK比OpenJDK更稳定。OpenJDK和OracleJDK的代码几乎相同,但OracleJDK有更多的类和一些错误修复。因此,如果您想开发
企业/商业软件,我建议您选择OracleJDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用OpenJDK可能会遇到了许多应用程序崩溃的问题,但是,只需切换到OracleJDK就可以解决问题;
4.顶级公司正在使用OracleJDK,例如AndroidStudio,Minecraft和
IntelliJIDEA开发工具,其中OpenJDK不太受欢迎;
5.在响应性和JVM性能方面,OracleJDK与OpenJDK相比提供了更好的性能;
6.OracleJDK不会为即将发布的版本提供长期支持,用户每次都必须通过更新到最新版本获得支持来获取最新版本;
7.OracleJDK根据二进制代码许可协议获得许可,而OpenJDK根据GPLv2许可获得许可。
Java和C++的区别
我知道很多人没学过C++,但是面试官就是没事喜欢拿咱们Java和C++比呀!没办法!!!就算没学过C++,也要记下来!
•都是面向对象的语言,都支持封装、继承和多态
•Java不提供指针来直接访问内存,程序内存更加安全
•Java的类是单继承的,C++支持多重继承;虽然Java的类不可以多
继承,但是接口可以多继承。
•Java有自动内存管理机制,不需要程序员手动释放无用内存
什么是Java程序的主类应用程序和小程序的主类有何不同
一个程序中可以有多个类,但只能有一个类是主类。在Java应用程序中,这
个主类是指包含main()方法的类。而在Java小程序中,这个主类是一个继
承自系统类JApplet或Applet的子类。应用程序的主类不一定要求是public
类,但小程序的主类要求必须是public类。主类是Java程序执行的入口点。
Java应用程序与小程序之间有那些差别
简单说应用程序是从主线程启动(也就是main()方法)。applet小程序没有
main方法,主要是嵌在浏览器页面上运行(调用init()线程或者run()来启动),嵌
入浏览器这点跟flash的小游戏类似。
字符型常量和字符串常量的区别
1.形式上:字符常量是单引号引起的一个字符字符串常量是双引号引起的
若干个字符
2.含义上:字符常量相当于一个整形值(ASCII值),可以参加表达式运算字符串常量代表一个地址值(该字符串在内存中存放位置)
3.占内存大小字符常量只占2个字节字符串常量占若干个字节(至少一个
字符结束标志)(注意:char在Java中占两个字节)
Java编程思想第四版:2.2.2节
构造器Constructor是否可被override
在讲继承的时候我们就知道父类的私有属性和构造方法并不能被继承,所以
Constructor也就不能被override(重写),但是可以overload(重载),所以你可以看到一个类中有多个构造函数的情况。
重载和重写的区别
重载:发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
重写:发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为private则子类就不能重写该方法。
Java面向对象编程三大特性:封装继承多态
封装
封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。
继承
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码。关于继承如下3点请记住:
1.子类拥有父类非private的属性和方法。
2.子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
3.子类可以用自己的方式实现父类的方法。(以后介绍)。
线程安全性
String中的对象是不可变的,也就可以理解为常量,线程安全。
AbstractStringBuilder是StringBuilder与StringBuffer的公共父类,定义了一些字符串的基本操作,如expandCapacity、append、insert、indexOf等公共方法。StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder并没有对方法进行加同步锁,所以是非线程安全的。性能
每次对String类型进行改变的时候,都会生成一个新的String对象,然后将指针指向新的String对象。StringBuffer每次都会对StringBuffer对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用
StringBuilder相比使用StringBuffer仅能获得10%~15%左右的性能提升,但却要冒多线程不安全的风险。对于三者使用的总结:
1.操作少量的数据=String
2.单线程操作字符串缓冲区下操作大量数据=StringBuilder
3.多线程操作字符串缓冲区下操作大量数据=StringBuffer
自动装箱与拆箱
装箱:将基本类型用它们对应的引用类型包装起来;拆箱:将包装类型转换为基本数据类型;
在一个静态方法内调用一个非静态成员为什么是非法的
由于静态方法可以不通过对象进行调用,因此在静态方法里,不能调用其他非静态变量,也不可以访问非静态变量成员。
在Java中定义一个不做事且没有参数的构造方法的作用
Java程序在执行子类的构造方法之前,如果没有用super()来调用父类特定的构造方法,则会调用父类中“没有参数的构造方法”。因此,如果父类中只定义了有参数的构造方法,而在子类的构造方法中又没有用super()来调用父类
中特定的构造方法,则编译时将发生错误,因为Java程序在父类中找不到没有参数的构造方法可供执行。解决办法是在父类里加上一个不做事且没有参数的构造方法。
importJava和Javax有什么区别
刚开始的时候JavaAPI所必需的包是Java开头的包,Javax当时只是扩展
API包来说使用。然而随着时间的推移,Javax逐渐的扩展成为JavaAPI的组
成部分。但是,将扩展从Javax包移动到Java包将是太麻烦了,最终会破坏
一堆现有的代码。因此,最终决定Javax包将成为标准API的一部分。
所以,实际上Java和Javax没有区别。这都是一个名字。
接口和抽象类的区别是什么
1.接口的方法默认是public,所有方法在接口中不能有实现(Java8开始
接口方法可以有默认实现),抽象类可以有非抽象的方法
2.接口中的实例变量默认是final类型的,而抽象类中则不一定
3.一个类可以实现多个接口,但最多只能实现一个抽象类
4.一个类实现接口的话要实现接口的所有方法,而抽象类不一定
5.接口不能用new实例化,但可以声明,但是必须引用一个实现该接口的对象从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
成员变量与局部变量的区别有那些
1.从语法形式上,看成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被public,private,static等修饰符所
修饰,而局部变量不能被访问控制修饰符及static所修饰;但是,成员
变量和局部变量都能被final所修饰;
2.从变量在内存中的存储方式来看,成员变量是对象的一部分,而对象存在于堆内存,局部变量存在于栈内存
3.从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
4.成员变量如果没有被赋初值,则会自动以类型的默认值而赋值(一种情况例外被final修饰的成员变量也必须显示地赋值);而局部变量则不
会自动赋值。
创建一个对象用什么运算符?对象实体与对象引用有何不同?
new运算符,new创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向0个或[1]个对象
(一根绳子可以不系气球,也可以系一个气球);一个对象可以有n个引用指向
它(可以用n条绳子系住一个气球)。
1.名字与类名相同;
什么是方法的返回值?返回值在类的方法里的作用是什么?
方法的返回值是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用:接收出结果,使得它可以用于其他的操作!
一个类的构造方法的作用是什么若一个类没有声明构造方
法,该程序能正确执行吗?为什么?
主要作用是完成对类对象的初始化工作。可以执行。因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。
构造方法有哪些特性
1.名字与类名相同
2.没有返回值,但不能用void声明构造函数;
3.生成类的对象时自动执行,无需调用。
静态方法和实例方法有何不同
1.在外部调用静态方法时,可以使用”类名.方法名”的方式,也可以使用”对
象名.方法名”的方式。而实例方法只有后面这种方式。也就是说,调用
静态方法可以无需创建对象。
2.静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制.
对象的相等与指向他们的引用相等,两者有什么不同?
对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
在调用子类构造方法之前会先调用父类没有参数的构造方
法,其目的是?
帮助子类做初始化工作。
==与equals(重要)
==:它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同
一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
equals():它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
•情况1:类没有覆盖equals()方法。则通过equals()比较该类的两个
说明:
•String中的equals方法是被重写过的,因为object的equals方法是比较的对象的内存地址,而String的equals方法比较的是对象的值。
•当创建String类型的对象时,虚拟机会在常量池中查找有没有已经存
在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个String对象。
hashCode与equals(重要)
面试官可能会问你:“你重写过hashcode和equals么,为什么重写equals
时必须重写hashCode方法?”
hashCode()介绍
hashCode()的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()定义
在JDK的Object.Java中,这就意味着Java中的任何类都包含有hashCode()函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有hashCode
我们以“HashSet如何检查重复”为例子来说明为什么要有hashCode:
当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断
对象加入的位置,同时也会与其他已经加入的对象的hashcode值作比较,如
果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有
相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。
如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head
firstJava》第二版)。这样我们就大大减少了equals的次数,相应就大大提高了执行速度。
hashCode()与equals()的相关规定
1.如果两个对象相等,则hashcode一定也是相同的
2.两个对象相等,对两个对象分别调用equals方法都返回true
3.两个对象有相同的hashcode值,它们也不一定是相等的
4.因此,equals方法被覆盖过,则hashCode方法也必须被覆盖
5.hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
关于final关键字的一些总结
final关键字主要用在三个地方:变量、方法、类。
1.对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
2.当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。
3.使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优
化了)。类中所有的private方法都隐式地指定为final。
Java中的异常处理
Java异常类层次结构图
在Java中,所有的异常都有一个共同的祖先Java.lang包中的Throwable类。Throwable:有两个重要的子类:Exception(异常)和Error(错误),二者都是Java异常处理的重要子类,各自都包含大量子类。
Error(错误):是程序无法处理的错误,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时JVM(Java虚拟机)出现的问题。例如,Java虚拟机运行错误 (VirtualMachineError),当JVM不再有继续执行操作所需的内存资源时,将出现OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误 (VirtualMachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在Java中,错误通过Error的子类描述。
Exception(异常):是程序本身可以处理的异常。Exception类有一个重要的子类
RuntimeException。RuntimeException异常由Java虚拟机抛出。
NullPointerException(要访问的变量没有引用任何对象时,抛出该异常)、
ArithmeticException(算术运算异常,一个整数除以0时,抛出该异常)和
ArrayIndexOutOfBoundsException(下标越界异常)。
注意:异常和错误的区别:异常能被程序本身可以处理,错误是无法处理。
Throwable类常用方法
•publicStringgetMessage():返回异常发生时的详细信息
•publicStringtoString():返回异常发生时的简要描述
•publicStringgetLocalizedMessage():返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以声称本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同
•publicvoidprintStackTrace():在控制台上打印Throwable对象封装的异常信息
接口继承关系和实现
集合类存放于Java.util包中,主要有3种:set(集)、list(列表包含Queue)和map(映射)。
1.Collection:Collection是集合List、Set、Queue的最基本的接口。
2.Iterator:迭代器,可以通过迭代器遍历集合中的数据
3.Map:是映射表的基础接口
List
Java的List是非常常用的数据类型。List是有序的Collection。JavaList一共三个实现类:分别是ArrayList、Vector和LinkedList。
ArrayList(数组)
ArrayList是最常用的List实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要将已经有数组的数据复制到新的存储空间中。当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
Vector(数组实现、线程同步)
Vector与ArrayList一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一
个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问ArrayList慢。
LinkList(链表)
LinkedList是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
Set
Set注重独一无二的性质,该体系集合用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复。对象的相等性本质是对象hashCode值(Java是依据对象的内存地址计算出的此序号)判断的,如果想要让两个不同的对象视为相等的,就必须覆盖Object的hashCode方法和equals方法。
HashSet(Hash表)
哈希表边存放的是哈希值。HashSet存储元素的顺序并不是按照存入时的顺序(和List显然不同)而是按照哈希值来存的所以取数据也是按照哈希值取得。元素的哈希值是通过元素的hashcode方法来获取的,HashSet首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals方法如果equls结果为true,HashSet就视为同一个元素。如果equals为false就不是同一个元素。
哈希值相同equals为false的元素是怎么存储呢,就是在同样的哈希值下顺延(可以认为哈希值相同的元素放在一个哈希桶中)。也就是哈希一样的存一列。如图1表示hashCode值不相同的情况;图2表示hashCode值相同,但equals不相同的情况。
HashSet通过hashCode值来确定元素在内存中的位置。一个hashCode位置上可以存放多个元素。
TreeSet(二叉树)
1.TreeSet()是使用二叉树的原理对新add()的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入的二叉树指定的位置。
2.Integer和String对象都可以进行默认的TreeSet排序,而自定义类的对象是不可以的,自己定义的类必须实现Comparable接口,并且覆写相应的compareTo()函数,才可以正常使用。
3.在覆写compare()函数时,要返回相应的值才能使TreeSet按照一定的规则来排序
4.比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
LinkHashSet(HashSet+LinkedHashMap)
对于LinkedHashSet而言,它继承与HashSet、又基于LinkedHashMap来实现的。
LinkedHashSet底层使用LinkedHashMap来保存所有元素,它继承与HashSet,其所有的方法操作上又与HashSet相同,因此LinkedHashSet的实现上非常简单,只提供了四个构造方法,并通过传递一个标识参数,调用父类的构造器,底层构造一个LinkedHashMap来实现,在相关操作上与父类HashSet的操作相同,直接调用父类HashSet的方法即可。
Map
HashMap(数组+链表+红黑树)
HashMap根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。我们用下面这张图来介绍
HashMap的结构。
Java7实现
大方向上,HashMap里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色的实体是嵌套类Entry的实例,Entry包含四个属性:key,value,hash值和用于单向链表的next。
1.capacity:当前数组容量,始终保持2^n,可以扩容,扩容后数组大小为当前的2倍。
2.loadFactor:负载因子,默认为0.75。
3.threshold:扩容的阈值,等于capacity*loadFactor
Java8实现
Java8对HashMap进行了一些修改,最大的不同就是利用了红黑树,所以其由数组+链表+红黑树组成。
根据Java7HashMap的介绍,我们知道,查找的时候,根据hash值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决
于链表的长度,为O(n)。为了降低这部分的开销,在Java8中,当链表中的元素超过了8个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为O(logN)。
ConcurrentHashMap
Segment段
ConcurrentHashMap和HashMap思路是差不多的,但是因为它支持并发操作,所以要复杂一些。整个ConcurrentHashMap由一个个Segment组成,Segment代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个segment。
线程安全(Segment继承ReentrantLock加锁)
简单理解就是,ConcurrentHashMap是一个Segment数组,Segment通过继承ReentrantLock来进行加锁,所以每次需要加锁的操作锁住的是一个segment,这样只要保证每个Segment是线程安全的,也就实现了全局的线程安全。
并行度concurrencyLevel:并行级别、并发数、Segment数,怎么翻译不重要,理解它。默认是16,也就是说ConcurrentHashMap有16个Segments,所以理论上,这个时候,最多可以同时支持16个线程并发写,只要它们的操作分别分布在不同的Segment上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。再具体到每个Segment内部,其实每个Segment很像之前介绍的HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
Java8实现(引入了红黑树)
Java8对ConcurrentHashMap进行了比较大的改动,Java8也引入了红黑树。
Java8实现(../../../../../0马士兵/新建文件夹/BAT面试突击资料(1)/整理/BAT面试突击资料/06-Java面试
核心知识点整理(时间较多的同学全面复习).assets/Java8实现(引入了红黑树).jpg)
HashTable(线程安全)
Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
3.4.4.TreeMap(可排序)
TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。
在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出Java.lang.ClassCastException类型的异常。
LinkHashMap(记录插入顺序)
LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
TreeMap的实现就是红黑树数据结构,也就说是一棵自平衡的排序二叉树,这样就可以保证当需要快速检索指定节点。
TreeSet和TreeMap的关系
为了让大家了解TreeMap和TreeSet之间的关系,下面先看TreeSet类的部分源代码:
publicclassTreeSet
implementsNavigableSet
{
//使用NavigableMap的key来保存Set集合的元素
privatetransientNavigableMap
//使用一个PRESENT作为Map集合的所有value。
privatestaticfinalObjectPRESENT=newObject();
//包访问权限的构造器,以指定的NavigableMap对象创建Set集合
TreeSet(NavigableMap
{
this.m=m;
}
publicTreeSet()//①
{
//以自然排序方式创建一个新的TreeMap,
//根据该TreeSet创建一个TreeSet,
//使用该TreeMap的key来保存Set集合的元素
this(newTreeMap
}
publicTreeSet(Comparator<?superE>comparator)//②
{
//以定制排序方式创建一个新的TreeMap,
//根据该TreeSet创建一个TreeSet,
//使用该TreeMap的key来保存Set集合的元素
this(newTreeMap
}
publicTreeSet(Collection<?extendsE>c)
{
//调用①号构造器创建一个TreeSet,底层以TreeMap保存集合元素
this();
//向TreeSet中添加Collection集合c里的所有元素
addAll(c);
}
publicTreeSet(SortedSet
{
//调用②号构造器创建一个TreeSet,底层以TreeMap保存集合元素
this(s.comparator());
//向TreeSet中添加SortedSet集合s里的所有元素
addAll(s);
}
//TreeSet的其他方法都只是直接调用TreeMap的方法来提供实现
…
publicbooleanaddAll(Collection<?extendsE>c)
{
if(m.size()==0&&c.size()>0&&
cinstanceofSortedSet&&
minstanceofTreeMap)
{
//把c集合强制转换为SortedSet集合
SortedSet<?extendsE>set=(SortedSet<?extendsE>)c;//把m集合强制转换为TreeMap集合
TreeMap
Comparator<?superE>cc=(Comparator<?superE>)set.comparator();Comparator<?superE>mc=map.comparator();
//如果cc和mc两个Comparator相等
if(cc==mc||(cc!=null&&cc.equals(mc)))
{
//把Collection中所有元素添加成TreeMap集合的key
map.addAllForTreeSet(set,PRESENT);
returntrue;
}
}
//直接调用父类的addAll()方法来实现
returnsuper.addAll(c);
}
…
}
显示更多
从上面代码可以看出,TreeSet的①号、②号构造器的都是新建一个TreeMap作为实际存储Set元素的容器,而另外2个构造器则分别依赖于①号和②号构造器,由此可见,TreeSet底层实际使用的存储容器就是TreeMap。
与HashSet完全类似的是,TreeSet里绝大部分方法都是直接调用TreeMap的方法来实现的,这一点读者可以自行参阅TreeSet的源代码,此处就不再给出了。
对于TreeMap而言,它采用一种被称为”红黑树”的排序二叉树来保存Map中每个Entry——每个Entry都被当成”红黑树”的一个节点对待。例如对于如下程序而言:
publicclassTreeMapTest
{
publicstaticvoidmain(String[]args)
{
TreeMap
newTreeMap
map.put(“ccc”,89.0);
map.put(“aaa”,80.0);
map.put(“zzz”,80.0);
map.put(“bbb”,89.0);
System.out.println(map);
}
}
显示更多
当程序执行map.put(“ccc”,89.0);时,系统将直接把“ccc”-89.0这个Entry放入Map中,这个Entry就是该”红黑树”的根节点。接着程序执行map.put(“aaa”,80.0);时,程序会将“aaa”-80.0作为新节点添加到已有的红黑树中。
以后每向TreeMap中放入一个key-value对,系统都需要将该Entry当成一个新节点,添加成已有红黑树中,通过这种方式就可保证TreeMap中所有key总是由小到大地排列。例如我们输出上面程序,将看到如下结果(所有key由小到大地排列):
{aaa=80.0,bbb=89.0,ccc=89.0,zzz=80.0}
显示更多
TreeMap的添加节点
对于TreeMap而言,由于它底层采用一棵”红黑树”来保存集合中的Entry,这意味这TreeMap添加元素、取出元素的性能都比HashMap低:当TreeMap添加元素时,需要通过循环找到新增Entry的插入位置,因此比较耗性能;当从TreeMap中取出元素时,需要通过循环才能找到合适的Entry,也比较耗性能。但TreeMap、TreeSet比HashMap、HashSet的优势在于:TreeMap中的所有Entry总是按key根据指定排序规则保持有序状态,TreeSet中所有元素总是根据指定排序规则保持有序状态。
红黑树
红黑树是一种自平衡排序二叉树,树中每个节点的值,都大于或等于在它的左子树中的所有节点的值,并且小于或等于在它的右子树中的所有节点的值,这确保红黑树运行时可以快速地在树中查找和定位的所需节点。
为了理解TreeMap的底层实现,必须先介绍排序二叉树和红黑树这两种数据结构。其中红黑树又是一种特殊的排序二叉树。
排序二叉树是一种特殊结构的二叉树,可以非常方便地对树中所有节点进行排序和检索。排序二叉树要么是一棵空二叉树,要么是具有下列性质的二叉树:
若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
它的左、右子树也分别为排序二叉树。
图1显示了一棵排序二叉树:
图1.排序二叉树
对排序二叉树,若按中序遍历就可以得到由小到大的有序序列。如图1所示二叉树,中序遍历得:
{2,3,4,8,9,9,10,13,15,18}
创建排序二叉树的步骤,也就是不断地向排序二叉树添加节点的过程,向排序二叉树添加节点的步骤如下:
1.以根节点当前节点开始搜索。
2.拿新节点的值和当前节点的值比较。
3.如果新节点的值更大,则以当前节点的右子节点作为新的当前节点;如果新节点的值更小,则以当前节点的左子节点作为新的当前节点。
4.重复2、3两个步骤,直到搜索到合适的叶子节点为止。
5.将新节点添加为第4步找到的叶子节点的子节点;如果新节点更大,则添加为右子节点;否则添加为左子节点。
掌握上面理论之后,下面我们来分析TreeMap添加节点(TreeMap中使用Entry内部类代表节点)的实现,TreeMap集合的put(Kkey,Vvalue)方法实现了将Entry放入排序二叉树中,下面是该方法的源代码:
publicVput(Kkey,Vvalue)
{
//先以t保存链表的root节点
Entry
//如果t==null,表明是一个空链表,即该TreeMap里没有任何Entry
if(t==null)
{
//将新的key-value创建一个Entry,并将该Entry作为root
root=newEntry
//设置该Map集合的size为1,代表包含一个Entry
size=1;
//记录修改次数为1
modCount++;
returnnull;
}
intcmp;
Entry
Comparator<?superK>cpr=comparator;
//如果比较器cpr不为null,即表明采用定制排序
if(cpr!=null)
{
do{
//使用parent上次循环后的t所引用的Entry
parent=t;
//拿新插入key和t的key进行比较
cmp=cpr.compare(key,t.key);
//如果新插入的key小于t的key,t等于t的左边节点
if(cmp<0)
t=t.left;
//如果新插入的key大于t的key,t等于t的右边节点
elseif(cmp>0)
t=t.right;
//如果两个key相等,新的value覆盖原有的value,
//并返回原有的value
else
returnt.setValue(value);
}while(t!=null);
显示更多
上面程序中粗体字代码就是实现”排序二叉树”的关键算法,每当程序希望添加新节点时:系统总是从树的根节点开始比较——即将根节点当成当前节点,如果新增节点大于当前节点、并且当前节点的右子节点存在,则以右子节点作为当前节点;如果新增节点小于当前节点、并且当前节点的左子节点存在,则以左子节点作为当前节点;如果新增节点等于当前节点,则用新增节点覆盖当前节点,并结束循环——直到找到某个节点的左、右子节点不存在,将新节点添加该节点的子节点——如果新节点比该节点大,则添加为右子节点;如果新节点比该节点小,则添加为左子节点。
TreeMap的删除节点
当程序从排序二叉树中删除一个节点之后,为了让它依然保持为排序二叉树,程序必须对该排序二叉树进行维护。维护可分为如下几种情况:
(1)被删除的节点是叶子节点,则只需将它从其父节点中删除即可。
(2)被删除节点p只有左子树,将p的左子树pL添加成p的父节点的左子树即可;被删除节点p只有右子树,将p的右子树pR添加成p的父节点的右子树即可。
(3)若被删除节点p的左、右子树均非空,有两种做法:
将pL设为p的父节点q的左或右子节点(取决于p是其父节点q的左、右子节点),将pR设为p节点的中序前趋节点s的右子节点(s是pL最右下的节点,也就是pL子树中最大的节点)。
以p节点的中序前趋或后继替代p所指节点,然后再从原排序二叉树中删去中序前趋或后继节点即可。(也就是用大于p的最小节点或小于p的最大节点代替p节点即可)。
图2显示了被删除节点只有左子树的示意图:
图2.被删除节点只有左子树
图3显示了被删除节点只有右子树的示意图:
图3.被删除节点只有右子树
图4显示了被删除节点既有左子节点,又有右子节点的情形,此时我们采用到是第一种方式进行维护:
图4.被删除节点既有左子树,又有右子树
图5显示了被删除节点既有左子树,又有右子树的情形,此时我们采用到是第二种方式进行维护:
图5.被删除节点既有左子树,又有右子树
TreeMap删除节点采用图5所示右边的情形进行维护——也就是用被删除节点的右子树中最小节点与被删节点交换的方式进行维护。
TreeMap删除节点的方法由如下方法实现:
privatevoiddeleteEntry(Entry
{
modCount++;
size—;
//如果被删除节点的左子树、右子树都不为空
if(p.left!=null&&p.right!=null)
{
//用p节点的中序后继节点代替p节点
Entry
p.key=s.key;
p.value=s.value;
p=s;
}
//如果p节点的左节点存在,replacement代表左节点;否则代表右节点。
Entry
if(replacement!=null)
{
replacement.parent=p.parent;
//如果p没有父节点,则replacemment变成父节点
if(p.parent==null)
root=replacement;
//如果p节点是其父节点的左子节点
elseif(p==p.parent.left)
p.parent.left=replacement;
//如果p节点是其父节点的右子节点
else
p.parent.right=replacement;
p.left=p.right=p.parent=null;
//修复红黑树
if(p.color==BLACK)
fixAfterDeletion(replacement);
}
//如果p节点没有父节点
显示更多
红黑树
排序二叉树虽然可以快速检索,但在最坏的情况下:如果插入的节点集本身就是有序的,要么是由小到大排列,要么是由大到小排列,那么最后得到的排序二叉树将变成链表:所有节点只有左节点(如果插入节点集本身是大到小排列);或所有节点只有右节点(如果插入节点集本身是小到大排列)。在这种情况下,排序二叉树就变成了普通链表,其检索效率就会很差。
为了改变排序二叉树存在的不足,RudolfBayer与1972年发明了另一种改进后的排序二叉树:红黑树,他将这种排序二叉树称为”对称二叉B树”,而红黑树这个名字则由LeoJ.Guibas和RobertSedgewick于1978年首次提出。
红黑树是一个更高效的检索二叉树,因此常常用来实现关联数组。典型地,JDK提供的集合类TreeMap本身就是一个红黑树的实现。
红黑树在原有的排序二叉树增加了如下几个要求:
性质1:每个节点要么是红色,要么是黑色。
性质2:根节点永远是黑色的。
性质3:所有的叶节点都是空节点(即null),并且是黑色的。
性质4:每个红色节点的两个子节点都是黑色。(从每个叶子到根的路径上不会有两个连续的红色节点)
性质5:从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。
Java实现的红黑树
上面的性质3中指定红黑树的每个叶子节点都是空节点,而且并叶子节点都是黑色。但Java实现的红黑树将使用null来代表空节点,因此遍历红黑树时将看不到黑色的叶子节点,反而看到每个叶子节点都是红色的。
Java中实现的红黑树可能有如图6所示结构:
图6.Java红黑树的示意
备注:本文中所有关于红黑树中的示意图采用白色代表红色。黑色节点还是采用了黑色表示。
根据性质5:红黑树从根节点到每个叶子节点的路径都包含相同数量的黑色节点,因此从根节点到叶子节点的路径中包含的黑色节点数被称为树的”黑色高度(black-height)”。
性质4则保证了从根节点到叶子节点的最长路径的长度不会超过任何其他路径的两倍。假如有一棵黑色
高度为3的红黑树:从根节点到叶节点的最短路径长度是2,该路径上全是黑色节点(黑节点–黑节点–黑节点)。最长路径也只可能为4,在每个黑色节点之间插入一个红色节点(黑节点–红节点–黑节点–红节点–黑节点),性质4保证绝不可能插入更多的红色节点。由此可见,红黑树中最长路径就是一条红黑交替的路径。
由此我们可以得出结论:对于给定的黑色高度为N的红黑树,从根到叶子节点的最短路径长度为N-1,最长路径长度为2*(N-1)。
提示:排序二叉树的深度直接影响了检索的性能,正如前面指出,当插入节点本身就是由小到大排列时,排序二叉树将变成一个链表,这种排序二叉树的检索性能最低:N个节点的二叉树深度就是N-1。
红黑树和平衡二叉树
红黑树并不是真正的平衡二叉树,但在实际应用中,红黑树的统计性能要高于平衡二叉树,但极端性能略差。
红黑树通过上面这种限制来保证它大致是平衡的——因为红黑树的高度不会无限增高,这样保证红黑树在最坏情况下都是高效的,不会出现普通排序二叉树的情况。
由于红黑树只是一个特殊的排序二叉树,因此对红黑树上的只读操作与普通排序二叉树上的只读操作完全相同,只是红黑树保持了大致平衡,因此检索性能比排序二叉树要好很多。
但在红黑树上进行插入操作和删除操作会导致树不再符合红黑树的特征,因此插入操作和删除操作都需要进行一定的维护,以保证插入节点、删除节点后的树依然是红黑树。
添加节点后的修复
上面put(Kkey,Vvalue)方法中①号代码处使用fixAfterInsertion(e)方法来修复红黑树——因此每
插入后的修复
在插入操作中,红黑树的性质1和性质3两个永远不会发生改变,因此无需考虑红黑树的这两个特性。
插入操作按如下步骤进行:
1.以排序二叉树的方法插入新节点,并将它设为红色。
2.进行颜色调换和树旋转。
这种颜色调用和树旋转就比较复杂了,下面将分情况进行介绍。在介绍中,我们把新插入的节点定义为N节点,N节点的父节点定义为P节点,P节点的兄弟节点定义为U节点,P节点父节点定义为G节点。
下面分成不同情形来分析插入操作
情形1:新节点N是树的根节点,没有父节点
在这种情形下,直接将它设置为黑色以满足性质2。
情形2:新节点的父节点P是黑色
在这种情况下,新插入的节点是红色的,因此依然满足性质4。而且因为新节点N有两个黑色叶子节点;但是由于新节点N是红色,通过它的每个子节点的路径依然保持相同的黑色节点数,因此依然满足性质5。
情形3:如果父节点P和父节点的兄弟节点U都是红色
在这种情况下,程序应该将P节点、U节点都设置为黑色,并将P节点的父节点设为红色(用来保持性质5)。现在新节点N有了一个黑色的父节点P。由于从P节点、U节点到根节点的任何路径都必须通过G节点,在这些路径上的黑节点数目没有改变(原来有叶子和G节点两个黑色节点,现在有叶子和P两个黑色节点)。
经过上面处理后,红色的G节点的父节点也有可能是红色的,这就违反了性质4,因此还需要对G节点递归地进行整个过程(把G当成是新插入的节点进行处理即可)。
图7显示了这种处理过程:
图7.插入节点后进行颜色调换
备注:虽然图11.28绘制的是新节点N作为父节点P左子节点的情形,其实新节点N作为父节点P右子节点的情况与图11.28完全相同。
情形4:父节点P是红色、而其兄弟节点U是黑色或缺少;且新节点N是父节点P的右子节点,而父节点P又是其父节点G的左子节点。
在这种情形下,我们进行一次左旋转对新节点和其父节点进行,接着按情形5处理以前的父节点P(也就是把P当成新插入的节点即可)。这导致某些路径通过它们以前不通过的新节点N或父节点P的其中之一,但是这两个节点都是红色的,因此不会影响性质5。
图8显示了对情形4的处理:
图8.插入节点后的树旋转
备注:图11.29中P节点是G节点的左子节点,如果P节点是其父节点G节点的右子节点,那么上面的处理情况应该左、右对调一下。
情形5:父节点P是红色、而其兄弟节点U是黑色或缺少;且新节点N是其父节点的左子节点,而父节点P又是其父节点G的左子节点。
在这种情形下,需要对节点G的一次右旋转,在旋转产生的树中,以前的父节点P现在是新节点N和节点G的父节点。由于以前的节点G是黑色,否则父节点P就不可能是红色,我们切换以前的父节点P和节点G的颜色,使之满足性质4,性质5也仍然保持满足,因为通过这三个节点中任何一个的所有路径以前都通过节点G,现在它们都通过以前的父节点P。在各自的情形下,这都是三个节点中唯一的黑色节点。
图9显示了情形5的处理过程:
图9.插入节点后的颜色调整、树旋转
备注:图11.30中P节点是G节点的左子节点,如果P节点是其父节点G节点的右子节点,那么上面的处理情况应该左、右对调一下。
TreeMap为插入节点后的修复操作由fixAfterInsertion(Entry
//插入节点后修复红黑树
privatevoidfixAfterInsertion(Entry
{
x.color=RED;
//直到x节点的父节点不是根,且x的父节点不是红色
while(x!=null&&x!=root
&&x.parent.color==RED)
{
//如果x的父节点是其父节点的左子节点
if(parentOf(x)==leftOf(parentOf(parentOf(x))))
{
//获取x的父节点的兄弟节点
Entry
//如果x的父节点的兄弟节点是红色
if(colorOf(y)==RED)
{
//将x的父节点设为黑色
setColor(parentOf(x),BLACK);
//将x的父节点的兄弟节点设为黑色
setColor(y,BLACK);
//将x的父节点的父节点设为红色
setColor(parentOf(parentOf(x)),RED);
x=parentOf(parentOf(x));
}
//如果x的父节点的兄弟节点是黑色
else
{
//如果x是其父节点的右子节点
if(x==rightOf(parentOf(x)))
{
//将x的父节点设为x
x=parentOf(x);
rotateLeft(x);
}
//把x的父节点设为黑色
setColor(parentOf(x),BLACK);
//把x的父节点的父节点设为红色
setColor(parentOf(parentOf(x)),RED);
rotateRight(parentOf(parentOf(x)));
}
}
//如果x的父节点是其父节点的右子节点
else
{
//获取x的父节点的兄弟节点
Entry
//如果x的父节点的兄弟节点是红色
if(colorOf(y)==RED)
{
//将x的父节点设为黑色。
setColor(parentOf(x),BLACK);
//将x的父节点的兄弟节点设为黑色
setColor(y,BLACK);
//将x的父节点的父节点设为红色
setColor(parentOf(parentOf(x)),RED);
//将x设为x的父节点的节点
x=parentOf(parentOf(x));
}
//如果x的父节点的兄弟节点是黑色
else
{
//如果x是其父节点的左子节点
if(x==leftOf(parentOf(x)))
{
//将x的父节点设为x
x=parentOf(x);
rotateRight(x);
}
//把x的父节点设为黑色
setColor(parentOf(x),BLACK);
//把x的父节点的父节点设为红色
setColor(parentOf(parentOf(x)),RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
//将根节点设为黑色
root.color=BLACK;
}
显示较少
删除节点后的修复
与添加节点之后的修复类似的是,TreeMap删除节点之后也需要进行类似的修复操作,通过这种修复来保证该排序二叉树依然满足红黑树特征。大家可以参考插入节点之后的修复来分析删除之后的修复。TreeMap在删除之后的修复操作由fixAfterDeletion(Entry
//删除节点后修复红黑树
privatevoidfixAfterDeletion(Entry
{
//直到x不是根节点,且x的颜色是黑色
while(x!=root&&colorOf(x)==BLACK)
{
//如果x是其父节点的左子节点
if(x==leftOf(parentOf(x)))
{
//获取x节点的兄弟节点
Entry
//如果sib节点是红色
if(colorOf(sib)==RED)
{
//将sib节点设为黑色
setColor(sib,BLACK);
//将x的父节点设为红色
setColor(parentOf(x),RED);
rotateLeft(parentOf(x));
//再次将sib设为x的父节点的右子节点
sib=rightOf(parentOf(x));
}
//如果sib的两个子节点都是黑色
if(colorOf(leftOf(sib))==BLACK
&&colorOf(rightOf(sib))==BLACK)
{
//将sib设为红色
setColor(sib,RED);
//让x等于x的父节点
x=parentOf(x);
}
else
{
//如果sib的只有右子节点是黑色
if(colorOf(rightOf(sib))==BLACK)
{
//将sib的左子节点也设为黑色
setColor(leftOf(sib),BLACK);
//将sib设为红色
setColor(sib,RED);
rotateRight(sib);
sib=rightOf(parentOf(x));
}
//设置sib的颜色与x的父节点的颜色相同
setColor(sib,colorOf(parentOf(x)));
//将x的父节点设为黑色
setColor(parentOf(x),BLACK);
//将sib的右子节点设为黑色
setColor(rightOf(sib),BLACK);
rotateLeft(parentOf(x));
x=root;
}
}
//如果x是其父节点的右子节点
else
{
//获取x节点的兄弟节点
Entry
//如果sib的颜色是红色
if(colorOf(sib)==RED)
{
//将sib的颜色设为黑色
setColor(sib,BLACK);
//将sib的父节点设为红色
setColor(parentOf(x),RED);
rotateRight(parentOf(x));
sib=leftOf(parentOf(x));
}
//如果sib的两个子节点都是黑色
if(colorOf(rightOf(sib))==BLACK
&&colorOf(leftOf(sib))==BLACK)
{
//将sib设为红色
setColor(sib,RED);
//让x等于x的父节点
x=parentOf(x);
}
else
{
//如果sib只有左子节点是黑色
if(colorOf(leftOf(sib))==BLACK)
{
//将sib的右子节点也设为黑色
setColor(rightOf(sib),BLACK);
//将sib设为红色
setColor(sib,RED);
rotateLeft(sib);
sib=leftOf(parentOf(x));
}
//将sib的颜色设为与x的父节点颜色相同
setColor(sib,colorOf(parentOf(x)));
//将x的父节点设为黑色
setColor(parentOf(x),BLACK);
//将sib的左子节点设为黑色
setColor(leftOf(sib),BLACK);
rotateRight(parentOf(x));
x=root;
}
}
}
setColor(x,BLACK);
}
检索节点
当TreeMap根据key来取出value时,TreeMap对应的方法如下:
publicVget(Objectkey)
{
//根据指定key取出对应的Entry
Entry>K,V
return(p==null?null:p.value);
}
显示较少
从上面程序的粗体字代码可以看出,get(Objectkey)方法实质是由于getEntry()方法实现的,这个getEntry()方法的代码如下:
finalEntry
{
//如果comparator不为null,表明程序采用定制排序
if(comparator!=null)
//调用getEntryUsingComparator方法来取出对应的key
returngetEntryUsingComparator(key);
//如果key形参的值为null,抛出NullPointerException异常
if(key==null)
thrownewNullPointerException();
//将key强制类型转换为Comparable实例
Comparable<?superK>k=(Comparable<?superK>)key;
//从树的根节点开始
Entry
while(p!=null)
{
//拿key与当前节点的key进行比较
intcmp=k.compareTo(p.key);
//如果key小于当前节点的key,向”左子树”搜索
if(cmp<0)
p=p.left;
//如果key大于当前节点的key,向”右子树”搜索
elseif(cmp>0)
p=p.right;
//不大于、不小于,就是找到了目标Entry
else
returnp;
}
returnnull;
显示较少
上面的getEntry(Objectobj)方法也是充分利用排序二叉树的特征来搜索目标Entry,程序依然从二叉树的根节点开始,如果被搜索节点大于当前节点,程序向”右子树”搜索;如果被搜索节点小于当前节点,程序向”左子树”搜索;如果相等,那就是找到了指定节点。
当TreeMap里的comparator!=null即表明该TreeMap采用了定制排序,在采用定制排序的方式下,TreeMap采用getEntryUsingComparator(key)方法来根据key获取Entry。下面是该方法的代码:
finalEntry
{
Kk=(K)key;
//获取该TreeMap的comparator
Comparator<?superK>cpr=comparator;
if(cpr!=null)
{
//从根节点开始
Entry
while(p!=null)
{
//拿key与当前节点的key进行比较
intcmp=cpr.compare(k,p.key);
//如果key小于当前节点的key,向”左子树”搜索
if(cmp<0)
p=p.left;
//如果key大于当前节点的key,向”右子树”搜索
elseif(cmp>0)
p=p.right;
//不大于、不小于,就是找到了目标Entry
else
returnp;
}
}
returnnull;
}
显示较少
其实getEntry、getEntryUsingComparator两个方法的实现思路完全类似,只是前者对自然排序的TreeMap获取有效,后者对定制排序的TreeMap有效。
通过上面源代码的分析不难看出,TreeMap这个工具类的实现其实很简单。或者说:从内部结构来看,TreeMap本质上就是一棵”红黑树”,而TreeMap的每个Entry就是该红黑树的一个节点。
Java异常分类及处理
如果某个方法不能按照正常的途径完成任务,就可以通过另一种路径退出方法。在这种情况下会抛出一个封装了错误信息的对象。此时,这个方法会立刻退出同时不返回任何值。另外,调用这个方法的其他代码也无法继续执行,异常处理机制会将代码执行交给异常处理器。
异常分类
Throwable是Java语言中所有错误或异常的超类。下一层分为Error和Exception
Error
1.Error类是指Java运行时系统的内部错误和资源耗尽错误。应用程序不会抛出该类对象。如果出现
了这样的错误,除了告知用户,剩下的就是尽力使程序安全的终止。
Exception(RuntimeException、CheckedException)
2.Exception又有两个分支,一个是运行时异常RuntimeException,一个是ckedException。
RuntimeException如:NullPointerException、ClassCastException;一个是检查异常CheckedException,如I/O错误导致的IOException、SQLException。RuntimeException是那些可能在Java虚拟机正常运行期间抛出的异常的超类。如果出现RuntimeException,那么一定是程序员的错误.
检查异常CheckedException:一般是外部错误,这种异常都发生在编译阶段,Java编译器会强制程序去捕获此类异常,即会出现要求你把这段可能出现异常的程序进行trycatch,该类异常一般包括几个方面:
1.试图在文件尾部读取数据
2.试图打开一个错误格式的URL
3.试图根据给定的字符串查找class对象,而这个字符串表示的类并不存在
异常的处理方式
遇到问题不进行具体处理,而是继续抛给调用者(throw,throws)抛出异常有三种形式,一是throw,一个throws,还有一种系统自动抛异常。
trycatch捕获异常针对性处理方式
Throw和throws的区别:
位置不同
1.throws用在函数上,后面跟的是异常类,可以跟多个;而throw用在函数内,后面跟的是异常对象。
功能不同:
2.throws用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先的处理方式;throw抛出具体的问题对象,执行到throw,功能就已经结束了,跳转到调用者,并将具体的问题对象抛给调用者。也就是说throw语句独立存在时,下面不要定义其他语句,因为执行不到。
3.throws表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某种异常对象。
4.两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
Java反射
动态语言
动态语言,是指程序在运行时可以改变其结构:新的函数可以引进,已有的函数可以被删除等结
构上的变化。比如常见的JavaScript就是动态语言,除此之外Ruby,Python等也属于动态语言,而C、C++则不属于动态语言。从反射角度说Java属于半动态语言。
反射机制概念(运行状态中知道类所有的属性和方法)
在Java中的反射机制是指在运行状态中,对于任意一个类都能够知道这个类所有的属性和方法;并且对于任意一个对象,都能够调用它的任意一个方法;这种动态获取信息以及动态调用对象方法的功能成为Java语言的反射机制。
编译时类型和运行时类型
在Java程序中许多对象在运行是都会出现两种类型:编译时类型和运行时类型。编译时的类型由声明对象时实用的类型来决定,运行时的类型由实际赋值给对象的类型决定。如:
Personp=newStudent();其中编译时类型为Person,运行时类型为Student。
的编译时类型无法获取具体方法
程序在运行时还可能接收到外部传入的对象,该对象的编译时类型为Object,但是程序有需要调用该对象的运行时类型的方法。为了解决这些问题,程序需要在运行时发现对象和类的真实信息。然而,如果编译时根本无法预知该对象和类属于哪些类,程序只能依靠运行时信息来发现该对象和类的真实信息,此时就必须使用到反射了。
Java反射API
反射API用来生成JVM中的类、接口或则对象的信息。
1.Class类:反射的核心类,可以获取类的属性,方法等信息。
2.Field类:Java.lang.reflec包中的类,表示类的成员变量,可以用来获取和设置类之中的属性值。
3.Method类:Java.lang.reflec包中的类,表示类的方法,它可以用来获取类中的方法信息或者执行方法。
4.Constructor类:Java.lang.reflec包中的类,表示类的构造方法。
反射使用步骤(获取Class对象、调用对象方法)
1.获取想要操作的类的Class对象,他是反射的核心,通过Class对象我们可以任意调用类的方法。
2.调用Class类中的方法,既就是反射的使用阶段。
3.使用反射API来操作这些信息。
获取Class对象的3种方法
调用某个对象的getClass()方法
Personp=newPerson();
Classclazz=p.getClass();
调用某个类的class属性来获取该类对应的Class对象
Classclazz=Person.class;
使用Class类中的forName()静态方法(最安全/性能最好)
Classclazz=Class.forName(“类的全路径”);(最常用)
当我们获得了想要操作的类的Class对象后,可以通过Class类中的方法获取并查看该类中的方法和属性。
//获取Person类的Class对象
Classclazz=Class.forName(“reflection.Person”);
//获取Person类的所有方法信息
Method[]method=clazz.getDeclaredMethods();
for(Methodm:method){
System.out.println(m.toString());
}
//获取Person类的所有成员属性信息
Field[]field=clazz.getDeclaredFields();
f:field){
System.out.println(f.toString());
Java注解
概念
Annotation(注解)是Java提供的一种对元程序中元素关联信息和元数据(metadata)的途径和方法。Annatation(注解)是一个接口,程序可以通过反射来获取指定程序中元素的Annotation对象,然后通过该Annotation对象来获取注解中的元数据信息。
4种标准元注解
元注解的作用是负责注解其他注解。Java5.0定义了4个标准的meta-annotation类型,它们被用来提供对其它annotation类型作说明。
@Target修饰的对象范围
@Target说明了Annotation所修饰的对象范围:Annotation可被用于packages、types(类、接口、枚举、Annotation类型)、类型成员(方法、构造方法、成员变量、枚举值)、方法参数和本地变量(如循环变量、catch参数)。在Annotation类型的声明中使用了target可更加明晰其修饰的目标
@Retention定义被保留的时间长短
Retention定义了该Annotation被保留的时间长短:表示需要在什么级别保存注解信息,用于描述注解的生命周期(即:被描述的注解在什么范围内有效),取值(RetentionPoicy)由:
nSOURCE:在源文件中有效(即源文件保留)
nCLASS:在class文件中有效(即class保留)
nRUNTIME:在运行时有效(即运行时保留)
@Documented描述-Javadoc
@Documented用于描述其它类型的annotation应该被作为被标注的程序成员的公共API,因此可以被例如Javadoc此类的工具文档化。
@Inherited阐述了某个被标注的类型是被继承的
@Inherited元注解是一个标记注解,@Inherited阐述了某个被标注的类型是被继承的。如果一个使用了@Inherited修饰的annotation类型被用于一个class,则这个annotation将被用于该class的子类。
注解处理器
如果没有用来读取注解的方法和工作,那么注解也就不会比注释更有用处了。使用注解的过程中,很重要的一部分就是创建于使用注解处理器。JavaSE5扩展了反射机制的API,以帮助程序员快速的构造自定义注解处理器。下面实现一个注解处理器。
/1:定义注解*/
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public@interfaceFruitProvider{
/供应商编号/
publicintid()default-1;
/**供应商名称/
publicStringname()default””
Java内部类
Java类中不仅可以定义变量和方法,还可以定义类,这样定义在类内部的类就被称为内部类。根据定义的方式不同,内部类分为静态内部类,成员内部类,局部内部类,匿名内部类四种。
静态内部类
定义在类内部的静态类,就是静态内部类。
publicclassOut{
privatestaticinta;
privateintb;
publicstaticclassInner{
publicvoidprint(){
System.out.println(a);
}
}}
1.静态内部类可以访问外部类所有的静态变量和方法,即使是private的也一样。
2.静态内部类和一般类一致,可以定义静态变量、方法,构造方法等。
3.其它类使用静态内部类需要使用“外部类.静态内部类”方式,如下所示:Out.Innerinner=newOut.Inner();inner.print();
4.Java集合类HashMap内部就有一个静态内部类Entry。Entry是HashMap存放元素的抽象,HashMap内部维护Entry数组用了存放元素,但是Entry对使用者是透明的。像这种和外部类关系密切的,且不依赖外部类实例的,都可以使用静态内部类。
成员内部类
定义在类内部的非静态类,就是成员内部类。成员内部类不能定义静态方法和变量(final修饰的除外)。这是因为成员内部类是非静态的,类初始化的时候先初始化静态成员,如果允许成员内部类定义静态变量,那么成员内部类的静态变量初始化顺序是有歧义的。
publicclassOut{
privatestaticinta;
privateintb;
publicclassInner{
publicvoidprint(){
System.out.println(a);
System.out.println(b);
}
}
}
局部内部类(定义在方法中的类)
定义在方法中的类,就是局部类。如果一个类只在某个方法中使用,则可以考虑使用局部类。
publicclassOut{
privatestaticinta;
privateintb;
publicvoidtest(finalintc){
finalintd=1;
classInner{
publicvoidprint(){
System.out.println(c);
}
}
}
}
匿名内部类(要继承一个父类或者实现一个接口、直接使用new来生成一个对象的引用)
匿名内部类我们必须要继承一个父类或者实现一个接口,当然也仅能只继承一个父类或者实现一个接口。同时它也是没有class关键字,这是因为匿名内部类是直接使用new来生成一个对象的引用。
publicabstractclassBird{
privateStringname;
publicStringgetName(){
returnname;
}
publicvoidsetName(Stringname){
this.name=name;
Java泛型
泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。比如我们要写一个排序方法,能够对整型数
组、字符串数组甚至其他任何类型的数组进行排序,我们就可以使用Java泛型。
泛型方法()
你可以写一个泛型方法,该方法在调用时可以接收不同类型的参数。根据传递给泛型方法的参数类型,编译器适当地处理每一个方法调用。
//泛型方法printArray
publicstatic
{
for(Eelement:inputArray){
System.out.printf(“%s”,element);
}
}
1.<?extendsT>表示该通配符所代表的类型是T类型的子类。
2.<?superT>表示该通配符所代表的类型是T类型的父类。
泛型类
泛型类的声明和非泛型类的声明类似,除了在类名后面添加了类型参数声明部分。和泛型方法一样,泛型类的类型参数声明部分也包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。因为他们接受一个或多个参数,这些类被称为参数化的类或参数化的类型。
类型通配符?
类型通配符一般是使用?代替具体的类型参数。例如List<?>在逻辑上是List,List等所有List<具体类型实参>的父类。
类型擦除
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节代码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会被编译器在编译的时候去掉。这个过程就称为类型擦除。如在代码中定义的List和List等类型,在编译之后都会变成List。JVM看到的只是List,而由泛型附加的类型信息对JVM来说是不可见的。
类型擦除的基本过程也比较简单,首先是找到用来替换类型参数的具体类。这个具体类一般是Object。如果指定了类型参数的上界的话,则使用这个上界。把代码中的类型参数都替换成具体的类。
Java序列化(创建可复用的Java对象)
保存(持久化)对象及其状态到内存或者磁盘
Java平台允许我们在内存中创建可复用的Java对象,但一般情况下,只有当JVM处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比JVM的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。
Java对象序列化就能够帮助我们实现该功能。
序列化对象以字节数组保持-静态成员不保存
使用Java对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
序列化用户远程对象传输
除了在持久化对象时会用到对象序列化之外,当使用RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。Java序列化API为处理对象序列化提供了一个标准机制,该API简单易用。
Serializable实现序列化
在Java中,只要一个类实现了Java.io.Serializable接口,那么它就可以被序列化。
ObjectOutputStream和ObjectInputStream对对象进行序列化及反序列化
通过ObjectOutputStream和ObjectInputStream对对象进行序列化及反序列化。
writeObject和readObject自定义序列化策略
在类中增加writeObject和readObject方法可以实现自定义序列化策略。
序列化ID
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化ID是否一致(就是privatestaticfinallongserialVersionUID)
序列化并不保存静态变量序列化子父类说明
要想将父类对象也序列化,就需要让父类也实现Serializable接口。
Transient关键字阻止该变量被序列化到文件中
1.在变量声明前加上Transient关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient变量的值被设为初始值,如int型的是0,对象型的是null。
2.服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
Java复制
将一个对象的引用复制给另外一个对象,一共有三种方式。第一种方式是直接赋值,第二种方式是浅拷贝,第三种是深拷贝。所以大家知道了哈,这三种概念实际上都是为了拷贝对象。
直接赋值复制
直接赋值。在Java中,Aa1=a2,我们需要理解的是这实际上复制的是引用,也就是说a1和a2指向的是同一个对象。因此,当a1变化的时候,a2里面的成员变量也会跟着变化。
浅复制(复制引用但不复制引用的对象)
创建一个新对象,然后将当前对象的非静态字段复制到该新对象,如果字段是值类型的,那么对该字段执行复制;如果该字段是引用类型的话,则复制引用但不复制引用的对象。
因此,原始对象及其副本引用同一个对象。
classResumeimplementsCloneable{
publicObjectclone(){
try{
return(Resume)super.clone();
}catch(Exceptione){
e.printStackTrace();
returnnull;
}
}
}
深复制(复制对象和其应用对象)
深拷贝不仅复制对象本身,而且复制对象包含的引用指向的所有对象。
classStudentimplementsCloneable{
Stringname;
intage;
Professorp;
Student(Stringname,intage,Professorp){
this.name=name;
this.age=age;
this.p=p;
}
publicObjectclone(){
Studento=null;
序列化(深clone一中实现)
在Java语言里深复制一个对象,常常可以先使对象实现Serializable接口,然后把对象(实际上只是对
象的一个拷贝)写到一个流里,再从流里读出来,便可以重建对象。
Java9比Java8改进了什么;
1)引入了模块系统,采用模块化系统的应用程序只需要这些应用程序所需的那部分JDK模块,而非是整个JDK框架了,减少了内存的开销。
2)引入了一个新的package:Java.net.http,里面提供了对Http访问很好的支持,不仅支持Http1.1而且还支持HTTP2。
3)引入了jshell这个交互性工具,让Java也可以像脚本语言一样来运行,可以从控制台启动jshell,在jshell中直接输入表达式并查看其执行结果。
4)增加了List.of()、Set.of()、Map.of()和Map.ofEntries()等工厂方法来创建不可变集合5)HTML5风格的Java帮助文档
6)多版本兼容JAR功能,能让你创建仅在特定版本的Java环境中运行库程序时选择使用的class版本。
7)统一JVM日志
可以使用新的命令行选项-Xlog来控制JVM上所有组件的日志记录。该日志记录系统可以设置输出的日志消息的标签、级别、修饰符和输出目标等。
8)垃圾收集机制Java9移除了在Java8中被废弃的垃圾回收器配置组合,同时把G1设为默认的垃圾回收器实现.因为相对于Parallel来说,G1会在应用线程上做更多的事情,而Parallel几乎没有在应用线程上做任何事情,它基本上完全依赖GC线程完成所有的内存管理。这意味着切换到G1将会为应用线程带来额外的工作,从而直接影响到应用的性能
9)I/O流新特性Java.io.InputStream中增加了新的方法来读取和复制InputStream中包含的数据。readAllBytes:读取InputStream中的所有剩余字节。readNBytes:从InputStream中读取指定数量的字节到数组中。transferTo:读取InputStream中的全部字节并写入到指定的OutputStream中。
Java8十大新特性详解
本教程将Java8的新特新逐一列出,并将使用简单的代码示例来指导你如何使用默认接口方法,lambda表达式,方法引用以及多重Annotation,之后你将会学到最新的API上的改进,比如流,函数式接口,Map以及全新的日期API
“Javaisstillnotdead—andpeoplearestartingtofigurethatout.”
本教程将用带注释的简单代码来描述新特性,你将看不到大片吓人的文字。
一、接口的默认方法
Java8允许我们给接口添加一个非抽象的方法实现,只需要使用default关键字即可,这个特征又叫做扩展方法,示例如下:
代码如下:
interfaceFormula{
doublecalculate(inta);
defaultdoublesqrt(inta){
returnMath.sqrt(a);
}
}
Formula接口在拥有calculate方法之外同时还定义了sqrt方法,实现了Formula接口的子类只需要实现一个calculate方法,默认方法sqrt将在子类上可以直接使用。
代码如下:
Formulaformula=newFormula(){
@Override
publicdoublecalculate(inta){
returnsqrt(a*100);
}
};
formula.calculate(100);//100.0
formula.sqrt(16);//4.0
文中的formula被实现为一个匿名类的实例,该代码非常容易理解,6行代码实现了计算sqrt(a*100)。在下一节中,我们将会看到实现单方法接口的更简单的做法。
译者注:在Java中只有单继承,如果要让一个类赋予新的特性,通常是使用接口来实现,在C++中支持多继承,允许一个子类同时具有多个父类的接口与功能,在其他语言中,让一个类同时具有其他的可复用代码的方法叫做mixin。新的Java8的这个特新在编译器实现的角度上来说更加接近Scala的trait。在C#中也有名为扩展方法的概念,允许给已存在的类型扩展方法,和Java8的这个在语义上有差别。
二、Lambda表达式
首先看看在老版本的Java中是如何排列字符串的:
代码如下:
Listnames=Arrays.asList(“peterF”,”anna”,”mike”,”xenia”);
Collections.sort(names,newComparator(){
@Override
publicintcompare(Stringa,Stringb){
returnb.compareTo(a);
}
});
只需要给静态方法Collections.sort传入一个List对象以及一个比较器来按指定顺序排列。通常做法都是创建一个匿名的比较器对象然后将其传递给sort方法。
在Java8中你就没必要使用这种传统的匿名对象的方式了,Java8提供了更简洁的语法,lambda表达式:
代码如下:
Collections.sort(names,(Stringa,Stringb)->{
returnb.compareTo(a);
});
看到了吧,代码变得更段且更具有可读性,但是实际上还可以写得更短:
代码如下:
Collections.sort(names,(Stringa,Stringb)->b.compareTo(a));
对于函数体只有一行代码的,你可以去掉大括号{}以及return关键字,但是你还可以写得更短点:代码如下:
Collections.sort(names,(a,b)->b.compareTo(a));
Java编译器可以自动推导出参数类型,所以你可以不用再写一次类型。接下来我们看看lambda表达式还能作出什么更方便的东西来:
三、函数式接口
Lambda表达式是如何在Java的类型系统中表示的呢?每一个lambda表达式都对应一个类型,通常是接口类型。而“函数式接口”是指仅仅只包含一个抽象方法的接口,每一个该类型的lambda表达式都会被匹配到这个抽象方法。因为默认方法不算抽象方法,所以你也可以给你的函数式接口添加默认方法。
我们可以将lambda表达式当作任意只包含一个抽象方法的接口类型,确保你的接口一定达到这个要求,你只需要给你的接口添加@FunctionalInterface注解,编译器如果发现你标注了这个注解的接口有多于一个抽象方法的时候会报错的。
示例如下:
代码如下:
@FunctionalInterface
interfaceConverter
Tconvert(Ffrom);
}
Converter
Integerconverted=converter.convert(“123”);
System.out.println(converted);//123
需要注意如果@FunctionalInterface如果没有指定,上面的代码也是对的。
译者注将lambda表达式映射到一个单方法的接口上,这种做法在Java8之前就有别的语言实现,比如RhinoJavaScript解释器,如果一个函数参数接收一个单方法的接口而你传递的是一个function,Rhino解释器会自动做一个单接口的实例到function的适配器,典型的应用场景有
org.w3c.dom.events.EventTarget的addEventListener第二个参数EventListener。
四、方法与构造函数引用
前一节中的代码还可以通过静态方法引用来表示:
代码如下:
Converter
Integerconverted=converter.convert(“123”);
System.out.println(converted);//123
Java8允许你使用::关键字来传递方法或者构造函数引用,上面的代码展示了如何引用一个静态方法,我们也可以引用一个对象的方法:
代码如下:
converter=something::startsWith;
Stringconverted=converter.convert(“Java”);
System.out.println(converted);//“J”
接下来看看构造函数是如何使用::关键字来引用的,首先我们定义一个包含多个构造函数的简单类:代码如下:
classPerson{
StringfirstName;
StringlastName;
Person(){}
Person(StringfirstName,StringlastName){
this.firstName=firstName;
this.lastName=lastName;
}
}
接下来我们指定一个用来创建Person对象的对象工厂接口:
代码如下:
{
Pcreate(StringfirstName,StringlastName);
}
这里我们使用构造函数引用来将他们关联起来,而不是实现一个完整的工厂:
代码如下:
PersonFactorypersonFactory=Person::new;
Personperson=personFactory.create(“Peter”,”Parker”);
我们只需要使用Person::new来获取Person类构造函数的引用,Java编译器会自动根据PersonFactory.create方法的签名来选择合适的构造函数。
五、Lambda作用域
在lambda表达式中访问外层作用域和老版本的匿名对象中的方式很相似。你可以直接访问标记了final的外层局部变量,或者实例的字段以及静态变量。
六、访问局部变量
我们可以直接在lambda表达式中访问外层的局部变量:
代码如下:
finalintnum=1;
Converter
(from)->String.valueOf(from+num);
StringConverter.convert(2);//3
但是和匿名对象不同的是,这里的变量num可以不用声明为final,该代码同样正确:代码如下:
intnum=1;
Converter
(from)->String.valueOf(from+num);
StringConverter.convert(2);//3
不过这里的num必须不可被后面的代码修改(即隐性的具有final的语义),例如下面的就无法编译:代码如下:
intnum=1;
Converter
(from)->String.valueOf(from+num);
num=3;
在lambda表达式中试图修改num同样是不允许的。
}
}
八、访问接口的默认方法
还记得第一节中的formula例子么,接口Formula定义了一个默认方法sqrt可以直接被formula的实例包括匿名对象访问到,但是在lambda表达式中这个是不行的。
Lambda表达式中是无法访问到默认方法的,以下代码将无法编译:
代码如下:
Formulaformula=(a)->sqrt(a*100);
Built-inFunctionalInterfaces
JDK1.8API包含了很多内建的函数式接口,在老Java中常用到的比如Comparator或者Runnable接口,这些接口都增加了@FunctionalInterface注解以便能用在lambda上。
Java8API同样还提供了很多全新的函数式接口来让工作更加方便,有一些接口是来自GoogleGuava库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
Predicate接口
Predicate接口只有一个参数,返回boolean类型。该接口包含多种默认方法来将Predicate组合成其他复杂的逻辑(比如:与,或,非):
代码如下:
Predicatepredicate=(s)->s.length()>0;
predicate.test(“foo”);//true
predicate.negate().test(“foo”);//false
PredicatenonNull=Objects::nonNull;
PredicateisNull=Objects::isNull;
PredicateisEmpty=String::isEmpty;
PredicateisNotEmpty=isEmpty.negate();
Function接口
Function接口有一个参数并且返回一个结果,并附带了一些可以和其他函数组合的默认方法 (compose,andThen):
代码如下:
Function
Function
backToString.apply(“123”);//“123”
Supplier接口
Supplier接口返回一个任意范型的值,和Function接口不同的是该接口没有任何参数代码如下:
SupplierpersonSupplier=Person::new;
personSupplier.get();//newPerson
Consumer接口
Consumer接口表示执行在单个参数上的操作。
代码如下:
Consumergreeter=(p)->System.out.println(“Hello,”+p.firstName);
greeter.accept(newPerson(“Luke”,”Skywalker”));
Comparator接口
Comparator是老Java中的经典接口,Java8在此之上添加了多种默认方法:
代码如下:
Comparatorcomparator=(p1,p2)->p1.firstName.compareTo(p2.firstName);
Personp1=newPerson(“John”,”Doe”);
Personp2=newPerson(“Alice”,”Wonderland”);
comparator.compare(p1,p2);//>0
comparator.reversed().compare(p1,p2);//<0
Optional接口
Optional不是函数是接口,这是个用来防止NullPointerException异常的辅助类型,这是下一届中将要用到的重要概念,现在先简单的看看这个接口能干什么:
Optional被定义为一个简单的容器,其值可能是null或者不是null。在Java8之前一般某个函数应该返回
非空对象但是偶尔却可能返回了null,而在Java8中,不推荐你返回null而是返回Optional。代码如下:
Optionaloptional=Optional.of(“bam”);
optional.isPresent();//true
optional.get();//“bam”
optional.orElse(“fallback”);//“bam”
optional.ifPresent((s)->System.out.println(s.charAt(0)));//“b”
Stream接口
Java.util.Stream表示能应用在一组元素上一次执行的操作序列。Stream操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,这样你就可以将多个操作依次串起来。Stream的创建需要指定一个数据源,比如Java.util.Collection的子类,List或者Set,Map不支持。Stream的操作可以串行执行或者并行执行。
首先看看Stream是怎么用,首先创建实例代码的用到的数据List:
代码如下:
ListStringCollection=newArrayList<>();
StringCollection.add(“ddd2”);
StringCollection.add(“aaa2”);
StringCollection.add(“bbb1”);
StringCollection.add(“aaa1”);
StringCollection.add(“bbb3”);
StringCollection.add(“ccc”);
StringCollection.add(“bbb2”);
StringCollection.add(“ddd1”);
Java8扩展了集合类,可以通过Collection.stream()或者Collection.parallelStream()来创建一个Stream。下面几节将详细解释常用的Stream操作:
过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于中间操作,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。
代码如下:
StringCollection
.stream()
.filter((s)->s.startsWith(“a”))
.forEach(System.out::println);
//“aaa2”,”aaa1”
Sort排序
排序是一个中间操作,返回的是排序好后的Stream。如果你不指定一个自定义的Comparator则会使用默认排序。
代码如下:
StringCollection
.stream()
.sorted()
.filter((s)->s.startsWith(“a”))
.forEach(System.out::println);
//“aaa1”,”aaa2”
需要注意的是,排序只创建了一个排列好后的Stream,而不会影响原有的数据源,排序之后原数据StringCollection是不会被修改的:
代码如下:
System.out.println(StringCollection);
//ddd2,aaa2,bbb1,aaa1,bbb3,ccc,bbb2,ddd1
Map映射
中间操作map会将元素根据指定的Function接口来依次将元素转成另外的对象,下面的示例展示了将字符串转换为大写字符串。你也可以通过map来讲对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
代码如下:
StringCollection
.stream()
.map(String::toUpperCase)
.sorted((a,b)->b.compareTo(a))
.forEach(System.out::println);
//“DDD2”,”DDD1”,”CCC”,”BBB3”,”BBB2”,”AAA2”,”AAA1”
Match匹配
Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配整个Stream。所有的匹配操作都是最终操作,并返回一个boolean类型的值。
代码如下:
booleananyStartsWithA=
StringCollection
.stream()
.anyMatch((s)->s.startsWith(“a”));
System.out.println(anyStartsWithA);//true
booleanallStartsWithA=
StringCollection
.stream()
.allMatch((s)->s.startsWith(“a”));
System.out.println(allStartsWithA);//false
booleannoneStartsWithZ=
StringCollection
.stream()
.noneMatch((s)->s.startsWith(“z”));
System.out.println(noneStartsWithZ);//true
Count计数
计数是一个最终操作,返回Stream中元素的个数,返回值类型是long。
代码如下:
longstartsWithB=
StringCollection
.stream()
.filter((s)->s.startsWith(“b”))
.count();
System.out.println(startsWithB);//3
Reduce规约
这是一个最终操作,允许通过指定的函数来讲stream中的多个元素规约为一个元素,规越后的结果是通过Optional接口表示的:
代码如下:
Optionalreduced=
StringCollection
.stream()
.sorted()
.reduce((s1,s2)->s1+”#”+s2);
reduced.ifPresent(System.out::println);
//“aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2”
并行Streams
前面提到过Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
下面的例子展示了是如何通过并行Stream来提升性能:
首先我们创建一个没有重复元素的大表:
代码如下:
intmax=1000000;
Listvalues=newArrayList<>(max);
for(inti=0;i
values.add(uuid.toString());
}
然后我们计算一下排序这个Stream要耗时多久,
串行排序:
代码如下:
longt0=System.nanoTime();
longcount=values.stream().sorted().count();
System.out.println(count);
longt1=System.nanoTime();
longmillis=TimeUnit.NANOSECONDS.toMillis(t1-t0);
System.out.println(String.format(“sequentialsorttook:%dms”,millis));
//串行耗时:899ms
并行排序:
代码如下:
longt0=System.nanoTime();
longcount=values.parallelStream().sorted().count();
System.out.println(count);
longt1=System.nanoTime();
longmillis=TimeUnit.NANOSECONDS.toMillis(t1-t0);
System.out.println(String.format(“parallelsorttook:%dms”,millis));
//并行排序耗时:472ms
上面两个代码几乎是一样的,但是并行版的快了50%之多,唯一需要做的改动就是将stream()改为parallelStream()。
Map
前面提到过,Map类型不支持stream,不过Map提供了一些新的有用的方法来处理一些日常任务。代码如下:
Map
for(inti=0;i<10;i++){
map.putIfAbsent(i,”val”+i);
}
map.forEach((id,val)->System.out.println(val));
以上代码很容易理解,putIfAbsent不需要我们做额外的存在性检查,而forEach则接收一个Consumer接口来对map里的每一个键值对进行操作。
下面的例子展示了map上的其他有用的函数:
代码如下:
map.computeIfPresent(3,(num,val)->val+num);
map.get(3);//val33
map.computeIfPresent(9,(num,val)->null);
map.containsKey(9);//false
map.computeIfAbsent(23,num->”val”+num);
map.containsKey(23);//true
map.computeIfAbsent(3,num->”bam”);
map.get(3);//val33
接下来展示如何在Map里删除一个键值全都匹配的项:
代码如下:
map.remove(3,”val3”);
map.get(3);//val33
另外一个有用的方法:
代码如下:
map.getOrDefault(42,”notfound”);//notfound
对Map的元素做合并也变得很容易了:
代码如下:
map.merge(9,”val9”,(value,newValue)->value.concat(newValue));
map.get(9);//val9
map.merge(9,”concat”,(value,newValue)->value.concat(newValue));
map.get(9);//val9concat
Merge做的事情是如果键名不存在则插入,否则则对原键对应的值做合并操作并重新插入到map中。
九、DateAPI
Java8在包Java.time下包含了一组全新的时间日期API。新的日期API和开源的Joda-Time库差不多,但又不完全一样,下面的例子展示了这组新API里最重要的一些部分:
Clock时钟
Clock类提供了访问当前日期和时间的方法,Clock是时区敏感的,可以用来取代
System.currentTimeMillis()来获取当前的微秒数。某一个特定的时间点也可以使用Instant类来表示,Instant类也可以用来创建老的Java.util.Date对象。
代码如下:
Clockclock=Clock.systemDefaultZone();
longmillis=clock.millis();
Instantinstant=clock.instant();
DatelegacyDate=Date.from(instant);//legacyJava.util.Date
Timezones时区
在新API中时区使用ZoneId来表示。时区可以很方便的使用静态方法of来获取到。时区定义了到UTS时
间的时间差,在Instant时间点对象到本地日期对象之间转换的时候是极其重要的。
代码如下:
System.out.println(ZoneId.getAvailableZoneIds());
//printsallavailabletimezoneids
ZoneIdzone1=ZoneId.of(“Europe/Berlin”);
ZoneIdzone2=ZoneId.of(“Brazil/East”);
System.out.println(zone1.getRules());
System.out.println(zone2.getRules());
//ZoneRules[currentStandardOffset=+01:00]
//ZoneRules[currentStandardOffset=-03:00]
LocalTime本地时间
LocalTime定义了一个没有时区信息的时间,例如晚上10点,或者17:30:15。下面的例子使用前面代码创建的时区创建了两个本地时间。之后比较时间并以小时和分钟为单位计算两个时间的时间差:
代码如下:
LocalTimenow1=LocalTime.now(zone1);
LocalTimenow2=LocalTime.now(zone2);
System.out.println(now1.isBefore(now2));//false
longhoursBetween=ChronoUnit.HOURS.between(now1,now2);
longminutesBetween=ChronoUnit.MINUTES.between(now1,now2);
System.out.println(hoursBetween);//-3
System.out.println(minutesBetween);//-239
LocalTime提供了多种工厂方法来简化对象的创建,包括解析时间字符串。
代码如下:
LocalTimelate=LocalTime.of(23,59,59);
System.out.println(late);//23:59:59
DateTimeFormattergermanFormatter=
DateTimeFormatter
.ofLocalizedTime(FormatStyle.SHORT)
.withLocale(Locale.GERMAN);
LocalTimeleetTime=LocalTime.parse(“13:37”,germanFormatter);
System.out.println(leetTime);//13:37
LocalDate本地日期
LocalDate表示了一个确切的日期,比如2014-03-11。该对象值是不可变的,用起来和LocalTime基本一致。下面的例子展示了如何给Date对象加减天/月/年。另外要注意的是这些对象是不可变的,操作返
回的总是一个新实例。
代码如下:
LocalDatetoday=LocalDate.now();
LocalDatetomorrow=today.plus(1,ChronoUnit.DAYS);
LocalDateyesterday=tomorrow.minusDays(2);
LocalDateindependenceDay=LocalDate.of(2014,Month.JULY,4);
DayOfWeekdayOfWeek=independenceDay.getDayOfWeek();
System.out.println(dayOfWeek);//FRIDAY
从字符串解析一个LocalDate类型和解析LocalTime一样简单:
代码如下:
DateTimeFormattergermanFormatter=
DateTimeFormatter
.ofLocalizedDate(FormatStyle.MEDIUM)
.withLocale(Locale.GERMAN);
LocalDatexmas=LocalDate.parse(“24.12.2014”,germanFormatter);
System.out.println(xmas);//2014-12-24
LocalDateTime本地日期时间
LocalDateTime同时表示了时间和日期,相当于前两节内容合并到一个对象上了。LocalDateTime和
LocalTime还有LocalDate一样,都是不可变的。LocalDateTime提供了一些能访问具体字段的方法。
代码如下:
LocalDateTimesylvester=LocalDateTime.of(2014,Month.DECEMBER,31,23,59,59);
DayOfWeekdayOfWeek=sylvester.getDayOfWeek();
System.out.println(dayOfWeek);//WEDNESDAY
Monthmonth=sylvester.getMonth();
System.out.println(month);//DECEMBER
longminuteOfDay=sylvester.getLong(ChronoField.MINUTE_OF_DAY);
System.out.println(minuteOfDay);//1439
只要附加上时区信息,就可以将其转换为一个时间点Instant对象,Instant时间点对象可以很容易的转换
为老式的Java.util.Date。
代码如下:
Instantinstant=sylvester
.atZone(ZoneId.systemDefault())
.toInstant();
DatelegacyDate=Date.from(instant);
System.out.println(legacyDate);//WedDec3123:59:59CET2014
格式化LocalDateTime和格式化时间和日期一样的,除了使用预定义好的格式外,我们也可以自己定义格式:
代码如下:
DateTimeFormatterformatter=
DateTimeFormatter
.ofPattern(“MMMdd,yyyy-HH:mm”);
LocalDateTimeparsed=LocalDateTime.parse(“Nov03,2014-07:13”,formatter);StringString=formatter.format(parsed);
System.out.println(String);//Nov03,2014-07:13
和Java.text.NumberFormat不一样的是新版的DateTimeFormatter是不可变的,所以它是线程安全的。
十、Annotation注解
在Java8中支持多重注解了,先看个例子来理解一下是什么意思。
首先定义一个包装类Hints注解用来放置一组具体的Hint注解:
代码如下:
@interfaceHints{
Hint[]value();
}
@Repeatable(Hints.class)
@interfaceHint{
Stringvalue();
}
Java8允许我们把同一个类型的注解使用多次,只需要给该注解标注一下@Repeatable即可。
例1:使用包装类当容器来存多个注解(老方法)
代码如下:
@Hints({@Hint(“hint1”),@Hint(“hint2”)})
classPerson{}
例2:使用多重注解(新方法)代码如下:@Hint(“hint1”)@Hint(“hint2”)classPerson{}第二个例子里Java编译器会隐性的帮你定义好@Hints注解,了解这一点有助于你用反射来获取这些信息:代码如下:Hinthint=Person.class.getAnnotation(Hint.class);System.out.println(hint);//null
Hintshints1=Person.class.getAnnotation(Hints.class);
System.out.println(hints1.value().length);//2
Hint[]hints2=Person.class.getAnnotationsByType(Hint.class);
System.out.println(hints2.length);//2
即便我们没有在Person类上定义@Hints注解,我们还是可以通过getAnnotation(Hints.class)来获取@Hints注解,更加方便的方法是使用getAnnotationsByType可以直接获取到所有的@Hint注解。
另外Java8的注解还增加到两种新的target上了:
代码如下:
@Target({ElementType.TYPE_PARAMETER,ElementType.TYPE_USE})
@interfaceMyAnnotation{}
关于Java8的新特性就写到这了,肯定还有更多的特性等待发掘。JDK1.8里还有很多很有用的东西,比如Arrays.parallelSort,StampedLock和CompletableFuture等等。
Java9逆天的十大新特性
在介绍Java9之前,我们先来看看Java成立到现在的所有版本。
1990年初,最初被命名为Oak;
1995年5月23日,Java语言诞生;
1996年1月,第一个JDK-JDK1.0诞生;
1996年4月,10个最主要的操作系统供应商申明将在其产品中嵌入Java技术;
1996年9月,约8.3万个网页应用了Java技术来制作;
1997年2月18日,JDK1.1发布;
1997年4月2日,JavaOne会议召开,参与者逾一万人,创当时全球同类会议纪录;
1997年9月,JavaDeveloperConnection社区成员超过十万;
1998年2月,JDK1.1被下载超过2,000,000次;
1998年12月8日,Java2企业平台J2EE发布;
1999年6月,SUN公司发布Java三个版本:标准版(J2SE)、企业版(J2EE)和微型版(J2ME);
2000年5月8日,JDK1.3发布;
2000年5月29日,JDK1.4发布;
2001年6月5日,Nokia宣布到2003年将出售1亿部支持Java的手机;
2001年9月24日,J2EE1.3发布;
2002年2月26日,J2SE1.4发布,此后Java的计算能力有了大幅提升;
2004年9月30日,J2SE1.5发布,成为Java语言发展史上的又一里程碑。为了表示该版本的重要性,J2SE1.5更名为JavaSE5.0;
2005年6月,JavaOne大会召开,SUN公司公开JavaSE6。此时,Java的各种版本已经更名,以取消其中的数字“2”:J2EE更名为JavaEE,J2SE更名为JavaSE,J2ME更名为JavaME;
2006年12月,SUN公司发布JRE6.0;
2009年4月20日,甲骨文以74亿美元的价格购SUN公司,取得Java的版权,业界传闻说这对Java程序员是个坏消息(其实恰恰相反);
2010年11月,由于甲骨文对Java社区的不友善,因此Apache扬言将退出JCP;
2011年7月28日,甲骨文发布JavaSE7;
2014年3月18日,甲骨文发表JavaSE8;
2017年7月,甲骨文发表JavaSE9。
写在前面
**modularitySystem模块系统
Java9中主要的变化是已经实现的模块化系统。
Modularity提供了类似于OSGI框架的功能,模块之间存在相互的依赖关系,可以导出一个公共的API,并且隐藏实现的细节,Java提供该功能的主要的动机在于,减少内存的开销,在JVM启动的时候,至少会有30~60MB的内存加载,主要原因是JVM需要加载rt.jar,不管其中的类是否被classloader加载,第一步整个jar都会被JVM加载到内存当中去,模块化可以根据模块的需要加载程序运行需要的class。
在引入了模块系统之后,JDK被重新组织成94个模块。Java应用可以通过新增的jlink工具,创建出只包含所依赖的JDK模块的自定义运行时镜像。这样可以极大的减少Java运行时环境的大小。使得JDK可以在更小的设备中使用。采用模块化系统的应用程序只需要这些应用程序所需的那部分JDK模块,而非是整个JDK框架了。
HTTP/2
JDK9之前提供HttpURLConnectionAPI来实现Http访问功能,但是这个类基本很少使用,一般都会选择Apache的HttpClient,此次在Java9的版本中引入了一个新的package:Java.net.http,里面提供了对Http访问很好的支持,不仅支持Http1.1而且还支持HTTP2,以及WebSocket,据说性能特别好。
注意:新的HttpClientAPI在Java9中以所谓的孵化器模块交付。也就是说,这套API不能保证100%完成。
JShell
用过Python的童鞋都知道,Python中的读取-求值-打印循环(Read-Evaluation-PrintLoop)很方便。它的目的在于以即时结果和反馈的形式。
Java9引入了jshell这个交互性工具,让Java也可以像脚本语言一样来运行,可以从控制台启动jshell,在jshell中直接输入表达式并查看其执行结果。当需要测试一个方法的运行效果,或是快速的对表达式进行求值时,jshell都非常实用。
除了表达式之外,还可以创建Java类和方法。jshell也有基本的代码完成功能。我们在教人们如何编写Java的过程中,不再需要解释“publicstaticvoidmain(String[]args)”这句废话。
不可变集合工厂方法
Java9增加了List.of()、Set.of()、Map.of()和Map.ofEntries()等工厂方法来创建不可变集合。
Liststrs=List.of(“Hello”,”World”);
ListstrsList.of(1,2,3);
Setstrs=Set.of(“Hello”,”World”);
Setints=Set.of(1,2,3);
Mapmaps=Map.of(“Hello”,1,”World”,2);
除了更短和更好阅读之外,这些方法也可以避免您选择特定的集合实现。在创建后,继续添加元素到这些集合会导致“UnsupportedOperationException”。
私有接口方法
Java8为我们提供了接口的默认方法和静态方法,接口也可以包含行为,而不仅仅是方法定义。
默认方法和静态方法可以共享接口中的私有方法,因此避免了代码冗余,这也使代码更加清晰。如果私有方法是静态的,那这个方法就属于这个接口的。并且没有静态的私有方法只能被在接口中的实例调用。
interfaceInterfaceWithPrivateMethods{
privatestaticStringstaticPrivate(){
return”staticprivate”;
}
privateStringinstancePrivate(){
}
}
HTML5风格的Java帮助文档
Java8之前的版本生成的Java帮助文档是在HTML4中。在Java9中,Javadoc的输出现在符合兼容HTML5标准。现在HTML4是默认的输出标记语言,但是在之后发布的JDK中,HTML5将会是默认的输出标记语言。
Java帮助文档还是由三个框架组成的结构构成,这是不会变的,并且以HTML5输出的Java帮助文档也保持相同的结构。每个Javadoc页面都包含有关JDK模块类或接口来源的信息。
多版本兼容JAR
当一个新版本的Java出现的时候,你的库用户要花费很长时间才会切换到这个新的版本。这就意味着库要去向后兼容你想要支持的最老的Java版本(许多情况下就是Java6或者7)。这实际上意味着未来的很长一段时间,你都不能在库中运用Java9所提供的新特性。幸运的是,多版本兼容JAR功能能让你创建仅在特定版本的Java环境中运行库程序时选择使用的class版本:
multirelease.jar
├──META-INF
│└──versions
│└──9
│└──multirelease
│└──Helper.class
├──multirelease
├──Helper.class
└──Main.class
在上述场景中,multirelease.jar可以在Java9中使用,不过Helper这个类使用的不是顶层的multirelease.Helper这个class,而是处在“META-INF/versions/9”下面的这个。这是特别为Java9准备的class版本,可以运用Java9所提供的特性和库。同时,在早期的Java诸版本中使用这个JAR也是能运行的,因为较老版本的Java只会看到顶层的这个Helper类。
统一JVM日志
Java9中,JVM有了统一的日志记录系统,可以使用新的命令行选项-Xlog来控制JVM上所有组件的日志记录。该日志记录系统可以设置输出的日志消息的标签、级别、修饰符和输出目标等。
Java9的垃圾收集机制
Java9移除了在Java8中被废弃的垃圾回收器配置组合,同时把G1设为默认的垃圾回收器实现。替代了之前默认使用的ParallelGC,对于这个改变,evens的评论是酱紫的:这项变更是很重要的,因为相对于Parallel来说,G1会在应用线程上做更多的事情,而Parallel几乎没有在应用线程上做任何事情,它基本上完全依赖GC线程完成所有的内存管理。这意味着切换到G1将会为应用线程带来额外的工作,从而直接影响到应用的性能
I/O流新特性
Java.io.InputStream中增加了新的方法来读取和复制InputStream中包含的数据。
readAllBytes:读取InputStream中的所有剩余字节。
readNBytes:从InputStream中读取指定数量的字节到数组中。
transferTo:读取InputStream中的全部字节并写入到指定的OutputStream中。
除了上面这些以外,还有以下这么多的新特性,不再一一介绍。
102:ProcessAPIUpdates
110:HTTP2Client
143:ImproveContendedLocking
158:UnifiedJVMLogging
165:CompilerControl
193:VariableHandles
197:SegmentedCodeCache
199:SmartJavaCompilation,PhaseTwo
200:TheModularJDK
201:ModularSourceCode
211:ElideDeprecationWarningsonImportStatements
212:ResolveLintandDoclintWarnings
213:MillingProjectCoin
214:RemoveGCCombinationsDeprecatedinJDK8
215:TieredAttributionforJavac
216:ProcessImportStatementsCorrectly
217:AnnotationsPipeline2.0
219:DatagramTransportLayerSecurity(DTLS)
220:ModularRun-TimeImages
221:SimplifiedDocletAPI
222:jshell:TheJavaShell(Read-Eval-PrintLoop)
223:NewVersion-StringScheme
224:HTML5Javadoc
225:JavadocSearch
226:UTF-8PropertyFiles
227:Unicode7.0
228:AddMoreDiagnosticCommands
229:CreatePKCS12KeystoresbyDefault
231:RemoveLaunch-TimeJREVersionSelection
232:ImproveSecureApplicationPerformance
233:GenerateRun-TimeCompilerTestsAutomatically
235:TestClass-FileAttributesGeneratedbyJavac
236:ParserAPIforNashorn
237:Linux/AArch64Port
238:Multi-ReleaseJARFiles
240:RemovetheJVMTIhprofAgent
241:RemovethejhatTool
243:Java-LevelJVMCompilerInterface
244:TLSApplication-LayerProtocolNegotiationExtension
245:ValidateJVMCommand-LineFlagArguments
246:LeverageCPUInstructionsforGHASHandRSA
247:CompileforOlderPlatformVersions
248:MakeG1theDefaultGarbageCollector
249:OCSPStaplingforTLS
250:StoreInternedStringsinCDSArchives
251:Multi-ResolutionImages
252:UseCLDRLocaleDatabyDefault
253:PrepareJavaFXUIControls&CSSAPIsforModularization
254:CompactStrings
255:MergeSelectedXerces2.11.0UpdatesintoJAXP
256:BeanInfoAnnotations
257:UpdateJavaFX/MediatoNewerVersionofGStreamer
258:HarfBuzzFont-LayoutEngine
259:Stack-WalkingAPI
260:EncapsulateMostInternalAPIs
261:ModuleSystem
262:TIFFImageI/O
263:HiDPIGraphicsonWindowsandLinux
264:PlatformLoggingAPIandService
265:MarlinGraphicsRenderer
266:MoreConcurrencyUpdates
267:Unicode8.0
268:XMLCatalogs
269:ConvenienceFactoryMethodsforCollections
270:ReservedStackAreasforCriticalSections
271:UnifiedGCLogging
272:Platform-SpecificDesktopFeatures
273:DRBG-BasedSecureRandomImplementations
274:EnhancedMethodHandles
275:ModularJavaApplicationPackaging
276:DynamicLinkingofLanguage-DefinedObjectModels
277:EnhancedDeprecation
278:AdditionalTestsforHumongousObjectsinG1
279:ImproveTest-FailureTroubleshooting
280:IndifyStringConcatenation
281:HotSpotC++Unit-TestFramework
282:jlink:TheJavaLinker
283:EnableGTK3onLinux
284:NewHotSpotBuildSystem
285:Spin-WaitHints
287:SHA-3HashAlgorithms
288:DisableSHA-1Certificates
289:DeprecatetheAppletAPI
290:FilterIncomingSerializationData
292:ImplementSelectedECMAScript6FeaturesinNashorn
294:Linux/s390xPort
295:Ahead-of-TimeCompilation
HashMap内部的数据结构是什么?底层是怎么实现的?
HashMap内部结构
jdk8以前:数组+链表
jdk8以后:数组+链表(当链表长度到8时,转化为红黑树)
在并发的情况,发生扩容时,可能会产生循环链表,在执行get的时候,会触发死循环,引起CPU的100%问题,所以一定要避免在并发环境下使用HashMap。
延伸考察ConcurrentHashMap与HashMap、
HashTable等,考察对技术细节的深入了解程度;
老生常谈,HashMap的死循环
问题
最近的几次面试中,我都问了是否了解HashMap在并发使用时可能发生死循环,导致cpu100%,结果让我很意外,都表示不知道有这样的问题,让我意外的是面试者的工作年限都不短。
由于HashMap并非是线程安全的,所以在高并发的情况下必然会出现问题,这是一个普遍的问题,虽然网上分析的文章很多,还是觉得有必须写一篇文章,让关注我公众号的同学能够意识到这个问题,并了解这个死循环是如何产生的。
如果是在单线程下使用HashMap,自然是没有问题的,如果后期由于代码优化,这段逻辑引入了多线程并发执行,在一个未知的时间点,会发现CPU占用100%,居高不下,通过查看堆栈,你会惊讶的发现,线程都Hang在hashMap的get()方法上,服务重启之后,问题消失,过段时间可能又复现了。
这是为什么?
原因分析
在了解来龙去脉之前,我们先看看HashMap的数据结构。
在内部,HashMap使用一个Entry数组保存key、value数据,当一对key、value被加入时,会通过一个hash算法得到数组的下标index,算法很简单,根据key的hash值,对数组的大小取模hash&(length-1),并把结果插入数组该位置,如果该位置上已经有元素了,就说明存在hash冲突,这样会在index位置生成链表。
如果存在hash冲突,最惨的情况,就是所有元素都定位到同一个位置,形成一个长长的链表,这样get一个值时,最坏情况需要遍历所有节点,性能变成了O(n),所以元素的hash值算法和HashMap的初始化大小很重要。
HashMap的put方法实现:
1、判断key是否已经存在
如果元素个数已经达到阈值,则扩容,并把原来的元素移动过去。
3、扩容实现
voidresize(intnewCapacity){
Entry[]oldTable=table;
intoldCapacity=oldTable.length;
…
Entry[]newTable=newEntry[newCapacity];
…
transfer(newTable,rehash);
table=newTable;
threshold=(int)Math.min(newCapacity*loadFactor,MAXIMUM_CAPACITY+1);}
这里会新建一个更大的数组,并通过transfer方法,移动元素。
voidtransfer(Entry[]newTable,booleanrehash){
intnewCapacity=newTable.length;
for(Entry
while(null!=e){
Entry
if(rehash){
e.hash=null==e.key?0:hash(e.key);
}
inti=indexFor(e.hash,newCapacity);
e.next=newTable[i];
newTable[i]=e;
e=next;
}
}
}
移动的逻辑也很清晰,遍历原来table中每个位置的链表,并对每个元素进行重新hash,在新的newTable找到归宿,并插入。
案例分析
假设HashMap初始化大小为4,插入个3节点,不巧的是,这3个节点都hash到同一个位置,如果按照默认的负载因子的话,插入第3个节点就会扩容,为了验证效果,假设负载因子是1.
voidtransfer(Entry[]newTable,booleanrehash){
intnewCapacity=newTable.length;
for(Entry
while(null!=e){
Entry
if(rehash){
e.hash=null==e.key?0:hash(e.key);
}
inti=indexFor(e.hash,newCapacity);
e.next=newTable[i];
newTable[i]=e;
e=next;
}
}
}
以上是节点移动的相关逻辑。
插入第4个节点时,发生rehash,假设现在有两个线程同时进行,线程1和线程2,两个线程都会新建新的数组。
假设线程2在执行到Entry
变量next指向节点b。
线程1继续执行,很不巧,a、b、c节点rehash之后又是在同一个位置7,开始移动节点第一步,移动节点a
第二步,移动节点b
注意,这里的顺序是反过来的,继续移动节点c
这个时候线程1的时间片用完,内部的table还没有设置成新的newTable,线程2开始执行,这时内部的引用关系如下:
执行之后的引用关系如下图
执行后,变量e指向节点b,因为e不是null,则继续执行循环体,执行后的引用关系
4、
所以最终的引用关系是这样的:
节点a和b互相引用,形成了一个环,当在数组该位置get寻找对应的key时,就发生了死循环。
另外,如果线程2把newTable设置成到内部的table,节点c的数据就丢了,看来还有数据遗失的问题。
总结
所以在并发的情况,发生扩容时,可能会产生循环链表,在执行get的时候,会触发死循环,引起CPU的100%问题,所以一定要避免在并发环境下使用HashMap。
曾经有人把这个问题报给了Sun,不过Sun不认为这是一个bug,因为在HashMap本来就不支持多线程使用,要并发就用ConcurrentHashmap。
ConcurrentHashMap在jdk1.8中的改进
一、简单回顾ConcurrentHashMap在jdk1.7中的设计
先简单看下ConcurrentHashMap类在jdk1.7中的设计,其基本结构如图所示:
每一个segment都是一个HashEntry
publicclassConcurrentHashMap
implementsConcurrentMap
//将整个hashmap分成几个小的map,每个segment都是一个锁;与hashtable相比,这么设计的目的是对于put,remove等操作,可以减少并发冲突,对
//不属于同一个片段的节点可以并发操作,大大提高了性能
finalSegment
//本质上Segment类就是一个小的hashmap,里面table数组存储了各个节点的数据,继承了ReentrantLock,可以作为互拆锁使用
staticfinalclassSegment
transientvolatileHashEntry
transientintcount;
}
//基本节点,存储Key,Value值
staticfinalclassHashEntry
finalinthash;
finalKkey;
volatileVvalue;
volatileHashEntry
}
}
二、在jdk1.8中主要做了2方面的改进
改进一:取消segments字段,直接采用transientvolatileHashEntry
table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将keyhash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
为了说明以上2个改动,看一下put操作是如何实现的。
finalVputVal(Kkey,Vvalue,booleanonlyIfAbsent){
if(key==null||value==null)thrownewNullPointerException();inthash=spread(key.hashCode());
intbinCount=0;
for(Node
Node
//如果table为空,初始化;否则,根据hash值计算得到数组索引i,如果tab[i]为空,直接新建节点Node即可。注:tab[i]实质为链表或者红黑树的首节点。
if(tab==null||(n=tab.length)==0)
tab=initTable();
elseif((f=tabAt(tab,i=(n-1)&hash))==null){
if(casTabAt(tab,i,null,
newNode
break;//nolockwhenaddingtoemptybin
}
//如果tab[i]不为空并且hash值为MOVED,说明该链表正在进行transfer操作,返回扩容完成后的table。
elseif((fh=f.hash)==MOVED)
tab=helpTransfer(tab,f);
else{
VoldVal=null;
//针对首个节点进行加锁操作,而不是segment,进一步减少线程冲突
synchronized(f){
if(tabAt(tab,i)==f){
if(fh>=0){
binCount=1;
for(Node
Kek;
//如果在链表中找到值为key的节点e,直接设置e.val=value即可。
if(e.hash==hash&&
((ek=e.key)==key||
(ek!=null&&key.equals(ek)))){oldVal=e.val;
if(!onlyIfAbsent)
e.val=value;
break;
}
//如果没有找到值为key的节点,直接新建Node并加入链表即可。Node
if((e=e.next)==null){
pred.next=newNode
break;
}
}
}
//如果首节点为TreeBin类型,说明为红黑树结构,执行putTreeVal操作。elseif(finstanceofTreeBin){
Node
binCount=2;
if((p=((TreeBin
oldVal=p.val;
if(!onlyIfAbsent)
p.val=value;
}
}
}
}
if(binCount!=0){
//如果节点数>=8,那么转换链表结构为红黑树结构。
if(binCount>=TREEIFY_THRESHOLD)
treeifyBin(tab,i);
if(oldVal!=null)
returnoldVal;
break;
}
}
}
//计数增加1,有可能触发transfer操作(扩容)。
addCount(1L,binCount);
returnnull;
}
另外,在其他方面也有一些小的改进,比如新增字段transientvolatileCounterCell[]counterCells;可方便的计算hashmap中所有元素的个数,性能大大优于jdk1.7中的size()方法。
三、ConcurrentHashMapjdk1.7、jdk1.8性能比较
测试程序如下:
publicclassCompareConcurrentHashMap{
privatestaticConcurrentHashMap
ConcurrentHashMap
publicstaticvoidputPerformance(intindex,intnum){
for(inti=index;i<(num+index);i++)
map.put(String.valueOf(i),i);
}
publicstaticvoidgetPerformance2(){
longstart=System.currentTimeMillis();
for(inti=0;i<400000;i++)
map.get(String.valueOf(i));
longend=System.currentTimeMillis();
System.out.println(“get:itcosts”+(end-start)+”ms”);}
publicstaticvoidmain(String[]args)throwsInterruptedException{longstart=System.currentTimeMillis();
finalCountDownLatchcdLatch=newCountDownLatch(4);
for(inti=0;i<4;i++){
finalintfinalI=i;
newThread(newRunnable(){
publicvoidrun(){
CompareConcurrentHashMap.putPerformance(100000*finalI,
100000);
cdLatch.countDown();
}
}).start();
}
cdLatch.await();
longend=System.currentTimeMillis();
System.out.println(“put:itcosts”+(end-start)+”ms”);CompareConcurrentHashMap.getPerformance2();
}
}
程序运行多次后取平均值,结果如下:
四、Collections.synchronizedList和CopyOnWriteArrayList性能分析
CopyOnWriteArrayList在线程对其进行变更操作的时候,会拷贝一个新的数组以存放新的字段,因此写操作性能很差;而Collections.synchronizedList读操作采用了synchronized,因此读性能较差。以下为测试程序:
publicclassApp{
privatestaticList
privatestaticList
CopyOnWriteArrayList
privateprivateprivateprivate
staticCountDownLatchstaticCountDownLatchstaticCountDownLatchstaticCountDownLatch
cdl1=newCountDownLatch(2);
cdl2=newCountDownLatch(2);
cdl3=newCountDownLatch(2);
cdl4=newCountDownLatch(2);
staticclassThread1extendsThread{
@Override
publicvoidrun(){
for(inti=0;i<10000;i++)
arrayList.add(String.valueOf(i));
cdl1.countDown();
}
}
staticclassThread2extendsThread{
@Override
publicvoidrun(){
for(inti=0;i<10000;i++)
copyOnWriteArrayList.add(String.valueOf(i));
cdl2.countDown();
}
}
staticclassThread3extendsThread1{
@Override
publicvoidrun(){
intsize=arrayList.size();
for(inti=0;i
cdl3.countDown();
}
}
staticclassThread4extendsThread1{
@Override
publicvoidrun(){
intsize=copyOnWriteArrayList.size();
for(inti=0;i
cdl4.countDown();
}
}
publicstaticvoidmain(String[]args)throwsInterruptedException{longstart1=System.currentTimeMillis();
newThread1().start();
newThread1().start();
cdl1.await();
System.out.println(“arrayListadd:”+(System.currentTimeMillis()-start1));
longstart2=System.currentTimeMillis();
newThread2().start();
newThread2().start();
cdl2.await();
System.out.println(“copyOnWriteArrayListadd:”+
(System.currentTimeMillis()-start2));
longstart3=System.currentTimeMillis();
newThread3().start();
newThread3().start();
cdl3.await();
System.out.println(“arrayListget:”+(System.currentTimeMillis()-start3));
longstart4=System.currentTimeMillis();
newThread4().start();
组的大小
程如下:
if(c*ssize
intcap=MIN_SEGMENT_TABLE_CAPACITY;
while(cap
Segment在实现上继承了
put实现
put方法插入数据时,根据key的hash值,在
put方法通过加锁机制插入数
Segment对象的
tryLock()方法成功获取锁,则把
scanAndLockForPut方法中,会通过
重复执行
执行
3、当线程A执行完插入操作时,会通过
size实现
ConcurrentHashMap是可以并发插入数据的,所以在准确计算元素时存在一定的难度,一般的思路是统计每个
Segment同时可能有数据的插入或则
删除,在1.7的实现中,采用了如下方式:
try{
for(;;){
if(retries++==RETRIES_BEFORE_LOCK){
for(intj=0;j
}
sum=0L;
size=0;
overflow=false;
for(intj=0;j
if(seg!=null){
sum+=seg.modCount;
intc=seg.count;
if(c<0||(size+=c)<0)
overflow=true;
}
}
if(sum==last)
break;
last=sum;
}
}finally{
if(retries>RETRIES_BEFORE_LOCK){
先采用不加锁的方式,连续计算元素的个数,最多计算3次:
1、如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;
2、如果前后两次计算结果都不同,则给每个
JDK1.8
数据结构
1.8中放弃了
行实现,结构如下:
Node数组,实现如下:
privatefinalNode
Node
while((tab=table)==null||tab.length==0){
if((sc=sizeCtl)<0)
Thread.yield();//lostinitializationrace;justspinelseif(U.compareAndSwapInt(this,SIZECTL,sc,-1)){
try{
if((tab=table)==nulltab.length==0){
intn=(sc>0)?scDEFAULT_CAPACITY;
@SuppressWarnings(“unchecked”)
Node
sc=n-(n>>>2);
}
}finally{
sizeCtl=sc;
}
break;
}
returntab;
}
put实现
当执行put方法插入数据时,根据key的hash值,在Node数组中找到相应的位置,实现如下:
2、如果CounterCell数组counterCells为空,调用fullAddCount()方法进行初始化,并插入对应的记录数,通过CAS设置cellsBusy字段,只有设置成功的线程才能初始化CounterCell数组,实现如下:
什么情况会触发扩容
1、如果新增节点之后,所在链表的元素个数达到了阈值8,则会调用
黑树,不过在结构转换之前,会对数组长度进行判断,实现如下:
如果数组长度n小于阈值MIN_TREEIFY_CAPACITY,默认是64,则会调用tryPresize方法把数组长度
扩大到原来的两倍,并触发
addCount方法记录元素个数,并检查是否需要进行扩容,当数组元素个数达
transfer方法,重新调整节点的位置。
transfer实现
transfer方法实现了在并发的情况下,高效的从原始组数往新数组中移动元素,假设扩容之前节点的
分布如下,这里区分蓝色节点和红色节点,是为了后续更好的分析:
在上图中,第14个槽位插入新节点之后,链表元素个数已经达到了8,且数组长度为16,优先通过扩容来缓解链表过长的问题,实现如下:
1、根据当前数组长度n,新建一个两倍长度的数组
nextTable的引用,在处理完每个槽位的节点之
for自循环处理每个槽位中的链表元素,默认
i指当前处理的槽位序号,
4、在当前假设条件下,槽位15中没有节点,则通过CAS插入在第二步中初始化的
点,用于告诉其它线程该槽位已经处理过了;
5、如果槽位15已经被线程A处理了,那么线程B处理到这个节点时,取到该节点的hash值应该为
-1,则直接跳过,继续处理下一个槽位14的节点;
6、处理槽位14的节点,是一个链表结构,先定义两个变量节点ln和hn,按我的理解应该是lowNode和highNode,分别保存hash值的第X位为0和1的节点,具体实现如下:
ln链:和原来链表相比,顺序已经不一样了
hn链:
通过CAS把ln链表设置到新数组的i位置,hn链表设置到i+n的位置;
7、如果该槽位是红黑树结构,则构造树节点
把节点分为两类,分别插入到
ln节点的生成逻辑如下:
UNTREEIFY_THRESHOLD,默认为6,则通过
hi链表中的元素个数是否等于0:如果等于0,表示
lo链表重新构造红黑树。
最后,同样的通过CAS把
解决方案有Hashtable和Collections.synchronizedMap(hashMap),不过这两个方案基本上是对读写进行加锁操作,一个线程在读写元素,其余线程必须等待,性能可想而知。
所以,DougLea给我们带来了并发安全的ConcurrentHashMap,它的实现是依赖于Java内存模型,所以我们在了解ConcurrentHashMap的之前必须了解一些底层的知识:
1.Java内存模型
2.Java中的Unsafe
3.Java中的CAS
4.深入浅出Java同步器
5.深入浅出ReentrantLock
本文源码是JDK8的版本,与之前的版本有较大差异。
JDK1.7分析
ConcurrentHashMap采用分段锁的机制,实现并发的更新操作,底层采用数组+链表的存储结构。其包含两个核心静态内部类Segment和HashEntry。
1.Segment继承ReentrantLock用来充当锁的角色,每个Segment对象守护每个散列映射表的若干个桶。
2.HashEntry用来封装映射表的键/值对;
3.每个桶是由若干个HashEntry对象链接起来的链表。
一个ConcurrentHashMap实例中包含由若干个Segment对象组成的数组,下面我们通过一个图来演示一下ConcurrentHashMap的结构:
JDK1.8分析
1.8的实现已经抛弃了Segment分段锁机制,利用CAS+Synchronized来保证并发更新的安全,底层采用数组+链表+红黑树的存储结构。
重要概念
在开始之前,有些重要的概念需要介绍一下:
1.table:默认为null,初始化发生在第一次插入操作,默认大小为16的数组,用来存储Node节点数据,扩容时大小总是2的幂次方。
2.nextTable:默认为null,扩容时新生成的数组,其大小为原数组的两倍。
sizeCtl:默认为0,用来控制table的初始化和扩容操作,具体应用在后续会体现出来。-1代表table正在初始化
-N表示有N-1个线程正在进行扩容操作
其余情况:
1、如果table未初始化,表示table需要初始化的大小。2、如果table初始化完成,表示table的容量,默认是table大小的0.75倍,居然用这个公式算0.75(n-(n>>>2))。
Node:保存key,value及key的hash值的数据结构。
classNode
finalinthash;
finalKkey;
volatileVval;
volatileNode
…省略部分代码
}
其中value和next都用volatile修饰,保证并发的可见性。
ForwardingNode:一个特殊的Node节点,hash值为-1,其中存储nextTable的引用。
finalclassForwardingNode
finalNode
ForwardingNode(Node
super(MOVED,null,null,null);
this.nextTable=tab;
}
}
只有table发生扩容的时候,ForwardingNode才会发挥作用,作为一个占位符放在table中表示当前节点为null或则已经被移动。
实例初始化
实例化ConcurrentHashMap时带参数时,会根据参数调整table的大小,假设参数为100,最终会调整成256,确保table的大小总是2的幂次方,算法如下:
ConcurrentHashMap
intn=c-1;
n|=n>>>1;
n|=n>>>2;
n|=n>>>4;
n|=n>>>8;
n|=n>>>16;
return(n<0)?1:(n>=MAXIMUM_CAPACITY)?MAXIMUM_CAPACITY:n+1;}
注意,ConcurrentHashMap在构造函数中只会初始化sizeCtl值,并不会直接初始化table,而是延缓到第一次put操作。
table初始化
前面已经提到过,table初始化操作会延缓到第一次put行为。但是put是可以并发执行的,DougLea是如何实现table只初始化一次的?让我们来看看源码的实现。
privatefinalNode
Node
while((tab=table)==null||tab.length==0){
//如果一个线程发现sizeCtl<0,意味着另外的线程执行CAS操作成功,当前线程只需要让出cpu时间片
if((sc=sizeCtl)<0)
Thread.yield();//lostinitializationrace;justspinelseif(U.compareAndSwapInt(this,SIZECTL,sc,-1)){
try{
if((tab=table)==null||tab.length==0){
intn=(sc>0)?sc:DEFAULT_CAPACITY;
@SuppressWarnings(“unchecked”)
Node
sc=n-(n>>>2);
}
}finally{
sizeCtl=sc;
}
}}
return
}
break;
tab;
sizeCtl默认为0,如果ConcurrentHashMap实例化时有传参数,sizeCtl会是一个2的幂次方的值。所以执行第一次put操作的线程会执行Unsafe.compareAndSwapInt方法修改sizeCtl为-1,有且只有一个线程能够修改成功,其它线程通过Thread.yield()让出CPU时间片等待table初始化完成。
put操作
假设table已经初始化完成,put操作采用CAS+synchronized实现并发插入或更新操作,具体实现如下。
inthash=spread(key.hashCode());
intbinCount=0;
for(Node
Node
if(tab==null||(n=tab.length)==0)
tab=initTable();
elseif((f=tabAt(tab,i=(n-1)&hash))==null){if(casTabAt(tab,i,null,newNode
break;//nolockwhenaddingtoemptybin
}
elseif((fh=f.hash)==MOVED)
tab=helpTransfer(tab,f);
…省略部分代码
}
addCount(1L,binCount);
returnnull;
}
1.hash算法
staticfinalintspread(inth){return(h^(h>>>16))&HASH_BITS;}
1.table中定位索引位置,n是table的大小
intindex=(n-1)&hash
1.获取table中对应索引的元素f。
DougLea采用Unsafe.getObjectVolatile来获取,也许有人质疑,直接table[index]不可以么,为什么要这么复杂?
在Java内存模型中,我们已经知道每个线程都有一个工作内存,里面存储着table的副本,虽然table是volatile修饰的,但不能保证线程每次都拿到table中的最新元素,
Unsafe.getObjectVolatile可以直接获取指定内存的数据,保证了每次拿到数据都是最新的。
2.如果f为null,说明table中这个位置第一次插入元素,利用Unsafe.compareAndSwapObject方法插入Node节点。
如果CAS成功,说明Node节点已经插入,随后addCount(1L,binCount)方法会检查当前容量是否需要进行扩容。
如果CAS失败,说明有其它线程提前插入了节点,自旋重新尝试在这个位置插入节点。
1.如果f的hash值为-1,说明当前f是ForwardingNode节点,意味有其它线程正在扩容,则一起进行
扩容操作。
2.其余情况把新的Node节点按链表或红黑树的方式插入到合适的位置,这个过程采用同步内置锁实现并发,代码如下:
synchronized(f){
if(tabAt(tab,i)==f){
if(fh>=0){
binCount=1;
for(Node
Kek;
if(e.hash==hash&&
((ek=e.key)==key||
(ek!=null&&key.equals(ek)))){
oldVal=e.val;
if(!onlyIfAbsent)
e.val=value;
break;
}
Node
if((e=e.next)==null){
pred.next=newNode
value,null);
break;
}
}
}
elseif(finstanceofTreeBin){
Node
binCount=2;
if((p=((TreeBin
value))!=null){
oldVal=p.val;
if(!onlyIfAbsent)
p.val=value;
}
}
}
}
在节点f上进行同步,节点插入之前,再次利用tabAt(tab,i)==f判断,防止被其它线程修改。
1.如果f.hash>=0,说明f是链表结构的头结点,遍历链表,如果找到对应的node节点,则修改value,否则在链表尾部加入节点。
2.如果f是TreeBin类型节点,说明f是红黑树根节点,则在树结构上遍历元素,更新或增加节点。
3.如果链表中节点数binCount>=TREEIFY_THRESHOLD(默认是8),则把链表转化为红黑树结构。
table扩容
当table容量不足的时候,即table的元素数量达到容量阈值sizeCtl,需要对table进行扩容。整个扩容分为两部分:
1.构建一个nextTable,大小为table的两倍。
2.把table的数据复制到nextTable中。
这两个过程在单线程下实现很简单,但是ConcurrentHashMap是支持并发插入的,扩容操作自然也会有并发的出现,这种情况下,第二步可以支持节点的并发复制,这样性能自然提升不少,但实现的复杂度也上升了一个台阶。
先看第一步,构建nextTable,毫无疑问,这个过程只能只有单个线程进行nextTable的初始化,具体实现如下:
privatefinalvoidaddCount(longx,intcheck){
…省略部分代码
if(check>=0){
Node
while(s>=(long)(sc=sizeCtl)&&(tab=table)!=null&&
(n=tab.length)
if(sc<0){
if((sc>>>RESIZE_STAMP_SHIFT)!=rs||sc==rs+1||sc==rs+MAX_RESIZERS||(nt=nextTable)==null||
transferIndex<=0)
break;
if(U.compareAndSwapInt(this,SIZECTL,sc,sc+1))transfer(tab,nt);
}
elseif(U.compareAndSwapInt(this,SIZECTL,sc,
(rs<
s=sumCount();
}
}
}
通过Unsafe.compareAndSwapInt修改sizeCtl值,保证只有一个线程能够初始化nextTable,扩容后的数组长度为原来的两倍,但是容量是原来的1.5。
节点从table移动到nextTable,大体思想是遍历、复制的过程。
1.首先根据运算得到需要遍历的次数i,然后利用tabAt方法获得i位置的元素f,初始化一个forwardNode实例fwd。
2.如果f==null,则在table中的i位置放入fwd,这个过程是采用Unsafe.compareAndSwapObjectf方法实现的,很巧妙的实现了节点的并发移动。
3.如果f是链表的头节点,就构造一个反序链表,把他们分别放在nextTable的i和i+n的位置上,移动完成,采用Unsafe.putObjectVolatile方法给table原位置赋值fwd。
4.如果f是TreeBin节点,也做一个反序处理,并判断是否需要untreeify,把处理的结果分别放在nextTable的i和i+n的位置上,移动完成,同样采用Unsafe.putObjectVolatile方法给table原位置赋值fwd。
遍历过所有的节点以后就完成了复制工作,把table指向nextTable,并更新sizeCtl为新数组大小的0.75倍,扩容完成。
红黑树构造
注意:如果链表结构中元素超过TREEIFY_THRESHOLD阈值,默认为8个,则把链表转化为红黑树,提高遍历查询效率。
if(binCount!=0){
if(binCount>=TREEIFY_THRESHOLD)
treeifyBin(tab,i);
if(oldVal!=null)
returnoldVal;
break;
}
接下来我们看看如何构造树结构,代码如下:
privatefinalvoidtreeifyBin(Node
Node
if(tab!=null){
if((n=tab.length)
elseif((b=tabAt(tab,index))!=null&&b.hash>=0){
synchronized(b){
if(tabAt(tab,index)==b){
TreeNode
TreeNode
newTreeNode
null,null);
if((p.prev=tl)==null)
hd=p;
else
tl.next=p;
tl=p;
}
setTabAt(tab,index,newTreeBin
}
}
}
}
}
可以看出,生成树节点的代码块是同步的,进入同步代码块之后,再次验证table中index位置元素是否被修改过。
1、根据table中index位置Node链表,重新生成一个hd为头结点的TreeNode链表。2、根据hd头结点,生成TreeBin树结构,并把树结构的root节点写到table的index位置的内存中,具体实现如下:
TreeBin(TreeNode
super(TREEBIN,null,null,null);
this.first=b;
TreeNode
for(TreeNode
next=(TreeNode
x.left=x.right=null;
if(r==null){
x.parent=null;
x.red=false;
r=x;
}
else{
Kk=x.key;
inth=x.hash;
Class<?>kc=null;
for(TreeNode
intdir,ph;
Kpk=p.key;
if((ph=p.hash)>h)
dir=-1;
elseif(ph
elseif((kc==null&&
(kc=comparableClassFor(k))==null)||
(dir=compareComparables(kc,k,pk))==0)dir=tieBreakOrder(k,pk);
TreeNode
if((p=(dir<=0)?p.left:p.right)==null){
x.parent=xp;
if(dir<=0)
xp.left=x;
else
xp.right=x;
r=balanceInsertion(r,x);
break;
}
}
}
}
this.root=r;
assertcheckInvariants(root);
}
主要根据Node节点的hash值大小构建二叉树。这个红黑树的构造过程实在有点复杂,感兴趣的同学可以看看源码。
get操作
get操作和put操作相比,显得简单了许多。
publicVget(Objectkey){
Node
inth=spread(key.hashCode());
if((tab=table)!=null&&(n=tab.length)>0&&
(e=tabAt(tab,(n-1)&h))!=null){
if((eh=e.hash)==h){
if((ek=e.key)==key||(ek!=null&&key.equals(ek)))returne.val;
}
elseif(eh<0)
return(p=e.find(h,key))!=null?p.val:null;
while((e=e.next)!=null){
if(e.hash==h&&
((ek=e.key)==key||(ek!=null&&key.equals(ek))))returne.val;
}
}
returnnull;
}
1.判断table是否为空,如果为空,直接返回null。
2.计算key的hash值,并获取指定table中指定位置的Node节点,通过遍历链表或则树结构找到对应的节点,返回value值。
个时,会调用treeifyBin()方法把链表结构转化成红黑树结构,实现如下:
从上述实现可以看出:并非一开始就创建红黑树结构,如果当前Node数组长度小于阈值MIN_TREEIFY_CAPACITY,默认为64,先通过扩大数组容量为原来的两倍以缓解单个链表元素过大的性
能问题。
红黑树构造过程
下面对红黑树的构造过程进行分析:
Node链表,生成对应的
TreeNode链表如下,其中节点中的数值代表
TreeBin在实现上同样继承了
TreeBin类对象可以保持在
4、加入节点60,如果root不为空,则通过比较节点hash值的大小将新节点插入到指定位置,实现如下:
p指向红黑树中当前遍历到的节点,从根节点开始递归遍历,
p的左节点是否为空,如果不为空,则把
x指向的节点插入到该位置;
p的右节点是否为空,如果不为空,则把
x指向的节点插入到该位置;
hash值相等,怎么办?
Comparable接口,如果实现
key对象没有实现
dir值,
下:
System.identityHashCode(a)调用的是对
hashCode();
插入节点60之后的二叉树:
if((xp=x.parent)==null){
x.red=false;
returnx;
}
elseif(!xp.red||(xpp=xp.parent)==null)
returnroot;
调整之后的二叉树:
②、加入节点50,二叉树如下:
balanceInsertion()方法调整二叉树,此时节点50的父节点60是左儿子,走如下逻辑:
if(xp==(xppl=xpp.left)){
if((xppr=xpp.right)!=null&&xppr.red){
xppr.red=false;
xp.red=false;
xpp.red=true;
x=xpp;
}
else{
if(x==xp.right){
root=rotateLeft(root,x=xp);
xpp=(xp=x.parent)==null?null:xp.parent;
}
if(xp!=null){
xp.red=false;
if(xpp!=null){
xpp.red=true;
root=rotateRight(root,xpp);
}
}
}
}
根据上述逻辑,把节点60设置成黑色,把节点80设置成红色,并对节点80执行右旋操作,右旋实现如下:
static
TreeNode
TreeNode
if(p!=null&&(l=p.left)!=null){
if((lr=p.left=l.right)!=null)
lr.parent=p;
if((pp=l.parent=p.parent)==null)
(root=l).red=false;
elseif(pp.right==p)
pp.right=l;
else
pp.left=l;
l.right=p;
p.parent=l;
}
returnroot;
}
右旋之后的红黑树如下:
③、加入节点70,二叉树如下:
balanceInsertion()方法调整二叉树,此时父节点80是个右儿子,节点70是左儿子,且叔节点50不为空,且是红色的,则执行如下逻辑:
此时二叉树如下:
x,设置其颜色为黑色,最终二叉树如下:
④、加入节点20,二叉树变化如下:
因为节点20的父节点50是一个黑色的节点,不需要进行调整;
⑤、加入节点65,二叉树变化如下:
对节点80进行右旋操作。
⑥、加入节点40,二叉树变化如下:
1、对节点20执行左旋操作;
2、对节点50执行右旋操作;
最后加入节点10,二叉树变化如下:
重新对节点进行着色,到此为止,红黑树已经构造完成;
说说反射的用途及实现,反射是不是很慢,我们在项目中是
否要避免使用反射;
一、用途反射被广泛地用于那些需要在运行时检测或修改程序行为的
程序中。
二、实现方式Foofoo=newFoo();
第一种:通过Object类的getClass方法Classcla=foo.getClass();
第二种:通过对象实例方法获取对象Classcla=foo.class;
第三种:通过Class.forName方式Classcla=Class.forName(“xx.xx.Foo”);
三、缺点
1)影响性能反射包括了一些动态类型,所以JVM无法对这些代码进行优化。因此,反射操作的效率
要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。2)安全限制使用反射技术要求程序必须在一个没有安全限制的环境中运行。
3)内部暴露由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用--代码有功能上的错误,降低可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
说说自定义注解的场景及实现;
利用自定义注解,结合SpringAOP可以完成权限控制、日志记录、统一异常处理、数字签名、数据加解密等功能。
实现场景(API接口数据加解密)
1)自定义一个注解,在需要加解密的方法上添加该注解
2)配置SringAOP环绕通知
3)截获方法入参并进行解密
4)截获方法返回值并进行加密
List和Map区别
一、概述
List是存储单列数据的集合,Map是存储键和值这样的双列数据的集合,List中存储的数据是有顺序,并且允许重复,值允许有多个null;Map中存储的数据是没有顺序的,键不能重复,值是可以有重复的,key最多有一个null。
二、明细
List
1)可以允许重复的对象。
2)可以插入多个null元素。
3)是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。
<br />
4)常用的实现类有ArrayList、LinkedList和Vector。ArrayList最为流行,它提供了使用索引的随意访问,而LinkedList则对于经常需要从List中添加或删除元素的场合更为合适。
Map
1)Map不是collection的子接口或者实现类。Map是一个接口。
2)Map的每个Entry都持有两个对象,也就是一个键一个值,Map可能会持有相同的值对象但键对象必须是唯一的。
3)TreeMap也通过Comparator或者Comparable维护了一个排序顺序。
4)Map里你可以拥有随意个null值但最多只能有一个null键。
5)Map接口最流行的几个实现类是HashMap、LinkedHashMap、Hashtable和TreeMap。 (HashMap、TreeMap最常用)
Set(问题扩展)
1)不允许重复对象
2)无序容器,你无法保证每个元素的存储顺序,TreeSet通过Comparator或Comparable维护了一个排序顺序。
3)只允许一个null元素
4)Set接口最流行的几个实现类是HashSet、LinkedHashSet以及TreeSet。最流行的是基于HashMap实现的HashSet;TreeSet还实现了SortedSet接口,因此TreeSet是一个根据其compare()和compareTo()的定义进行排序的有序容器。
三、场景(问题扩展)
1)如果你经常会使用索引来对容器中的元素进行访问,那么List是你的正确的选择。如果你已经知道索引了的话,那么List的实现类比如ArrayList可以提供更快速的访问,如果经常添加删除元素的,那么肯定要选择LinkedList。
2)如果你想容器中的元素能够按照它们插入的次序进行有序存储,那么还是List,因为List是一个有序容器,它按照插入顺序进行存储。
3)如果你想保证插入元素的唯一性,也就是你不想有重复值的出现,那么可以选择一个Set的实现类,比如HashSet、LinkedHashSet或者TreeSet。所有Set的实现类都遵循了统一约束比如唯一性,而且还提供了额外的特性比如TreeSet还是一个SortedSet,所有存储于TreeSet中的元素可以使用Java里的Comparator或者Comparable进行排序。LinkedHashSet也按照元素的插入顺序对它们进行存储。
4)如果你以键和值的形式进行数据存储那么Map是你正确的选择。你可以根据你的后续需要从Hashtable、HashMap、TreeMap中进行选择。
List、Set、Map的区别
(图一)<br />1.面试题:你说说collection里面有什么子类。<br /> (其实面试的时候听到这个问题的时候,你要知道,面试官是想考察List,Set)<br />正如图一,list和set是实现了collection接口的。<br /> <br />(图二)<br />List:1.可以允许重复的对象。<br />2.可以插入多个null元素。<br />3.是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。<br /> <br />
4.常用的实现类有ArrayList、LinkedList和Vector。ArrayList最为流行,它提
供了使用索引的随意访问,而LinkedList则对于经常需要从List中添加或删除元素的场合更为合适。
(图三)<br />Set:1.不允许重复对象<br />2.无序容器,你无法保证每个元素的存储顺序,TreeSet通过Comparator或者<br />Comparable维护了一个排序顺序。<br />3.只允许一个null元素<br />4.Set接口最流行的几个实现类是HashSet、LinkedHashSet以及TreeSet。最<br />流行的是基于HashMap实现的HashSet;TreeSet还实现了SortedSet接口,因此TreeSet是一个根据其compare()和compareTo()的定义进行排序的有序容器。<br /><br />(图四)
1.Map不是collection的子接口或者实现类。Map是一个接口。
2.Map的每个Entry都持有两个对象,也就是一个键一个值,Map可能会持有相同的值对象但键对象必须是唯一的。
3.TreeMap也通过Comparator或者Comparable维护了一个排序顺序。
4.Map里你可以拥有随意个null值但最多只能有一个null键。
5.Map接口最流行的几个实现类是HashMap、LinkedHashMap、Hashtable
和TreeMap。(HashMap、TreeMap最常用)
<br /> <br />
2.面试题:什么场景下使用list,set,map呢?
(或者会问为什么这里要用list、或者set、map,这里回答它们的优缺点就可以
了)
答:
1.如果你经常会使用索引来对容器中的元素进行访问,那么List是你的正确的选
<br /><br />
择。如果你已经知道索引了的话,那么List的实现类比如ArrayList可以提供更快速的访问,如果经常添加删除元素的,那么肯定要选择LinkedList。
2.如果你想容器中的元素能够按照它们插入的次序进行有序存储,那么还是List,因为List是一个有序容器,它按照插入顺序进行存储。
3.如果你想保证插入元素的唯一性,也就是你不想有重复值的出现,那么可以选择一个Set的实现类,比如HashSet、LinkedHashSet或者TreeSet。所有Set的实现类都遵循了统一约束比如唯一性,而且还提供了额外的特性比如TreeSet还是一个SortedSet,所有存储于TreeSet中的元素可以使用Java里的Comparator或者Comparable进行排序。LinkedHashSet也按照元素的插入顺序对它们进行存储。
4.如果你以键和值的形式进行数据存储那么Map是你正确的选择。你可以根据你的后续需要从Hashtable、HashMap、TreeMap中进行选择。
大家可以跟着下面的步骤一起尝试一下。
1.我们知道了列表要实现排序,需要重写comparable接口的compareTo的方法。
但是是我不知道comparaTo里面要怎么写呢,它有传入参数吗?它有返回值吗?
如果有事什么类型的呢?ok,下面一起来做一下。先把这个链接的帮助文档下载下来。下载完之后,打开帮助文档,
<br /> <br />
2.看完了帮助文档是不是心里稍微有点底气了呢,那现在打开eclipse我们一起来写一写吧。
首先我们要比较对象的哪个属性呢。年龄?身高?还是体重?刚刚看帮助文档已经知道了,所以下面大家一起来写一下。
如果大家也是像上图这种写法,那么再想一想有没有更好的办法。(我这样吻是肯定有的,好好看看帮助文档,你就知道了,我知道你只要用心想想,肯定想出来的!)
好了,写完年龄,不去继续花几分钟把按照身高来排序也写一下吧。
Arraylist与LinkedList区别,ArrayList与Vector区
别;
1)数据结构Vector、ArrayList内部使用数组,而LinkedList内部使用双向链表,由数组和链表的特性知:LinkedList适合指定位置插入、删除操作,不适合查找;ArrayList、Vector适合查找,不适合指定
位置的插入删除操作。但是ArrayList越靠近尾部的元素进行增删时,其实效率比LinkedList要高2)线程安全Vector线程安全,ArrayList、LinkedList线程不安全。
3)空间ArrayList在元素填满容器时会自动扩充容器大小的50%,而Vector则是100%,因此ArrayList更节省空间。
Java异常简介
Java异常是Java提供的一种识别及响应错误的一致性机制。
Java异常机制可以使程序中异常处理代码和正常业务代码分离,保证程序代码更加优雅,并提高程序健壮性。在有效使用异常的情况下,异常能清晰的回答what,where,why这3个问题:异常类型回答了“什么”被抛出,异常堆栈跟踪回答了“在哪”抛出,异常信息回答了“为什么”会抛出。
Java异常架构
1.Throwable
Throwable是Java语言中所有错误与异常的超类。
Throwable包含两个子类:Error(错误)和Exception(异常),它们通常用于指示发生了异常情况。
Throwable包含了其线程创建时线程执行堆栈的快照,它提供了printStackTrace()等接口用于获取堆栈跟踪数据等信息。
2.Error(错误)
定义:Error类及其子类。程序中无法处理的错误,表示运行应用程序中出现了严重的错误。
特点:此类错误一般表示代码运行时JVM出现问题。通常有Virtual
MachineError(虚拟机运行错误)、NoClassDefFoundError(类定义错误)
等。比如OutOfMemoryError:内存不足错误;StackOverflowError:栈溢出错误。此类错误发生时,
JVM将终止线程。这些错误是不受检异常,非代码性错误。因此,当此类错误发生时,应用程序不
应该去处理此类错误。按照Java惯例,我们是不应该实现任何新的Error子类的!
3.Exception(异常)
程序本身可以捕获并且可以处理的异常。Exception这种异常又分为两类:运行时异常和编译时异常。
运行时异常
定义:RuntimeException类及其子类,表示JVM在运行期间可能出现的异常。
特点:Java编译器不会检查它。也就是说,当程序中可能出现这类异常时,倘若既”没有通过throws声明抛出它”,也”没有用try-catch语句捕获它”,还是会编译通过。比如NullPointerException空指针异常、
ArrayIndexOutBoundException数组下标越界异常、ClassCastException类型转换异常、ArithmeticExecption算术异常。此类异常属于不受检异常,一般是由程序逻辑错误引起的,在程序中可以选择捕获处理,也可以不处理。虽然Java编译器不会检查运行时异常,但是我们也可以通过throws进行声明抛
出,也可以通过try-catch对它进行捕获处理。如果产生运行时异常,则需要通过修改代码来进行避免。例如,若会发生除数为零的情况,则需要通过代码避免该情况的发生!
RuntimeException异常会由Java虚拟机自动抛出并自动捕获(就算我们没写异常捕获语句运行时也会抛出错误!!),此类异常的出现绝大数情况是代码本身有问题应该从逻辑上去解决并改进代码。
编译时异常
定义:Exception中除RuntimeException及其子类之外的异常。
特点:Java编译器会检查它。如果程序中出现此类异常,比如
ClassNotFoundException(没有找到指定的类异常),IOException(IO流异常),要么通过throws进行声明抛出,要么通过try-catch进行捕获处理,否则不能通过编译。在程序中,通常不会自定义该类异常,而是直接使用系统提供的异常类。该异常我们必须手动在代码里添加捕获语句来处理该异常。
4.受检异常与非受检异常
Java的所有异常可以分为受检异常(checkedexception)和非受检异常
(uncheckedexception)。
受检异常
编译器要求必须处理的异常。正确的程序在运行过程中,经常容易出现的、符合
预期的异常情况。一旦发生此类异常,就必须采用某种方式进行处理。除
RuntimeException及其子类外,其他的Exception异常都属于受检异常。编译器会检查此类异常,也就是说当编译器检查到应用中的某处可能会此类异常时,将会提示你处理本异常——要么使用try-catch捕获,要么使用方法签名中用throws关键字抛出,否则编译不通过。
非受检异常
编译器不会进行检查并且不要求必须处理的异常,也就说当程序中出现此类异常时,即使我们没有try-catch捕获它,也没有使用throws抛出该异常,编译也会正常通过。该类异常包括运行时异常 (RuntimeException极其子类)和错误(Error)
Java异常关键字
•try–用于监听。将要被监听的代码(可能抛出异常的代码)放在try语句块之内,当try语句块内发生异常时,异常就被抛出。
•catch–用于捕获异常。catch用来捕获try语句块中发生的异常。
•finally–finally语句块总是会被执行。它主要用于回收在try块里打开的物力资源(如数据库连接、网络连接和磁盘文件)。只有finally块,执行完成之后,才会回来执行try或者catch块中的return或者throw语
句,如果finally中使用了return或者throw等终止方法的语句,则就不会跳回执行,直接停止。
•throw–用于抛出异常。
•throws–用在方法签名中,用于声明该方法可能抛出的异常。
Java异常处理
Java通过面向对象的方法进行异常处理,一旦方法抛出异常,系统自动根据该异常对象寻找合适异常处理器(ExceptionHandler)来处理该异常,把各种不同的异常进行分类,并提供了良好的接口。在Java中,每个异常都是一个对
象,它是Throwable类或其子类的实例。当一个方法出现异常后便抛出一个异常对象,该对象中包含有异常信息,调用这个对象的方法可以捕获到这个异常并可以对其进行处理。Java的异常处理是通过5个关键词来实现的:try、catch、throw、throws和finally。
在Java应用中,异常的处理机制分为声明异常,抛出异常和捕获异常。
声明异常
通常,应该捕获那些知道如何处理的异常,将不知道如何处理的异常继续传递下
去。传递异常可以在方法签名处使用throws关键字声明可能会抛出的异常。注意
非检查异常(Error、RuntimeException或它们的子类)不可使用throws关键字来声明要抛出的异常。
.assets/clip_image002-1604914706296.gif)一个方法出现编译时异常,就需要try-catch/throws处理,否则会导致编译错误
抛出异常
如果你觉得解决不了某些异常问题,且不需要调用者处理,那么你可以抛出异常。throw关键字作用是在方法内部抛出一个Throwable类型的异常。任何Java代码都可以通过throw语句抛出异常。
捕获异常
程序通常在运行之前不报错,但是运行后可能会出现某些未知的错误,但是还不想直接抛出到上一级,那么就需要通过try…catch…的形式进行异常捕获,之后根据不同的异常情况来进行相应的处理。如何选择异常类型
可以根据下图来选择是捕获异常,声明异常还是抛出异常
常见异常处理方式直接抛出异常
通常,应该捕获那些知道如何处理的异常,将不知道如何处理的异常继续传递下去。传递异常可以在方法签名处使用throws关键字声明可能会抛出的异常。
1privatestaticvoidreadFile(StringfilePath)throwsIOException{
2Filefile=newFile(filePath);
3Stringresult;
4BufferedReaderreader=newBufferedReader(newFileReader(file));
5while((result=reader.readLine())!=null){
6System.out.println(result);7}
8reader.close();9}
封装异常再抛出
有时我们会从catch中抛出一个异常,目的是为了改变异常的类型。多用于在多系统集成时,当某个子系统故障,异常类型可能有多种,可以用统一的异常类型向外暴露,不需暴露太多内部异常细节。
1privatestaticvoidreadFile(StringfilePath)throwsMyException{2try{
3//code
4}catch(IOExceptione){
5MyExceptionex=newMyException(“readfilefailed.”);
6ex.initCause(e);
7throwex;
8}
9}
捕获异常
在一个try-catch语句块中可以捕获多个异常类型,并对不同类型的异常做出不同的处理
1privatestaticvoidreadFile(StringfilePath){
2try{
3//code
4}catch(FileNotFoundExceptione){
5//handleFileNotFoundException
6}catch(IOExceptione){
7//handleIOException
8}
9}
同一个catch也可以捕获多种类型异常,用|隔开
1privatestaticvoidreadFile(StringfilePath){
2try{
3//code
4}catch(FileNotFoundException|UnknownHostExceptione){
5//handleFileNotFoundExceptionorUnknownHostException
6}catch(IOExceptione){
7//handleIOException
8}
9}
自定义异常
习惯上,定义一个异常类应包含两个构造函数,一个无参构造函数和一个带有详
细描述信息的构造函数(Throwable的toString方法会打印这些详细信息,调试时很有用)
1publicclassMyExceptionextendsException{
2publicMyException(){}
3publicMyException(Stringmsg){
4super(msg);5}
6//…
7}
try-catch-finally
当方法中发生异常,异常处之后的代码不会再执行,如果之前获取了一些本地资源需要释放,则需要在方法正常结束时和catch语句中都调用释放本地资源的代码,显得代码比较繁琐,finally语句可以解决这个问题。
调用该方法时,读取文件时若发生异常,代码会进入catch代码块,之后进入finally代码块;若读取文件时未发生异常,则会跳过catch代码块直接进入finally代码块。所以无论代码中是否发生异常,fianlly中的代码都会执行。若catch代码块中包含return语句,finally中的代码还会执行吗?将以上代码中的catch子句修改如下:
调用readFile方法,观察当catch子句中调用return语句时,finally子句是否执行
可见,即使catch中包含了return语句,finally子句依然会执行。若finally中也包含return语句,finally中的return会覆盖前面的return.
try代码块退出时,会自动调用scanner.close方法,和把scanner.close方法放在finally代码块中不同的是,若scanner.close抛出异常,则会被抑制,抛出的仍然为原始异常。被抑制的异常会由addSusppressed方法添加到原来的异常,如果想要获取被抑制的异常列表,可以调用getSuppressed方法来获取。
Java异常常见面试题
1.Error和Exception区别是什么?
Error类型的错误通常为虚拟机相关错误,如系统崩溃,内存不足,堆栈溢出等,编译器不会对这类错误进行检测,Java应用程序也不应对这类错误进行捕获,一旦这类错误发生,通常应用程序会被终止,仅靠应用程序本身无法恢复;
Exception类的错误是可以在应用程序中进行捕获并处理的,通常遇到这种错误,应对其进行处理,使应用程序可以继续正常运行。
2.运行时异常和一般异常(受检异常)区别是什么?
运行时异常包括RuntimeException类及其子类,表示JVM在运行期间可能出现的异常。Java编译器不会检查运行时异常。
受检异常是Exception中除RuntimeException及其子类之外的异常。Java编译器会检查受检异常。
RuntimeException异常和受检异常之间的区别:是否强制要求调用者必须处理此异常,如果强制要求调用者必须进行处理,那么就使用受检异常,否则就选择非受检异常(RuntimeException)。一般来讲,如果没有特殊的要求,我们建议使用RuntimeException异常。
3.JVM是如何处理异常的?
在一个方法中如果发生异常,这个方法会创建一个异常对象,并转交给JVM,该异常对象包含异常名称,异常描述以及异常发生时应用程序的状态。创建异常对象并转交给JVM的过程称为抛出异常。可能有一系列的方法调用,终才进入抛出异常的方法,这一系列方法调用的有序列表叫做调用栈。
JVM会顺着调用栈去查找看是否有可以处理异常的代码,如果有,则调用异常处理代码。当JVM发现可以处理异常的代码时,会把发生的异常传递给它。如果JVM没有找到可以处理该异常的代码块,JVM就会将该异常转交给默认的异常处理器(默认处理器为JVM的一部分),默认异常处理器打印出异常信息并终止应用程序。
4.throw和throws的区别是什么?
Java中的异常处理除了包括捕获异常和处理异常之外,还包括声明异常和拋出异常,可以通过throws关键字在方法上声明该方法要拋出的异常,或者在方法内部通过throw拋出异常对象。
throws关键字和throw关键字在使用上的几点区别如下:
throw关键字用在方法内部,只能用于抛出一种异常,用来抛出方法或代码块中的异常,受查异常
和非受查异常都可以被抛出。
throws关键字用在方法声明上,可以抛出多个异常,用来标识该方法可能抛出的异常列表。一个
方法用throws标识了可能抛出的异常列表,调用该方法的方法中必须包含可处理异常的代码,否则也要在方法签名中用throws关键字声明相应的异常。
5.final、finally、finalize有什么区别?
final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值。
finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代
码。
finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,Java中允许使用
finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。
6.NoClassDefFoundError和ClassNotFoundException区别?
NoClassDefFoundError是一个Error类型的异常,是由JVM引起的,不应该尝试捕获这个异常。
引起该异常的原因是JVM或ClassLoader尝试加载某类时在内存中找不到该类的定义,该动作发生在运行期间,即编译时该类存在,但是在运行时却找不到了,可能是变异后被删除了等原因导致;
ClassNotFoundException是一个受查异常,需要显式地使用try-catch对其进行捕获和处理,或在方法签名中用throws关键字进行声明。当使用Class.forName,ClassLoader.loadClass或ClassLoader.findSystemClass动态加载类到内存的时候,通过传入的类路径参数没有找到该类,就会抛出该异常;另一种抛出该异常的可能原因是某个类已经由一个类加载器加载至内存中,另一个加载器又尝试去加载它。
7.try-catch-finally中哪个部分可以省略?
答:catch可以省略
原因
更为严格的说法其实是:try只适合处理运行时异常,try+catch适合处理运行时异常+普通异常。也就是说,如果你只用try去处理普通异常却不加以catch处理,编译是通不过的,因为编译器硬性规定,普通异常如果选择捕获,则必须用catch显示声明以便进一步处理。而运行时异常在编译时没有如此规定,所以catch可以省略,你加上catch编译器也觉得无可厚非。
理论上,编译器看任何代码都不顺眼,都觉得可能有潜在的问题,所以你即使对所有代码加上try,代码在运行期时也只不过是在正常运行的基础上加一层皮。但是你一旦对一段代码加上try,就等于显示地承诺编译器,对这段代码可能抛出的异常进行捕获而非向上抛出处理。如果是普通异常,编译器要求必须用catch捕获以便进一步处理;如果运行时异常,捕获然后丢弃并且+finally扫尾处理,或者加上catch捕获以便进一步处理。
至于加上finally,则是在不管有没捕获异常,都要进行的“扫尾”处理。
8.try-catch-finally中,如果catch中return了,finally还会执
行吗?
答:会执行,在return前执行。
注意:在finally中改变返回值的做法是不好的,因为如果存在finally代码块,try中的return语句不会立马返回调用者,而是记录下返回值待finally代码块执行完毕之后再向调用者返回其值,然后如果在finally中修改了返回值,就会返回修改后的值。显然,在finally中返回或者修改返回值会对程序造成很大的困扰,C#中直接用编译错误的方式来阻止程序员干这种龌龊的事情,Java中也可以通过提升编译器的语法检查级别来产生警告或错误。
代码示例1:
1publicstaticintgetInt(){
2inta=10;
3try{
4System.out.println(a/0);
5a=20;
6}catch(ArithmeticExceptione){
7a=30;
8returna;9/
10returna在程序执行到这一步的时候,这里不是returna而是return30;这个返回路径就形成了
11但是呢,它发现后面还有finally,所以继续执行finally的内容,a=40
12再次回到以前的路径,继续走return30,形成返回路径之后,这里的a就不是a变量了,而是常量3013*/
14}finally{
15a=40;16}
17returna;18}
执行结果:30
代码示例2:
1publicstaticintgetInt(){
2inta=10;
3try{
4System.out.println(a/0);
5a=20;
6}catch(ArithmeticExceptione){
7a=30;
8returna;
9}finally{
10a=40;
11//如果这样,就又重新形成了一条返回路径,由于只能通过1个return返回,所以这里直接返回4012returna;
13}
14
15}
9.类ExampleA继承Exception,类ExampleB继承ExampleA。
有如下代码片断:
1try{
2thrownewExampleB(“b”)3}catch(ExampleAe){
4System.out.println(“ExampleA”);5}catch(Exceptione){
6System.out.println(“Exception”);7}
请问执行此段代码的输出是什么?
答:
输出:ExampleA。(根据里氏代换原则[能使用父类型的地方一定能使用子类型],抓取ExampleA类型异常的catch块能够抓住try块中抛出的ExampleB类型的异常)
面试题-说出下面代码的运行结果。(此题的出处是《Java编程思想》一书)
1classAnnoyanceextendsException{2}
3classSneezeextendsAnnoyance{4}
5classHuman{
6publicstaticvoidmain(String[]args)
7throwsException{
8try{
9try{
10thrownewSneeze();
11}catch(Annoyancea){
12System.out.println(“CaughtAnnoyance”);
13throwa;14}
15}catch(Sneezes){
16System.out.println(“CaughtSneeze”);
17return;
18}finally{
19System.out.println(“HelloWorld!”);
20}
21}
22}
结果
1CaughtAnnoyance
2CaughtSneeze
3HelloWorld!
10.常见的RuntimeException有哪些?
ClassCastException(类转换异常)
IndexOutOfBoundsException(数组越界)
NullPointerException(空指针)
ArrayStoreException(数据存储异常,操作数组时类型不一致)
还有IO操作的BufferOverflowException异常
11.Java常见异常有哪些
Java.lang.IllegalAccessError:违法访问错误。当一个应用试图访问、修改某个类的域(Field)或者调用其方法,但是又违反域或方法的可见性声明,则抛出该异常。
Java.lang.InstantiationError:实例化错误。当一个应用试图通过Java的new操作符构造一个抽象类或者接口时抛出该异常.
Java.lang.OutOfMemoryError:内存不足错误。当可用内存不足以让Java虚拟机分配给一个对象时抛出该错误。
Java.lang.StackOverflowError:堆栈溢出错误。当一个应用递归调用的层次太深而导致堆栈溢出或者陷入死循环时抛出该错误。
Java.lang.ClassCastException:类造型异常。假设有类A和B(A不是B的父类或子类),O是A的实例,那么当强制将O构造为类B的实例时抛出该异常。该异常经常被称为强制类型转换异常。
Java.lang.ClassNotFoundException:找不到类异常。当应用试图根据字符串形式的类名构造类,而在遍历CLASSPAH之后找不到对应名称的class文件时,抛出该异常。Java.lang.ArithmeticException:算术条件异常。譬如:整数除零等。
Java.lang.ArrayIndexOutOfBoundsException:数组索引越界异常。当对数组的索引值为负数或大于等于数组大小时抛出。
Java.lang.IndexOutOfBoundsException:索引越界异常。当访问某个序列的索引值小于0或大于等于序列大小时,抛出该异常。Java.lang.InstantiationException:实例化异常。当试图通过newInstance()方法创建某个类的实例,而该类是一个抽象类或接口时,抛出该异常。
Java.lang.NoSuchFieldException:属性不存在异常。当访问某个类的不存在的属性时抛出该异常。Java.lang.NoSuchMethodException:方法不存在异常。当访问某个类的不存在的方法时抛出该异常。
Java.lang.NullPointerException:空指针异常。当应用试图在要求使用对象的地方使用了null时,抛出该异常。譬如:调用null对象的实例方法、访问null对象的属性、计算null对象的长度、使用throw语句抛出null等等。
Java.lang.NumberFormatException:数字格式异常。当试图将一个String转换为指定的数字类型,而该字符串确不满足数字类型要求的格式时,抛出该异常。
Java.lang.StringIndexOutOfBoundsException:字符串索引越界异常。当使用索引值访问某个字符串中的字符,而该索引值小于0或大于等于序列大小时,抛出该异常
Java异常处理最佳实践
在Java中处理异常并不是一个简单的事情。不仅仅初学者很难理解,即使一些有经验的开发者也需要花费很多时间来思考如何处理异常,包括需要处理哪些异常,怎样处理等等。这也是绝大多数开发团队都会制定一些规则来规范进行异常处理的原因。而团队之间的这些规范往往是截然不同的。本文给出几个被很多团队使用的异常处理佳实践。
1.在finally块中清理资源或者使用try-with-resource语句
当使用类似InputStream这种需要使用后关闭的资源时,一个常见的错误就是在try块的后关闭资源。
1publicvoiddoNotCloseResourceInTry(){
2FileInputStreaminputStream=null;
3try{
4Filefile=newFile(“./tmp.txt”);
5inputStream=newFileInputStream(file);
6//usetheinputStreamtoreadafile
7//doNOTdothis
8inputStream.close();
9}catch(FileNotFoundExceptione){
10log.error(e);
11}catch(IOExceptione){
12log.error(e);
13}
14}
问题就是,只有没有异常抛出的时候,这段代码才可以正常工作。try代码块内代码会正常执行,并且资源可以正常关闭。但是,使用try代码块是有原因的,一般调用一个或多个可能抛出异常的方法,而且,你自己也可能会抛出一个异常,这意味着代码可能不会执行到try代码块的后部分。结果就是,你并没有关闭资源。
所以,你应该把清理工作的代码放到finally里去,或者使用try-with-resource特性。
1.1使用finally代码块
与前面几行try代码块不同,finally代码块总是会被执行。不管try代码块成功
执行之后还是你在catch代码块中处理完异常后都会执行。因此,你可以确保你清理了所有打开的资源。
1publicvoidcloseResourceInFinally(){
2FileInputStreaminputStream=null;
3try{
4Filefile=newFile(“./tmp.txt”);
5inputStream=newFileInputStream(file);6//usetheinputStreamtoreadafile
7}catch(FileNotFoundExceptione){
8log.error(e);9}finally{
10if(inputStream!=null){
11try{
12inputStream.close();
13}catch(IOExceptione){
14log.error(e);
15}
16}
17}
18}
1.2Java7的try-with-resource语法
如果你的资源实现了AutoCloseable接口,你可以使用这个语法。大多数的Java标准资源都继承了这个接口。当你在try子句中打开资源,资源会在try代码块执行后或异常处理后自动关闭。
1publicvoidautomaticallyCloseResource(){
2Filefile=newFile(“./tmp.txt”);
3try(FileInputStreaminputStream=newFileInputStream(file);){
4//usetheinputStreamtoreadafile
5}catch(FileNotFoundExceptione){
6log.error(e);
7}catch(IOExceptione){
8log.error(e);
9}
10}
11
2.优先明确的异常
你抛出的异常越明确越好,永远记住,你的同事或者几个月之后的你,将会调用你的方法并且处理异常。
因此需要保证提供给他们尽可能多的信息。这样你的API更容易被理解。你的方法的调用者能够更好的处理异常并且避免额外的检查。因此,总是尝试寻找适合你的异常事件的类,例如,抛出一个
NumberFormatException来替换一个IllegalArgumentException。避免抛出一个不明确的异常。
1publicvoiddoNotDoThis()throwsException{
2…
3}
4publicvoiddoThis()throwsNumberFormatException{
5…
6}
7
3.对异常进行文档说明
当在方法上声明抛出异常时,也需要进行文档说明。目的是为了给调用者提供尽可能多的信息,从而可以更好地避免或处理异常。
在Javadoc添加@throws声明,并且描述抛出异常的场景。
1publicvoiddoSomething(Stringinput)throwsMyBusinessException{2…
3}
4.使用描述性消息抛出异常
在抛出异常时,需要尽可能精确地描述问题和相关信息,这样无论是打印到日志中还是在监控工具中,都能够更容易被人阅读,从而可以更好地定位具体错误信息、错误的严重程度等。
但这里并不是说要对错误信息长篇大论,因为本来Exception的类名就能够反映错误的原因,因此只需要用一到两句话描述即可。
如果抛出一个特定的异常,它的类名很可能已经描述了这种错误。所以,你不需要提供很多额外的信息。一个很好的例子是NumberFormatException。当你以错误的格式提供String时,它将被Java.lang.Long类的构造函数抛出。
1try{
2newLong(“xyz”);
3}catch(NumberFormatExceptione){
4log.error(e);
5}
5.优先捕获最具体的异常
大多数IDE都可以帮助你实现这个佳实践。当你尝试首先捕获较不具体的异常时,它们会报告无法访问的代码块。
但问题在于,只有匹配异常的第一个catch块会被执行。因此,如果首先捕获
IllegalArgumentException,则永远不会到达应该处理更具体的NumberFormatException的catch块,因为它是IllegalArgumentException的子类。总是优先捕获具体的异常类,并将不太具体的catch块添加到列表的末尾。你可以在下面的代码片断中看到这样一个try-catch语句的例子。第一个catch块处理所有NumberFormatException异常,第二个处理所有非
NumberFormatException异常的IllegalArgumentException异常。
1publicvoidcatchMostSpecificExceptionFirst(){
2try{
3doSomething(“Amessage”);
4}catch(NumberFormatExceptione){
5log.error(e);
6}catch(IllegalArgumentExceptione){
7log.error(e)
8}
9}
6.不要捕获Throwable类
Throwable是所有异常和错误的超类。你可以在catch子句中使用它,但是你
永远不应该这样做!
如果在catch子句中使用Throwable,它不仅会捕获所有异常,也将捕获所有的错误。JVM抛出错误,指出不应该由应用程序处理的严重问题。典型的例子是OutOfMemoryError或者StackOverflowError。两者都是由应用程序控制之外的情况引起的,无法处理。
所以,好不要捕获Throwable,除非你确定自己处于一种特殊的情况下能够处理错误。
1publicvoiddoNotCatchThrowable(){
2try{
3//dosomething
4}catch(Throwablet){
5//don’tdothis!
6}
7}
很多时候,开发者很有自信不会抛出异常,因此写了一个catch块,但是没有做任何处理或者记录日志。
如上所示,后面的日志也没有附加更有用的信息。如果想要提供更加有用的信息,那么可以将异常包装为自定义异常。
10.不要使用异常控制程序的流程
不应该使用异常控制应用的执行流程,例如,本应该使用if语句进行条件判断的情况下,你却使用异常处理,这是非常不好的习惯,会严重影响应用的性能。
11.使用标准异常
如果使用内建的异常可以解决问题,就不要定义自己的异常。JavaAPI提供了上百种针对不同情况的异常类型,在开发中首先尽可能使用JavaAPI提供的异常,如果标准的异常不能满足你的要求,这时候创建自己的定制异常。尽可能得使用标准异常有利于新加入的开发者看懂项目代码。
12.异常会影响性能
异常处理的性能成本非常高,每个Java程序员在开发时都应牢记这句话。创建一个异常非常慢,抛出一个异常又会消耗1~5ms,当一个异常在应用的多个层级之间传递时,会拖累整个应用的性能。
仅在异常情况下使用异常;
在可恢复的异常情况下使用异常;尽管使用异常有利于Java开发,但是在应用中好不要捕获太多的调用栈,因为在很多情况下都不需要打印调用栈就知道哪里出错了。因此,异常消息应该提供恰到好处的信息。
13.总结
综上所述,当你抛出或捕获异常的时候,有很多不同的情况需要考虑,而且大部分事情都是为了改善代码的可读性或者API的可用性。
异常不仅仅是一个错误控制机制,也是一个通信媒介。因此,为了和同事更好的合作,一个团队必须要制定出一个佳实践和规则,只有这样,团队成员才能理解这些通用概念,同时在工作中使用它。
异常处理-阿里巴巴Java开发手册
1.【强制】Java类库中定义的可以通过预检查方式规避的
RuntimeException异常不应该通过catch的方式来处理,比如:
NullPointerException,IndexOutOfBoundsException等等。说明:无法通过预检查的异常除外,比如,在解析字符串形式的数字时,可能存在数字格式错误,不得不通过catchNumberFormatException来实现。正例:if(obj!=null){…}反例:try{obj.method();}catch
(NullPointerExceptione){…}
2.【强制】异常不要用来做流程控制,条件控制。说明:异常设计的初衷是解决程序运行中的各种意外情况,且异常的处理效率比条件判断方式要低很多。
3.【强制】catch时请分清稳定代码和非稳定代码,稳定代码指的是无论如何不会出错的代码。对于非稳定代码的catch尽可能进行区分异常类型,
再做对应的异常处理。说明:对大段代码进行try-catch,使程序无法根据不同的异常做出正确的应激反应,也不利于定位问题,这是一种不负责任的表现。正例:用户注册的场景中,如果用户输入非法字符,或用户名称已存在,或用户输入密码过于简单,在程序上作出分门别类的判断,并提示给用户。
4.【强制】捕获异常是为了处理它,不要捕获了却什么都不处理而抛弃之,如果不想处理它,请将该异常抛给它的调用者。外层的业务使用者,必须处理异常,将其转化为用户可以理解的内容。
5.【强制】有try块放到了事务代码中,catch异常后,如果需要回滚事务,一定要注意手动回滚事务。
6.【强制】finally块必须对资源对象、流对象进行关闭,有异常也要做try-catch。说明:如果JDK7及以上,可以使用try-with-resources方式。
7.【强制】不要在finally块中使用return。说明:try块中的return语句执行成功后,并不马上返回,而是继续执行finally块中的语句,如果此处存在return语句,则在此直接返回,无情丢弃掉try块中的返回点。反例:
1privateintx=0;
2publicintcheckReturn(){
3try{
4//x等于1,此处不返回
5return++x;
6}finally{
7//返回的结果是2
8return++x;
9}
10}
1.【强制】捕获异常与抛异常,必须是完全匹配,或者捕获异常是抛异常的父类。说明:如果预期对方抛的是绣球,实际接到的是铅球,就会产生意外情况。
2.【强制】在调用RPC、二方包、或动态生成类的相关方法时,捕捉异常必须使用Throwable类来进行拦截。说明:通过反射机制来调用方法,如果找不到方法,抛出NoSuchMethodException。什么情况会抛出
NoSuchMethodError呢?二方包在类冲突时,仲裁机制可能导致引入非预期的版本使类的方法签名不匹配,或者在字节码修改框架(比如:
ASM)动态创建或修改类时,修改了相应的方法签名。这些情况,即使代码编译期是正确的,但在代码运行期时,会抛出NoSuchMethodError。
3.【推荐】方法的返回值可以为null,不强制返回空集合,或者空对象等,必须添加注释充分说明什么情况下会返回null值。说明:本手册明确防止NPE是调用者的责任。即使被调用方法返回空集合或者空对象,对调用者来说,也并非高枕无忧,必须考虑到远程调用失败、序列化失败、运行时异常等场景返回null的情况。
4.【推荐】防止NPE,是程序员的基本修养,注意NPE产生的场景:1)返回类型为基本数据类型,return包装数据类型的对象时,自动拆箱有可能产生NPE。反例:publicintf(){returnInteger对象},如果为null,自动解箱抛NPE。2)数据库的查询结果可能为null。3)集合里的元素即使isNotEmpty,取出的数据元素也可能为null。4)远程调用返回对象时,一律要求进行空指针判断,防止NPE。5)对于Session中获取的数据,建议进行NPE检查,避免空指针。6)级联调用
obj.getA().getB().getC();一连串调用,易产生NPE。
正例:使用JDK8的Optional类来防止NPE问题。
5.【推荐】定义时区分unchecked/checked异常,避免直接抛出new
RuntimeException(),更不允许抛出Exception或者Throwable,应使用有业务含义的自定义异常。推荐业界已定义过的自定义异常,如:
DAOException/ServiceException等。
6.【参考】对于公司外的http/api开放接口必须使用“错误码”;而应用内部推荐异常抛出;跨应用间RPC调用优先考虑使用Result方式,封装isSuccess()方法、“错误码”、“错误简短信息”。说明:关于RPC方法返回方式使用Result方式的理由:1)使用抛异常返回方式,调用方如果没有捕获到就会产生运行时错误。2)如果不加栈信息,只是new自定义异常,加入自己的理解的errormessage,对于调用端解决问题的帮助不会太多。如果加了栈信息,在频繁调用出错的情况下,数据序列化和传输的性能损耗也是问题。
7.【参考】避免出现重复的代码(Don’tRepeatYourself),即DRY原则。说明:随意复制和粘贴代码,必然会导致代码的重复,在以后需要修改时,需要修改所有的副本,容易遗漏。必要时抽取共性方法,或者抽象公共类,甚至是组件化。正例:一个类中有多个public方法,都需要进行数行相同的参数校验操作,这个时候请抽取:privatebooleancheckParam(DTOdto){…}
Tomcat是什么?
Tomcat服务器Apache软件基金会项目中的一个核心项目,是一个免费的开放源代码的Web应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP程序的首选。
Tomcat的缺省端口是多少,怎么修改
找到Tomcat目录下的conf文件夹
进入conf文件夹里面找到server.xml文件
打开server.xml文件
在server.xml文件里面找到下列信息
把Connector标签的8080端口改成你想要的端口
tomcat有哪几种Connector运行模式(优化)?
下面,我们先大致了解TomcatConnector的三种运行模式。
BIO:同步并阻塞一个线程处理一个请求。缺点:并发量高时,线程数较多,浪费资源。Tomcat7或以下,在Linux系统中默认使用这种方式。
配制项:protocol=”HTTP/1.1”
NIO:同步非阻塞IO利用Java的异步IO处理,可以通过少量的线程处理大量的请求,可以复用同一
个线程处理多个connection(多路复用)。
Tomcat8在Linux系统中默认使用这种方式。
Tomcat7必须修改Connector配置来启动。
配制项:protocol=”org.apache.coyote.http11.Http11NioProtocol”
备注:我们常用的Jetty,Mina,ZooKeeper等都是基于Javanio实现.
APR:即ApachePortableRuntime,从操作系统层面解决io阻塞问题。AIO方式,异步非阻塞
IO(JavaNIO2又叫AIO)主要与NIO的区别主要是操作系统的底层区别.可以做个比喻:比作快递,NIO就是网购后要自己到官网查下快递是否已经到了(可能是多次),然后自己去取快递;AIO就是快递员送货上门了(不用关注快递进度)。
配制项:protocol=”org.apache.coyote.http11.Http11AprProtocol”
备注:需在本地服务器安装APR库。Tomcat7或Tomcat8在Win7或以上的系统中启动默认使用这种方式。Linux如果安装了apr和native,Tomcat直接启动就支持apr。
Tomcat有几种部署方式?
在Tomcat中部署Web应用的方式主要有如下几种:
利用Tomcat的自动部署。
把web应用拷贝到webapps目录。Tomcat在启动时会加载目录下的应用,并将编译后的结果放入
work目录下。
使用ManagerApp控制台部署。
在tomcat主页点击“ManagerApp”进入应用管理控制台,可以指定一个web应用的路径或war文件。
修改conf/server.xml文件部署。
修改conf/server.xml文件,增加Context节点可以部署应用。
增加自定义的Web部署文件。
在conf/Catalina/localhost/路径下增加xyz.xml文件,内容是Context节点,可以部署应用
tomcat容器是如何创建servlet类实例?用到了什么原
理?
1.当容器启动时,会读取在webapps目录下所有的web应用中的web.xml文件,然后对xml文件进行解析,并读取servlet注册信息。然后,将每个应用中注册的servlet类都进行加载,并通过反射的方式实例化。(有时候也是在第一次请求时实例化)
2.在servlet注册时加上1如果为正数,则在一开始就实例化,如果不写或为负数,则第一次请求实例化。
Tomcat工作模式
Tomcat作为servlet容器,有三种工作模式:
1.独立的servlet容器,servlet容器是web服务器的一部分;
2.进程内的servlet容器,servlet容器是作为web服务器的插件和Java容器的实现,web服务器插件在内部地址空间打开一个jvm使得Java容器在内部得以运行。反应速度快但伸缩性不足;
3.进程外的servlet容器,servlet容器运行于web服务器之外的地址空间,并作为web服务器的插件和Java容器实现的结合。反应时间不如进程内但伸缩性和稳定性比进程内优;进入Tomcat的请求可以根据Tomcat的工作模式分为如下两类:
Tomcat作为应用程序服务器:请求来自于前端的web服务器,这可能是Apache,IIS,Nginx等;
Tomcat作为独立服务器:请求来自于web浏览器;
面试时问到Tomcat相关问题的几率并不高,正式因为如此,很多人忽略了对Tomcat相关技能的掌握,下面这一篇文章整理了Tomcat相关的系统架构,介绍了Server、Service、Connector、Container之间的关系,各个模块的功能,可以说把这几个掌握住了,Tomcat相关的面试题你就不会有任何问题了!
另外,在面试的时候你还要有意识无意识的往Tomcat这个地方引,就比如说常见的SpringMVC的执行
流程,一个URL的完整调用链路,这些相关的题目你是可以往Tomcat处理请求的这个过程去说的!掌握
了Tomcat这些技能,面试官一定会佩服你的!
学了本章之后你应该明白的是:
Server、Service、Connector、Container四大组件之间的关系和联系,以及他们的主要功能点;Tomcat执行的整体架构,请求是如何被一步步处理的;
Engine、Host、Context、Wrapper相关的概念关系;
Container是如何处理请求的;
Tomcat用到的相关设计模式;
Tomcat顶层架构
俗话说,站在巨人的肩膀上看世界,一般学习的时候也是先总览一下整体,然后逐个部分个个击破,最后形成思路,了解具体细节,Tomcat的结构很复杂,但是Tomcat非常的模块化,找到了Tomcat最核心的模块,问题才可以游刃而解,了解了Tomcat的整体架构对以后深入了解Tomcat来说至关重要!先上一张Tomcat的顶层结构图(图A),如下:
Tomcat中最顶层的容器是Server,代表着整个服务器,从上图中可以看出,一个Server可以包含至少一个Service,即可以包含多个Service,用于具体提供服务。
Service主要包含两个部分:Connector和Container。从上图中可以看出Tomcat的心脏就是这两个组件,他们的作用如下:
Connector用于处理连接相关的事情,并提供Socket与Request请求和Response响应相关的转化;Container用于封装和管理Servlet,以及具体处理Request请求;
一个Tomcat中只有一个Server,一个Server可以包含多个Service,一个Service只有一个Container,但是可以有多个Connectors,这是因为一个服务可以有多个连接,如同时提供Http和Https链接,也可以提供向相同协议不同端口的连接,示意图如下(Engine、Host、Context下面会说到):
多个Connector和一个Container就形成了一个Service,有了Service就可以对外提供服务了,但是Service还要一个生存的环境,必须要有人能够给她生命、掌握其生死大权,那就非Server莫属了!所以整个Tomcat的生命周期由Server控制。
另外,上述的包含关系或者说是父子关系,都可以在tomcat的conf目录下的server.xml配置文件中看出,下图是删除了注释内容之后的一个完整的server.xml配置文件(Tomcat版本为8.0)
详细的配置文件内容可以到Tomcat官网查看:Tomcat配置文件
上边的配置文件,还可以通过下边的一张结构图更清楚的理解:
Server标签设置的端口号为8005,shutdown=”SHUTDOWN”,表示在8005端口监听“SHUTDOWN”命令,如果接收到了就会关闭Tomcat。一个Server有一个Service,当然还可以进行配置,一个Service有多个Connector,Service左边的内容都属于Container的,Service下边是Connector。
Tomcat顶层架构小结
1.Tomcat中只有一个Server,一个Server可以有多个Service,一个Service可以有多个Connector和一个Container;
2.Server掌管着整个Tomcat的生死大权;
3.Service是对外提供服务的;
4.Connector用于接受请求并将请求封装成Request和Response来具体处理;
5.Container用于封装和管理Servlet,以及具体处理request请求;
知道了整个Tomcat顶层的分层架构和各个组件之间的关系以及作用,对于绝大多数的开发人员来说Server和Service对我们来说确实很远,而我们开发中绝大部分进行配置的内容是属于Connector和Container的,所以接下来介绍一下Connector和Container。
Connector和Container的微妙关系
由上述内容我们大致可以知道一个请求发送到Tomcat之后,首先经过Service然后会交给我们的Connector,Connector用于接收请求并将接收的请求封装为Request和Response来具体处理,Request和Response封装完之后再交由Container进行处理,Container处理完请求之后再返回给Connector,最后在由Connector通过Socket将处理的结果返回给客户端,这样整个请求的就处理完了!
Connector最底层使用的是Socket来进行连接的,Request和Response是按照HTTP协议来封装的,所以Connector同时需要实现TCP/IP协议和HTTP协议!
Tomcat既然需要处理请求,那么肯定需要先接收到这个请求,接收请求这个东西我们首先就需要看一下Connector!
Connector架构分析
Connector用于接受请求并将请求封装成Request和Response,然后交给Container进行处理,Container处理完之后在交给Connector返回给客户端。因此,我们可以把Connector分为四个方面进行理解:
1.Connector如何接受请求的?
2.如何将请求封装成Request和Response的?
3.封装完之后的Request和Response如何交给Container进行处理的?
4.Container处理完之后如何交给Connector并返回给客户端的?首先看一下Connector的结构图,如下所示:
Connector就是使用ProtocolHandler来处理请求的,不同的ProtocolHandler代表不同的连接类型,比如:Http11Protocol使用的是普通Socket来连接的,Http11NioProtocol使用的是NioSocket来连接的。
其中ProtocolHandler由包含了三个部件:Endpoint、Processor、Adapter。
1.Endpoint用来处理底层Socket的网络连接,Processor用于将Endpoint接收到的Socket封装成Request,Adapter用于将Request交给Container进行具体的处理。
2.Endpoint由于是处理底层的Socket网络连接,因此Endpoint是用来实现TCP/IP协议的,而Processor用来实现HTTP协议的,Adapter将请求适配到Servlet容器进行具体的处理。
3.Endpoint的抽象实现AbstractEndpoint里面定义的Acceptor和AsyncTimeout两个内部类和一个Handler接口。Acceptor用于监听请求,AsyncTimeout用于检查异步Request的超时,Handler用于处理接收到的Socket,在内部调用Processor进行处理。
至此,我们应该很轻松的回答1,2,3的问题了,但是4还是不知道,那么我们就来看一下Container是如何进行处理的以及处理完之后是如何将处理完的结果返回给Connector的?
Container架构分析
Container用于封装和管理Servlet,以及具体处理Request请求,在Container内部包含了4个子容器,结构图如下:
4个子容器的作用分别是:
1.Engine:引擎,用来管理多个站点,一个Service最多只能有一个Engine;
2.Host:代表一个站点,也可以叫虚拟主机,通过配置Host就可以添加站点;
3.Context:代表一个应用程序,对应着平时开发的一套程序,或者一个WEB-INF目录以及下面的web.xml文件;
4.Wrapper:每一Wrapper封装着一个Servlet;下面找一个Tomcat的文件目录对照一下,如下图所示:
Context和Host的区别是Context表示一个应用,我们的Tomcat中默认的配置下webapps下的每一个文件夹目录都是一个Context,其中ROOT目录中存放着主应用,其他目录存放着子应用,而整个webapps就是一个Host站点。
我们访问应用Context的时候,如果是ROOT下的则直接使用域名就可以访问,例如:www.baidu.com,如果是Host(webapps)下的其他应用,则可以使用www.baidu.com/docs进行访问,当然默认指定的根应用(ROOT)是可以进行设定的,只不过Host站点下默认的主应用是ROOT目录下的。
看到这里我们知道Container是什么,但是还是不知道Container是如何进行请求处理的以及处理完之后是如何将处理完的结果返回给Connector的?别急!下边就开始探讨一下Container是如何进行处理的!
Container如何处理请求的
Container处理请求是使用Pipeline-Valve管道来处理的!(Valve是阀门之意)
Pipeline-Valve是责任链模式,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将处理后的结果返回,再让下一个处理者继续处理。
但是!Pipeline-Valve使用的责任链模式和普通的责任链模式有些不同!区别主要有以下两点:
每个Pipeline都有特定的Valve,而且是在管道的最后一个执行,这个Valve叫做BaseValve,BaseValve是不可删除的;
在上层容器的管道的BaseValve中会调用下层容器的管道。
我们知道Container包含四个子容器,而这四个子容器对应的BaseValve分别
在:StandardEngineValve、StandardHostValve、StandardContextValve、
StandardWrapperValve。
Pipeline的处理流程图如下:
Connector在接收到请求后会首先调用最顶层容器的Pipeline来处理,这里的最顶层容器的Pipeline就是EnginePipeline(Engine的管道);
在Engine的管道中依次会执行EngineValve1、EngineValve2等等,最后会执行StandardEngineValve,在StandardEngineValve中会调用Host管道,然后再依次执行Host的HostValve1、HostValve2等,最后在执行StandardHostValve,然后再依次调用Context的管道和Wrapper的管道,最后执行到StandardWrapperValve。
当执行到StandardWrapperValve的时候,会在StandardWrapperValve中创建FilterChain,并调
用其doFilter方法来处理请求,这个FilterChain包含着我们配置的与请求相匹配的Filter和Servlet,其doFilter方法会依次调用所有的Filter的doFilter方法和Servlet的service方法,这样请
求就得到了处理!
当所有的Pipeline-Valve都执行完之后,并且处理完了具体的请求,这个时候就可以将返回的结果
交给Connector了,Connector在通过Socket的方式将结果返回给客户端。

若有收获,就点个赞吧
0 人点赞
