一、Redis缓存
1、缓存使用
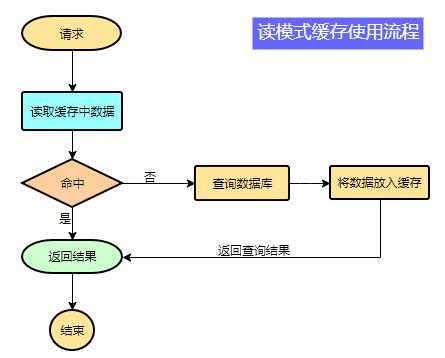
为了系统性能的提升,我们一般都会将部分数据放入缓存中,加速访问。而 db 承担数据落
盘工作。
哪些数据适合放入缓存?
1、即时性、数据一致性要求不高的
2、访问量大且更新频率不高的数据(读多,写少)
举例:电商类应用,商品分类,商品列表等适合缓存并加一个失效时间(根据数据更新频率
来定),后台如果发布一个商品,买家需要 5 分钟才能看到新的商品一般还是可以接受的。
data = cache.load(id); //从缓存加载数据If(data == null){data = db.load(id); //从数据库加载数据cache.put(id,data); //保存到 cache 中}return data;
注意:在开发中,凡是放入缓存中的数据我们都应该指定过期时间,使其可以在系统即使没有主动更新数据也能自动触发数据加载进缓存的流程。避免业务崩溃导致的数据永久不一致问题。
2、整合 redis 作为缓存

产生堆外内存溢出: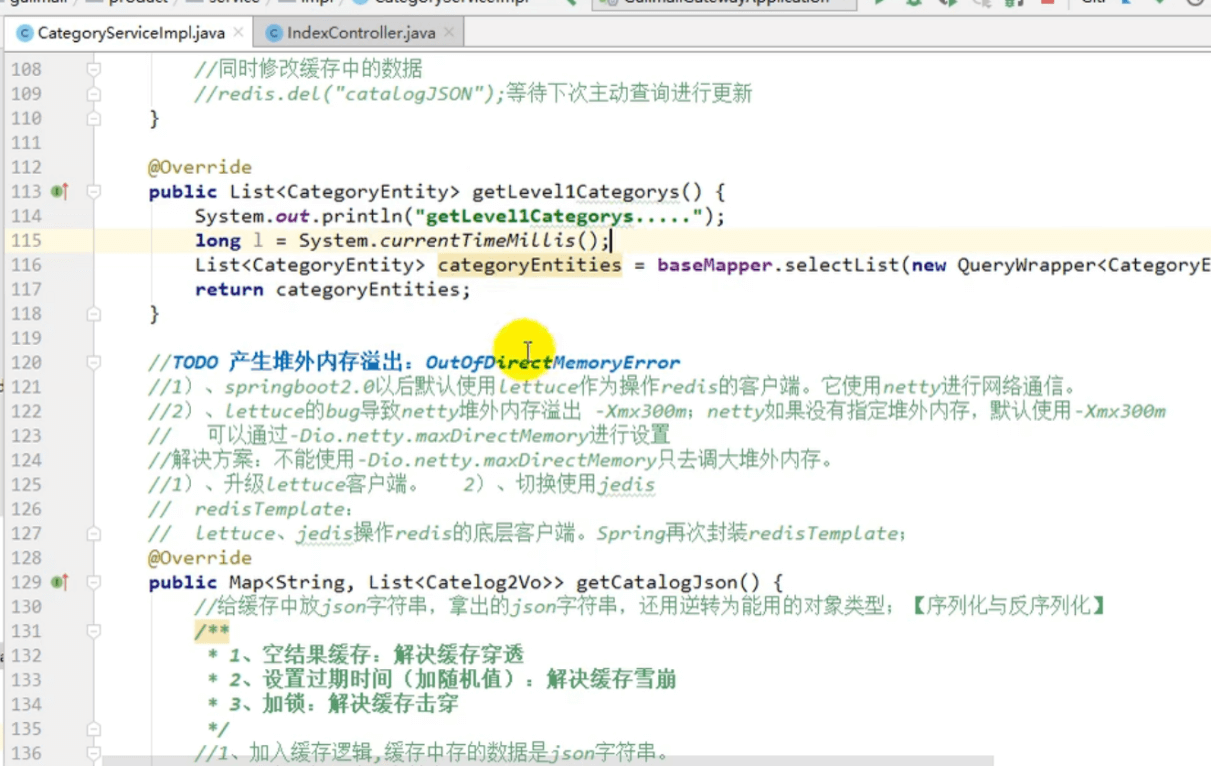
二、缓存失效问题
1、缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的null写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。l
解决:
缓存空结果、并且设置短的过期时间。布隆过滤器、mvc拦截器
2、缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB 瞬时压力过重雪崩。
解决:
- 规避雪崩:缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同缓存数据库中。
- 设置热点数据永远不过期。
- 出现雪崩:降级 熔断
- 事前:尽量保证整个redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
-
3、缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。
这个时候,需要考虑一个问题:如果这个key在大量请求同时进来前正好失效,那么所有对这个key 的数据查询都落到 db,我们称为缓存击穿
解决: 设置热点数据永远不过期。
- 加互斥锁:业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db去数据库加载,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
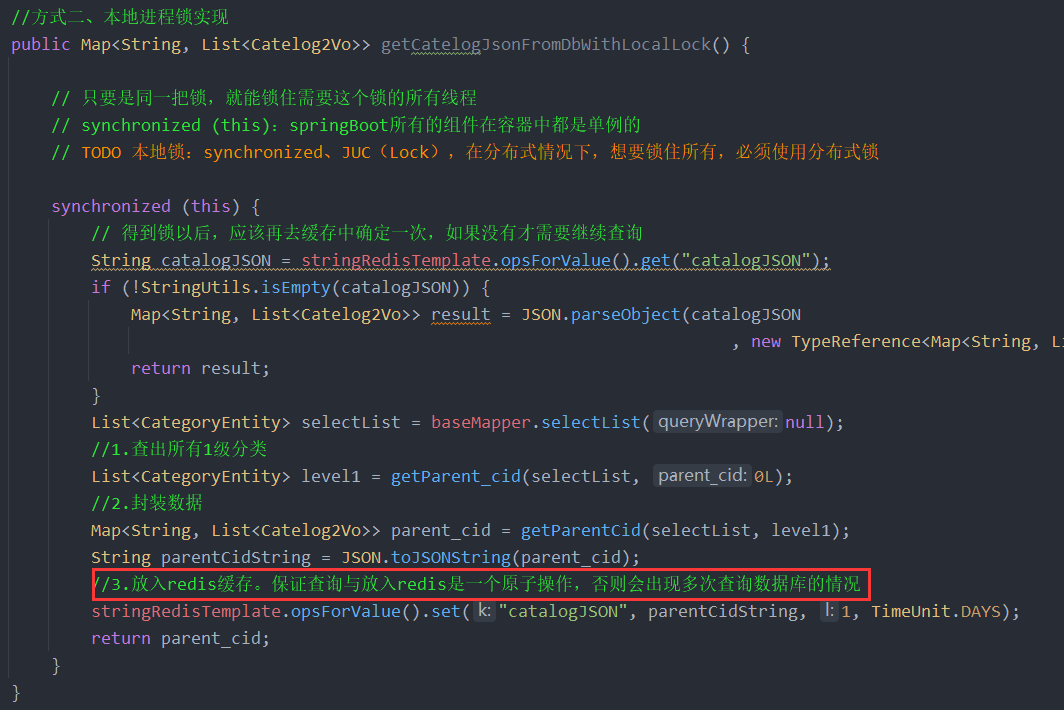
三、锁的时序问题
要保证查询数据与数据放入redis是一个原子操作,否则会出现多次查询数据库的情况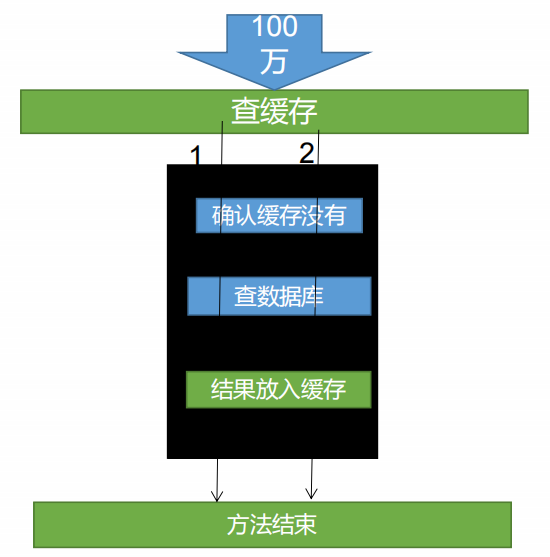
四、分布式缓存
本地缓存

本地模式在分布式下的问题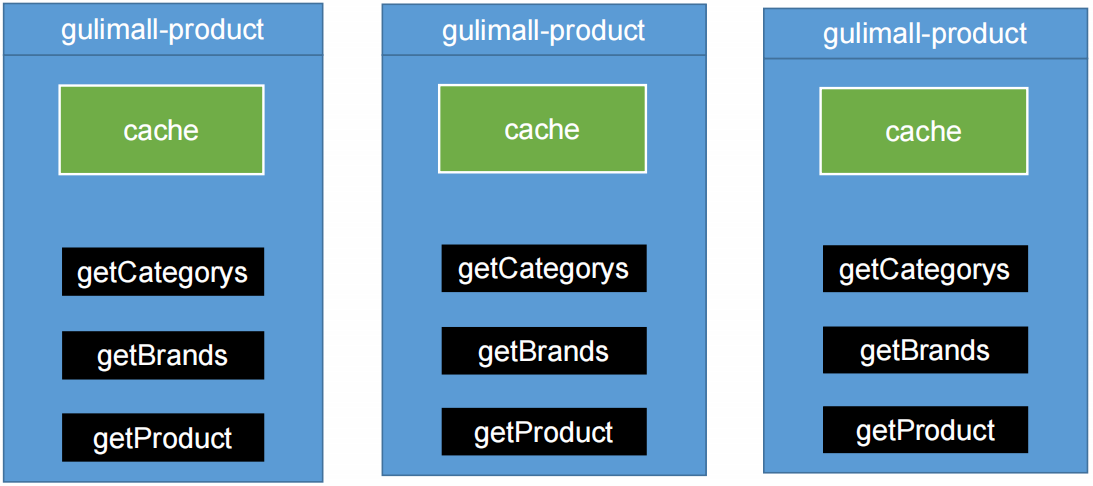
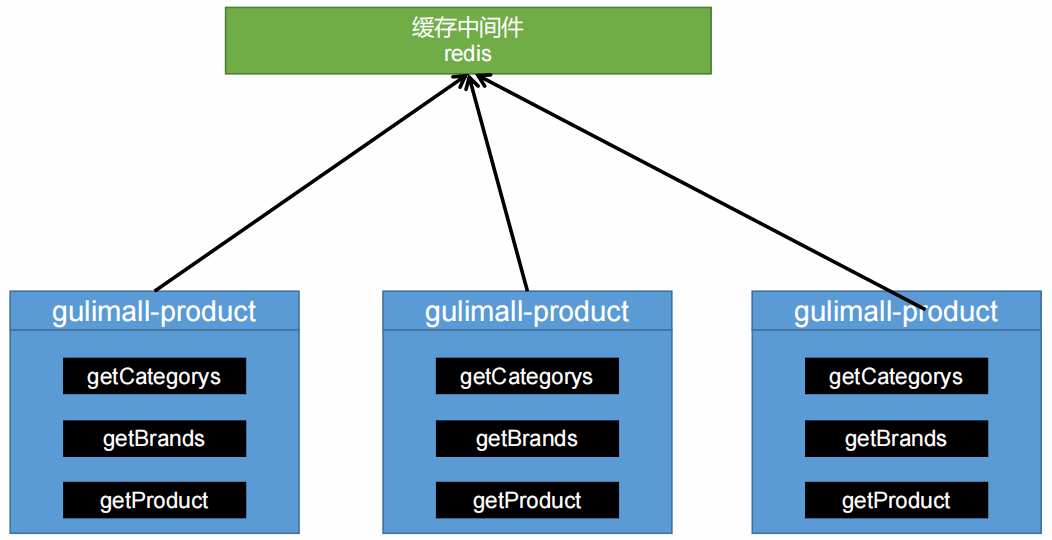
1、模拟分布式系统
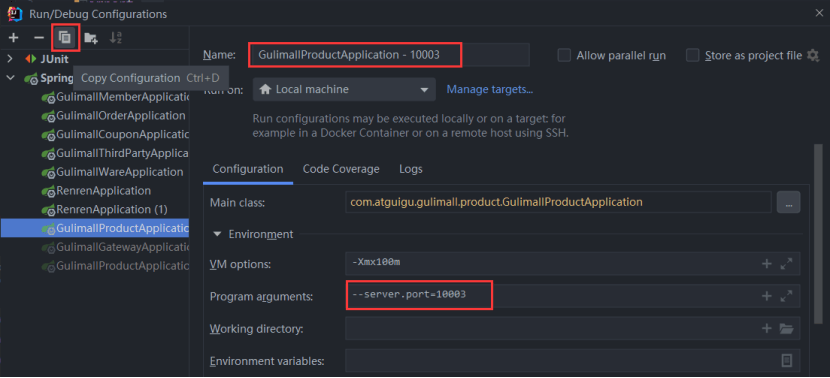
2、分布式锁与本地锁
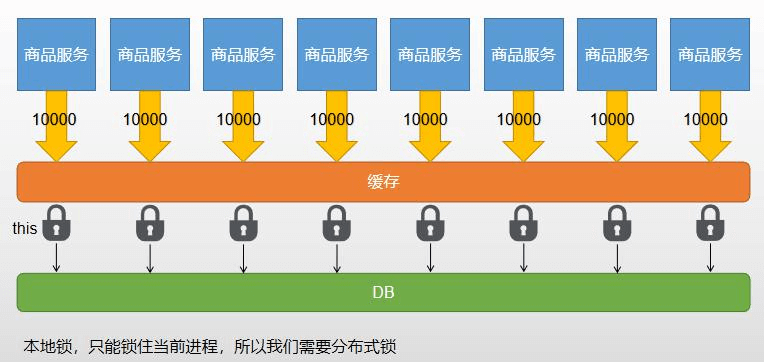
3、分布式锁原理
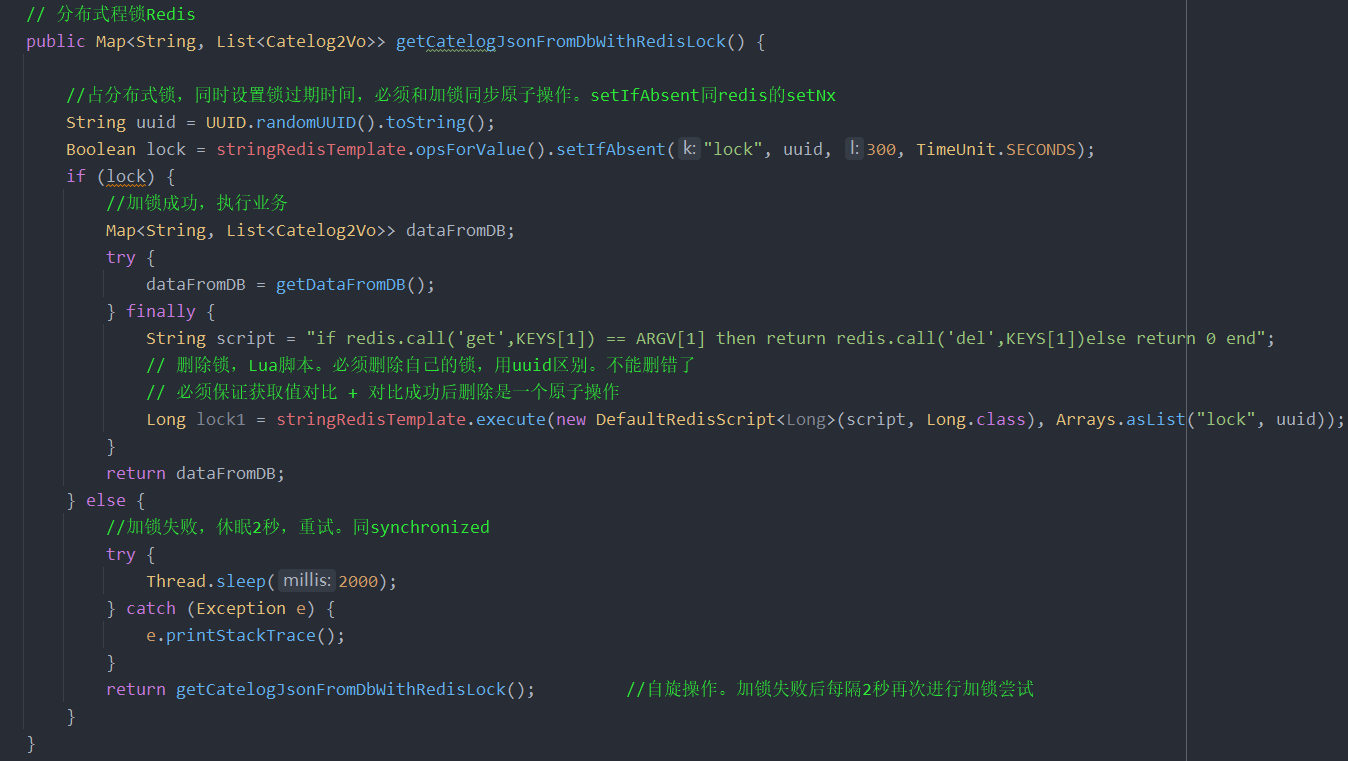
3.1 占分布式锁,同时设置锁过期时间,必须和加锁同步原子操作。setIfAbsent同redis的setNx
3.2 必须保证获取值对比+ 对比成功后删除是一个原子操作。使用Lua脚本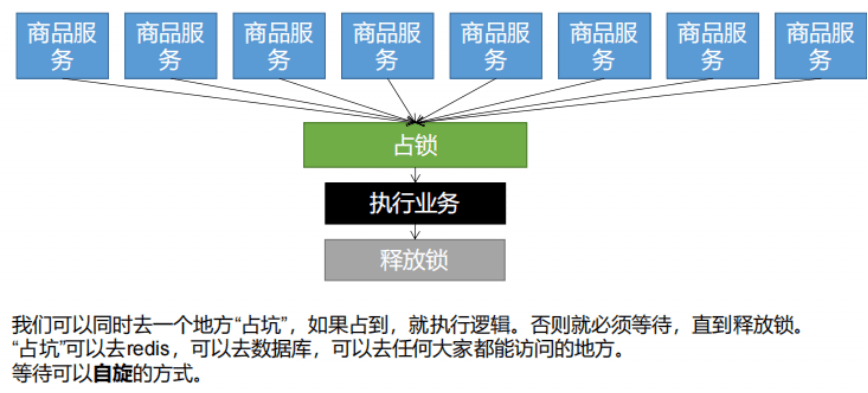
4、分布式锁演进-阶段一
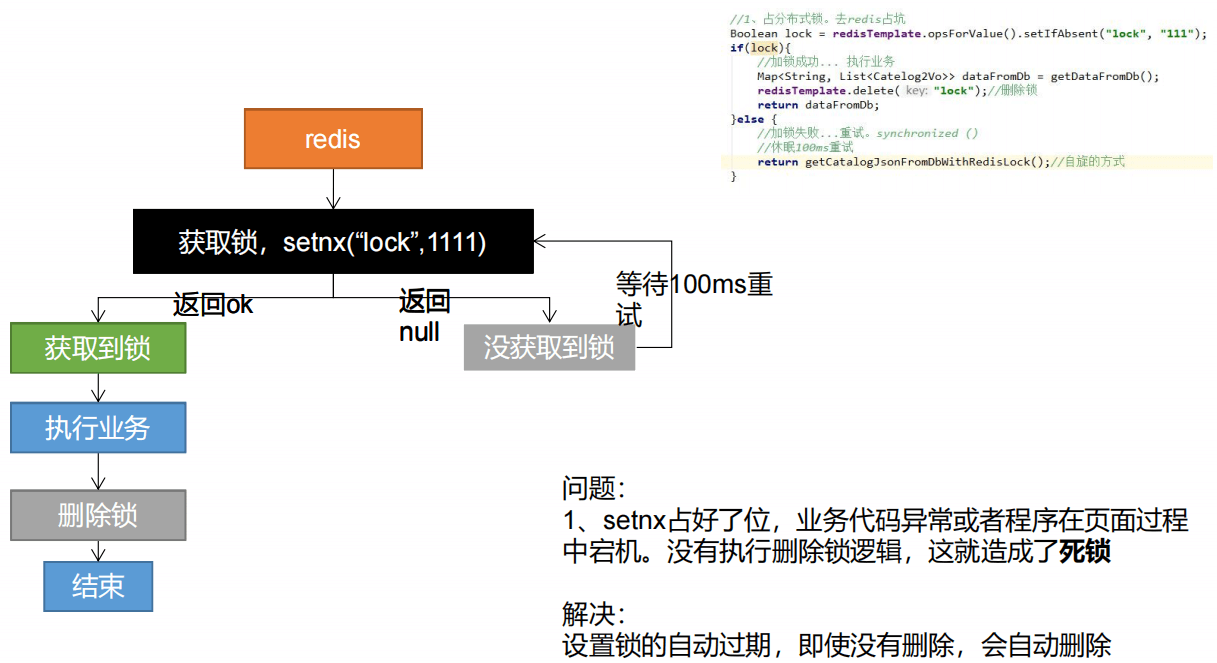
5、分布式锁演进-阶段二
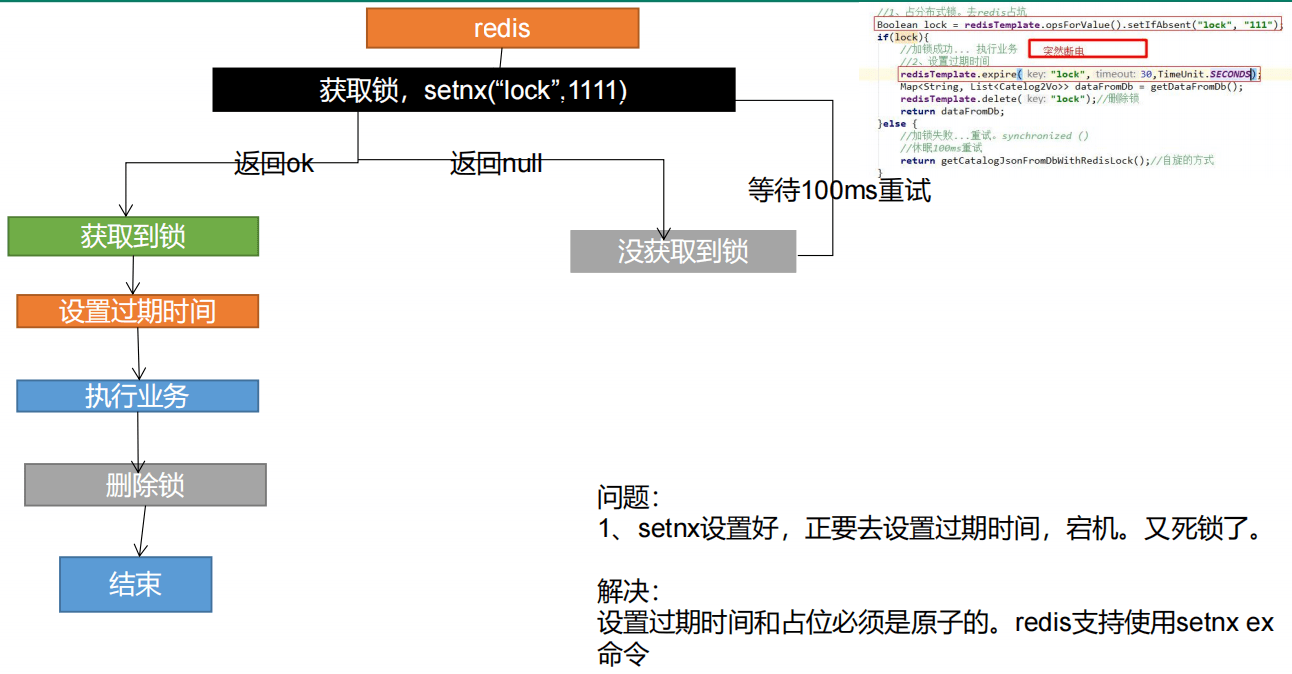
6、分布式锁演进-阶段三
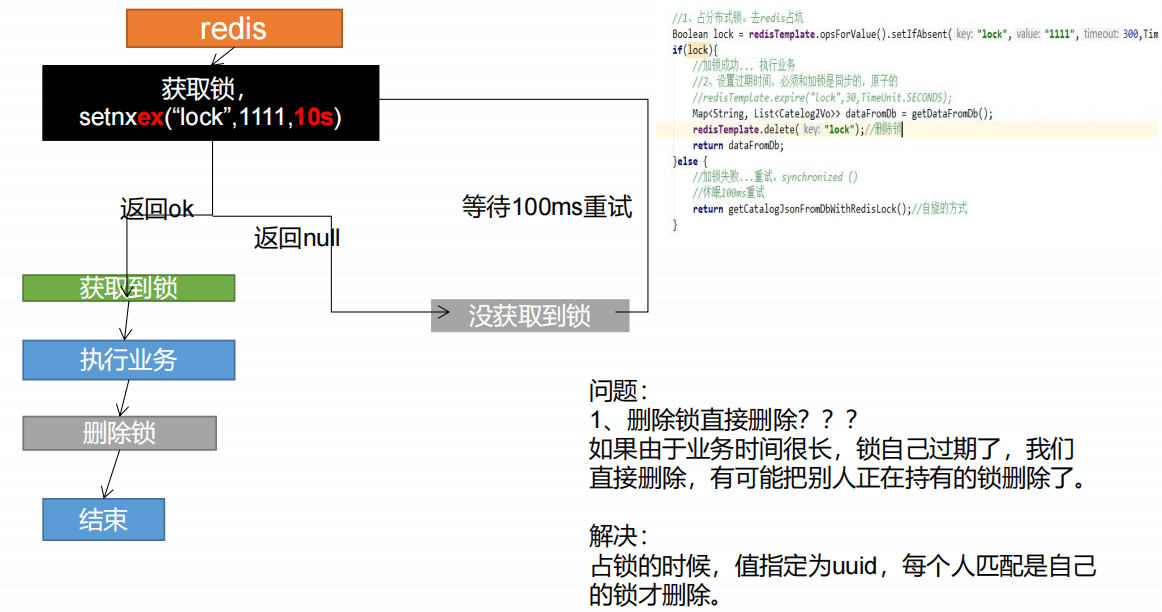
7、分布式锁演进-阶段四
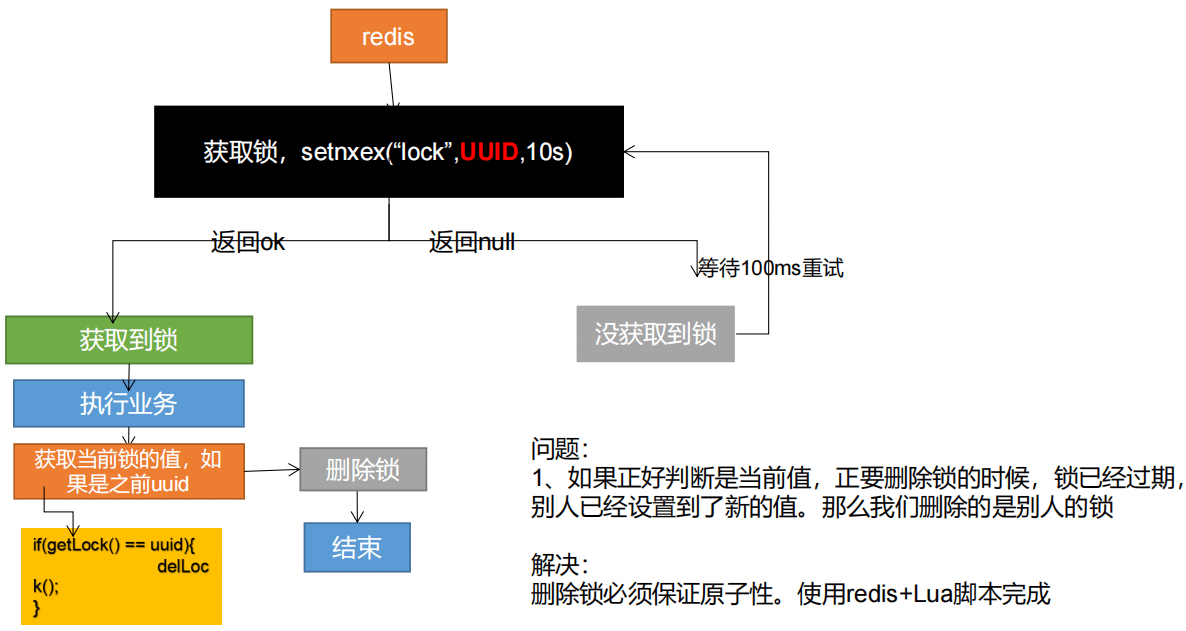
8、分布式锁演进-阶段五-最终形态
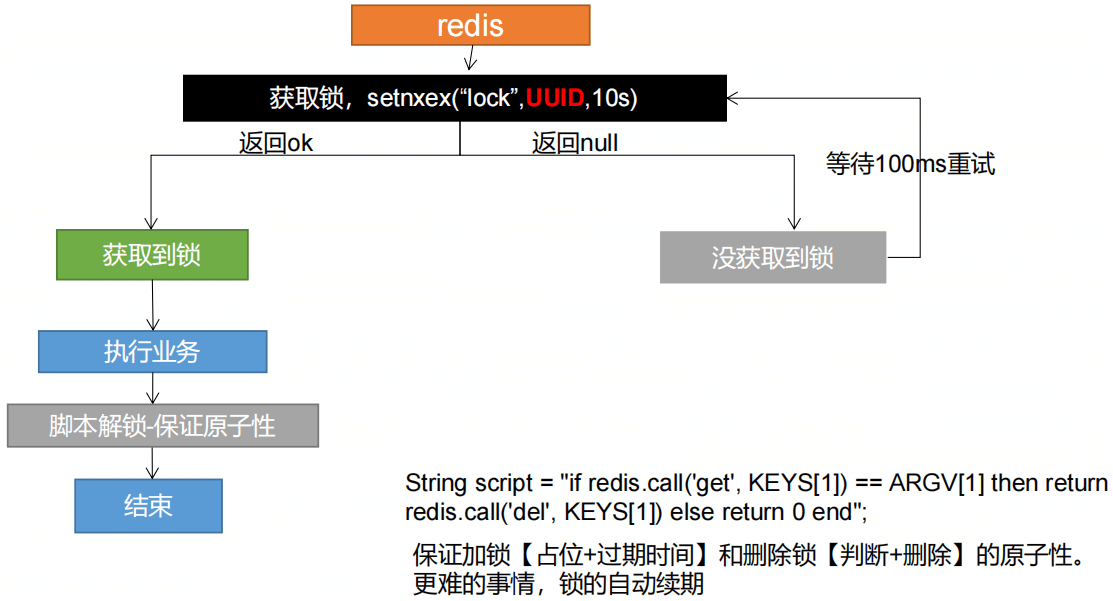
五、Redisson
1、简介
Redisson 是架设在 Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid)。充分 的利用了 Redis 键值数据库提供的一系列优势,基于 Java 实用工具包中常用接口,为使用者 提供了一系列具有分布式特性的常用工具类。使得原本作为协调单机多线程并发程序的工 具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作。
官方文档:https://github.com/redisson/redisson/wiki/%E7%9B%AE%E5%BD%95
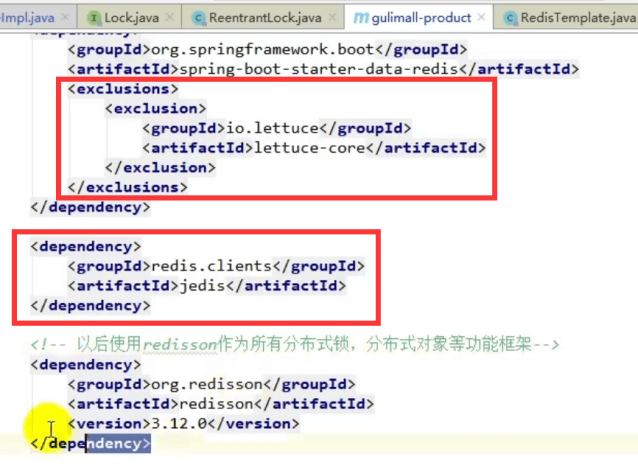
2、引入依赖
3、配置


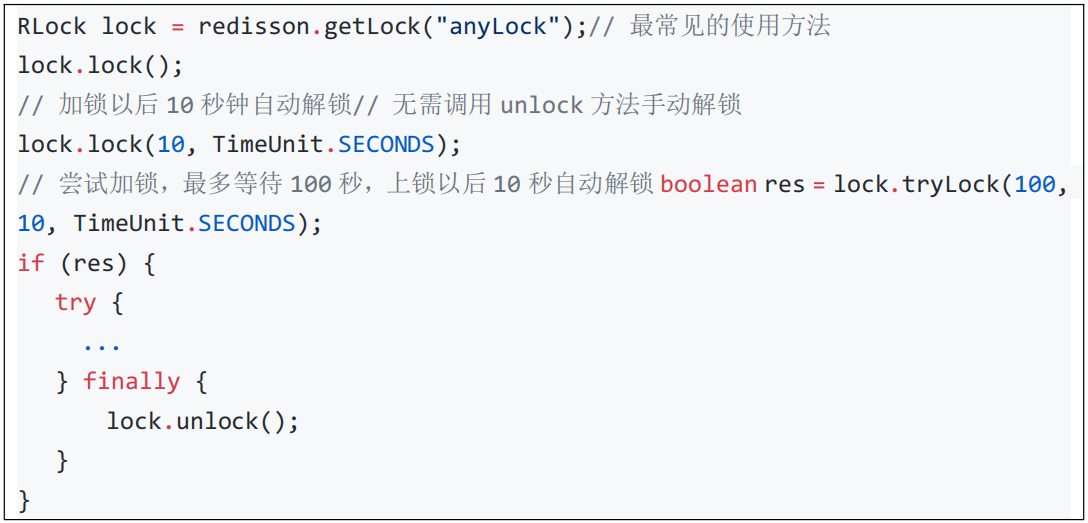
4、分布式锁测试
5、看门狗原理(可重入锁)


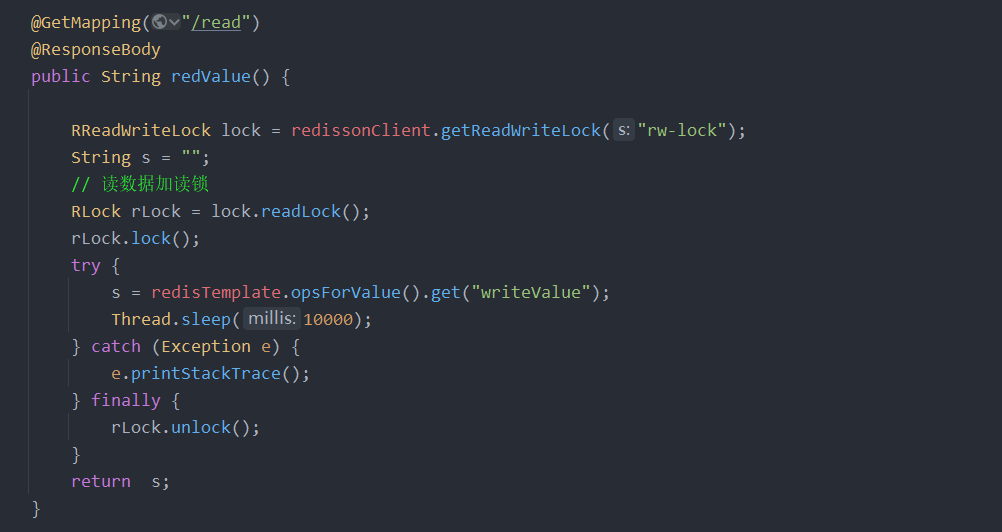
6、读写锁测试
基于Redis的Redisson分布式可重入读写锁RReadWriteLock Java对象实现了
java.util.concurrent.locks.ReadWriteLock接口。其中读锁和写锁都继承了RLock接口。
分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。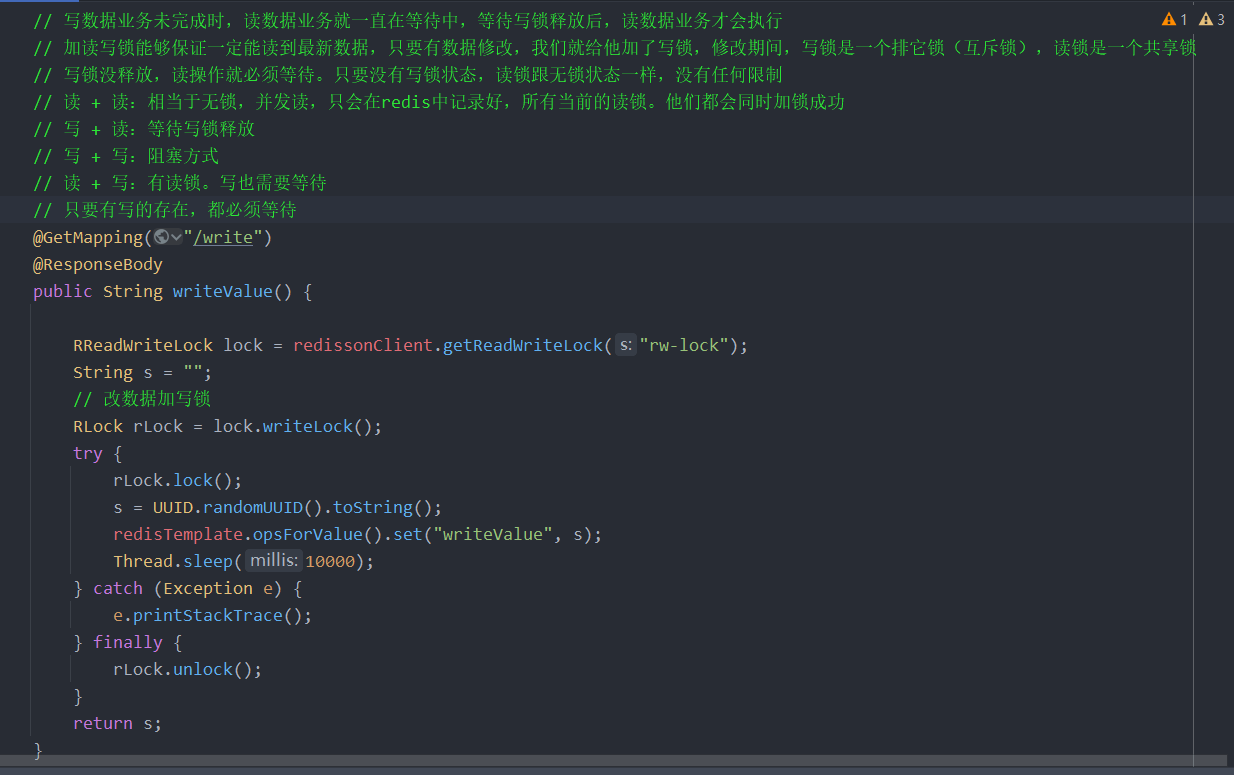
7、信号量测试
信号量为存储在redis中的一个数字,当这个数字大于0时,即可以调用acquire()方法增加数量,也可以调用release()方法减少数量,但是当调用release()之后小于0的话方法就会阻塞,直到数字大于0
基于Redis的Redisson的分布式信号量(Semaphore)Java对象RSemaphore采用了与java.util.concurrent.Semaphore相似的接口和用法。同时还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。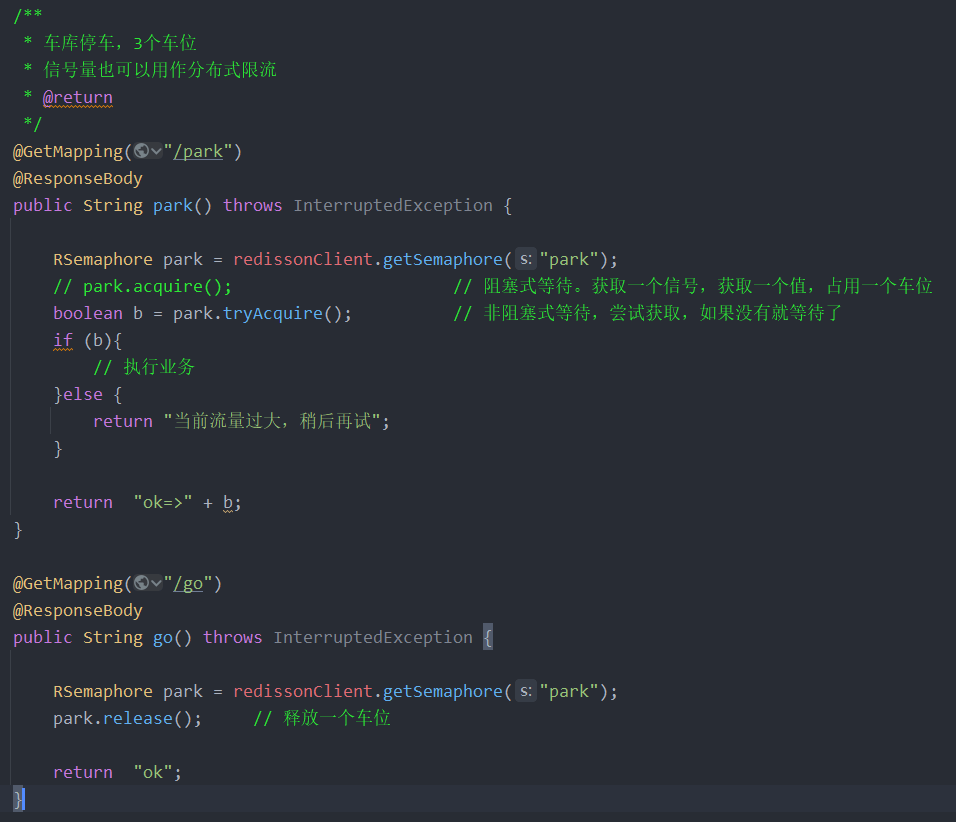
8、闭锁测试
基于Redisson的Redisson分布式闭锁(CountDownLatch)Java对象RCountDownLatch采用了与java.util.concurrent.CountDownLatch相似的接口和用法。

六、缓存一致性解决
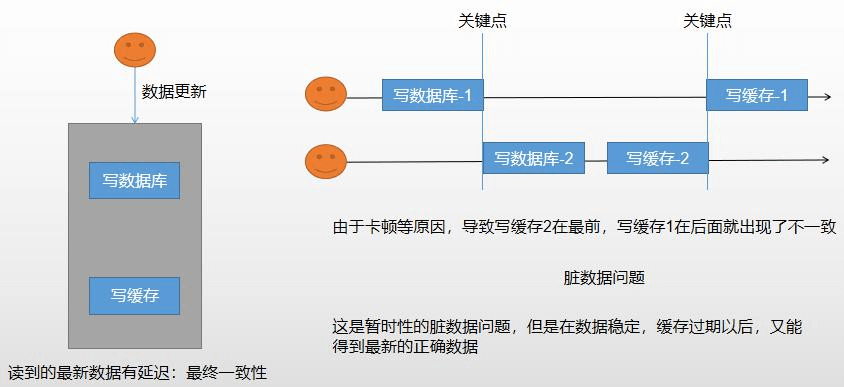
1、双写模式
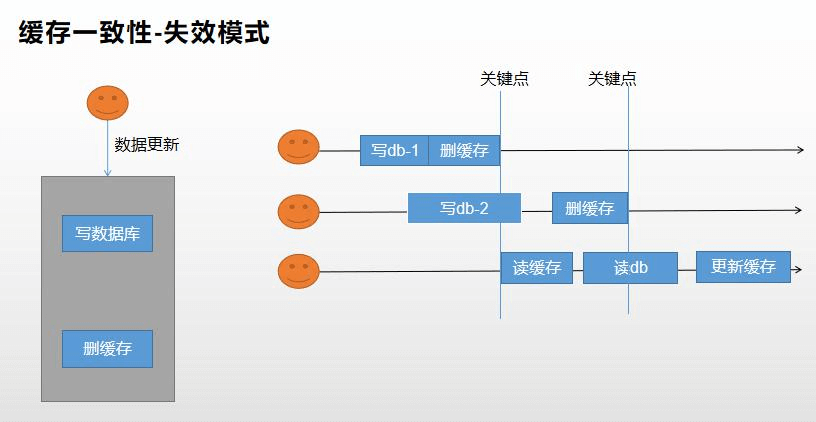
2、失效模式
3、改进方法1-分布式读写锁

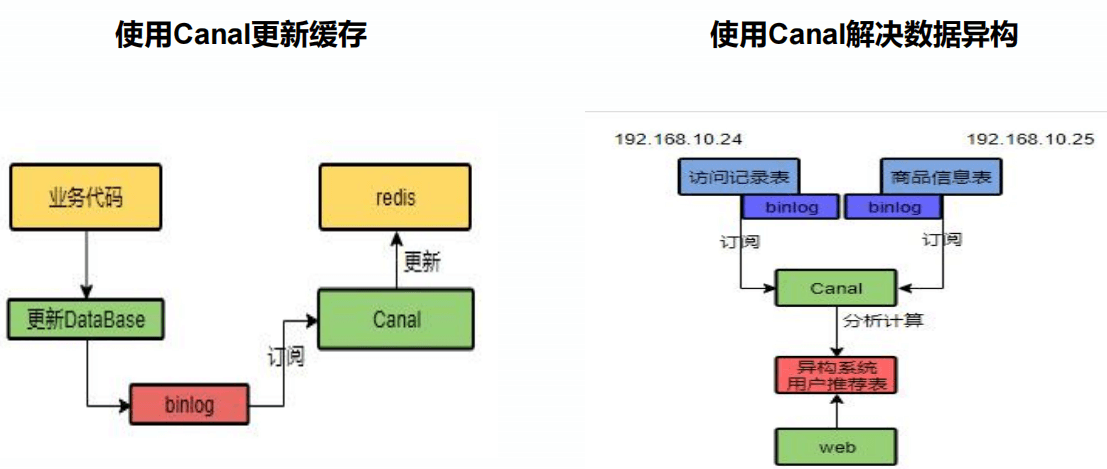
4、改进方法2-使用 cananl
七、SpringCache
1、简介
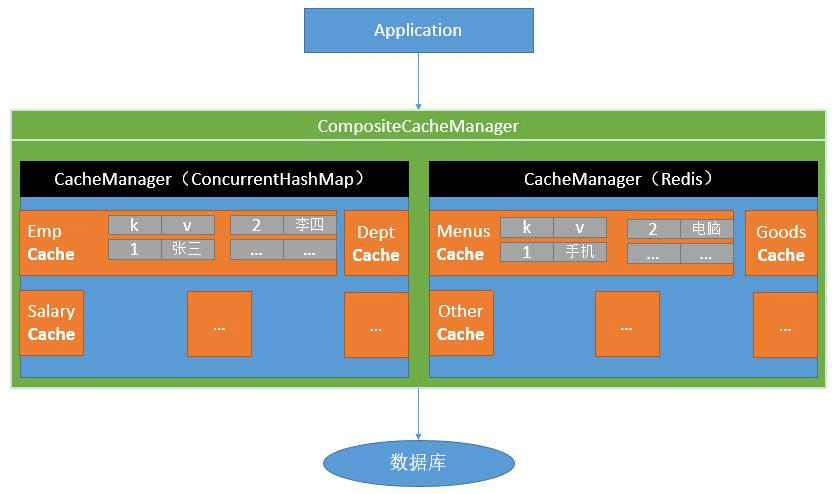
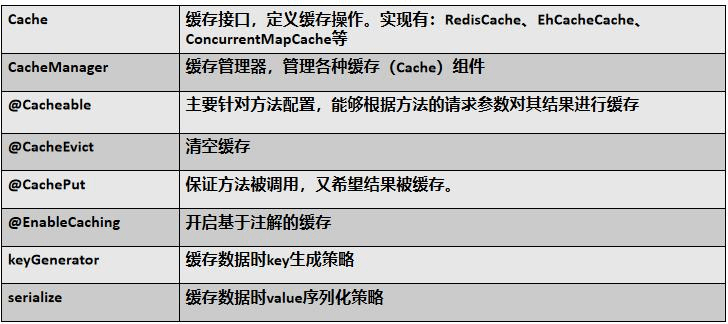
Spring从3.1开始定义了org.springframework.cache.Cache和org.springframework.cache.CacheManager 接口来统一不同的缓存技术; 并支持使用JCache(JSR-107)注解简化我们开发;
Cache接口为缓存的组件规范定义,包含缓存的各种操作集合;Cache接口下Spring提供了各种xxxCache的实现;如RedisCache,EhCacheCache,ConcurrentMapCache等;
每次调用需要缓存功能的方法时,Spring 会检查检查指定参数的指定的目标方法是否已 经被调用过;如果有就直接从缓存中获取方法调用后的结果,如果没有就调用方法并缓 存结果后返回给用户。下次调用直接从缓存中获取。
使用Spring缓存抽象时我们需要关注以下两点:
1、确定方法需要被缓存以及他们的缓存策略
2、从缓存中读取之前缓存存储的数据
2、基础概念
3、注解

4、表达式语法

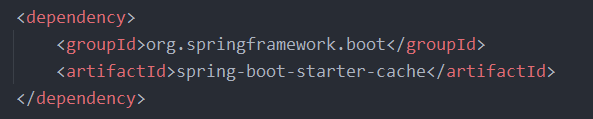
5、加入依赖
6、配置文件
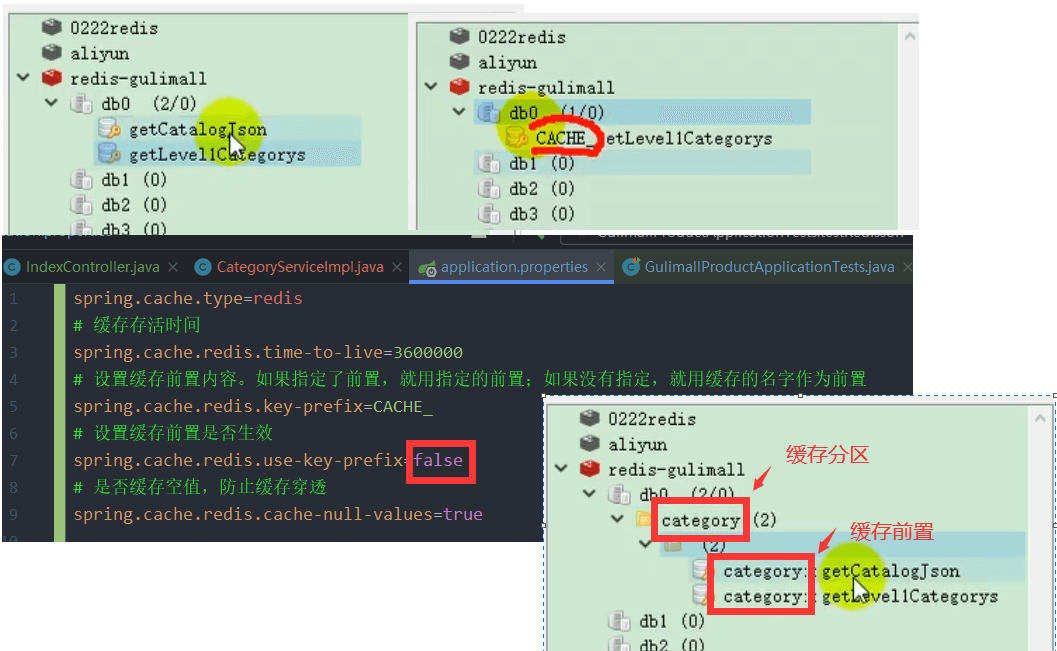
7、自定义缓存配置
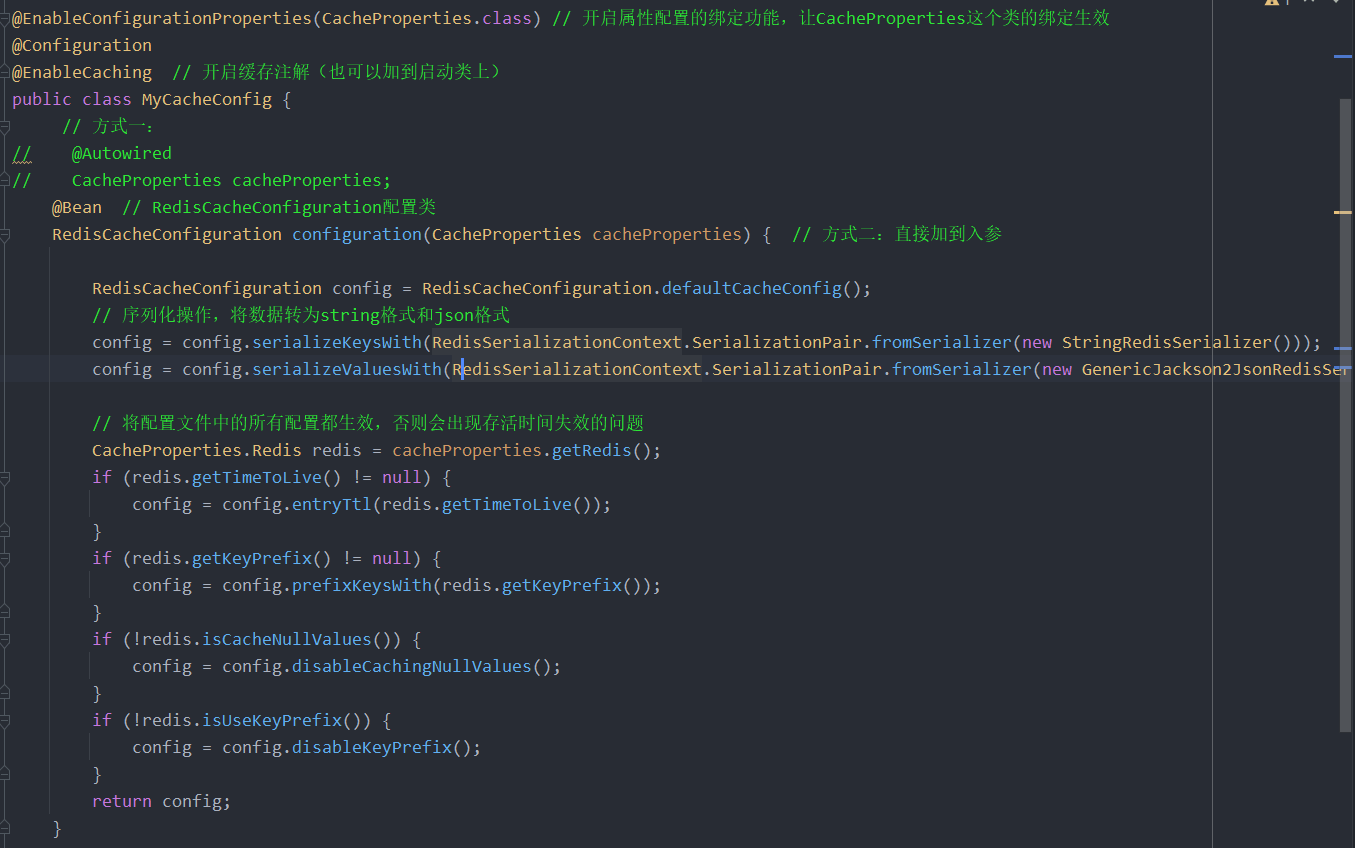
8、写模式@Cacheable
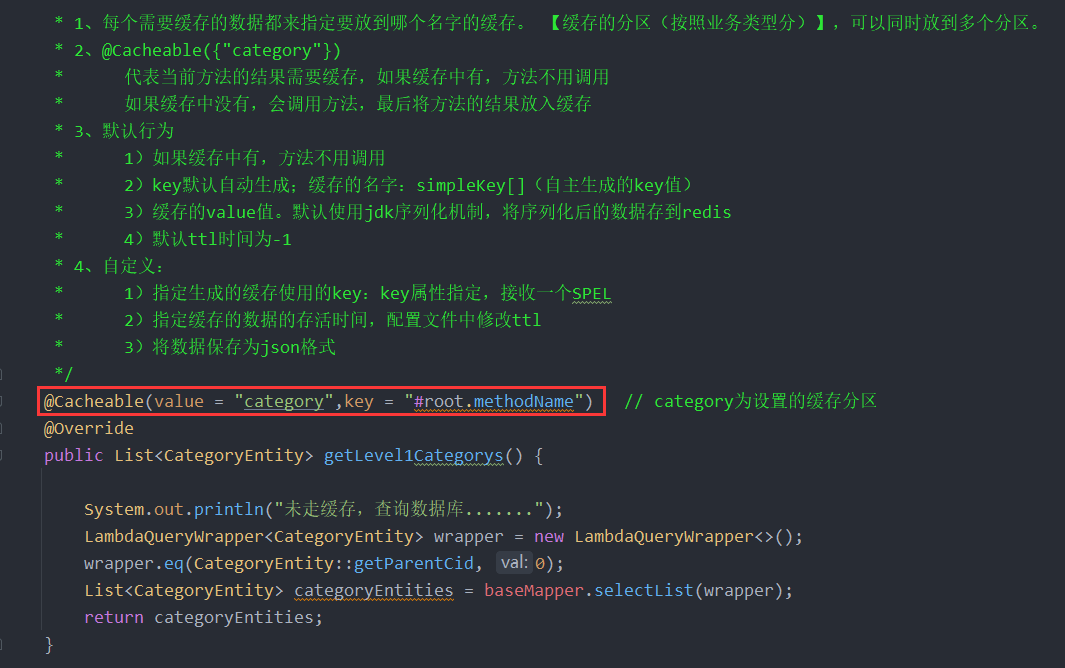
9、失效模式@CacheEvict

10、SpringCache原理与不足
原理:
CacheManager(RedisCacheManager)->Cache(RedisCache)->Cache复制缓存的读写
10.1 读模式
1)缓存穿透:查询一个null数据。解决方案:缓存空数据,可通过
spring.cache.redis.cache-null-values=true
2)缓存击穿:大量并发进来同时查询一个正好过期的数据。解决方案:加锁。 默认是无加锁的;
使用sync = true加本地锁(分布式系统下会访问多次数据库,可以接受)来解决击穿问题(调用的是RedisCache加锁的get方法)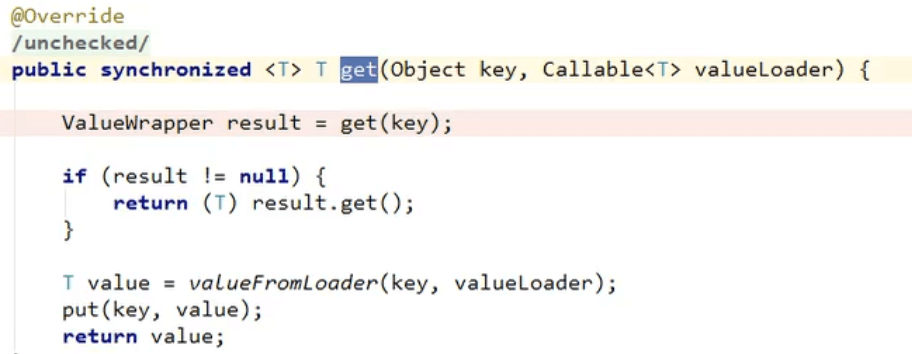
3)缓存雪崩:大量的key同时过期。解决:加随机时间。
加上过期时间spring.cache.redis.time-to-live=3600000
10.2 写模式
(缓存与数据库一致)SpringCache没有设计锁
读写加锁
引入Canal,感知到MySQL的更新去更新Redis
读多写多,直接去数据库查询就行
10.3 总结
常规数据(读多写少,即时性,一致性要求不高的数据),完全可以使用Spring-Cache
常规的写模式(只要缓存的数据有过期时间就足够了)
特殊数据:特殊设计
@Service("categoryService")public class CategoryServiceImpl extends ServiceImpl<CategoryDao, CategoryEntity> implements CategoryService {@Autowiredprivate CategoryBrandRelationService categoryBrandRelationService;@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Autowiredprivate RedissonClient redisson;/*** 查出所有分类以及子分类,以树形结构组装起来* @return*/@Overridepublic List<CategoryEntity> listWithTree() {// 1、查出所有分类List<CategoryEntity> entityList = baseMapper.selectList(null);// 2、组装成父子的树形结构// 2.1、找到所有的一级分类,filter筛选所有的一级分类,map设置一级分类的子菜单List<CategoryEntity> level1Menus = entityList.stream().filter(categoryEntity ->categoryEntity.getParentCid() == 0).map(menu -> {menu.setChildren(getChildrens(menu, entityList));return menu;}).sorted((menu1, menu2) -> {return (menu1.getSort() == null ? 0 : menu1.getSort()) - (menu2.getSort() == null ? 0 : menu2.getSort());}).collect(Collectors.toList());return level1Menus;}/*** 递归查找所有菜单的子菜单*/private List<CategoryEntity> getChildrens(CategoryEntity root, List<CategoryEntity> entityList){List<CategoryEntity> children = entityList.stream().filter(categoryEntity -> {return categoryEntity.getParentCid() == root.getCatId();}).map(menu -> {// 1、找到子菜单menu.setChildren(getChildrens(menu, entityList));return menu;}).sorted((menu1, menu2) -> {// 2、菜单的排序return (menu1.getSort() == null ? 0 : menu1.getSort()) - (menu2.getSort() == null ? 0 : menu2.getSort());}).collect(Collectors.toList());return children;}/*** 删除*/@Overridepublic void removeMenuByIds(List<Long> asList) {//TODO 1、检查当前删除的菜单,是否被别的地方引用baseMapper.deleteBatchIds(asList);}/*** 找到catelogId的完整路径;* [父/子/孙]* @param catelogId* @return [2,25,225]*/@Overridepublic Long[] findCatelogPath(Long catelogId) {List<Long> paths = new ArrayList<>();List<Long> finalPath = findParentPath(catelogId, paths);Collections.reverse(finalPath);return finalPath.toArray(new Long[finalPath.size()]);}// 得到的结果为:225,25,2private List<Long> findParentPath(Long catelogId, List<Long> paths) {paths.add(catelogId);CategoryEntity categoryEntity = baseMapper.selectById(catelogId);if(categoryEntity.getParentCid() != 0){// 判断父节点id是否为0,然后递归查询以上的所有节点数据findParentPath(categoryEntity.getParentCid(), paths);}return paths;}/*** 级联更新所有关联的数据** @CacheEvict:失效模式。根据缓存分区失效* 1、删除缓存分区category下某个具体cache,用key="'类名'",注意有单引号* @CacheEvict(value = "category", key = "'updateCascade'")** 2、同时删除缓存category下的多个cache* @Caching(evict = {* @CacheEvict(value = "category", key = "'updateCascade'"),* @CacheEvict(value = "category", key = "'getLevel1Categorys'")* })* 3、删除缓存分区category下所有cache* @CacheEvict(value = "category",allEntries = true)* 4、存储同一类型的数据,都可以指定成同一个分区。分区名默认就是缓存的前置*/@CacheEvict(value = "category",allEntries = true)@Transactional@Overridepublic void updateCascade(CategoryEntity category) {this.updateById(category);// 更新关联表categoryBrandRelationService.updateCategory(category.getCatId(),category.getName());}/*** 查询所有一级分类** 1、每个需要缓存的数据都来指定要放到哪个名字的缓存。 【缓存的分区(按照业务类型分)】,可以同时放到多个分区。* 2、@Cacheable({"category"})* 代表当前方法的结果需要缓存,如果缓存中有,方法不用调用* 如果缓存中没有,会调用方法,最后将方法的结果放入缓存* 3、默认行为* 1)如果缓存中有,方法不用调用* 2)key默认自动生成;缓存的名字:simpleKey[](自主生成的key值)* 3)缓存的value值。默认使用jdk序列化机制,将序列化后的数据存到redis* 4)默认ttl时间为-1* 4、自定义:* 1)指定生成的缓存使用的key:key属性指定,接收一个SPEL* 2)指定缓存的数据的存活时间,配置文件中修改ttl* 3)将数据保存为json格式*/@Cacheable(value = "category",key = "#root.methodName") // category为设置的缓存分区@Overridepublic List<CategoryEntity> getLevel1Categorys() {System.out.println("未走缓存,查询数据库.......");LambdaQueryWrapper<CategoryEntity> wrapper = new LambdaQueryWrapper<>();wrapper.eq(CategoryEntity::getParentCid, 0);List<CategoryEntity> categoryEntities = baseMapper.selectList(wrapper);return categoryEntities;}// 方式五、使用spring Cache@Cacheable(value = "category",key = "#root.methodName")@Overridepublic Map<String, List<Catelog2Vo>> getCatelogJson() {System.out.println("未走缓存,查询数据库.......");/*** 优化:将数据库中的多次查询变为一次,存至缓存selectList,需要的数据从list取出,避免频繁的数据库交互*/List<CategoryEntity> selectList = baseMapper.selectList(null);//1.查出所有1级分类List<CategoryEntity> level1 = getParent_cid(selectList, 0L);//2.封装数据Map<String, List<Catelog2Vo>> parent_cid = getParentCid(selectList, level1);return parent_cid;}//方式四、使用分布式锁Redissonpublic Map<String, List<Catelog2Vo>> getCatelogJsonFromDbWithRedissonLock() {// 1、锁的名字,锁的粒度,越细越快// 自动续期,自动删除,不会出现死锁RLock lock = redisson.getLock("catalogJson-lock");lock.lock(); // 阻塞式等待// 加锁成功,执行业务Map<String, List<Catelog2Vo>> dataFromDB;try {dataFromDB = getDataFromDB();} finally {lock.unlock();}return dataFromDB;}//方式三、使用分布式程锁Redispublic Map<String, List<Catelog2Vo>> getCatelogJson2() {//加入缓存逻辑,缓存中存的数据是JSON字符串。JSON跨语言,跨平台兼容//从缓存中取出的数据要逆转为能用的对象类型,序列化与发序列化String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");if (StringUtils.isEmpty(catalogJSON)) {//缓存中没有数据,查询数据库Map<String, List<Catelog2Vo>> catelogJsonFromDb = getCatelogJsonFromDbWithRedisLock();//查到的数据再放入缓存,将对象转为JSON放入缓存中。保证查询与放入redis是一个原子操作,否则会出现多次查询数据库的情况String s = JSON.toJSONString(catelogJsonFromDb);stringRedisTemplate.opsForValue().set("catalogJSON", s, 1, TimeUnit.DAYS);return catelogJsonFromDb;}Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {});return result;}//分布式程锁Redispublic Map<String, List<Catelog2Vo>> getCatelogJsonFromDbWithRedisLock() {//占分布式锁,同时设置锁过期时间,必须和加锁同步原子操作。setIfAbsent同redis的setNxString uuid = UUID.randomUUID().toString();Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);if (lock) {//加锁成功,执行业务Map<String, List<Catelog2Vo>> dataFromDB;try {dataFromDB = getDataFromDB();} finally {String script = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1])else return 0 end";// 删除锁,Lua脚本。必须删除自己的锁,用uuid区别。不能删错了// 必须保证获取值对比 + 对比成功后删除是一个原子操作Long lock1 = stringRedisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock", uuid));}return dataFromDB;} else {//加锁失败,休眠2秒,重试。同synchronizedtry {Thread.sleep(2000);} catch (Exception e) {e.printStackTrace();}return getCatelogJsonFromDbWithRedisLock(); //自旋操作。加锁失败后每隔2秒再次进行加锁尝试}}// 抽取公共方法,直接从数据库获取数据private Map<String, List<Catelog2Vo>> getDataFromDB() {String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");if (!StringUtils.isEmpty(catalogJSON)) {Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {});return result;}// 将数据库的多次查询变为一次List<CategoryEntity> selectList = baseMapper.selectList(null);//1.查出所有1级分类List<CategoryEntity> level1 = getParent_cid(selectList, 0L);//2.封装数据Map<String, List<Catelog2Vo>> parent_cid = getParentCid(selectList, level1);String s = JSON.toJSONString(parent_cid);stringRedisTemplate.opsForValue().set("catalogJSON", s, 1, TimeUnit.DAYS);return parent_cid;}//方式二、本地进程锁实现public Map<String, List<Catelog2Vo>> getCatelogJsonFromDbWithLocalLock() {// 只要是同一把锁,就能锁住需要这个锁的所有线程// synchronized (this):springBoot所有的组件在容器中都是单例的// TODO 本地锁:synchronized、JUC(Lock),在分布式情况下,想要锁住所有,必须使用分布式锁synchronized (this) {// 得到锁以后,应该再去缓存中确定一次,如果没有才需要继续查询String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");if (!StringUtils.isEmpty(catalogJSON)) {Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() { });return result;}List<CategoryEntity> selectList = baseMapper.selectList(null);//1.查出所有1级分类List<CategoryEntity> level1 = getParent_cid(selectList, 0L);//2.封装数据Map<String, List<Catelog2Vo>> parent_cid = getParentCid(selectList, level1);String parentCidString = JSON.toJSONString(parent_cid);//3.放入redis缓存。保证查询与放入redis是一个原子操作,否则会出现多次查询数据库的情况stringRedisTemplate.opsForValue().set("catalogJSON", parentCidString, 1, TimeUnit.DAYS);return parent_cid;}}//方式一、没有锁,直接从数据库获取,但优化了取数据逻辑public Map<String, List<Catelog2Vo>> getCatelogJsonFromDb() {/*** 优化:将数据库中的多次查询变为一次,存至selectList,需要的数据从list取出,避免频繁的数据库交互*/List<CategoryEntity> selectList = baseMapper.selectList(null);//1.查出所有1级分类List<CategoryEntity> level1 = getParent_cid(selectList, 0L);//2.封装数据Map<String, List<Catelog2Vo>> parent_cid = getParentCid(selectList, level1);return parent_cid;}// 查出所有1级分类private List<CategoryEntity> getParent_cid(List<CategoryEntity> selectList, Long parent_cid) {List<CategoryEntity> level1 = selectList.stream().filter(item -> item.getParentCid() == parent_cid).collect(Collectors.toList());return level1;}// 封装数据private Map<String, List<Catelog2Vo>> getParentCid(List<CategoryEntity> selectList, List<CategoryEntity> level1) {Map<String, List<Catelog2Vo>> parent_cid = level1.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {//1.查出1级分类中所有2级分类List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());//2.封装上面的结果List<Catelog2Vo> catelog2Vos = null;if (categoryEntities != null) {catelog2Vos = categoryEntities.stream().map(l2 -> {Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());//查询当前2级分类的3级分类List<CategoryEntity> level3 = getParent_cid(selectList, l2.getCatId());if (level3 != null) {List<Catelog2Vo.Catelog3Vo> collect = level3.stream().map(l3 -> {//封装指定格式Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());return catelog3Vo;}).collect(Collectors.toList());catelog2Vo.setCatalog3List(collect);}return catelog2Vo;}).collect(Collectors.toList());}return catelog2Vos;}));return parent_cid;}// 初级方式:每次遍历从数据库获取数据,性能很差public Map<String, List<Catelog2Vo>> getCatelogJsonBase() {// 1、查出所有一级分类List<CategoryEntity> level1Categorys = getLevel1Categorys();// 2、封装数据为map集合。key为一级分类ID,value为一级分类对应的二级分类和三级分类Map<String, List<Catelog2Vo>> map = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {// 3、获取一级分类对应的二级分类LambdaQueryWrapper<CategoryEntity> wrapper = new LambdaQueryWrapper<CategoryEntity>();wrapper.eq(CategoryEntity::getParentCid, v.getCatId());List<CategoryEntity> categoryEntities = baseMapper.selectList(wrapper);// 4、封装二级分类为Catelog2VoList<Catelog2Vo> catelog2VoList = new ArrayList<>();if (!CollectionUtils.isEmpty(categoryEntities)) {catelog2VoList = categoryEntities.stream().map(leve2 -> {Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null,leve2.getCatId().toString(), leve2.getName());// 5、获取二级分类下的三级分类LambdaQueryWrapper<CategoryEntity> wrapper1 = new LambdaQueryWrapper<CategoryEntity>();wrapper.eq(CategoryEntity::getParentCid, leve2.getCatId());List<CategoryEntity> categorysLevel3 = baseMapper.selectList(wrapper1);// 6、封装二级分类下的三级分类为Catelog3VoList<Catelog2Vo.Catelog3Vo> catelog3VoList = new ArrayList<>();if (!CollectionUtils.isEmpty(categorysLevel3)) {catelog3VoList = categorysLevel3.stream().map(leve3 -> {Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(leve2.getCatId().toString(),leve3.getCatId().toString(), leve3.getName());return catelog3Vo;}).collect(Collectors.toList());}catelog2Vo.setCatalog3List(catelog3VoList);return catelog2Vo;}).collect(Collectors.toList());}return catelog2VoList;}));return map;}}

若有收获,就点个赞吧
0 人点赞
