- 一、Redis分布式缓存设计(String专题)
- 二、Redis分布式缓存设计(hash专题)
- 三、Redis分布式缓存设计(List专题)
- 四、Redis分布式缓存设计(Set专题)
- 五、Redis分布式缓存设计(zset专题)
- 六、Spring源码分析:Spring与Redis通信原理剖析
资料来源:https://www.bilibili.com/video/BV1GV411U78a?p=9&spm_id_from=pageDriver
一、Redis分布式缓存设计(String专题)
1、Springboot集成Redis
1.1 Springboot+mybatis+Redis的缓存实战
1.2 案例实战:重写Redis的序列化
优化重写Redis的序列化,改为Json方式
为什么要重写Redis序列化方式,改为Json呢?
因为RedisTemplate默认使用的是JdkSerializationRedisSerializer,会出现2个问题:
1、被序列化的对象必须实现Serializable接口
@Table(name = "users")public class User implements Serializable {
2、被序列化会出现乱码,导致value值可读性差
127.0.0.1:6379> keys *1) "\xac\xed\x00\x05t\x00\auser:62"2) "\xac\xed\x00\x05t\x00\auser:65"3) "\xac\xed\x00\x05t\x00\auser:50"4) "\xac\xed\x00\x05t\x00\auser:36"5) "\xac\xed\x00\x05t\x00\x06user:6"6) "\xac\xed\x00\x05t\x00\auser:17"7) "\xac\xed\x00\x05t\x00\auser:28"127.0.0.1:6379> get "\xac\xed\x00\x05t\x00\auser:62""\xac\xed\x00\x05sr\x00\x1acom.agan.redis.entity.User?\xebU\xa1\xe2\xa6\xfe\xe3\x02\x00\aL\x00\ncreateTimet\x00\x10Ljava/util/Date;L\x00\adeletedt\x00\x10Ljava/lang/Byte;L\x00\x02idt\x00\x13Ljava/lang/Integer;L\x00\bpasswordt\x00\x12Ljava/lang/String;L\x00\x03sexq\x00~\x00\x02L\x00\nupdateTimeq\x00~\x00\x01L\x00\busernameq\x00~\x00\x04xpsr\x00\x0ejava.util.Datehj\x81\x01KYt\x19\x03\x00\x00xpw\b\x00\x00\x01o+5\x1d\xf8xsr\x00\x0ejava.lang.Byte\x9cN`\x84\xeeP\xf5\x1c\x02\x00\x01B\x00\x05valuexr\x00\x10java.lang.Number\x86\xac\x95\x1d\x0b\x94\xe0\x8b\x02\x00\x00xp\x00sr\x00\x11java.lang.Integer\x12\xe2\xa0\xa4\xf7\x81\x878\x02\x00\x01I\x00\x05valuexq\x00~\x00\t\x00\x00\x00>t\x00\x04un59q\x00~\x00\nsq\x00~\x00\x06w\b\x00\x00\x01o+5\x1d\xf8xt\x00\x04un59"
@Configurationpublic class RedisConfiguration {/*** 重写Redis序列化方式,使用Json方式:* 当我们的数据存储到Redis的时候,我们的键(key)和值(value)都是通过Spring提供的Serializer序列化到Redis的。* RedisTemplate默认使用的是JdkSerializationRedisSerializer,* StringRedisTemplate默认使用的是StringRedisSerializer。** Spring Data JPA为我们提供了下面的Serializer:* GenericToStringSerializer、Jackson2JsonRedisSerializer、* JacksonJsonRedisSerializer、JdkSerializationRedisSerializer、* OxmSerializer、StringRedisSerializer。* 在此我们将自己配置RedisTemplate并定义Serializer。*/@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);//创建一个json的序列化对象GenericJackson2JsonRedisSerializer jackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer();//设置value的序列化方式jsonredisTemplate.setValueSerializer(jackson2JsonRedisSerializer);//设置key序列化方式stringredisTemplate.setKeySerializer(new StringRedisSerializer());//设置hash key序列化方式stringredisTemplate.setHashKeySerializer(new StringRedisSerializer());//设置hash value的序列化方式jsonredisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);redisTemplate.afterPropertiesSet();return redisTemplate;}}
体验:
- 先把user的序列化删除
- 创建类RedisConfiguration
- flushdb:清空redis的旧数据,因为改了序列化,老数据以及不能兼容了,必须清空旧数据
- 往redis 初始化100条数据
- 用 keys 命令查看所有key ```java 127.0.0.1:6379> keys 1) “user:187” 2) “user:117” 3) “user:170” 4) “user:139” 5) “user:157”
127.0.0.1:6379> get user:187 “{\”@class\”:\”com.agan.redis.entity.User\”,\”id\”:187,\”username\”:\”un84\”,\”password\”:\”un84\”, \”sex\”:0,\”deleted\”:0,\”updateTime\”:[\”java.util.Date\”,1576983528000], \”createTime\”:[\”java.util.Date\”,1576983528000]}”
<a name="pkg4X"></a>## 2、Springcache集成Redis<a name="ej9o0"></a>### 2.1 为什么要用springcache,它解决了什么问题?SpringCache是spring3.1版本发布出来的,他是对使用缓存进行封装和抽象,通过在方法上使用annotation注解就能拿到缓存结果。<br /> 正是因为用了annotation,所以它解决了业务代码和缓存代码的耦合度问题,即再不侵入业务代码的基础上让现有代码即刻支持缓存,它让开发人员无感知的使用了缓存。<br /> 特别注意: 对于Redis的缓存,SpringCache只支持String,其他的Hash 、List、set、ZSet都不支持<a name="wuDty"></a>### 2.2 Springcache实现缓存**步骤1:pom文件加入依赖包**```java<!--redis--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!--spring cache--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency><!--spring cache连接池依赖包--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>2.6.2</version></dependency>
步骤2:配置文件,加入redis配置信息
## Redis 配置# Redis数据库索引(默认为0)spring.redis.database=0# Redis服务器地址spring.redis.host=192.168.1.138# Redis服务器连接端口spring.redis.port=6379# Redis服务器连接密码(默认为空)spring.redis.password=# 连接池最大连接数(使用负值表示没有限制)spring.redis.lettuce.pool.max-active=8# 连接池最大阻塞等待时间spring.redis.lettuce.pool.max-wait=-1ms# 连接池中的最大空闲连接spring.redis.lettuce.pool.max-idle=8# 连接池中的最小空闲连接spring.redis.lettuce.pool.min-idle=0# 连接超时时间(毫秒)spring.redis.timeout=5000ms
步骤3:开启缓存配置,设置序列化
重点是开启 @EnableCaching
@Configuration@EnableCachingpublic class RedisConfig {@Primary@Beanpublic CacheManager cacheManager(RedisConnectionFactory redisConnectionFactory){RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig();redisCacheConfiguration = redisCacheConfiguration// 设置缓存的默认超时时间:30分钟.entryTtl(Duration.ofMinutes(30L))// 如果是空值,不缓存.disableCachingNullValues()// 设置key序列化器.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(keySerializer()))// 设置value序列化器.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(valueSerializer()));return RedisCacheManager.builder(RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory)).cacheDefaults(redisCacheConfiguration).build();}/*** key序列化器*/private RedisSerializer<String> keySerializer() {return new StringRedisSerializer();}/*** value序列化器*/private RedisSerializer<Object> valueSerializer() {return new GenericJackson2JsonRedisSerializer();}}
步骤4:逻辑代码
@Api(description = "用户接口")@RestController@RequestMapping("/user")public class UserController {@Autowiredprivate UserService userService;@ApiOperation("单个用户查询,按userid查用户信息")@RequestMapping(value = "/findById/{id}", method = RequestMethod.GET)public UserVO findById(@PathVariable int id) {User user = this.userService.findUserById(id);UserVO userVO = new UserVO();BeanUtils.copyProperties(user, userVO);return userVO;}@ApiOperation("修改某条数据")@PostMapping(value = "/updateUser")public void updateUser(@RequestBody UserVO obj) {User user = new User();BeanUtils.copyProperties(obj, user);userService.updateUser(user);}@ApiOperation("按id删除用户")@RequestMapping(value = "/del/{id}", method = RequestMethod.GET)public void deleteUser(@PathVariable int id) {this.userService.deleteUser(id);}}
@Service@CacheConfig(cacheNames = { "user" })public class UserService {private static final Logger LOGGER = LoggerFactory.getLogger(UserService.class);@Autowiredprivate UserMapper userMapper;@Cacheable(key="#id")public User findUserById(Integer id){return this.userMapper.selectByPrimaryKey(id);}@CachePut(key = "#obj.id")public User updateUser(User obj){this.userMapper.updateByPrimaryKeySelective(obj);return this.userMapper.selectByPrimaryKey(obj.getId());}@CacheEvict(key = "#id")public void deleteUser(Integer id){User user=new User();user.setId(id);user.setDeleted((byte)1);this.userMapper.updateByPrimaryKeySelective(user);}}
2.3 剖析SpringCache常用注解
@CacheConfig(cacheNames = { "user" })public class UserService {private static final Logger LOGGER = LoggerFactory.getLogger(UserService.class);@Autowiredprivate UserMapper userMapper;@Cacheable(key="#id")public User findUserById(Integer id){return this.userMapper.selectByPrimaryKey(id);}@CachePut(key = "#obj.id")public User updateUser(User obj){this.userMapper.updateByPrimaryKeySelective(obj);return this.userMapper.selectByPrimaryKey(obj.getId());}@CacheEvict(key = "#id")public void deleteUser(Integer id){User user=new User();user.setId(id);user.setDeleted((byte)1);this.userMapper.updateByPrimaryKeySelective(user);}}
@CacheConfig是类级别的注解,统一该类的所有缓存可以前缀。
@CacheConfig(cacheNames = { "user" })public class UserService {
以上代码,代表了该类的所有缓存可以都是”user::”为前缀
@Cacheable是方法级别的注解,用于将方法的结果缓存起来。
@Cacheable(key="#id")public User findUserById(Integer id){return this.userMapper.selectByPrimaryKey(id);}
以上方法被调用时,先从缓存中读取数据,如果缓存没有找到数据,再执行方法体,最后把返回值添加到缓存中。
注意:
@Cacheable 一般是配合@CacheConfig一起使用的 例如上文的@CacheConfig(cacheNames = { “user” }) 和 @Cacheable(key=”#id”)一起使用时。 调用方法传入id=100,那redis对应的key=user::100 ,value通过采用GenericJackson2JsonRedisSerializer序列化为json 调用方法传入id=200,那redis对应的key=user::200 ,value通过采用GenericJackson2JsonRedisSerializer序列化为json
@CachePut是方法级别的注解,用于更新缓存。
@CachePut(key = "#obj.id")public User updateUser(User obj){this.userMapper.updateByPrimaryKeySelective(obj);return this.userMapper.selectByPrimaryKey(obj.getId());}
以上方法被调用时,先执行方法体,然后springcache通过返回值更新缓存,即key = “#obj.id”,value=User
@CachePut是方法级别的注解,用于删除缓存。
public void deleteUser(Integer id){User user = new User();user.setId(id);user.setDeleted((byte)1);this.userMapper.updateByPrimaryKeySelective(user);}
2.4 SpringCache的大坑
对于Redis的缓存,SpringCache只支持String,其他的Hash 、List、set、ZSet都不支持, 所以对于Hash 、List、set、ZSet只能用RedisTemplate
对于多表查询的数据缓存,SpringCache是不支持的,只支持单表的简单缓存。 对于多表的整体缓存,只能用RedisTemplate。
3、淘宝商品分布式全局ID
3.1 为什么分布式系统需要全局唯一ID
3.2 全局唯一ID必须具备什么特点
3.3 剖析淘宝商品ID的特点
3.4 基于Redis生成分布式全局唯一ID原理
3.5 案例实战:Springboot+Redis生成淘宝商品ID
4、Redis性能优化实战
4.1 真实案例分析Redis的性能瓶颈
4.2 什么事lua
4.3 Redis为什么要是有lua
4.4 LUA的语法入门
4.5 真实案例分析Redis的性能瓶颈及如何优化
4.6 案例实战:Springboot实现多条Redis命令合成一个lua
4.7 案例实战:Redis+lua 实现黑客防刷攻击
4.8 案例实战:Springboot+Redis+lua 实现黑客防刷攻击
5、微信文章的阅读量PV
5.1 微信文章的阅读量场景介绍
这样一个场景: 在微信公众号里面的文章,每个用户阅读一遍文章,该篇文章的阅读量就会加1。如下图: 
对于微信这种一线互联网公司,如此大的并发量,一般不可能采用数据库来做计数器,通常都是用redis的incr命令来实现。
5.2 微信文章的阅读量原理:Redis INCR命令
INCR命令,它的全称是increment,用途就是计数器。 每执行一次INCR命令,都将key的value自动加1。 如果key不存在,那么key的值初始化为0,然后再执行INCR操作。
例如:微信文章id=100,做阅读计算如:
127.0.0.1:6379> incr article:100(integer) 1127.0.0.1:6379> incr article:100(integer) 2127.0.0.1:6379> incr article:100(integer) 3127.0.0.1:6379> incr article:100(integer) 4127.0.0.1:6379> get article:100"4"
技术方案的缺陷:需要频繁的修改Redis,耗费CPU,高并发修改Redis会导致Redis的CPU达到100%
使用zset解决高并发问题
5.3 编码实现微信文章的阅读量
@RestController@Slf4jpublic class ViewController {@Autowiredprivate StringRedisTemplate stringRedisTemplate;@GetMapping(value = "/view")public void view(Integer id) {// redis keyString key="article:" + id;// 调用redis的increment计数器命令long n = stringRedisTemplate.opsForValue().increment(key);log.info("key={},阅读量为{}", key, n);}}
5.4 课后练习
这节课,我们讲的INCR命令,都是在redis内存操作的,那如何同步到数据库呢?
如果不同步到数据库,就会出现数据丢失,请思考:如何把阅读量PV同步到mydql数据库?
二、Redis分布式缓存设计(hash专题)
1、Redis经典场景:hash存储Java对象
1.1 Redis存储Java对象
Redis存储java对象,一般是String或Hash两种
String的存储通常用在频繁读操作,它的存储格式是json,即把java对象转换为json,然后存入redis
Hash的存储场景应用在频繁写操作,即当对象的某个属性频繁修改时,不适用string+json的数据结构,因为不灵活,每次修改都需要把整个对象转换为json存储。
如果采用hash,就可以针对某个属性单独修改,不用序列号去修改整个对象。例如,商品的库存、价格、关注数、评价数经常变动时,就使用存储hash结果。
1.2 案例实战:SpringBoot+Redis+hash存储商品数据
步骤1:加入依赖包
<!--swagger--><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.9.2</version></dependency><!--swagger-ui--><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger-ui</artifactId><version>2.9.2</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-redis</artifactId><version>1.4.7.RELEASE</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.8</version></dependency><dependency><groupId>commons-lang</groupId><artifactId>commons-lang</artifactId><version>2.6</version></dependency>
步骤2:创建商品的Redis处理
@RestController@Slf4j@RequestMapping(value = "/pruduct")public class ProductController {@Autowiredprivate RedisTemplate redisTemplate;@PostMapping(value = "/create")public void create(Product obj) {// TODO 先进db// 创建商品,先把数据添加到数据库,再存入redisString key = "product:"+1000;// 将Object对象里面的属性和值转化成Map对象Map<String, Object> map = this.objectToMap(obj);// 批量put操作:putAll等于hmset命令// String数据结构opsForValue、hash数据结构opsForHashthis.redisTemplate.opsForHash().putAll(key, map);Object name = redisTemplate.opsForHash().get(key, "name");log.info("name={}",name);Object price = redisTemplate.opsForHash().get(key, "price");log.info("price={}",price);Object detail = redisTemplate.opsForHash().get(key, "detail");log.info("detail={}",detail);}/*** 将Object对象里面的属性和值转化成Map对象*/public Map<String, Object> objectToMap(Object obj) {Map<String, Object> map = new HashMap<String,Object>();Class<?> clazz = obj.getClass();for (Field field : clazz.getDeclaredFields()) {field.setAccessible(true);String fieldName = field.getName();Object value = null;try {value = field.get(obj);} catch (IllegalAccessException e) {log.error(e.getMessage());}map.put(fieldName, value);}return map;}}
步骤3:解决序列化问题
127.0.0.1:6379> keys *1) "\xac\xed\x00\x05t\x00\x0cproduct:1000"127.0.0.1:6379> hgetAll "\xac\xed\x00\x05t\x00\x0cproduct:1000"1) "\xac\xed\x00\x05t\x00\x02id"2) ""3) "\xac\xed\x00\x05t\x00\x06detail"4) "\xac\xed\x00\x05t\x00\x03www"5) "\xac\xed\x00\x05t\x00\x05price"6) "\xac\xed\x00\x05sr\x00\x11java.lang.Integer\x12\xe2\xa0\xa4\xf7\x81\x878\x02\x00\x01I\x00\x05valuexr\x00\x10java.lang.Number\x86\xac\x95\x1d\x0b\x94\xe0\x8b\x02\x00\x00xp\x00\x00\a\xd0"7) "\xac\xed\x00\x05t\x00\x04name"8) "\xac\xed\x00\x05t\x00\x06huawei"127.0.0.1:6379>127.0.0.1:6379>127.0.0.1:6379>127.0.0.1:6379> flushdbOK127.0.0.1:6379> keys *1) "product:1000"127.0.0.1:6379> hgetall product:10001) "price"2) "2000"3) "name"4) "\"huawei\""5) "id"6) ""7) "detail"8) "\"www\""
@Configurationpublic class RedisConfiguration {/*** 重写Redis序列化方式,使用Json方式:* 当我们的数据存储到Redis的时候,我们的键(key)和值(value)都是通过Spring提供的Serializer序列化到Redis的。* RedisTemplate默认使用的是JdkSerializationRedisSerializer,* StringRedisTemplate默认使用的是StringRedisSerializer。** Spring Data JPA为我们提供了下面的Serializer:* GenericToStringSerializer、Jackson2JsonRedisSerializer、* JacksonJsonRedisSerializer、JdkSerializationRedisSerializer、* OxmSerializer、StringRedisSerializer。* 在此我们将自己配置RedisTemplate并定义Serializer。*/@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);// 创建一个json的序列化对象GenericJackson2JsonRedisSerializer jackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// 设置value的序列化方式jsonredisTemplate.setValueSerializer(jackson2JsonRedisSerializer);// 设置key序列化方式stringredisTemplate.setKeySerializer(new StringRedisSerializer());// 设置hash key序列化方式stringredisTemplate.setHashKeySerializer(new StringRedisSerializer());// 设置hash value的序列化方式jsonredisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);redisTemplate.afterPropertiesSet();return redisTemplate;}}
步骤4:商品涨价
@PostMapping(value = "/addPrice")public void addPrice(int id, int price) {String key = "product:" + id;// 商品价格涨价:increment等于hincrby命令redisTemplate.opsForHash().increment(key, "price", price);Object price2 = redisTemplate.opsForHash().get(key, "price");log.info("price={}",price2);}
2、淘宝短链接实战
2.1 体验淘宝短链接业务场景
场景1:淘宝短信
【天猫】有优惠啦!黄皮金煌芒果(水仙芒)带箱10斤49.8元!核薄无丝很甜喔!购买: c.tb.cn/c.ZzhFZ0 急鲜丰 退订回TD
打开IE,输入:c.tb.cn/c.ZzhFZ0 就转变为如下:https://h5.m.taobao.com/ecrm/jump-to-app.html?scm=20140608.2928562577.LT_ITEM.1699166744&target_url= http%3A%2F%2Fh5.m.taobao.com%2Fawp%2Fcore%2Fdetail.htm%3Fid%3D567221004504%26scm=20140607.2928562577. LT_ITEM.1699166744&spm=a313p.5.1cfl9ch.947174560063&short_name=c.ZzhFZ0&app=chrome
场景2:淘宝APP分享URL
【这个#聚划算团购#宝贝不错:【官方旗舰】步步高家教机S5英语小学初高中课本同步小天才平板儿童点读学习机智能学生平板电脑护眼旗舰店(分享自@手机淘宝android客户端)】 https://m.tb.cn/h.eAE6vuE點£擊☆鏈ㄣ接,再选择瀏覽→噐咑ぺ鐦;或椱ァ製这句话€eyuf1YeAXFf€后打开👉淘宀┡ē👈
打开IE,输入https://m.tb.cn/h.eAE6vuE 就转变为如下: https://detail.tmall.com/item.htm?id=597254411409&price=3998-4398&sourceType=item&sourceType=item&suid= 4c8fc4d8-cb5e-40c0-b4b6-c4a06598781a&ut_sk=1.WmH11veugHoDAGWzSv+jAZg2_21646297_1574219840558.Copy.1&un =ceed7d76bfbe7a3b4b68d5f77a161062&share_crt_v=1&spm=a2159r.13376460.0.0&sp_tk=4oKzaUU0SllFcWZuRjLigrM= &cpp=1&shareurl=true&short_name=h.eF25Q3n&sm=505e90&app=chrome&sku_properties=1627207:28332
体验了以上2个场景,我们来总结:
- 先说下什么是短链接? 就是把普通网址,转换成比较短的网址。
- 短链接有什么好处?
- 节省网址长度,便于社交化传播。
方便后台跟踪点击量、统计。
public static void main(String[] args) {String str="566ab90f";System.out.println("2进制: " + Long.toBinaryString(0x3FFFFFFF));// 566ab90fSystem.out.println("2进制:" + Long.toBinaryString(0x566ab90f));System.out.println("格式化后:" + Long.toBinaryString(0x3fffffff & 0x566ab90f));System.out.println("0x0000003D:2进制:" + Long.toBinaryString(0x0000003D));System.out.println("0x0000003D:10进制:" + Long.parseLong("0000003D", 16));}
import org.apache.commons.codec.digest.DigestUtils;/*** 将长网址 md5 生成 32 位签名串,分为 4 段, 每段 8 个字节* 对这四段循环处理, 取 8 个字节, 将他看成 16 进制串与 0x3fffffff(30位1) 与操作, 即超过 30 位的忽略处理* 这 30 位分成 6 段, 每 5 位的数字作为字母表的索引取得特定字符, 依次进行获得 6 位字符串* 总的 md5 串可以获得 4 个 6 位串,取里面的任意一个就可作为这个长 url 的短 url 地址*/public class ShortUrlGenerator {//26+26+10=62public static final String[] chars = new String[]{"a", "b", "c", "d", "e", "f", "g", "h","i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t","u", "v", "w", "x", "y", "z", "0", "1", "2", "3", "4", "5","6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H","I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T","U", "V", "W", "X", "Y", "Z"};/*** 一个长链接URL转换为4个短KEY*/public static String[] shortUrl(String url) {String key = "";// 对地址进行md5String sMD5EncryptResult = DigestUtils.md5Hex(key + url);System.out.println(sMD5EncryptResult);String hex = sMD5EncryptResult;String[] resUrl = new String[4];for (int i = 0; i < 4; i++) {// 取出8位字符串,md5 32位,被切割为4组,每组8个字符String sTempSubString = hex.substring(i * 8, i * 8 + 8);// 先转换为16进账,然后用0x3FFFFFFF进行位与运算,目的是格式化截取前30位long lHexLong = 0x3FFFFFFF & Long.parseLong(sTempSubString, 16);String outChars = "";for (int j = 0; j < 6; j++) {// 0x0000003D代表什么意思?他的10进制是61,61代表chars数组长度62的0到61的坐标。// 0x0000003D & lHexLong进行位与运算,就是格式化为6位,即61内的数字// 保证了index绝对是61以内的值long index = 0x0000003D & lHexLong;outChars += chars[(int) index];//每次循环按位移5位,因为30位的二进制,分6次循环,即每次右移5位lHexLong = lHexLong >> 5;}// 把字符串存入对应索引的输出数组resUrl[i] = outChars;}return resUrl;}public static void main(String[] args) {// 长连接String longUrl = "https://detail.tmall.com/item.htm?id=597254411409";// 转换成的短链接后6位码,返回4个短链接String[] shortCodeArray = shortUrl(longUrl);for (int i = 0; i < shortCodeArray.length; i++) {// 任意一个都可以作为短链接码System.out.println(shortCodeArray[i]);}}}
2.2 案例实战:SpringBoot+Redis高并发《短链接转换器》
《短链接转换器》的原理:
- 长链接转换为短链接 - 实现原理:长链接转换为短链接加密串key,然后存储于Redis的hash结构中。
重定向到原始的url - 实现原理:通过加密串key到Redis找出原始url,然后重定向出去
@RestController@Slf4jpublic class ShortUrlController {@Autowiredprivate HttpServletResponse response;@Autowiredprivate RedisTemplate redisTemplate;private final static String SHORT_URL_KEY="short:url";/*** 长链接转换为短链接* 实现原理:长链接转换为短加密串key,然后存储在redis的hash结构中。*/@GetMapping(value = "/encode")public String encode(String url) {// 一个长链接url转换为4个短加密串keyString [] keys = ShortUrlGenerator.shortUrl(url);// 任意取出其中一个,我们就拿第一个String key = keys[0];// 用hash存储,key = 加密串,value = 原始urlredisTemplate.opsForHash().put(SHORT_URL_KEY, key, url);log.info("长链接 = {},转换 = {}", url, key);return "http://127.0.0.1:9090/" + key;}/*** 重定向到原始的URL* 实现原理:通过短加密串KEY到redis找出原始URL,然后重定向出去*/@GetMapping(value = "/{key}")public void decode(@PathVariable String key) {// 到redis中把原始url找出来String url = (String)redisTemplate.opsForHash().get(SHORT_URL_KEY, key);try {// 重定向到原始的urlresponse.sendRedirect(url);} catch (IOException e) {e.printStackTrace();}}}
@Configurationpublic class RedisConfiguration {/*** 重写Redis序列化方式,使用Json方式:* 当我们的数据存储到Redis的时候,我们的键(key)和值(value)都是通过Spring提供的Serializer序列化到数据库的。RedisTemplate默认使用的是JdkSerializationRedisSerializer,StringRedisTemplate默认使用的是StringRedisSerializer。* Spring Data JPA为我们提供了下面的Serializer:* GenericToStringSerializer、Jackson2JsonRedisSerializer、JacksonJsonRedisSerializer、JdkSerializationRedisSerializer、OxmSerializer、StringRedisSerializer。* 在此我们将自己配置RedisTemplate并定义Serializer。* @param redisConnectionFactory* @return*/@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);GenericJackson2JsonRedisSerializer jackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer();redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);redisTemplate.setKeySerializer(new StringRedisSerializer());redisTemplate.setHashKeySerializer(new StringRedisSerializer());redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);redisTemplate.afterPropertiesSet();return redisTemplate;}}
3、京东双11购物车实战
3.1 京东购物车多种场景分析
步骤1:先登录你的京东账号,清空以前购物车,然后添加1件商品A,保证你的购物车只有1件商品A
步骤2:退出登录,购物车添加商品B,然后关闭浏览器再打开。(购物车的商品B仍存在)
步骤3:再次登录你的京东账号。(购物车有两件商品)3.2 图解分析:双11高并发的京东购物车技术实现
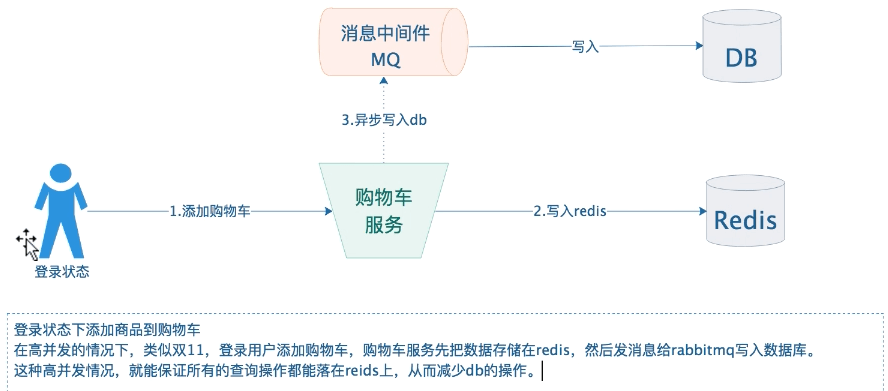
1、登录状态添加商品到购物车
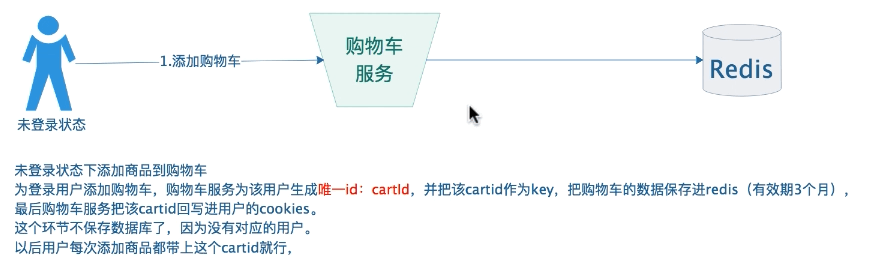
2、未登录状态添加商品到购物车
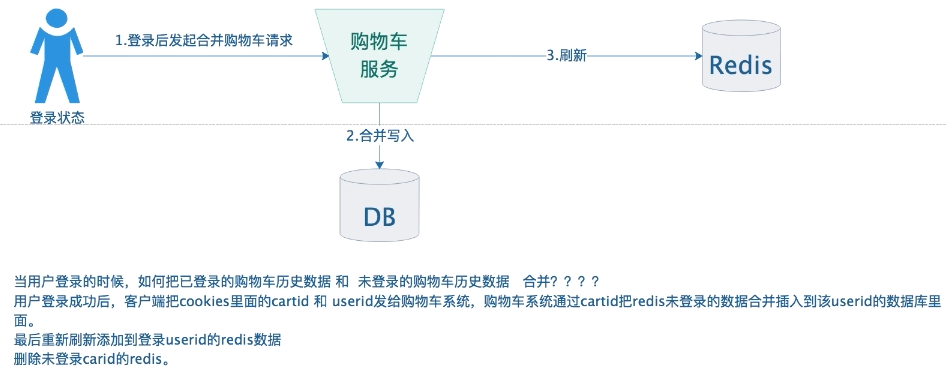
3、登录状态合并购物车
3.3 购物车的Redis经典场景
场景一:往购物车加入2件商品,采用hash数据结果,key=cart: user: 用户id
127.0.0.1:6379> hset cart:user:1000 101 1(integer) 1127.0.0.1:6379> hset cart:user:1000 102 1(integer) 1127.0.0.1:6379> hgetall cart:user:10001) "101"2) "1"3) "102"4) "1"
场景二:修改购物车的数据,为某件商品添加数量
127.0.0.1:6379> hincrby cart:user:1000 101 1(integer) 2127.0.0.1:6379> hincrby cart:user:1000 102 10(integer) 11127.0.0.1:6379> hgetall cart:user:10001) "101"2) "2"3) "102"4) "11"
场景三:统计购物车有多少件商品
127.0.0.1:6379> hlen cart:user:1000(integer) 2
场景四:删除购物车某件商品
127.0.0.1:6379> hdel cart:user:1000 102(integer) 1127.0.0.1:6379> hgetall cart:user:10001) "101"2) "2"
3.4 案例实战:SpringBoot+Redis实现高并发购物车
```java @Autowired private RedisTemplate redisTemplate;
/**
- 购物车key的前缀 */ public static final String CART_KEY = “cart:user:”;
/**
- 添加购物车
*/
@PostMapping(value = “/addCart”)
public void addCart(Cart obj) {
String key = CART_KEY + obj.getUserId();
Boolean hasKey = redisTemplate.opsForHash().getOperations().hasKey(key);
// 存在
if(hasKey){
}else{this.redisTemplate.opsForHash().put(key, obj.getProductId().toString(), obj.getAmount());
} //TODO 发rabbitmq 出去 }this.redisTemplate.opsForHash().put(key, obj.getProductId().toString(), obj.getAmount());this.redisTemplate.expire(key,90, TimeUnit.DAYS);
/**
- 修改购物车的数量 */ @PostMapping(value = “/updateCart”) public void updateCart(Cart obj) { String key = CART_KEY + obj.getUserId(); this.redisTemplate.opsForHash().put(key, obj.getProductId().toString(), obj.getAmount()); //TODO 发rabbitmq 出去 }
/* 删除购物车 */ @PostMapping(value = “/delCart”) public void delCart(Long userId, Long productId) { String key = CART_KEY + userId; this.redisTemplate.opsForHash().delete(key, productId.toString()); //TODO 发rabbitmq 出去 }
@PostMapping(value = “/findAll”) public CartPage findAll(Long userId) { String key = CART_KEY + userId; CartPage cartPage = new CartPage(); // 查购物车的总数 long size = this.redisTemplate.opsForHash().size(key); cartPage.setCount((int) size);
// 查询购物车的所有商品// entries = hgetall命令Map<String, Integer> map = this.redisTemplate.opsForHash().entries(key);List<Cart> cartList = new ArrayList<>();for (Map.Entry<String, Integer> entry : map.entrySet()) {Cart cart = new Cart();cart.setUserId(userId);cart.setProductId(Long.parseLong(entry.getKey()));cart.setAmount(entry.getValue());cartList.add(cart);}cartPage.setCartList(cartList);return cartPage;
}
```java@Datapublic class Cart {private Long userId;private Long productId;private int amount;}@Datapublic class CartPage<T> {private List<T> cartList;private int count;}
3.5 案例实战:SpringBoot+Redis+Cookies实现高并发的购物车
@RestController@Slf4j@RequestMapping(value = "/cookiecart")public class CookieCartController {@Autowiredprivate RedisTemplate redisTemplate;@Autowiredprivate IdGenerator idGenerator;@Autowiredprivate HttpServletRequest request;@Autowiredprivate HttpServletResponse response;public static final String COOKIE_KEY = "cart:cookie:";/*** 添加购物车*/@PostMapping(value = "/addCart")public void addCart(CookieCart obj) {String cartId = this.getCookiesCartId();String key = COOKIE_KEY + cartId;Boolean hasKey = redisTemplate.opsForHash().getOperations().hasKey(key);// 存在if(hasKey){this.redisTemplate.opsForHash().put(key, obj.getProductId().toString(),obj.getAmount());}else{this.redisTemplate.opsForHash().put(key, obj.getProductId().toString(), obj.getAmount());this.redisTemplate.expire(key,90, TimeUnit.DAYS);}}/*** 修改购物车*/@PostMapping(value = "/updateCart")public void updateCart(CookieCart obj) {String cartId = this.getCookiesCartId();String key = COOKIE_KEY + cartId;this.redisTemplate.opsForHash().put(key, obj.getProductId().toString(), obj.getAmount());}/*** 删除购物车*/@PostMapping(value = "/delCart")public void delCart(Long productId) {String cartId = this.getCookiesCartId();String key = COOKIE_KEY + cartId;this.redisTemplate.opsForHash().delete(key, productId.toString());}/*** 查询某个用户的购物车*/@PostMapping(value = "/findAll")public CartPage findAll() {String cartId = this.getCookiesCartId();String key = COOKIE_KEY + cartId;CartPage<CookieCart> cartPage = new CartPage();// 查询该用户购物车的总数long size = this.redisTemplate.opsForHash().size(key);cartPage.setCount((int)size);// 查询购物车的所有商品Map<String,Integer> map = this.redisTemplate.opsForHash().entries(key);List<CookieCart> cartList = new ArrayList<>();for (Map.Entry<String,Integer> entry:map.entrySet()){CookieCart cart = new CookieCart();cart.setProductId(Long.parseLong(entry.getKey()));cart.setAmount(entry.getValue());cartList.add(cart);}cartPage.setCartList(cartList);return cartPage;}/*** 获取cookies*/public String getCookiesCartId(){// 第一步:先检查cookies是否有cartidCookie[] cookies = request.getCookies();if(cookies != null){for(Cookie cookie : cookies){if(cookie.getName().equals("cartId")){return cookie.getValue();}}}// 第二步:cookies没有cartid,直接生成全局id,并设置到cookie里面// 生成全局唯一idlong id = this.idGenerator.incrementId();// 设置到cookiesCookie cookie = new Cookie("cartId", String.valueOf(id));response.addCookie(cookie);return id + "";}/*** 合并购物车* 把cookie中的购物车合并到登录用户的购物车*/@PostMapping(value = "/mergeCart")public void mergeCart(Long userId) {// 第一步:提取未登录用户的cookie的购物车数据String cartId = this.getCookiesCartId();String keycookie = COOKIE_KEY+cartId;Map<String,Integer> map = this.redisTemplate.opsForHash().entries(keycookie);// 第二步:把cookie中得购物车合并到登录用户的购物车String keyuser = "cart:user:" + userId;this.redisTemplate.opsForHash().putAll(keyuser, map);// 第三步:删除redis未登录的用户cookies的购物车数据this.redisTemplate.delete(keycookie);// 第四步:删除未登录用户cookies的cartidCookie cookie=new Cookie("cartId", null);cookie.setMaxAge(0);response.addCookie(cookie);}}
@Datapublic class CookieCart {private Long productId;private int amount;}
@Servicepublic class IdGenerator {@Autowiredprivate StringRedisTemplate stringRedisTemplate;private static final String ID_KEY = "id:generator:cart";/*** 生成全局唯一id*/public Long incrementId() {long n=this.stringRedisTemplate.opsForValue().increment(ID_KEY);return n;}}
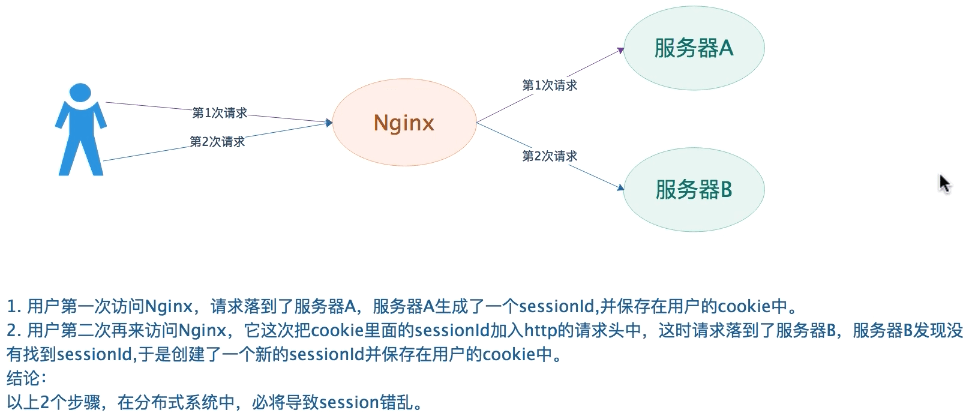
4、Redis解决分布式系统的session不一致问题

5、微博实战:用户注册
6、微博实战:用户发微博
三、Redis分布式缓存设计(List专题)
1、list命令实战
2、高并发淘宝聚划算商品列表
2.1 需求分析:淘宝聚划算功能
https://ju.taobao.com/
这张页面的特点: 1. 数据量少,才13页 2. 高并发,请求量大
2.2 高并发的淘宝聚划算实现技术方案
像聚划算这种高并发的功能,绝对不可能用数据库的! 一般的做法是先把数据库中的数据抽取到Redis里面。采用定时器,来定时缓存。 这张页面的特点,数据量不多,才13页。最大的特点就要支持分页。Redis的 list数据结构天然支持这种高并发的分页查询功能。
具体的技术方案采用list 的lpush 和 lrange来实现。
## 先用定时器把数据刷新到list中127.0.0.1:6379> lpush jhs p1 p2 p3 p4 p5 p6 p7 p8 p9 p10(integer) 10## 用lrange来实现分页127.0.0.1:6379> lrange jhs 0 51) "p10"2) "p9"3) "p8"4) "p7"5) "p6"6) "p5"127.0.0.1:6379> lrange jhs 6 101) "p4"2) "p3"3) "p2"4) "p1"
2.3 案例实战:SpringBoot+Redis实现淘宝聚划算功能
步骤1:配置redis
步骤2:采用定时器把特价商品都刷入redis缓存中
@Service@Slf4jpublic class TaskService {@Autowiredprivate RedisTemplate redisTemplate;@PostConstructpublic void initJHS(){log.info("启动定时器..........");new Thread(()->runJhs()).start();}/*** 模拟定时器,定时把数据库的特价商品,刷新到redis中*/public void runJhs() {while (true){// 模拟从数据库读取100件特价商品,用于加载到聚划算的页面中List<Product> list = this.products();// 采用redis list数据结构的lpush来实现存储redisTemplate.delete(Constants.JHS_KEY);// lpush命令redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY, list);try {// 间隔一分钟 执行一遍Thread.sleep(1000*60);} catch (InterruptedException e) {e.printStackTrace();}log.info("runJhs定时刷新..............");}}/*** 模拟从数据库读取100件特价商品,用于加载到聚划算的页面中*/public List<Product> products() {List<Product> list = new ArrayList<>();for (int i = 0; i < 100; i++) {Random rand = new Random();int id = rand.nextInt(10000);Product ob j = new Product((long) id, "product" + i, i, "detail");list.add(obj);}return list;}}
@Datapublic class Product {private Long id;/*** 产品名称*/private String name;/*** 产品价格*/private Integer price;/*** 产品详情*/private String detail;}
步骤3:Redis分页查询
/*** 分页查询:在高并发的情况下,只能走redis查询,走db的话必定会把db打垮*/@GetMapping(value = "/find")public List<Product> find(int page, int size) {List<Product> list = null;long start = (page - 1) * size;long end = start + size - 1;try {// 采用redis list数据结构的lrange命令实现分页查询list = redisTemplate.opsForList().range(Constants.JHS_KEY, start, end);if (CollectionUtils.isEmpty(list)) {//TODO 走DB查询}log.info("查询结果:{}", list);} catch (Exception ex) {// 这里的异常,一般是redis瘫痪 ,或redis网络timeoutlog.error("exception:", ex);//TODO 走DB查询}return list;}
2.4 如何防止缓存击穿
1、什么是缓存击穿
在高并发的系统中,大量的请求同时查询一个key时,如果这个key正好失效或删除,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿 如下图:

当查询QPS=1000的时候,这时定时任务更新redis,先删除再添加就会出现缓存击穿,就会导致大量的请求都打到数据库上面去
2、如何解决缓存击穿的问题?
针对这种定时更新缓存的特定场景,解决缓存击穿一般是采用主从轮询的原理来实现。
- 定时器更新原理
开辟2块缓存,A 和 B,定时器在更新缓存的时候,先更新B缓存,然后再更新A缓存,记得要按这个顺序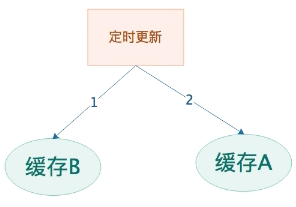
查询原理
用户先查询缓存A,如果缓存A查询不到(例如,更新缓存的时候删除了),再查下缓存B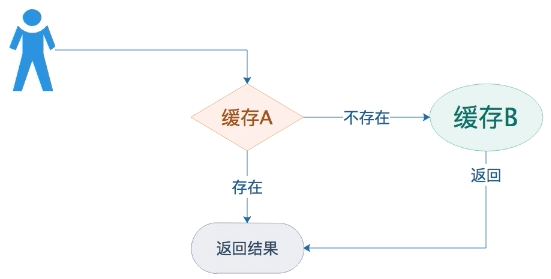
以上2个步骤,由原来的一块缓存,开辟出2块缓存,最终解决了缓存击穿的问题3、淘宝聚划算的缓存击穿实现
```java @PostConstruct public void initJHSAB(){
log.info(“启动AB定时器……….”); new Thread(()->runJhsAB()).start(); }
public void runJhsAB() {
while (true){// 模拟从数据库读取100件 特价商品,用于加载到聚划算页面List<Product> list=this.products();// 先更新Bthis.redisTemplate.delete(Constants.JHS_KEY_B);this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY_B,list);// 再更新Athis.redisTemplate.delete(Constants.JHS_KEY_A);this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY_A,list);try {Thread.sleep(1000*60);} catch (InterruptedException e) {e.printStackTrace();}log.info("重新刷新..............");}
}
```java@GetMapping(value = "/findAB")public List<Product> findAB(int page, int size) {List<Product> list = null;long start = (page - 1) * size;long end = start + size - 1;try {// 采用redis list数据结构的lrange命令实现分页查询。list = this.redisTemplate.opsForList().range(Constants.JHS_KEY_A, start, end);// 用户先查询缓存A,如果缓存A查询不到(例如,更新缓存的时候删除了),再查下缓存Bif (CollectionUtils.isEmpty(list)) {this.redisTemplate.opsForList().range(Constants.JHS_KEY_B, start, end);}log.info("{}", list);} catch (Exception ex) {// 这里的异常,一般是redis瘫痪 ,或 redis网络timeoutlog.error("exception:", ex);// TODO 走DB查询}return list;}
3、高并发的微信抢红包
3.1 微信抢红包的并发场景分析
3.2 微信抢红包的技术实现原理
3.3 案例实战:SpringBoot+Redis实现微信抢红包
private static final String ID_KEY = "id:generator:redpacket";private static final String RED_PACKET_KEY = "redpacket";private static final String RED_PACKET_CONSUME_KEY = "redpacket:consume:";@Autowiredprivate RedisTemplate redisTemplate;/*** 抢红包的接口*/@GetMapping(value = "/rob")public int rob(int redid, int userid) {// 第一步:验证该用户是否已经抢过了Object packet = redisTemplate.opsForHash().get(RED_PACKET_CONSUME_KEY + redid, String.valueOf(userid));if(packet == null){// 第二部:从list队列,弹出一个红包(解决了获取一个红包与从红包队列中删除红包是一个原子性操作)Object obj = redisTemplate.opsForList().leftPop(RED_PACKET_KEY + redid);if(obj != null){// 抢到红包,存起来redisTemplate.opsForHash().put(RED_PACKET_CONSUME_KEY + redid, String.valueOf(userid), obj);log.info("用户={}抢到{}", userid, obj);// TODO 异步把数据落地到数据库中return (Integer) obj;}// -1 代表抢完return -1;}// -2 代表已抢return -2;}/*** 包红包的接口*/@GetMapping(value = "/set")public long setRedpacket(int total, int count) {// 拆解分包Integer[] packet = this.spiltRedPacket(total, count);// 为每个红包生成全局唯一IDLong n = this.incrementId();// 采用list存储所有拆分后的小红包String key = RED_PACKET_KEY + n;redisTemplate.opsForList().leftPush(key, packet);// 设置3天有效期redisTemplate.expire(key, 3, TimeUnit.DAYS);log.info("拆解红包{}={}", key, packet);return n;}/*** 生成全局唯一ID*/public Long incrementId(){Long n = redisTemplate.opsForValue().increment(ID_KEY);return n;}/*** 拆解分包* 1、红包金额要被全部拆解完* 2、红包之间的金额不能相差太大*/public Integer[] spiltRedPacket(int total, int count){int use = 0;Integer[] array = new Integer[count];Random random = new Random();for (int i = 0; i < count; i++) {if(i == count-1){array[i] = total - use;}else {// 红包随机金额浮动系数int avg = (total - use) * 2 / (count - i);array[i] = 1 + random.nextInt(avg - 1);}use = use + array[i];}return array;}
4、高并发微信文章阅读量PV
4.1 高并发微信文章的阅读量PV业务场景分析
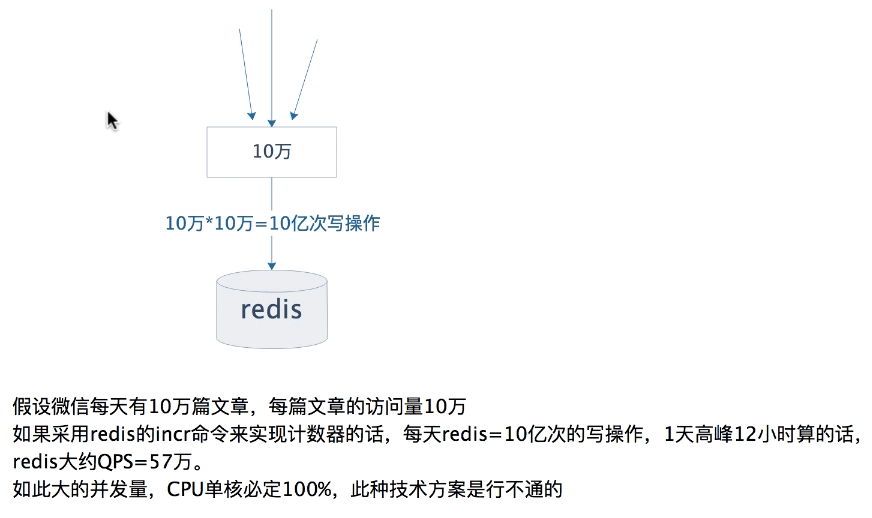
4.2 基于二级缓存的高并发微信文章的阅读量PV技术方案
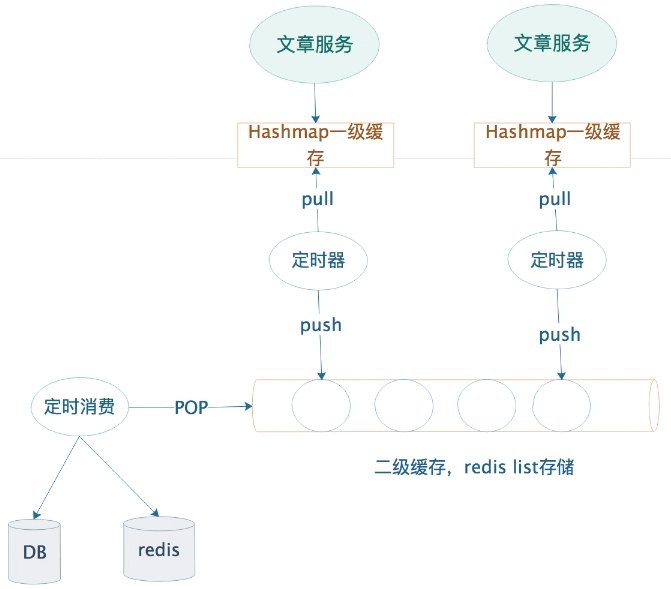


4.3 案例实战:SpringBoot+Redis实现二级缓存微信文章的PV统计
https://www.bilibili.com/video/BV1GV411U78a?p=29&spm_id_from=pageDriver
步骤1:模拟大量PV请求
@Service@Slf4jpublic class InitPVTask {@Autowiredprivate RedisTemplate redisTemplate;@PostConstructpublic void initPV(){log.info("启动模拟大量PV请求 定时器..........");new Thread(()->runArticlePV()).start();}/*** 模拟大量PV请求*/public void runArticlePV() {while (true){this.batchAddArticle();try {// 5秒执行一次Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}}}/*** 对1000篇文章,进行模拟请求PV*/public void batchAddArticle() {for (int i = 0; i < 1000; i++) {this.addPV(new Integer(i));}}/*** 那如何切割时间块呢? 如何把当前的时间切入时间块中?* 例如, 我们要计算“小时块”,先把当前的时间转换为为毫秒的时间戳,然后除以一个小时,* 即当前时间T/1000*60*60=小时key,然后用这个小时序号作为key。* 例如:* 2020-01-12 15:30:00=1578814200000毫秒 转换小时key=1578814200000/1000*60*60=438560* 2020-01-12 15:59:00=1578815940000毫秒 转换小时key=1578815940000/1000*60*60=438560* 2020-01-12 16:30:00=1578817800000毫秒 转换小时key=1578817800000/1000*60*60=438561* 剩下的以此类推** 每一次PV操作时,先计算当前时间是那个时间块,然后存储Map中。*/public void addPV(Integer id) {// 生成环境:时间块为5分钟// long m5=System.currentTimeMillis()/(1000*60*5);// 为了方便测试 改为1分钟 时间块long m1 = System.currentTimeMillis() / (1000*60*1);Map<Integer, Integer> mMap = Constants.PV_MAP.get(m1);if (CollectionUtils.isEmpty(mMap)){mMap = new ConcurrentHashMap();mMap.put(id, new Integer(1));// <1分钟的时间块,Map<文章Id,访问量>>Constants.PV_MAP.put(m1, mMap);}else {// 通过文章id 取出浏览量Integer value = mMap.get(id);if (value == null){mMap.put(id, new Integer(1));}else{mMap.put(id, value + 1);}}}}
步骤2:一级缓存定时器消费
@Service@Slf4jpublic class OneCacheTask {@Autowiredprivate RedisTemplate redisTemplate;@PostConstructpublic void cacheTask(){log.info("启动定时器:一级缓存消费..........");new Thread(()->runCache()).start();}/*** 一级缓存定时器消费* 定时器,定时(5分钟)从jvm的map把时间块的阅读pv取出来,* 然后push到reids的list数据结构中,list的存储的书为Map<文章id,访问量PV>即每个时间块的pv数据*/public void runCache() {while (true){this.consumePV();try {//间隔1.5分钟 执行一遍Thread.sleep(90000);} catch (InterruptedException e) {e.printStackTrace();}log.info("消费一级缓存,定时刷新..............");}}public void consumePV(){// 为了方便测试 改为1分钟 时间块long m1 = System.currentTimeMillis() / (1000*60*1);Iterator<Long> iterator = Constants.PV_MAP.keySet().iterator();while (iterator.hasNext()){// 取出map的时间块Long key = iterator.next();// 小于当前的分钟时间块key,就消费if (key < m1){// 先pushMap<Integer,Integer> map = Constants.PV_MAP.get(key);// push到reids的list数据结构中,list的存储的书为Map<文章id,访问量PV>即每个时间块的pv数据this.redisTemplate.opsForList().leftPush(Constants.CACHE_PV_LIST, map);// 后removeConstants.PV_MAP.remove(key);log.info("push进{}", map);}}}}
步骤3:二级缓存定时器消费
@Service@Slf4jpublic class TwoCacheTask {@Autowiredprivate RedisTemplate redisTemplate;@PostConstructpublic void cacheTask(){log.info("启动定时器:二级缓存消费..........");new Thread(()->runCache()).start();}/*** 二级缓存定时器消费* 定时器,定时(6分钟),从redis的list数据结构pop弹出Map<文章id,访问量PV>,弹出来做了2件事:* 第一件事:先把Map<文章id,访问量PV>,保存到数据库* 第二件事:再把Map<文章id,访问量PV>,同步到redis缓存的计数器incr。*/public void runCache() {while (true){while (this.pop()){}try {// 间隔2分钟 执行一遍Thread.sleep(1000*60*2);} catch (InterruptedException e) {e.printStackTrace();}log.info("消费二级缓存,定时刷新..............");}}public boolean pop(){//从redis的list数据结构pop弹出Map<文章id,访问量PV>ListOperations<String, Map<Integer,Integer>> operations = this.redisTemplate.opsForList();Map<Integer,Integer> map = operations.rightPop(Constants.CACHE_PV_LIST);log.info("弹出pop = {}", map);if (CollectionUtils.isEmpty(map)){return false;}// 第一步:先存入数据库// TODO: 插入数据库//第二步:同步redis缓存for (Map.Entry<Integer,Integer> entry : map.entrySet()){// log.info("key = {}, value = {}", entry.getKey(), entry.getValue());String key = Constants.CACHE_ARTICLE + entry.getKey();// 调用redis的increment命令long n = this.redisTemplate.opsForValue().increment(key, entry.getValue());// log.info("key = {}, pv = {}", key, n);}return true;}}
步骤4:查看浏览量
@Autowiredprivate StringRedisTemplate stringRedisTemplate;@GetMapping(value = "/view")public String view(Integer id) {String key = Constants.CACHE_ARTICLE + id;// 调用redis的get命令String n = this.stringRedisTemplate.opsForValue().get(key);log.info("key={},阅读量为{}", key, n);return n;}
public class Constants {public static final String CACHE_PV_LIST="pv:list";public static final String CACHE_ARTICLE="article:";/*** Map<时间块,Map<文章Id,访问量>>* =Map<2020-01-12 15:30:00到 15:59:00,Map<文章Id,访问量>>* =Map<438560,Map<文章Id,访问量>>*/public static final Map<Long, Map<Integer,Integer>> PV_MAP = new ConcurrentHashMap();}
5、微博实战:push推送
5.1 微博push推送业务场景分析
5.2 微博push推送的Redis技术方案
5.3 案例实战:基于push技术,实现微博个人列表
5.4 案例实战:基于push技术,实现微博关注列表
6、微博实战:push列表的性能优化
7、Redis普通分布式锁
8、Redis分布式重入锁
9、Redis分布式红锁
10、剖析Redis分布式redlock源码
四、Redis分布式缓存设计(Set专题)
1、Set数据结构详解
Redis的set 和java的set集合功能差不多的
集合(Set) 的主要功能就是求并集、交集、差集。
A = {'a', 'b', 'c'}B = {'a', 'e', 'i', 'o', 'u'}inter(x, y): 交集,在集合x和集合y中都存在的元素。inter(A, B) = {'a'}union(x, y): 并集,在集合x中或集合y中的元素,如果一个元素在x和y中都出现,那只记录一次即可。union(A,B) = {'a', 'b', 'c', 'e', 'i', 'o', 'u'}diff(x, y): 差集,在集合x中而不在集合y中的元素。diff(A,B) = {'b', 'c'}card(x): 基数,一个集合中元素的数量。card(A) = 3空集: 基数为0的集合
sadd(key, member):向名称为key的set中添加元素member
smembers(key):返回名称为key的set的所有元素
127.0.0.1:6379> sadd users u1(integer) 1127.0.0.1:6379> sadd users u2(integer) 1127.0.0.1:6379> sadd users u3 u4(integer) 2127.0.0.1:6379> smembers users1) "u2"2) "u4"3) "u1"4) "u3"
srem(key, member) :删除名称为key的set中的元素member
127.0.0.1:6379> smembers users1) "u2"2) "u4"3) "u1"4) "u3"127.0.0.1:6379> srem users u1(integer) 1127.0.0.1:6379> srem users u3 u4(integer) 2127.0.0.1:6379> smembers users1) "u2"
sismember(key, member) :member是否是名称为key的set的元素
127.0.0.1:6379> smembers users1) "u2"127.0.0.1:6379> sismember users u2(integer) 1127.0.0.1:6379> sismember users u1(integer) 0
scard(key) :返回名称为key的set的基数,一个集合中元素的数量
127.0.0.1:6379> smembers users1) "u2"127.0.0.1:6379> scard users(integer) 1
smove(srckey, dstkey, member) :将member元素从source集合移动到destination集合
127.0.0.1:6379> smembers users1) "u2"2) "u4"3) "u1"4) "u3"127.0.0.1:6379> smembers blacklist(empty list or set)127.0.0.1:6379> smove users blacklist u1(integer) 1127.0.0.1:6379> smembers users1) "u2"2) "u4"3) "u3"127.0.0.1:6379> smembers blacklist1) "u1"
srandmember(key) :随机返回名称为key的set的一个元素
127.0.0.1:6379> smembers users1) "u2"2) "u4"3) "u3"127.0.0.1:6379> srandmember users"u3"127.0.0.1:6379> srandmember users 21) "u2"2) "u3"
spop(key) :随机返回并删除名称为key的set中一个元素
127.0.0.1:6379> smembers users1) "u2"2) "u4"3) "u3"127.0.0.1:6379> spop users"u3"127.0.0.1:6379> smembers users1) "u2"2) "u4"
sinter(key1, key2,…key N) :求交集
127.0.0.1:6379> smembers group11) "3"2) "2"3) "4"4) "1"5) "a"127.0.0.1:6379> smembers group21) "b"2) "a"3) "1"4) "c"127.0.0.1:6379> sinter group1 group21) "a"2) "1"
sinterstore(dstkey, (key2,…key N)) :求交集并将交集保存到dstkey的集合
127.0.0.1:6379> sinterstore group3 group1 group2(integer) 2127.0.0.1:6379> smembers group11) "3"2) "4"3) "1"4) "2"5) "a"127.0.0.1:6379> smembers group21) "b"2) "a"3) "1"4) "c"127.0.0.1:6379> smembers group31) "a"2) "1"
sunion(key1, (keys)) :求并集
127.0.0.1:6379> sunion group1 group21) "3"2) "4"3) "1"4) "2"5) "b"6) "a"7) "c"
sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合
127.0.0.1:6379> sunionstore group4 group1 group2(integer) 7127.0.0.1:6379> smembers group41) "3"2) "4"3) "1"4) "2"5) "b"6) "a"7) "c"
sdiff(key1, (keys)) :求差集
127.0.0.1:6379> smembers group11) "3"2) "4"3) "1"4) "2"5) "a"127.0.0.1:6379> smembers group21) "b"2) "a"3) "1"4) "c"127.0.0.1:6379> sdiff group1 group21) "2"2) "3"3) "4"
sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合
127.0.0.1:6379> sdiffstore group5 group1 group2(integer) 3127.0.0.1:6379> smembers group51) "2"2) "3"3) "4"
2、淘宝商品评价黑名单校验器
2.1 黑名单过滤器业务场景分析
淘宝的商品评价功能,不是任何人就能评价的,有一种职业就是差评师,差评师就是勒索敲诈商家, 这种差评师在淘宝里面就被设置了黑名单,即使购买了商品,也评价不了。
2.2 黑名单校验器的Redis技术方案
黑名单过滤器除了针对上文说的淘宝评价,针对用户黑名单外,其实还有ip黑名单、设备黑名单等。
在高并发的情况下,通过数据库过滤明显不符合要求,一般的做法都是通过Redis来实现的。
那Redis那种数据结构适合做这种黑名单的呢?
答案是:set
步骤1:先把数据库的数据同步到Redis的set集合中。
步骤2:评价的时候验证是否为黑名单,通过sismember命令来实现。
2.3 SpringBoot+Redis实现黑名单校验器
步骤1:提前先把数据刷新到redis缓存中
@Service@Slf4jpublic class TaskService {@Autowiredprivate RedisTemplate redisTemplate;/*** 提前先把数据刷新到redis缓存中*/@PostConstructpublic void init(){log.info("启动初始化 ..........");List<Integer> blacklist = this.blacklist();//this.redisTemplate.delete(Constants.BLACKLIST_KEY);blacklist.forEach(t -> this.redisTemplate.opsForSet().add(Constants.BLACKLIST_KEY, t));}/*** 模拟100个黑名单*/public List<Integer> blacklist() {List<Integer> list = new ArrayList<>();for (int i = 0; i < 100; i++) {list.add(i);}return list;}}public class Constants {public static final String BLACKLIST_KEY="blacklist";}
步骤2:编写黑名单校验器接口
@Autowiredprivate RedisTemplate redisTemplate;/*** 编写黑名单校验器接口* true = 黑名单* false = 不是黑名单*/@GetMapping(value = "/isBlacklist")public boolean isBlacklist(Integer userId) {boolean bo = false;try {// 到set集合中去校验是否黑名单bo = this.redisTemplate.opsForSet().isMember(Constants.BLACKLIST_KEY, userId);log.info("查询结果:{}", bo);} catch (Exception ex) {// 这里的异常,一般是redis瘫痪,或redis网络timeoutlog.error("exception:", ex);// TODO 走DB查询}return bo;}
3、京东京豆抽奖实战
3.1 京东京豆抽奖的业务场景分析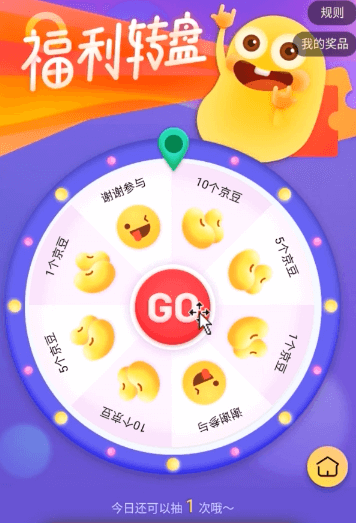
3.2 京东京豆抽奖的技术方案
京豆抽奖一般是采用Redis的set集合来操作的,那为什么是set集合适用于抽奖呢?
原因:1、set集合的特点是元素不重复,存放1个、5个、10个京豆、谢谢参与
2、set集合支持随机读取,具体的技术方案是采用set集合的srandmember命令来实现,随机返回set的一个元素
3.3 案例实战:SpringBoot+Redis实现京东京豆抽奖
步骤1:奖品的初始化
由于set集合是不重复,故在奖品初始化的时候,要为每个奖品设置一个序列号。
@Service@Slf4jpublic class TaskCrowdService {@Autowiredprivate RedisTemplate redisTemplate;/*** 提前先把数据刷新到redis缓存中*/@PostConstructpublic void init(){log.info("启动初始化..........");boolean bo = this.redisTemplate.hasKey(Constants.PRIZE_KEY);if(!bo){List<String> crowds=this.prize();crowds.forEach(t->this.redisTemplate.opsForSet().add(Constants.PRIZE_KEY,t));}}/*** 按一定的概率初始化奖品*/public List<String> prize() {List<String> list = new ArrayList<>();// 10个京豆,概率10%for (int i = 0; i < 10; i++) {list.add("10-" + i);}// 5个京豆,概率20%for (int i = 0; i < 20; i++) {list.add("5-" + i);}// 1个京豆,概率60%for (int i = 0; i < 60; i++) {list.add("1-" + i);}// 0个京豆,概率10%for (int i = 0; i < 10; i++) {list.add("0-" + i);}return list;}}
步骤2:抽奖
@Autowiredprivate RedisTemplate redisTemplate;@GetMapping(value = "/prize")public String prize() {String result = "";try {// 随机取1次String object = (String)this.redisTemplate.opsForSet().randomMember(Constants.PRIZE_KEY);if (!StringUtils.isEmpty(object)){// 截取序列号 例如10-1int temp = object.indexOf('-');int no = Integer.valueOf(object.substring(0 , temp));switch (no){case 0:result = "谢谢参与";break;case 1:result = "获得1个京豆";break;case 5:result = "获得5个京豆";break;case 10:result = "获得10个京豆";break;default:result = "谢谢参与";}}log.info("查询结果:{}", object);} catch (Exception ex) {log.error("exception:", ex);}return result;}
4、支付宝天天抽奖实战
4.1 支付宝天天抽奖的业务场景分析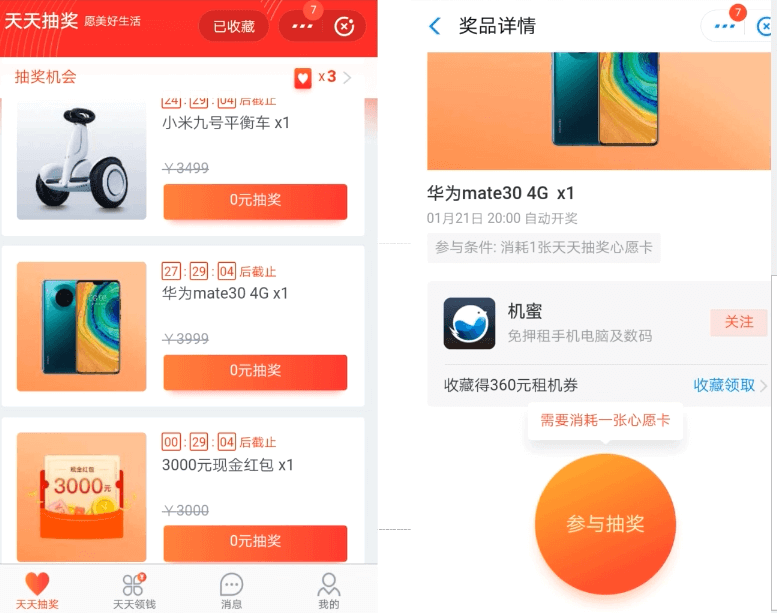
4.2 支付宝抽奖的技术方案
1、问题:支付宝的抽奖和京东京豆的抽奖有什么区别????
1)京豆抽奖:奖品是可以重复,例如抽5京豆可以再抽到5京豆,即京豆是无限量抽。
2)支付宝抽奖:奖品不能重复抽,例如1万人抽1台华为手机;再给大家举一个熟悉的例子: 例如公司年会,抽中奖品的人,下一轮就不能重复抽取,不然就会重复中奖。
2、支付宝抽奖技术方案和京东京豆类似,但是不同的是:
1)京东的京豆用了srandmember命令,即随机返回set的一个元素
2)支付宝的抽奖要用spop命令,即随机返回并删除set中一个元素
3、为什么呢?
因为支付宝的奖品有限,不能重复抽,故抽奖完后,必须从集合中剔除中奖的人。
再 举个每个人都参与过的例子,年会抽奖,你公司1000人,年会抽奖3等奖500名100元,2等奖50名1000元,1等奖10名10000元, 在抽奖的设计中就必须把已中奖的人剔除,不然就会出现重复中奖的概率。
4.3 案例实战:SpringBoot+Redis实现支付宝抽奖
步骤1:初始化抽奖数据
@Service@Slf4jpublic class TaskCrowdService {@Autowiredprivate RedisTemplate redisTemplate;/*** 提前先把数据刷新到redis缓存中*/@PostConstructpublic void init(){log.info("启动初始化..........");boolean bo = this.redisTemplate.hasKey(Constants.PRIZE_KEY);if(!bo){List<Integer> crowds = this.prize();crowds.forEach(t->this.redisTemplate.opsForSet().add(Constants.PRIZE_KEY, t));}}/*** 模拟10个用户来抽奖 list存放的是用户id* 例如支付宝参与抽奖,就把用户id加入set集合中* 例如公司抽奖,把公司所有的员工,工号都加入到set集合中*/public List<Integer> prize() {List<Integer> list = new ArrayList<>();for(int i=1; i<=10; i++){list.add(i);}return list;}}
步骤2:抽奖逻辑
@Autowiredprivate RedisTemplate redisTemplate;@GetMapping(value = "/prize")public List<Integer> prize(int num) {try {SetOperations<String, Integer> setOperations = this.redisTemplate.opsForSet();// spop命令,即随机返回并删除set中一个元素List<Integer> objs = setOperations.pop(Constants.PRIZE_KEY, num);log.info("查询结果:{}", objs);return objs;} catch (Exception ex) {log.error("exception:", ex);}return null;}
5、基于Redis的高并发随机展示
5.1 随机展示业务场景分析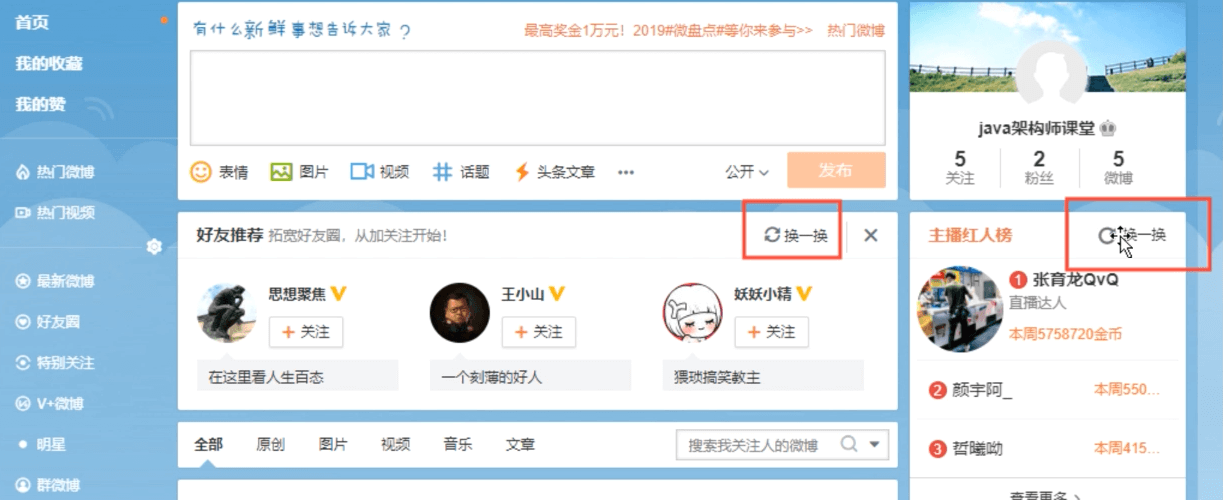
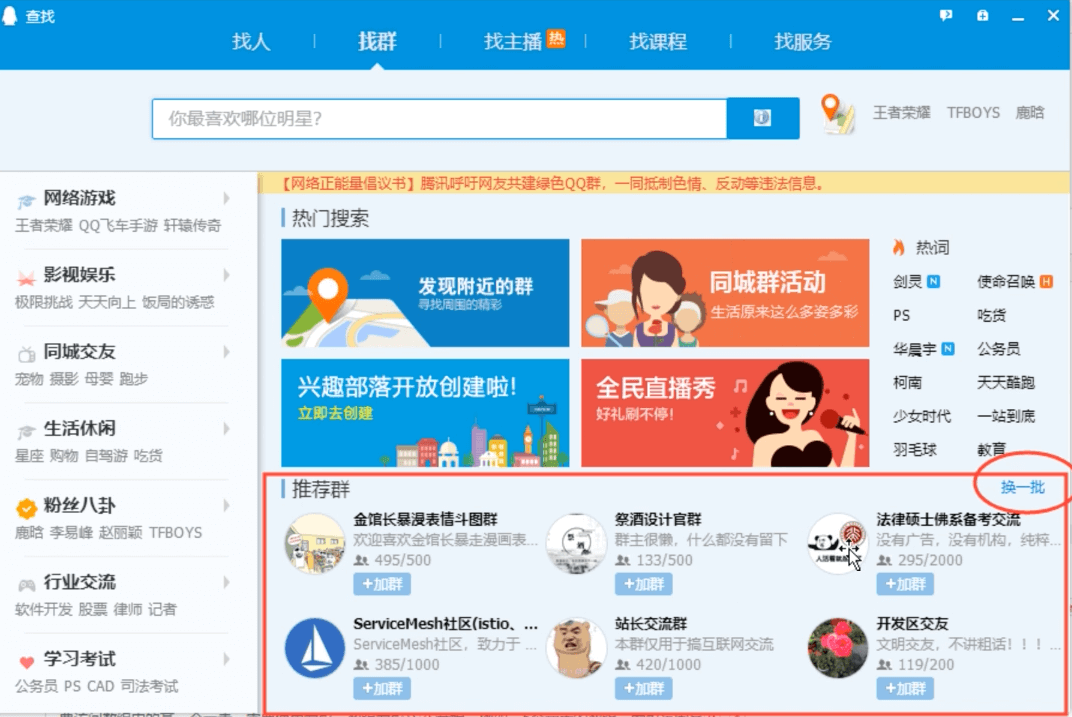
思考题:为什么要随机展示? 因为展示的区域有限啊,在那么小的地方展示全部数据是不可能的,通常的做法就是随机展示一批数据,然后用户点击“换一换”按钮,再随机展示另一批。
5.2 随机展示的Redis技术方案
上文已经说了随机展示的原因就是区域有限,而区域有限的地方通常就是首页或频道页,这些位置通常都是访问量并发量非常高的, 一般是不可能采用数据库来实现的,通常都是Redis来实现。
Redis的实现技术方案:
步骤1:先把数据准备好,把所有需要展示的内容存入Redis的Set数据结构中
步骤2:通过srandmember命令随机拿一批数据出来
5.3 SpringBoot+Redis实现微博好友、QQ群随机推荐
步骤1:提前先把数据刷新到redis缓存中
@Service@Slf4jpublic class TaskCrowdService {@Autowiredprivate RedisTemplate redisTemplate;/*** 提前先把数据刷新到redis缓存中。*/@PostConstructpublic void init(){log.info("启动初始化 群..........");List<String> crowds = this.crowd();this.redisTemplate.delete(Constants.CROWD_KEY);crowds.forEach(t -> this.redisTemplate.opsForSet().add(Constants.CROWD_KEY, t));}/*** 模拟100个热门群,用于推荐*/public List<String> crowd() {List<String> list = new ArrayList<>();for (int i = 0; i < 100; i++) {Random rand = new Random();int id = rand.nextInt(10000);list.add("群" + id);}return list;}}
步骤2:编写随机查询接口
@Autowiredprivate RedisTemplate redisTemplate;@GetMapping(value = "/crowd")public List<String> crowd() {List<String> list = null;try {//采用redis set数据结构,随机取出10条数据list = this.redisTemplate.opsForSet().randomMembers(Constants.CROWD_KEY, 10);log.info("查询结果:{}", list);} catch (Exception ex) {//这里的异常,一般是redis瘫痪 ,或 redis网络timeoutlog.error("exception:", ex);//TODO 走DB查询}return list;}
5.4 SpringBoot+Redis实现微博榜单随机推荐
步骤1:提前先把数据刷新到redis缓存中。
微博榜单和QQ群的区别是:微博榜单是整块数据的,所以随机的数据要按块来推荐。所以我们要定义一个java bean来包装整块数据
@Datapublic class WeiboList {private int id;/*** 榜单名称*/private String name;private List<String> users;}
@Service@Slf4jpublic class TaskWeiboListService {@Autowiredprivate RedisTemplate redisTemplate;/*** 定时把数据库的 ,刷新到redis缓存中。*/@PostConstructpublic void init(){log.info("启动初始化 榜单..........");List<WeiboList> crowds = this.list();this.redisTemplate.delete(Constants.WEIBO_LIST_KEY);crowds.forEach(t -> this.redisTemplate.opsForSet().add(Constants.WEIBO_LIST_KEY, t));}/*** 模拟10个热门榜单,用于推荐*/public List<WeiboList> list() {List<WeiboList> list = new ArrayList<>();for (int i = 0; i < 10; i++) {WeiboList wl = new WeiboList();wl.setId(i);wl.setName("榜单" + i);Random rand = new Random();List<String> users = new ArrayList<>();for (int j = 0; j<3; j++){int id = rand.nextInt(10000);users.add("user:" + id);}wl.setUsers(users);list.add(wl);}return list;}}
步骤2:编写随机查询接口
@GetMapping(value = "/weibolist")public WeiboList weibolist() {WeiboList list = null;try {// 随机取1块数据list = (WeiboList)this.redisTemplate.opsForSet().randomMember(Constants.WEIBO_LIST_KEY);log.info("查询结果:{}", list);} catch (Exception ex) {//这里的异常,一般是redis瘫痪 ,或 redis网络timeoutlog.error("exception:", ex);//TODO 走DB查询}return list;}
6、微博实战:帖子点赞
6.1 微博点赞业务场景分析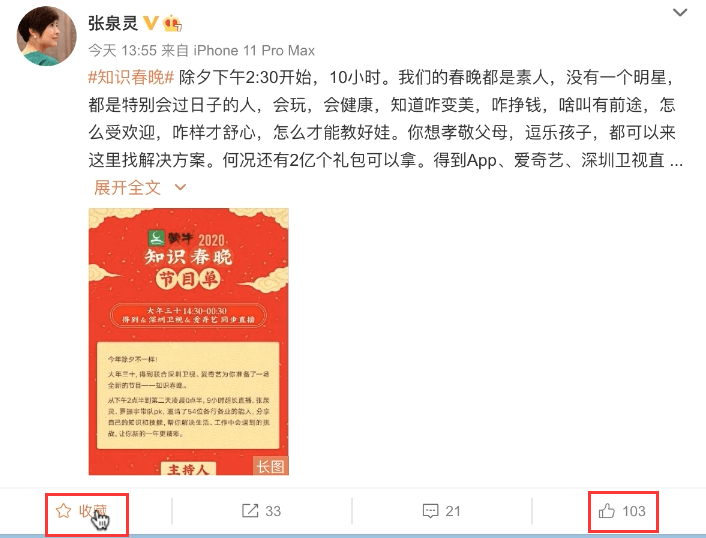
梳理点赞的业务场景,它有2个接口:
第一个接口:点赞或取消点赞,用户点击功能
第二个接口:查看帖子信息,通过用户id 和帖子id,查看该帖子的点赞数、该用户是否已点赞。
6.2 微博点赞的技术方案
点赞的关键技术就是要判断该用户是否点赞,已重复点赞的不允许再点赞,即过滤重复,虽然业务不复杂,可以采用数据库直接实现,但是对于微博这种高并发的场景,不可能查数据库的,一般是缓存,即Redis
我们来对上文梳理的2个接口进行技术分析:
第一个:点赞或取消点赞,用户点击功能。采用的是Redis的set数据结构,key = like: postid value = {userid}
127.0.0.1:6379> sadd like:1000 101(integer) 1127.0.0.1:6379> sadd like:1000 102(integer) 1127.0.0.1:6379> sadd like:1000 103(integer) 1127.0.0.1:6379> smembers like:10001) "101"2) "102"3) "103"
127.0.0.1:6379> srem like:1000 101(integer) 1127.0.0.1:6379> smembers like:10001) "102"2) "103"
第二个接口:查看帖子信息,通过用户id 和帖子id,查看该帖子的点赞数、该用户是否点赞状态。
127.0.0.1:6379> smembers like:10001) "102"2) "103"127.0.0.1:6379> scard like:1000(integer) 2
127.0.0.1:6379> smembers like:10001) "102"2) "103"127.0.0.1:6379> sismember like:1000 102(integer) 1127.0.0.1:6379> sismember like:1000 101(integer) 0
6.3 案例实战:SpringBoot+Redis 实现微博点赞
@RestController@Slf4j//@RequestMapping(value = "/")public class Controller {@Autowiredprivate RedisTemplate redisTemplate;/*** 点赞*/@GetMapping(value = "/dolike")public String dolike(int postid, int userid) {String result = "";try {String key = Constants.LIKE_KEY + postid;long object = this.redisTemplate.opsForSet().add(key, userid);if (object == 1){result = "点赞成功";}else{result = "你已重复点赞";}log.info("查询结果:{}", object);} catch (Exception ex) {log.error("exception:", ex);}return result;}/*** 取消点赞*/@GetMapping(value = "/undolike")public String undolike(int postid, int userid) {String result = "";try {String key = Constants.LIKE_KEY + postid;long object = this.redisTemplate.opsForSet().remove(key, userid);if (object == 1){result = "取消成功";}else{result = "你已重复取消点赞";}log.info("查询结果:{}", object);} catch (Exception ex) {log.error("exception:", ex);}return result;}/*** 根据postid userid查看帖子信息,返回结果是点赞总数和是否点赞*/@GetMapping(value = "/getpost")public Map getpost(int postid, int userid) {Map map = new HashMap();String result = "";try {String key = Constants.LIKE_KEY + postid;long size = this.redisTemplate.opsForSet().size(key);boolean bo = this.redisTemplate.opsForSet().isMember(key, userid);map.put("size", size);map.put("isLike", bo);log.info("查询结果:{}", map);} catch (Exception ex) {log.error("exception:", ex);}return map;}/*** 查看点赞明细,就是有哪些人点赞*/@GetMapping(value = "/likedetail")public Set likedetail(int postid) {Set set = null;try {String key = Constants.LIKE_KEY + postid;set = this.redisTemplate.opsForSet().members(key);log.info("查询结果:{}", set);} catch (Exception ex) {log.error("exception:", ex);}return set;}}
7、微博实战:微博关注与粉丝
8、微博实战:微关系计算
8.1 计算好友关系业务场景分析
8.2 计算好友关系的Redis技术方案
8.3 SpringBoot+Redis实现计算微博好友关系
五、Redis分布式缓存设计(zset专题)
1、Zset命令实战
zset 是 set 的一个升级版本,它在 set 的基础上增加了一个顺序属性, 它和 set 一样,zset也是 string 类型元素的集合,且不允许重复的成员,不同的是每个元素都会关联一个 double类型的 score。 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 2的(32 - 1)次方 (4294967295, 每个集合可存储40多亿个成员)。 zset 最经典的应用场景就是排行榜。
ZADD:ZADD key score member [[score member] [score member] …] 将一个或多个member元素及其score值加入到有序集key当中。
案例:创业公司招进了4个员工,分别为: alex 工资2000元 tom工资5000元 jack工资6000元 阿甘1000元,请按工资升序排序39.100.196.99:6379> zadd salary 2000 alex 5000 tom 6000 jack 1000 agan(integer) 439.100.196.99:6379> zrange salary 0 -1 withscores1) "agan"2) "1000"3) "alex"4) "2000"5) "tom"6) "5000"7) "jack"8) "6000"(1.21s)
案例:创业公司 tom离职了39.100.196.99:6379> zrange salary 0 -1 withscores1) "agan"2) "1000"3) "alex"4) "2000"5) "tom"6) "5000"7) "jack"8) "6000"(1.21s)39.100.196.99:6379> zrem salary tom(integer) 139.100.196.99:6379> zrange salary 0 -1 withscores1) "agan"2) "1000"3) "alex"4) "2000"5) "jack"6) "6000"
案例:创业公司 有多少人39.100.196.99:6379> zrange salary 0 -1 withscores1) "agan"2) "1000"3) "alex"4) "2000"5) "jack"6) "6000"39.100.196.99:6379> zcard salary(integer) 3
案例:创业公司老板问你 ,工资在2000 至 6000有多少人39.100.196.99:6379> zrange salary 0 -1 withscores1) "agan"2) "1000"3) "alex"4) "2000"5) "tom"6) "5000"7) "jack"8) "6000"39.100.196.99:6379> ZCOUNT salary 2000 6000(integer) 3
案例:创业公司老板问你 ,阿甘的工资是多少 ?39.100.196.99:6379> zrange salary 0 -1 withscores1) "agan"2) "1000"3) "alex"4) "2000"5) "tom"6) "5000"7) "jack"8) "6000"39.100.196.99:6379> zscore salary agan"1000"
案例:创业公司老板说阿甘表现很好,给他加500元吧39.100.196.99:6379> ZINCRBY salary 500 agan"1500"39.100.196.99:6379> zrange salary 0 -1 withscores1) "agan"2) "1500"3) "alex"4) "2000"5) "tom"6) "5000"7) "jack"8) "6000"
ZREVRANGE
ZREVRANGE key start stop [WITHSCORES] 返回有序集key中,指定区间内的成员、降序
案例:创业公司老板说经济不好,成本太大,看工资最多的是哪些人?39.100.196.99:6379> zrange salary 0 -1 withscores #升序1) "agan"2) "1500"3) "alex"4) "2000"5) "tom"6) "5000"7) "jack"8) "6000"39.100.196.99:6379> ZREVRANGE salary 0 -1 withscores #降序1) "jack"2) "6000"3) "tom"4) "5000"5) "alex"6) "2000"7) "agan"8) "1500"
ZRANGEBYSCORE:取某个范围score的member,可以用于分页查询
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
返回有序集key中,所有score值介于min和max之间(包括等于min或max)的成员。有序集成员按score值递增(从小到大)次序排列。
案例:创业公司老板要给工资低的人加薪水,老板要求先看低于5000元的有哪些人?人多的话分页查看39.100.196.99:6379> ZREVRANGE salary 0 -1 withscores1) "jack"2) "6000"3) "tom"4) "5000"5) "alex"6) "2000"7) "agan"8) "1500"39.100.196.99:6379> ZRANGEBYSCORE salary 1 50001) "agan"2) "alex"3) "tom"39.100.196.99:6379> ZRANGEBYSCORE salary 1 5000 LIMIT 0 21) "agan"2) "alex"39.100.196.99:6379> ZRANGEBYSCORE salary 1 5000 LIMIT 2 21) "tom"
ZREVRANGEBYSCORE 和上面的功能意义,但是这次是降序的
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] 返回有序集key中,score值介于max和min之间(默认包括等于max或min)的所有的成员。有序集成员按score值递减(从大到小)的次序排列。
ZRANK:取某个member的排名、升序
ZRANK key member
案例:创业公司老板要查,工资从低到高,查某个员工排第几名?9.100.196.99:6379> ZREVRANGE salary 0 -1 withscores1) "jack"2) "6000"3) "tom"4) "5000"5) "alex"6) "2000"7) "agan"8) "1500"(0.75s)39.100.196.99:6379> ZRANK salary agan(integer) 0
ZREVRANK:取某个member的排名,降序
ZREVRANK key member
ZREMRANGEBYRANK:移除指定排名(rank)区间内的所有成员
ZREMRANGEBYRANK key start stop
案例:经济不好,老板要裁员了,把工资最低的2个人裁掉39.100.196.99:6379> zrange salary 0 -1 withscores1) "agan"2) "1500"3) "alex"4) "2000"5) "tom"6) "5000"7) "jack"8) "6000"39.100.196.99:6379> ZREMRANGEBYRANK salary 0 1(integer) 239.100.196.99:6379> zrange salary 0 -1 withscores1) "tom"2) "5000"3) "jack"4) "6000"
ZREMRANGEBYSCORE:移除指定score值介于min和max之间(包括等于min或max)的成员
ZREMRANGEBYSCORE key min max
案例:经济不好,老板要裁员了,把工资1000至2000之间的人裁掉39.100.196.99:6379> zrange salary 0 -1 withscores1) "agan"2) "1000"3) "alex"4) "2000"5) "tom"6) "5000"7) "jack"8) "6000"39.100.196.99:6379> ZREMRANGEBYSCORE salary 1000 2000(integer) 239.100.196.99:6379> zrange salary 0 -1 withscores1) "tom"2) "5000"3) "jack"4) "6000"
ZINTERSTORE 求交集
ZINTERSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX] 计算给定的一个或多个有序集的交集,其中给定key的数量必须以numkeys参数指定,并将该交集(结果集)储存到destination。
39.100.196.99:6379> zadd group1 10 a 20 b 30 c(integer) 339.100.196.99:6379> zadd group2 10 x 20 y 30 z 20 c(integer) 439.100.196.99:6379> ZINTERSTORE group3 group1 group2(error) ERR value is not an integer or out of range39.100.196.99:6379> ZINTERSTORE group3 2 group1 group2(integer) 139.100.196.99:6379> zrange group3 0 -1 withscores1) "c"2) "50"
ZUNIONSTORE求并集
ZUNIONSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX] 计算给定的一个或多个有序集的并集,其中给定key的数量必须以numkeys参数指定,并将该并集(结果集)储存到destination。
39.100.196.99:6379> ZUNIONSTORE group4 2 group1 group2(integer) 639.100.196.99:6379> zrange group4 0 -1 withscores1) "a"2) "10"3) "x"4) "10"5) "b"6) "20"7) "y"8) "20"9) "z"10) "30"11) "c"12) "50"
2、微博实战:微博热搜排行榜
2.1 业务场景分析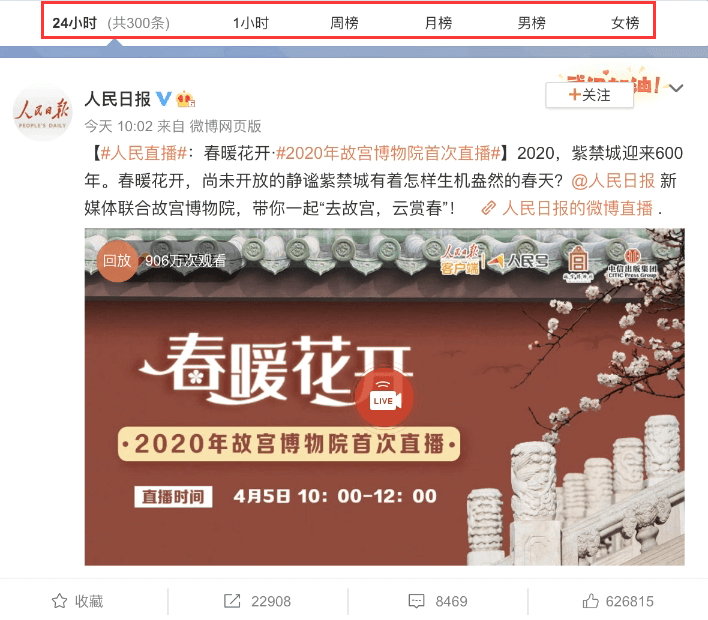


2.2 技术方案
3.3 案例实战:springboot+redis实现微博热搜排行榜
技术模拟思路:采用26个英文字母来实现排行,随机为每个字母生成一个随机数作为score
为了更好的体验,先做几件事:
- 先初始化1个月的历史数据
- 定时5秒钟,模拟微博的热度刷新(例如模拟点赞、收藏、评论的热度值更新)
- 定时1小时合并统计天、周、月的排行榜
步骤1:先初始化1个月的历史数据
package com.agan.redis.task;@Service@Slf4jpublic class InitService {@Autowiredprivate RedisTemplate redisTemplate;/*** 先初始化1个月的历史数据*/public void init30day(){// 计算当前的小时keylong hour = System.currentTimeMillis() / (1000*60*60);// 初始化近30天,每天24个keyfor(int i = 1; i < 24*30; i++){// 倒推过去30天String key = Constants.HOUR_KEY + (hour - i);this.initMember(key);System.out.println(key);}}/*** 初始化某个小时的key*/public void initMember(String key) {Random rand = new Random();// 采用26个英文字母来实现排行,随机为每个字母生成一个随机数作为scorefor(int i = 1; i <= 26; i++){this.redisTemplate.opsForZSet().add(key,String.valueOf((char)(96 + i)), rand.nextInt(10));}}}
步骤2:定时刷新数据
@Service@Slf4jpublic class TaskService {@Autowiredprivate RedisTemplate redisTemplate;/***2. 定时5秒钟,模拟微博的热度刷新(例如模拟点赞 收藏 评论的热度值更新)* 3. 定时1小时合并统计 天、周、月的排行榜。*/@PostConstructpublic void init(){log.info("启动初始化 ..........");// 2. 定时5秒钟,模拟微博的热度刷新(例如模拟点赞 收藏 评论的热度值更新)new Thread(()->this.refreshDataHour()).start();// 3. 定时1小时合并统计 天、周、月的排行榜。new Thread(()->this.refreshData()).start();}/*** 采用26个英文字母来实现排行,随机为每个字母生成一个随机数作为score*/public void refreshHour(){// 计算当前的小时keylong hour = System.currentTimeMillis()/(1000*60*60);// 为26个英文字母来实现排行,随机为每个字母生成一个随机数作为scoreRandom rand = new Random();for(int i = 1; i <= 26; i++){//redis的ZINCRBY 新增这个积分值this.redisTemplate.opsForZSet().incrementScore(Constants.HOUR_KEY+hour,String.valueOf((char)(96 + i)), rand.nextInt(10));}}/*** 刷新当天的统计数据*/public void refreshDay(){long hour=System.currentTimeMillis() / (1000*60*60);List<String> otherKeys = new ArrayList<>();// 算出近24小时内的keyfor(int i = 1; i < 23; i++){String key = Constants.HOUR_KEY + (hour - i);otherKeys.add(key);}// 把当前的时间key,并且把后推23个小时,共计近24小时,求出并集存入Constants.DAY_KEY中// redis ZUNIONSTORE 求并集this.redisTemplate.opsForZSet().unionAndStore(Constants.HOUR_KEY+hour,otherKeys,Constants.DAY_KEY);// 设置当天的key 40天过期,不然历史数据浪费内存for(int i=0;i<24;i++){String key=Constants.HOUR_KEY+(hour-i);this.redisTemplate.expire(key,40, TimeUnit.DAYS);}log.info("天刷新完成..........");}/*** 刷新7天的统计数据*/public void refreshWeek(){long hour = System.currentTimeMillis() / (1000*60*60);List<String> otherKeys = new ArrayList<>();// 算出近7天内的keyfor(int i = 1; i < 24*7-1; i++){String key=Constants.HOUR_KEY+(hour-i);otherKeys.add(key);}// 把当前的时间key,并且把后推24*7-1个小时,共计近24*7小时,求出并集存入Constants.WEEK_KEY中this.redisTemplate.opsForZSet().unionAndStore(Constants.HOUR_KEY + hour, otherKeys, Constants.WEEK_KEY);log.info("周刷新完成..........");}/*** 刷新30天的统计数据*/public void refreshMonth(){long hour = System.currentTimeMillis()/(1000*60*60);List<String> otherKeys = new ArrayList<>();// 算出近30天内的keyfor(int i = 1; i < 24*30-1; i++){String key = Constants.HOUR_KEY + (hour-i);otherKeys.add(key);}//把当前的时间key,并且把后推24*30个小时,共计近24*30小时,求出并集存入Constants.MONTH_KEY中this.redisTemplate.opsForZSet().unionAndStore(Constants.HOUR_KEY + hour, otherKeys, Constants.MONTH_KEY);log.info("月刷新完成..........");}/*** 定时1小时合并统计 天、周、月的排行榜。*/public void refreshData(){while (true){// 刷新当天的统计数据this.refreshDay();// 刷新7天的统计数据this.refreshWeek();// 刷新30天的统计数据this.refreshMonth();//TODO 在分布式系统中,建议用xxljob来实现定时try {Thread.sleep(1000*60*60);} catch (InterruptedException e) {e.printStackTrace();}}}/*** 定时5秒钟,模拟微博的热度刷新(例如模拟点赞 收藏 评论的热度值更新)*/public void refreshDataHour(){while (true){this.refreshHour();// TODO 在分布式系统中,建议用xxljob来实现定时try {Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}}}}
步骤3:排行榜查询接口
@RestController@Slf4jpublic class Controller {@Autowiredprivate RedisTemplate redisTemplate;@GetMapping(value = "/getHour")public Set getHour() {long hour=System.currentTimeMillis()/(1000*60*60);//ZREVRANGE 返回有序集key中,指定区间内的成员,降序。Set<ZSetOperations.TypedTuple<Integer>> rang = this.redisTemplate.opsForZSet().reverseRangeWithScores(Constants.HOUR_KEY + hour, 0, 30);return rang;}@GetMapping(value = "/getDay")public Set getDay() {Set<ZSetOperations.TypedTuple<Integer>> rang = this.redisTemplate.opsForZSet().reverseRangeWithScores(Constants.DAY_KEY, 0, 30);return rang;}@GetMapping(value = "/getWeek")public Set getWeek() {Set<ZSetOperations.TypedTuple<Integer>> rang = this.redisTemplate.opsForZSet().reverseRangeWithScores(Constants.WEEK_KEY, 0, 30);return rang;}@GetMapping(value = "/getMonth")public Set getMonth() {Set<ZSetOperations.TypedTuple<Integer>> rang = this.redisTemplate.opsForZSet().reverseRangeWithScores(Constants.MONTH_KEY, 0, 30);return rang;}}public class Constants {public static final String HOUR_KEY = "rank:hour:";public static final String DAY_KEY = "rank:day";public static final String WEEK_KEY = "rank:week";public static final String MONTH_KEY = "rank:month";}
3、美团地图附近酒店搜索
3.1 业务场景分析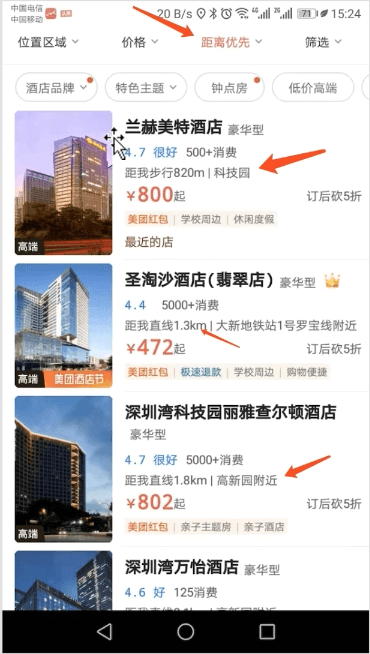
3.2 技术方案
自Redis 3.2开始,Redis基于Geohash和Zset提供了地理位置相关功能。
Geohash是一种地址编码,它能把二维的经纬度编码成一维的字符串。比如,世界之窗的编码是ws101xy1rp0。
Redis Geo模块包含了以下6个命令:
1)GEOADD:将给定的位置对象(纬度、经度、名字)添加到指定的key;
39.100.196.99:6379> geoadd hotel 113.9807127428 22.5428248089 "世界之窗" 113.9832042690 22.5408496326 "南山威尼斯酒店" 114.0684865267 22.5412294122 "福田喜来登酒店" 114.3135524539 22.5999265998 "大梅沙海景酒店" 113.9349465491 22.5305488659 "南山新年酒店" 114.0926367279 22.5497917634 "深圳华强广场酒店"639.100.196.99:6379> zrange hotel 0 -1南山新年酒店世界之窗南山威尼斯酒店福田喜来登酒店深圳华强广场酒店大梅沙海景酒店
注:
- 这里我们采用的是中文存储,如果出现了乱码,redis命令的登录命令加上 —raw,例如: ./redis-cli —raw
- 查看某个地址的经纬度,建议用 http://www.gpsspg.com/maps.htm,本课程就是用这个网址查出某个地址的具体经纬度
2)GEOPOS:从key里面返回所有给定位置对象的位置(经度和纬度);
39.100.196.99:6379> GEOPOS hotel "世界之窗"113.9807108044624328622.54282525199023013
3)GEOHASH:返回一个或多个位置对象的Geohash表示;
39.100.196.99:6379> GEOHASH hotel "世界之窗"ws101xy1rp0
4)GEODIST key member1 member2 [unit]:返回两个给定位置之间的距离;
指定单位的参数 unit 必须是以下单位的其中一个: — m 表示单位为米。 — km 表示单位为千米。 — mi 表示单位为英里。 — ft 表示单位为英尺
39.100.196.99:6379> GEODIST hotel "世界之窗" "南山威尼斯酒店" m337.4887
5)GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
给定一个经纬度,然后以半径为中心,计算出半径内的数据。
39.100.196.99:6379> GEORADIUS hotel 113.9410499639 22.5461508801 10 km WITHDIST WITHCOORD count 10南山新年酒店1.8451113.9349469542503356922.53054959741555052世界之窗4.0910113.9807108044624328622.54282525199023013南山威尼斯酒店4.3704113.9832052588462829622.54085070420710224
— WITHDIST:在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
— WITHCOORD:将位置元素的经度和维度也一并返回。
— WITHHASH:以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
— ASC、DESC:排序方式,按照距离的升序、降序排列
— STORE key1:把结果存入key1,zset格式,以坐标hash为score
— STOREDIST key2:把结果存入key2,zset格式,以距离为score
6)GEORADIUSBYMEMBER key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
GEORADIUSBYMEMBER 和 GEORADIUS 一样的功能,区别在于,GEORADIUS是以经纬度去查询,而GEORADIUSBYMEMBER是以当前集合中的某个member元素来查询
39.100.196.99:6379> GEORADIUSBYMEMBER hotel "世界之窗" 10 km WITHDIST WITHCOORD count 10世界之窗0.0000113.9807108044624328622.54282525199023013南山威尼斯酒店0.3375113.9832052588462829622.54085070420710224南山新年酒店4.8957113.9349469542503356922.53054959741555052福田喜来登酒店9.0190114.0684887766838073722.54122837765984144
3.3 案例实战:SpringBoot+Redis实现美团地图附近酒店搜索
@RestController@Slf4jpublic class Controller {@Autowiredprivate RedisTemplate redisTemplate;@GetMapping(value = "/init")public void init() {Map<String, Point> map = Maps.newHashMap();map.put("世界之窗", new Point(113.9807127428,22.5428248089));map.put("南山威尼斯酒店", new Point(113.9832042690 ,22.5408496326));map.put("福田喜来登酒店" , new Point(114.0684865267,22.5412294122));map.put("大梅沙海景酒店", new Point(114.3135524539 ,22.5999265998));map.put("南山新年酒店", new Point(113.9349465491,22.5305488659));map.put("深圳华强广场酒店", new Point(114.0926367279 ,22.5497917634));this.redisTemplate.opsForGeo().add(Constants.HOTEL_KEY, map);}@GetMapping(value = "/position")public Point position(String member) {// 获取经纬度坐标List<Point> list = this.redisTemplate.opsForGeo().position(Constants.HOTEL_KEY, member);return list.get(0);}@GetMapping(value = "/hash")public String hash(String member) {// geohash算法生成的base32编码值List<String> list = this.redisTemplate.opsForGeo().hash(Constants.HOTEL_KEY, member);return list.get(0);}@GetMapping(value = "/distance")public Distance distance(String member1, String member2) {Distance distance = this.redisTemplate.opsForGeo().distance(Constants.HOTEL_KEY, member1, member2, RedisGeoCommands.DistanceUnit.KILOMETERS);return distance;}/*** 通过经度,纬度查找附近的*/@GetMapping(value = "/radiusByxy")public GeoResults radiusByxy() {// 这个坐标是腾讯大厦位置Circle circle = new Circle(113.9410499639, 22.5461508801, Metrics.KILOMETERS.getMultiplier());// 返回50条RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(50);GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults = this.redisTemplate.opsForGeo().radius(Constants.HOTEL_KEY, circle, args);return geoResults;}/*** 通过地方查找附近*/@GetMapping(value = "/radiusByMember")public GeoResults radiusByMember() {String member ="世界之窗";// 返回50条RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(50);// 半径10公里内Distance distance = new Distance(10, Metrics.KILOMETERS);GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults = this.redisTemplate.opsForGeo().radius(Constants.HOTEL_KEY, member, distance, args);return geoResults;}}
4、微博实战:pull推送
4.1 微博push和pull有什么区别
4.2 微博pull拉取的redis技术方案
4.3 案例实战:基于pull技术,实现微博个人列表
4.4 案例实战:基于pull技术,实现微博关注列表
5、淘宝直播卖货
5.1 业务场景分析
5.2 技术方案
5.3 案例实战:基于Redis的直播发言弹幕
6、今日头条推荐引擎-布隆过滤器
6.1 推荐引擎已读去重-业务场景分析
6.2 如何实现已读去重
6.3 什么事布隆过滤器
6.4 采用docker安装RedisBloom
6.5 案例实战:SpringBoot+Redis实现推荐引擎已读去重
6.6 布隆过滤器设计原理剖析
7、Redis的IRC聊天工具
7.1 什么是Redis的stream数据结构
7.2 stream生产消息
7.3 stream独立消息
7.4 消息ID的原理
7.5 Redis的IRC聊天室
7.6 SpringBoot实现Redis的IRC聊天室
8、微服务的stream消息队列
8.1 为什么要用消息组,它解决了什么问题
8.2 案例实战:积分服务消息组
8.3 如何确保消息100%消费成功
8.4 没人消费的消息,采用消息转移
8.5 删除死信消息
8.6 案例实战:积分服务的消费队列
8.7 案例实战:积分服务 +push服务的集群消费队列
六、Spring源码分析:Spring与Redis通信原理剖析
1、Redis哈希槽分区
2、Spring与Redis的底层通信
3、Redis通讯协议
4、Redis面试题
5、Spring和Redis的通信原理
6、Redis通信异常处理

若有收获,就点个赞吧
0 人点赞
