- 在计算机里面,所有的都是数据
- 字符编码的本质就是:数值==>代表什么==>显示为什么

- ASCII码涵盖了英文书写所需的大部分字符,8bit,其中低7位用于表示字符对应的数值
- 常用汉字有6000多个,一个字节(8bit)显然是无法满足的
- 中国大陆用两字节来表示汉字
- 那么用什么值来表示哪一个汉字呢?
- 引入了自己的字符编码:GBK(国标扩展),其中定义了一个表(值和字符的映射表)
- GB2312
- 港澳台
- 繁体字
- 用什么值来表示哪一个汉字?
- 同样发展出了一套对应的字符编码:BIG5
- 两套不同的标准(GBK和BIG5)会导致相同的数值映射出的文字是不一样(也有可能有部分一样)
- 从”数值==>代表什么”,引入了字符编码
- ASCII
- GBK
- BIG5
- ……
- 那么就有个问题:使用不同的编码,同一个数值会对应不同的文字
- 比如:一个文件是香港人写的,文件使用BIG5编码得到的数值存储;我们在内地(没有安装BIG5的电脑)用GBK解析文件,将会得到一堆乱码
- GBK没办法把BIG5写的文件解析出来
- 全世界统一弄出一个编码表
- Unicode编码
- 用什么数值表示什么字符,也是一个映射的表格
- Unicode并没有限制一个数值要用多少个字节来表示

- Unicode编码表只是给出了数值与字符的关系;所以要考虑怎么表示Unicode码?
- 即Unicode码的数值应该用多少个字节存储的问题(计算机中如何保存这些数值)
- 怎么表示Unicode码?常用有如下方法:
- UTF-8
- UTF-16LE
- UTF-16BE
- 。。。
- UTF-8

- 0xEFBBBF三个字节用来表示UTF-8的编码格式
- UTF-16LE

- 0xFFFE两个字节用来表示小端
- 小端:高字节在后面,低字节在前面
- UTF-16BE

- 0xFEFF表示大端
- 大端:高字节在前面(0x00),低字节在后面(0x61)
- 在保存文件选择ASCII码时,会用计算机默认的编码格式(汉字默认为GB2312)
- UTF-16使用两个字节表示一个字符,只使用Unicode编码表
- UTF-8和UTF-16相比较特殊,我们需要直到它是如何表示Unicode的
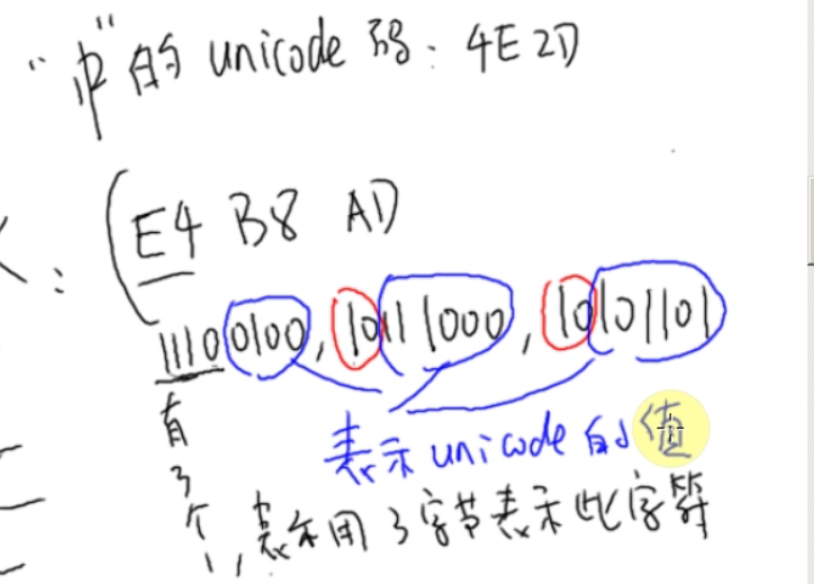
- UTF-8是变长的


- UTF-8可以使用1-4个字节表示一个符号,根据不同的符号而变化字节长度

参考:

- 一个字符==>显示为”什么”
- 点阵,字体
- 字体文件
- 含有编码表
- 字体数据
- 不同的字体文件中可能包含不同的字符集(也就是说具备不同的解码能力)
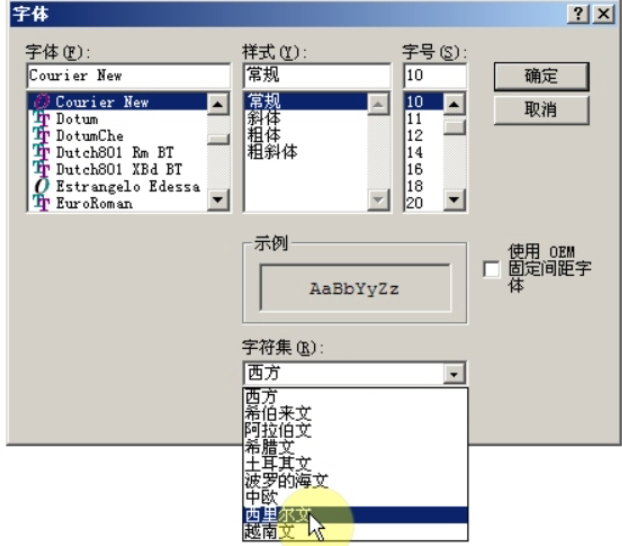
- 选择一个字体文件,除了有文字的字形外,还会有编码表;否则没办法根据数值直到要显示什么
同一段代码,源文件以不同的编码方式(ANSI/UTF-8…)保存,输出不同的结果
- 这并不是我们希望看到的结果
- man gcc下查找charset可以得到编译时关于字符集的问题
- 编译程序时,要指定字符集
- -finput-charset=charset 表示源文件的编码方式,默认以UTF-8来解析(如果解析出错,将会报错)
- -fexec-charset=charset 表示可执行程序里的字符以什么编码方式表示,默认UTF-8

- 如果源文件是以ANSI方式保存,GCC编译读取源文件时默认还是按UTF-8来解析它(并且可能不会报错,因为ANSI方式保存的文件其底层数值可能是正确存在UTF-8里的)

- -finput-charset=GBK 告诉GCC输入的字符集是国标码
- -fexec-charset=UTF-8 告诉编译器输出可执行程序时表示字符要按UTF-8来表示
- 这样可执行程序输出的结果和源文件是UTF-8,不指定字符集的结果是一样的
Unicode编码中表示字节排列顺序的那个文件头,叫做BOM(byte-order mark),FFFE和FEFF就是不同的BOM。
- UTF-8文件的BOM是“EF BB BF”,但是UTF-8的字节顺序是不变的,因此这个文件头实际上不起作用。有一些编程语言是ISO-8859-1编码,所以如果用UTF-8针对这些语言编程序,就必须去掉BOM,即保存成“UTF-8—无BOM”的格式才可以,PHP语言就是这样。

若有收获,就点个赞吧
0 人点赞
