性能监控指标
1. CPU 使用率
大多数操作系统的 CPU 使用率分为 用户态 CPU 使用率 和 系统态 CPU 使用率。用户态 CPU 使用率是指执行应用程序代码的时间占总 CPU 时间的百分比。而系统态 CPU 使用率是指执行操作系统调用的时间占总 CPU 时间的百分比。系统态 CPU 使用率高意味着共享资源有竞争或者 I/O 设备之间有大量的交互。既然原本用于执行操作系统内核调用的 CPU 周期也可以用来执行应用代码,所以理想情况下,应用达到最高性能和扩展性时,它的系统态 CPU 使用率接近 0%。所以提高应用性能和扩展性的一个目标是尽可能降低系统态 CPU 使用率。
对于计算密集型应用来说,我们还需要进一步监控 每时钟指令数(Instructions Per Clock,IPC)或 每指令时钟周期(Cycles Per Instruction,CPI)。因为现代操作系统自带的 CPU 使用率监控工具只报告 CPU 使用率,而没有 CPU 执行指令占 CPU 时钟周期的百分比。这意味着即便 CPU 在等待内存中的数据,操作系统工具仍然会报告 CPU 繁忙。这种情况通常被称为停滞。当 CPU 执行指令而所用的操作数据不在寄存器或缓存中时,就会发生停滞。由于指令执行前必须等待数据从内存装入 CPU 寄存器,所以一旦发生停滞,CPU 通常会等待(浪费)好几百个时钟周期。因此提高计算密集型应用性能的策略就是减少停滞或者改善 CPU 高速缓存使用率,从而减少 CPU 在等待内存数据时浪费的时钟周期。
Linux 提供了 top 和 vmstat 工具来监控 CPU 的使用率,其中,vmstat 显式格式如下:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st0 0 0 2330888 86604 1032468 0 0 0 8 14 8 0 0 100 0 00 0 0 2330748 86604 1032468 0 0 0 0 97 161 0 1 100 0 00 0 0 2330748 86604 1032468 0 0 0 0 123 202 1 0 100 0 0
- us:用户态 CPU 使用率
- sy:系统态 CPU 使用率
- id:空闲率或 CPU 可用率,us+sy=100-id
2. CPU 调度程序运行队列
除 CPU 使用率外,监控 CPU 调度程序运行队列对于分辨系统是否满负荷也有重要意义。运行队列中就是那些已准备好运行、正等待可用 CPU 的轻量级进程。如果准备运行的轻量级进程数超过系统所能处理的上限,运行队列就会很长,也表明系统负载可能已饱和。系统运行队列长度等于虚拟处理器的个数时,用户不会明显感觉到性能下降。此处虚拟处理器的个数是系统硬件线程的个数,也是 Java API Runtime.availableprocessors() 的返回值。当运行队列长度达到虚拟处理的 4 倍或更多时,系统的响应就非常迟缓了。
一般性的指导原则是:如果在很长一段时间里,运行队列的长度一直都超过虚拟处理器个数的 1 倍,我们就需要关注了,只是暂时还不需要立刻采取行动。如果在很长一段时间里,运行队列的长度达到虚拟处理器个数的 3-4 倍或更高,则需要立刻引起注意或采取行动。
解决运行队列长有两种方法。一种是增加 CPU 以分担负载或减少处理器的负载量。这种方法从根本上减少了每个虚拟处理器上的活动线程数,从而减少了运行队列中的轻量级进程数。另一种方法是分析系统中运行的应用,改进 CPU 使用率。换句话说,研究可以减少应用运行所需 CPU 周期的方法,如减少垃圾收集的频度或采用完成同样任务但 CPU 指令更少的算法。
Linux 上可以用 vmstat 命令监控运行队列长度,vmstat 输出的第一列就是运行队列长度,值是运行队列中轻量级进程的实际数量:
3. 内存使用率
除了 CPU 相关的监控外,我们还需要监控系统内存相关的属性,例如页面调度或页面交换、加锁、线程迁移中的让步式和抢占式上下文切换。
系统在进行页面交换或使用虚拟内存时,Java 应用或 JVM 会表现出明显的性能问题。当应用运行所需的内存超过可用物理内存时,就会发生页面交换。为了应对这种可能出现的情况,通常要为系统配置 swap 空间。swap 空间一般会在一个独立的磁盘分区上。当应用耗尽物理内存时,操作系统会将应用的一部分置换到磁盘的 swap 空间上,通常是应用中最少运行的部分,以免影响整个应用或应用最忙的那部分。当访问应用中被置换出去的部分时,就必须将它从磁盘置换进内存,而这种置换活动会对应用的响应性和吞吐量造成很大影响。
此外,JVM 垃圾收集器在系统页面交换时的性能也很差,这是由于垃圾收集器为了回收不可达对象所占用的内存空间,需要访问大量的内存。如果 Java 堆的一部分被置换出去,就必须先置换进内存以便垃圾收集器扫描存活对象,这会增加垃圾收集的持续时间。而垃圾收集又是一种 Stop-The-World 操作,即停止所有正在运行的应用线程,如果此时系统正在进行页面交换,则会引起 JVM 长时间的停顿。
Linux 上可以用 vmstat 输出中的 free 列监控页面交换,也可以用其他方法例如 top 或查看 /proc/meminfo 文件内容来监控。这里介绍用 vmstat 监控页面交换,需要监控 vmstat 中的 si 和 so,它们分别表示内存页面换入和换出的量。此外,free 列显示可用的空闲内存。
4. 监控上下文切换
在 JDK 5 中,HotSpot VM 实现了许多锁优化逻辑。线程通过自旋尝试获得锁,如果若干次自旋后仍然没有成功则挂起该线程,等待被唤醒再次尝试获取该锁。挂起和唤醒线程会导致操作系统的 让步式上下文切换(Voluntary Context Switch),其耗费的时钟周期代价非常高。因此锁竞争严重的应用会有大量的让步式上下文切换。
让步式上下文切换是指执行线程主动释放 CPU,而 抢占式上下文切换 则是指线程因为分配的时间片用尽而被迫放弃 CPU 或者被其他优先级更高的线程所抢占。抢占式上下文切换率高表明准备运行的线程数多于可用的虚拟处理器数量,如果此时用 vmstat 通常会看到很长的运行队列以及很高的 CPU 使用率。
在 Linux 上可以使用 pidstat 命令监控上下文切换,通过 -w 选项显示每个进程的上下文切换情况:
输出结果中的 cswch/s 为每秒钟让步式上下文切换的次数,nvcswch/s 为每秒钟抢占式上下文切换的次数。注意,这里统计的次数为所有虚拟处理器的总次数。
5. 磁盘 I/O 使用率
对于有磁盘操作的应用来说,查找性能问题,就应该监控磁盘 I/O。一些应用的核心功能需要大量使用磁盘,例如数据库,几乎所有的应用都会用日志记录重要的状态信息或事件发生时的应用行为。磁盘 I/O 使用率是理解应用磁盘使用情况最有用的监控数据。
在 Linux 上可以通过 iostat 报告每个磁盘设备的磁盘使用率和 CPU 使用率,如下示例:
其中,%system 表示系统态 CPU 使用率,%util 表示磁盘使用率。其他的 iostat 统计信息对于应用性能监控来说不重要,因为它们无法指示忙或不忙。
如果应用的磁盘 I/O 使用率高,就值得深入分析系统磁盘 I/O 子系统的性能,进一步查看它预期的负载量、磁盘服务时间、寻道时间以及服务 I/O 事件的时间。如果需要改善磁盘使用率,可以使用一些策略。从硬件和操作系统上看,下面是一些改进磁盘 I/O 使用率的策略:
- 更快的存储设备;
- 文件系统扩展到多个磁盘:
- 操作系统调优使得可以缓存大量的文件系统数据结构。
从应用角度看,任何减少磁盘活动的策略都有帮助,例如使用带缓存的输入输出流以减少读写操作次数,或在应用中集成缓存的数据结构以减少或消除磁盘交互。缓冲流减少了调用操作系统调用的次数从而降低系统态 CPU 的使用率。虽然这不会改善磁盘 I/O 性能,但可以使更多 CPU 周期用于应用的其他部分。对此,JDK 提供了缓冲数据结构,如 java.io.BufferedInputStream 和 java.io.BufferedOutputStream。
性能监控工具
1. top
top 命令能够实时显示系统中各个进程的资源占用情况,部分输出如下: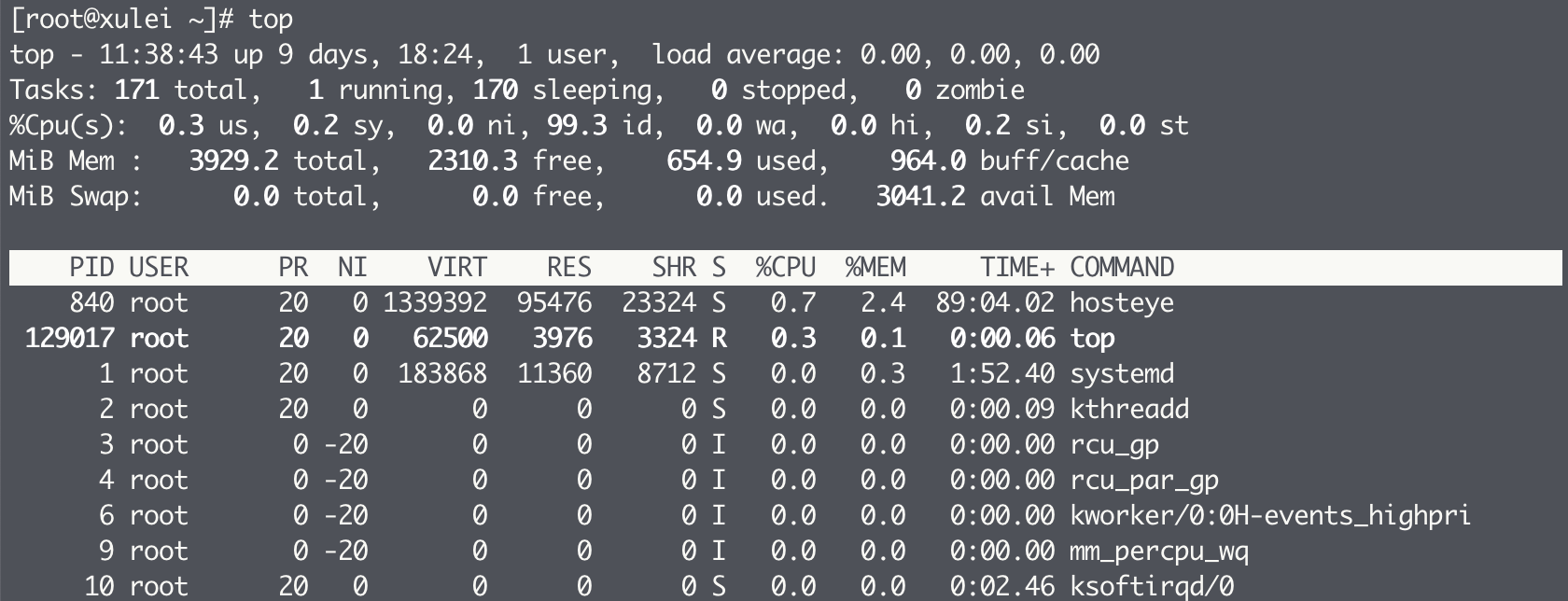
top 命令的输出可以分为两个部分:前半部分是系统的统计信息,后半部分是进程的使用率统计信息。
在统计信息中,第 1 行是任务队列信息,它的结果等同于 uptime 命令。从左到右依次表示:系统当前时间、系统运行时间、当前登录用户数。最后的 load average 表示系统的平均负载,即任务队列的平均长度,这 3 个值分别表示 1 分钟、5 分钟、15 分钟到现在的平均值。
第 2 行是进程统计信息,分别有总任务数、正在运行的进程数、睡眠进程数、停止的进程数、僵尸进程数。
第 3 行是 CPU 统计信息,分别为:
- us 表示用户空间 CPU 占用率
- sy 表示内核空间 CPU 占用率
- ni 表示用户进程空间改变过优先级的进程 CPU 的占用率
- id 表示空闲 CPU 占用率
- wa 表示等待输入输出的 CPU 时间百分比
- hi 表示硬件中断请求
- si 表示软件中断请求
在 Mem 行中,total 表示物理内存总量、free 表示空闲物理内存、used 表示已使用的物理内存、buff/cache 表示操作系统内核缓冲使用量。
top 命令的第 2 部分是进程信息区,显示了系统内各个进程的资源使用情况。主要字段的含义如下:
- PID:进程 id。
- USER:进程所有者的用户名。
- PR:优先级。
- NI:nice 值,负值表示高优先级,正值表示低优先级。
- VIRT:进程使用的虚拟内存总量,单位 kb,VIRT=SWAP+RES(物理内存)。
- RES:进程使用的、未被换出的物理内存大小,单位 kb,RES=CODE+DATA。
- SHR:共享内存大小,单位 kb。
- %CPU:从上次更新到现在的 CPU 时间占用百分比。
- %MEM:进程使用的物理内存百分比。
- TIME+:进程使用的 CPU 时间总计,单位 1/100秒。
- COMMAND:命令名/命令行。
如何找到最耗 CPU 的 Java 线程?
- 使用 top 命令,查找使用 CPU 最多的某个进程,记录它的 pid。
再次使用 top 命令,加 -Hp 参数,查看某个进程中使用 CPU 最多的某个线程,记录线程的 ID。
top -Hp $pid
使用 printf 函数,将十进制的 PID 转化成十六进制。
printf "%x" $PID
最后使用 jstack 命令获取线程栈,对比线程的 native id(nid)即可。
jstack $pid | grep $PID
2. vmstat
vmstat 是一款指定采样周期和次数的功能性监测工具,它可以统计 CPU、内存、swap 的使用情况。

指标含义如下:
- r:等待运行的进程数;
- b:处于非中断睡眠状态的进程数;
- swpd:虚拟内存使用情况,单位 kb;
- free:空闲的内存,单位 kb;
- buff:用来作为内核缓冲的内存,单位 kb;
- si:从磁盘交换到内存的交换页数量,单位 kb/秒;
- so:从内存交换到磁盘的交换页数量,单位 kb/秒;
- bi:发送到块设备的块数,单位 块/秒;
- bo:从块设备接收到的块数,单位 块/秒;
- in:每秒中断数,包括时钟中断;
- cs:每秒上下文切换次数;
- us:用户态 CPU 使用率;
- sy:系统态 CPU 使用率;
- id:空闲率或 CPU 可用率,us+sy=100-id;
- wa:等待 I/O 时间的百分比;
- st:运行虚拟机窃取的时间。
如果每秒上下文(cs,context switch)切换很高,并且比系统中断高很多(in,system interrupt),就表明很有可能是因为不合理的多线程调度所导致。
3. iostat
iostat 可以提供详细的 I/O 信息,它的基本使用如下: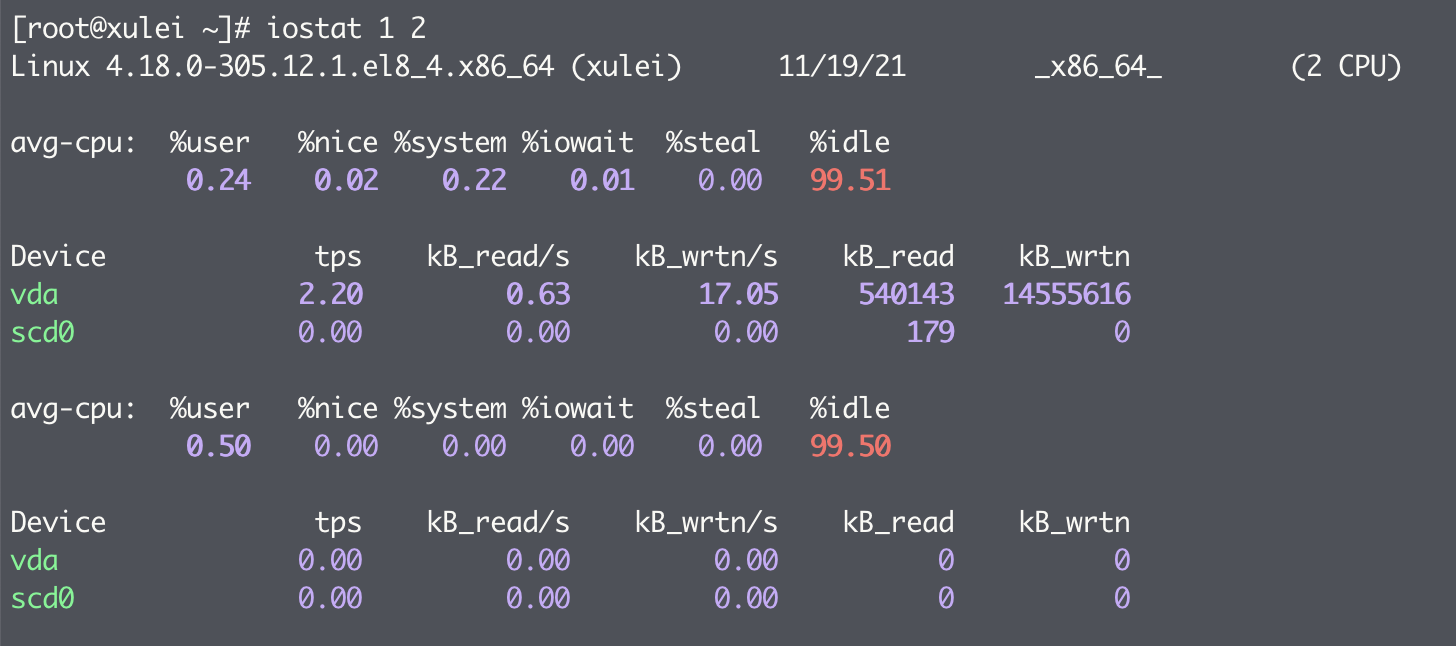
以上命令显示了 CPU 的使用概况和磁盘 I/O 的信息。输出信息每 1 秒采样一次,共采样 2 次。如果只需要显示磁盘信息,不需要显示 CPU 使用情况,则可以使用命令: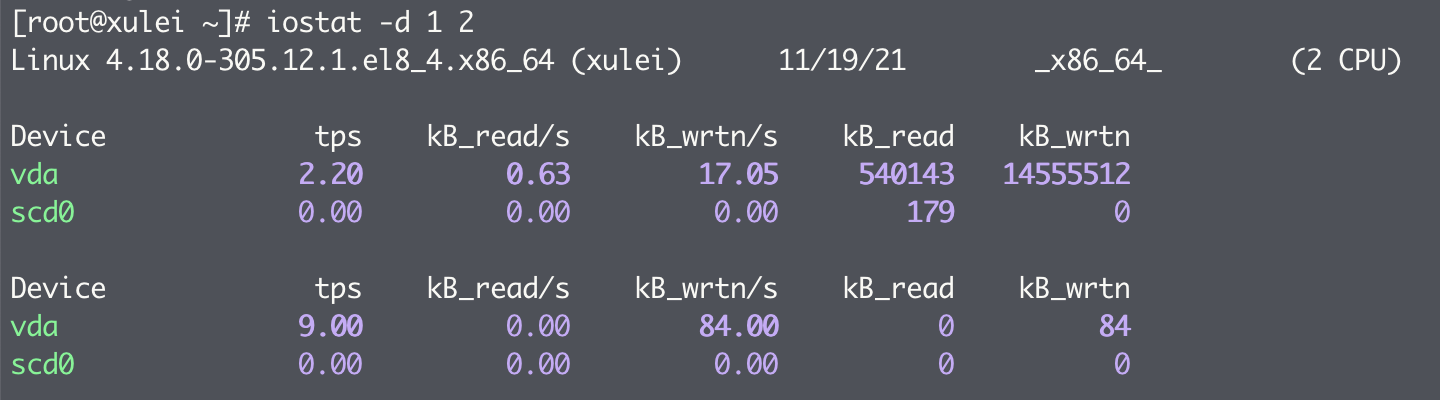
输出结果中各个列的含义如下:
- tps:该设备每秒的传输次数
- kB_read/s:每秒从设备读取的数据量
- kB_wrtn/s:每秒向设备写入的数据量
- kB_read:读取的总数据量
- kB_wrtn:写入的总数据量
4. pidstat
pidstat 是 Sysstat 中的一个组件,也是一款功能强大的性能监测工具,可通过 yum install sysstat 命令安装该监控组件。之前的 top 和 vmstat 两个命令都是监测进程的内存、CPU 以及 I/O 使用情况,而 pidstat 不仅可以监视进程的性能情况,也可以监视线程的性能情况。
通过 pidstat -help 命令,我们可以查看到有以下几个常用的参数来监测线程的性能:
常用参数的含义如下:
- -u:默认的参数,显示各个进程的 cpu 使用情况;
- -r:显示各个进程的内存使用情况;
- -d:显示各个进程的 I/O 使用情况;
- -w:显示每个进程的上下文切换情况;
- -p:指定进程号;
- -t:显示进程中线程的统计信息。
CPU 使用率监控:
先通过相关命令(例如 ps 或 jps)查询到相关进程 ID,再运行以下命令来监测该进程的 CPU 使用情况: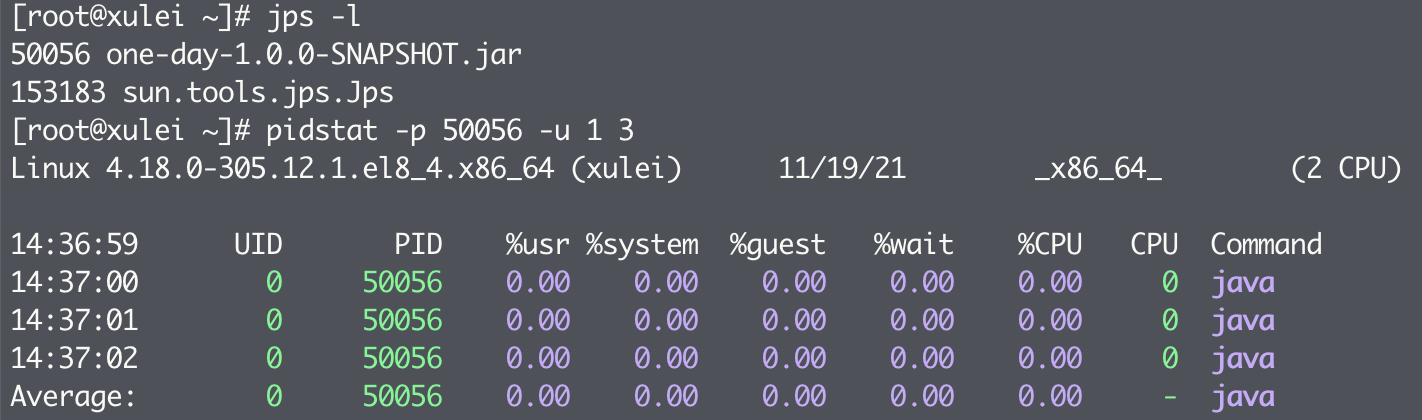
其中 pidstat 的参数 -p 用于指定进程 ID,-u 表示监控 CPU 的使用情况,1 表示每隔一秒进行一次采样,3 则表示采样总次数。输出指标含义如下:
- PID:进程 ID
- %usr:进程在用户空间占用 cpu 的百分比
- %system:进程在内核空间占用 cpu 的百分比
- %guest:进程在虚拟机占用 cpu 的百分比
- %wait:进程在等待输入输出上占用 CPU 的百分比
- %CPU:进程占用 cpu 的百分比
- CPU:处理进程的 cpu 编号
- Command:当前进程对应的命令
pidstat 的功能不仅仅限于观察进程信息,它可以进一步监控线程的信息,其中 TID 即为线程 ID: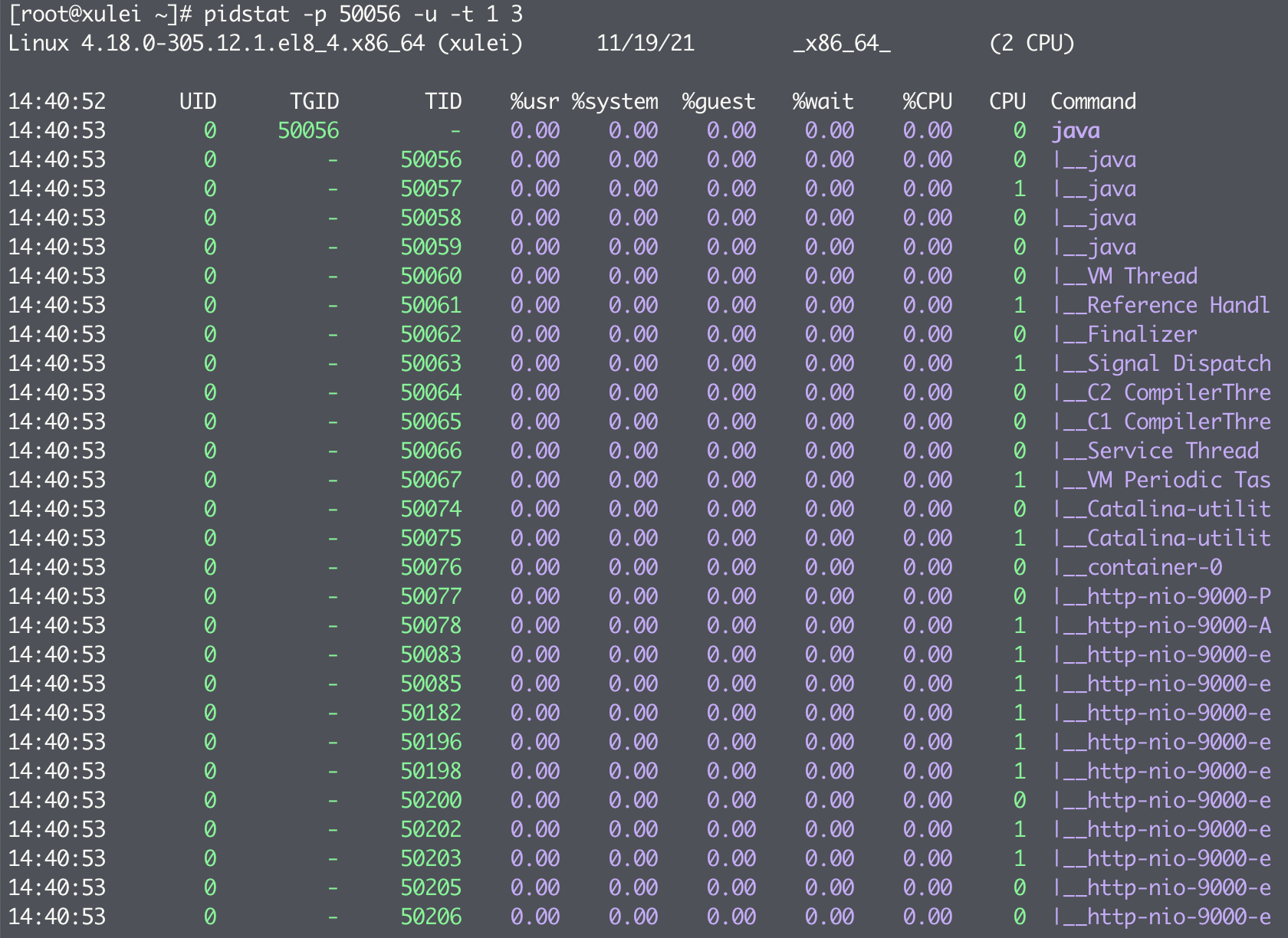
I/O 使用监控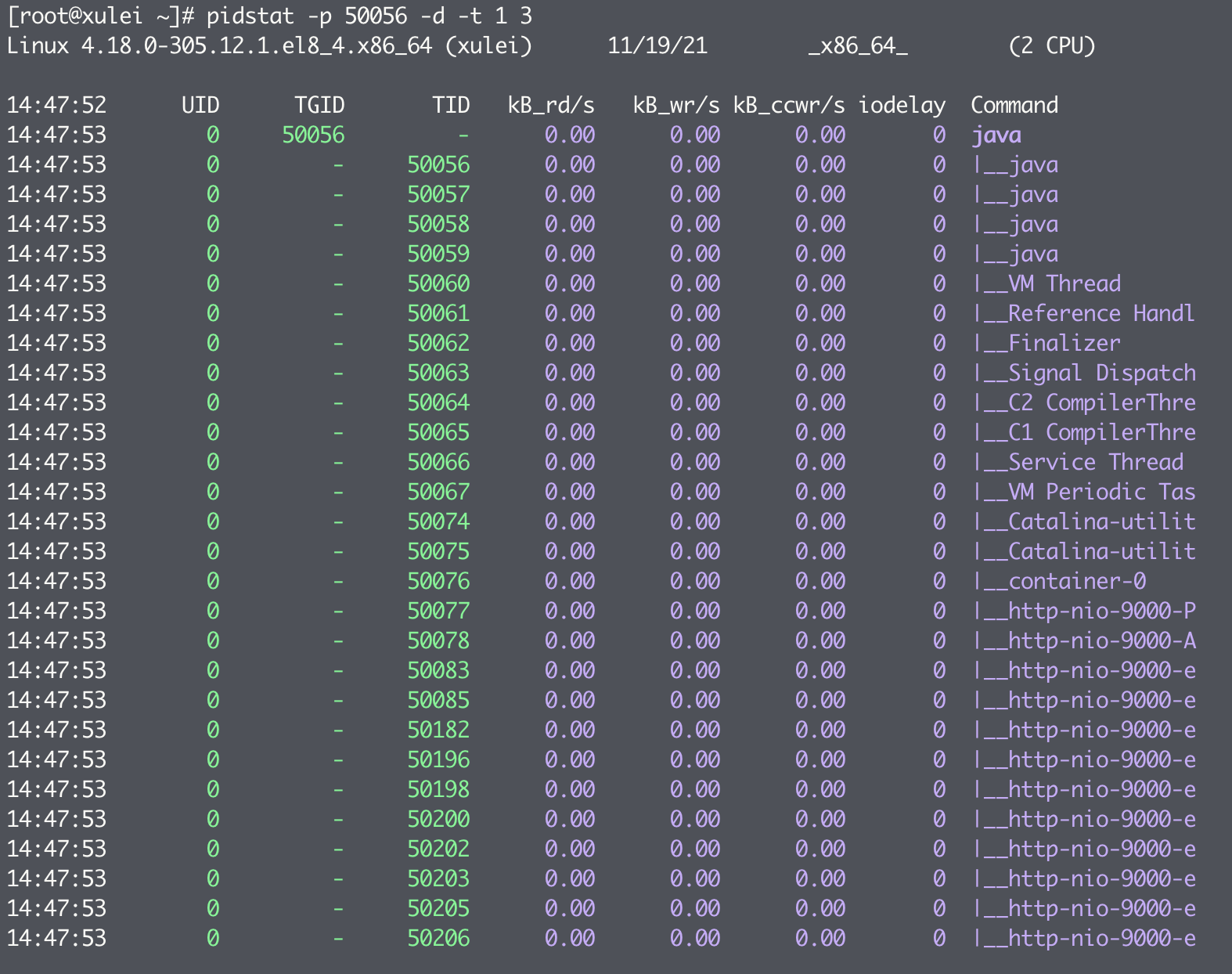
- kB_rd/s:每秒从磁盘读取的 KB 数
- kB_wr/s:每秒写入磁盘的 KB 数
- kB_ccwr/s:任务取消写入磁盘的 KB 数。当任务截断脏的 PageCache 时会发生
内存监控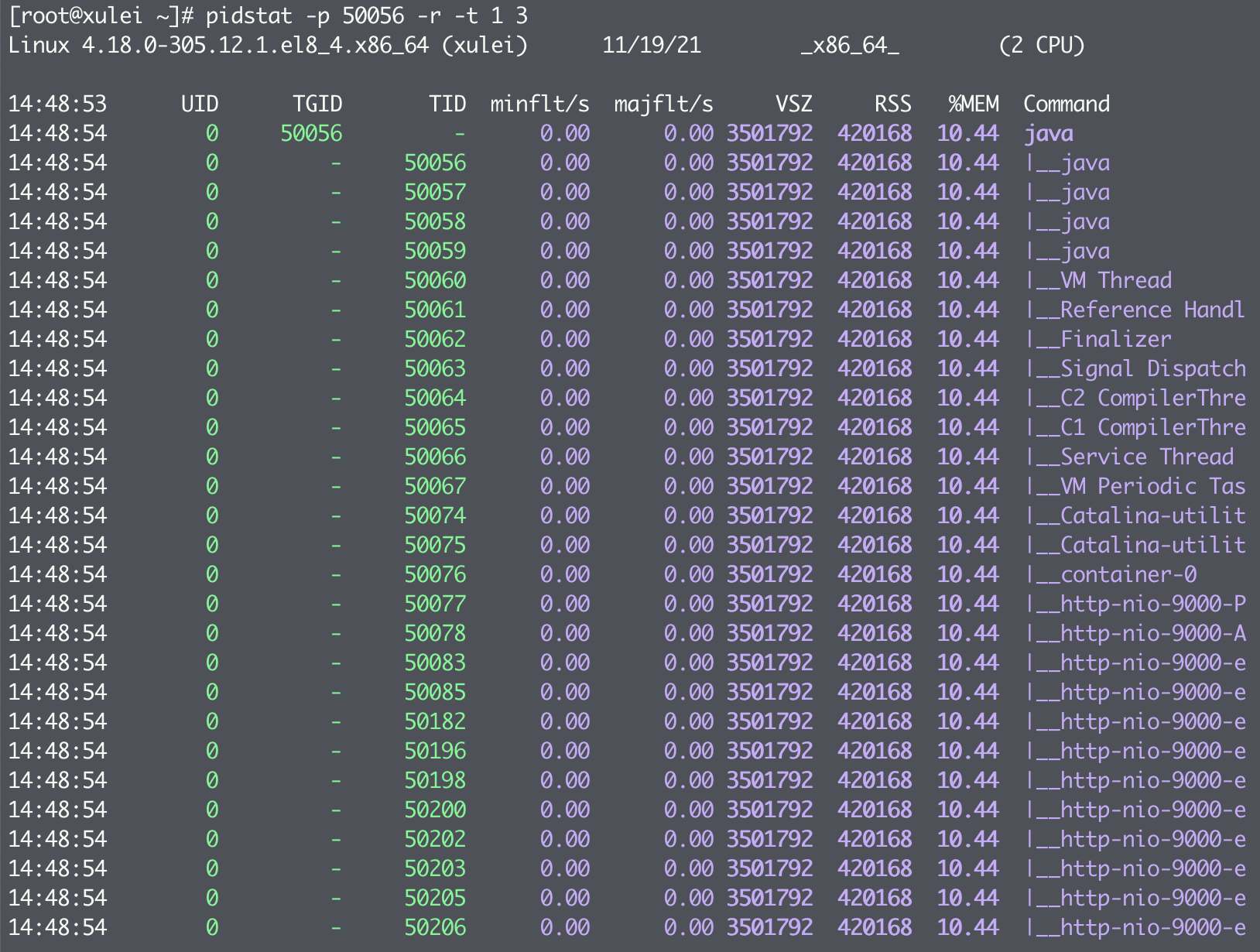
- minflt/s:每秒发生 minor faults(次要错误,不需要从磁盘中加载页)的总数;
- majflt/s:每秒发生 major faults(主要错误,需要从磁盘中加载页)的总数;
- VSZ:使用的虚拟内存大小,单位为 KB;
- RSS:使用的物理内存大小,单位为 KB。
- %MEM:占用内存比率

若有收获,就点个赞吧
0 人点赞
