注解(Annotation)是 Java 5 开始引入的新特征,它提供了一种安全的类似注释的机制,因为注释会被编译器忽略,注解则可以被编译器打包进入 class 文件。注解可以用来将任何的信息或元数据与程序元素(类、方法、成员变量等)进行关联,并且注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。
从 JVM 的角度看,注解本身对代码逻辑没有任何影响,如何使用注解完全由工具决定。Java 提供了几个元注解用来帮助我们构建自定义注解,每个注解都必须通过一个注解接口进行定义。这些接口中的方法与元注解中的元素相对:
元注解
元注解:对注解进行注解,也就是对注解进行标记,主要是对注解的行为做出一些限制,例如生命周期,作用范围等等。JDK 标准库提供了几种元注解,专门用于注解其他的注解,具体如下:
| @Target | 表示注解可以用于哪些地方。可能的 ElementType 参数包括: - CONSTRUCTOR:构造器的声明 - FIELD:字段声明(包括 enum 实例) - LOCAL_VARIABLE:局部变量声明 - METHOD:方法声明 - PACKAGE:包声明 - PARAMETER:参数声明 - TYPE:类、接口(包括注解类型)或者 enum 声明 |
|---|---|
| @Retention | 表示注解信息保存的时长。可选的 RetentionPolicy 参数包括: - SOURCE:编译器使用的注解,这类注解不会被编译进 class 文件,只在编译期会用到 - CLASS:注解在 class 文件中可用,但加载结束后并不会存在于内存中 - RUNTIME:VM 将在运行期保留注解,可通过反射机制读取注解的信息 |
| @Documented | 一个简单的 Annotations 标记注解,表示是否将注解信息添加在 Javadoc 中 |
| @Inherited | 允许子类继承父类的注解 |
| @Repeatable | 允许一个注解可以在同一个地方被使用多次(Java8) |
1. @Retention
@Documented@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.ANNOTATION_TYPE)public @interface Retention {RetentionPolicy value();}
RetentionPolicy.SOURCE:由编译器使用的注解,这类注解只在源码阶段保留,在编译器进行编译时这类注解会被丢弃。这些注解在编译结束后就不再有任何意义,所以它们不会写入字节码。例如 @Override 让编译器检查该方法是否正确地实现了覆写;@SuppressWarnings 告诉编译器忽略此处代码产生的警告。
RetentionPolicy.CLASS:由工具处理 class 文件使用的注解,这类注解在编译期保留,会被编译进 class 文件,但在类加载的时候被丢弃,不会存在于内存中。这是 @Retention 的默认值,比如有些工具会在类加载时对 class 进行动态修改,实现一些特殊功能。例如 @NotNull 就属于这样的注解。
RetentionPolicy.RUNTIME:在程序运行期能够读取的注解,它们在加载后一直存在于 JVM 内存中,这是最常用的注解。在程序中可以使用反射机制读取该注解的信息。自定义的注解通常使用这种方式,Spring 中 @Controller、@Service 等都属于这一类。
2. @Target
@Documented@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.ANNOTATION_TYPE)public @interface Target {/*** Returns an array of the kinds of elements an annotation type can be applied to.*/ElementType[] value();}
| 类型 | 作用的对象类型 | | —- | —- | | TYPE | 类、接口、枚举 | | FIELD | 字段声明(包括枚举常量) | | METHOD | 方法 | | PARAMETER | 方法或构造器的参数 | | CONSTRUCTOR | 构造方法 | | LOCAL_VARIABLE | 局部变量 | | ANNOTATION_TYPE | 注解类型声明 | | PACKAGE | 包 | | TYPE_PARAMETER | 1.8 之后,泛型 | | TYPE_USE | 1.8 之后,除了 PACKAGE 之外任意类型 |
3. @Repeatable
对于 Java 8 来说,将同种类型的注解多次应用于某一项是合法的。但为了向后兼容,可重复注解的实现者需要提供一个容器注解,它可以将这些重复注解存储到一个数组中。下面通过使用 @Repeatable 这个元注解来定义 Annotation 重复应用的场景:
@Repeatable(Reports.class)@Target(ElementType.TYPE)@Retention(RetentionPolicy.RUNTIME)public @interface Report {int type() default 0;String level() default "info";String value() default "";}// 容器注解@Target(ElementType.TYPE)@Retention(RetentionPolicy.RUNTIME)public @interface Reports {Report[] value();}
经过 @Repeatable 修饰后,在某个类型声明处,就可以添加多个 @Report 注解了:
@Report(type=1, level="debug")@Report(type=2, level="warning")public class Hello {}
在处理可重复注解时必须非常仔细。如果调用 getAnnotation 来查找某个可重复注解,而该注解又确实重复了,那么就会得到 null。这是因为重复注解被包装到了容器注解中。在这种情况下,我们应该调用 getAnnotationsByType 方法。该方法会遍历容器并给出一个重复注解的数组。如果只有一条注解,那么该数组的长度就为 1。
4. @Inherited
使用 @Inherited 定义子类是否可继承父类定义的 Annotation。在使用时注意:@Inherited 仅针对 @Target(ElementType.TYPE) 类型的 annotation 有效,并且仅针对 class 的继承,对 interface 的继承无效
@Inherited@Target(ElementType.TYPE)public @interface Report {int type() default 0;String level() default "info";String value() default "";}
在使用的时候,如果一个类用到了这个 @Report,则它的子类默认也定义了该注解:
@Report(type=1)public class Person {}public class Student extends Person {}
注解的使用
按照注解的生命周期以及处理方式的不同,通常将注解分为「运行时注解」和「编译时注解」。
1. 运行时注解
运行时注解的本质是实现了 Annotation 接口的特殊接口,JDK 在运行时为其创建代理类,注解方法的调用实际是通过 AnnotationInvocationHandler 的 invoke 方法来实现的,在 AnnotationInvocationHandler 内部维护了一个 Map, Map 中存放的是方法名与返回值的映射,对注解中自定义方法的调用其实最后就是用方法名去查 Map 并且放回的一个过程。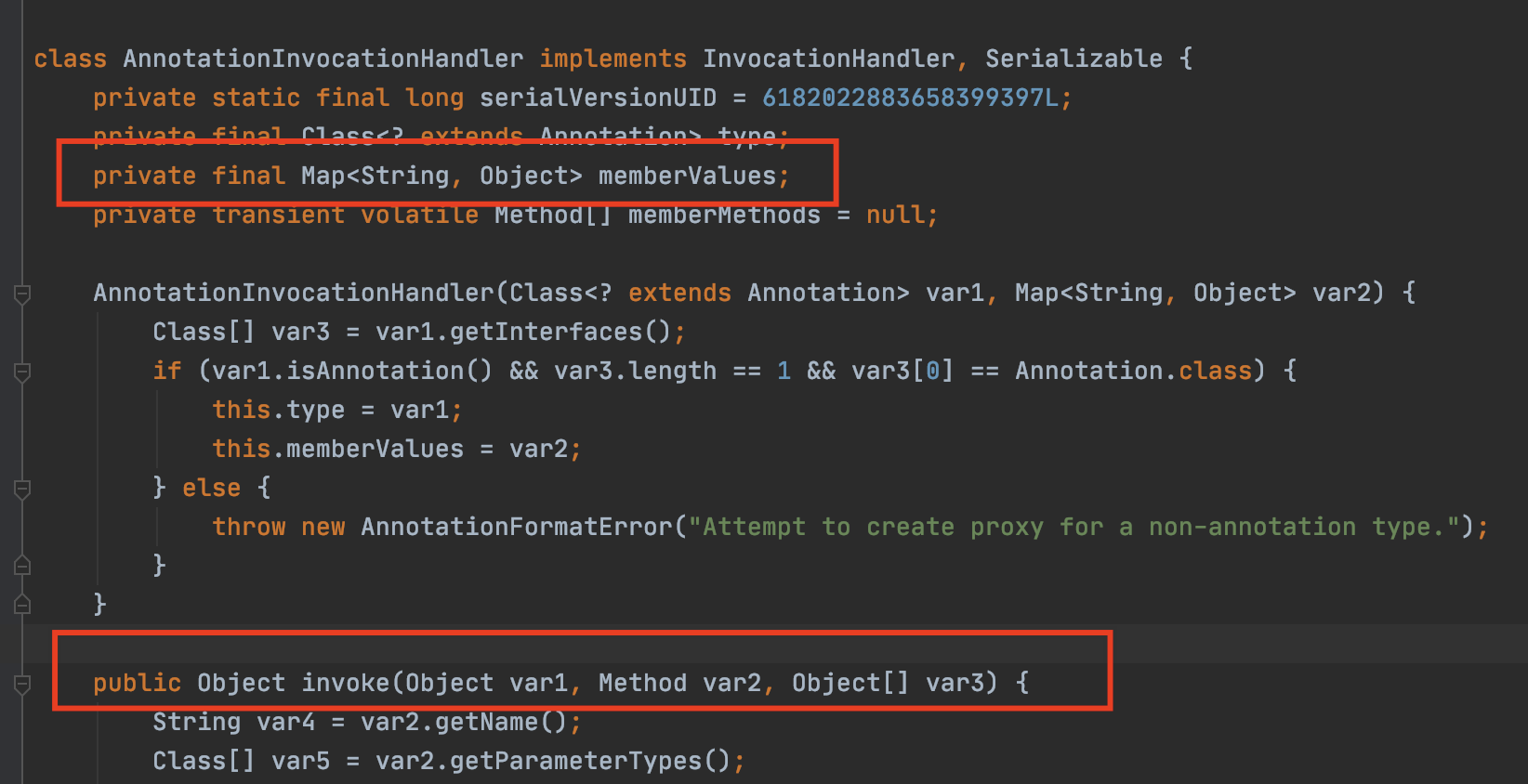
运行时注解的产生作用的步骤如下:
对 annotation 的反射调用使得动态代理创建实现该注解的一个类
代理背后真正的处理对象为 AnnotationInvocationHandler,这个类内部维护了一个 map,这个 map 的键值对形式为 <注解中定义的方法名,对应的属性名>
任何对 annotation 的自定义方法的调用,最终都会实际调用 AnnotatiInvocationHandler 的 invoke 方法,并且该 invoke 方法对于这类方法的处理很简单,拿到传递进来的方法名,然后去查 map
map 中 memeberValues 的初始化是在 AnnotationParser 中完成的,在方法调用前就会初始化好,之后缓存在 map 里面。
由于运行时注解在类加载后也是一种 class,并且所有的注解都继承自 java.lang.annotation.Annotation 接口,所以读取运行时注解可以使用反射 API。并且 Method、Constructor、Field、Class 和 Package 这些反射类都实现了 AnnotatedElement 接口,定义了通用的方法:
// 如果该项具有给定类型的注解,则返回truedefault boolean isAnnotationPresent(Class<? extends Annotation> annotationClass)// 获得给定类型的注解,如果该项不具有这样的注解,则返回null<T extends Annotation> T getAnnotation(Class<T> annotationClass);// 获得某个可重复注解类型的所有注解,或者返回长度为0的数组default <T extends Annotation> T[] getAnnotationsByType(Class<T> annotationClass)// 获得作用于该项的所有注解,包括继承来的注解。如果没有任何注解,则返回一个长度为0的数组Annotation[] getAnnotations();// 使用同上,区别是不包括继承来的注解default <T extends Annotation> T getDeclaredAnnotation(Class<T> annotationClass)default <T extends Annotation> T[] getDeclaredAnnotationsByType(Class<T> annotationClass)Annotation[] getDeclaredAnnotations()
除了上面这些通用的获取注解信息的方法外,各个类还有自己独有的获取注解信息的方法。比如想要获取方法参数上的 Annotation 就比较麻烦,因为方法参数本身可以看成一个数组,而每个参数又可以定义多个注解,所以一次获取方法参数的所有注解就必须用一个二维数组来表示。例如,对于以下方法定义的注解:
public void hello(@NotNull @Range(max=5) String name, @NotNull String prefix) {}
要读取方法参数的注解,我们先用反射获取 Method 实例,然后读取方法参数的所有注解:
// 获取Method实例:Method m = ...// 获取所有参数的Annotation:Annotation[][] annos = m.getParameterAnnotations();// 第一个参数(索引为0)的所有Annotation:Annotation[] annosOfName = annos[0];for (Annotation anno : annosOfName) {if (anno instanceof Range) { // @Range注解Range r = (Range) anno;}if (anno instanceof NotNull) { // @NotNull注解NotNull n = (NotNull) anno;}}
2. 编译时注解
我们知道,Java 的注解机制允许开发人员自定义注解。这些自定义注解同样可以为 Java 编译器添加自定义的编译规则。编译时注解通过注解处理器(annotation processor)来支持,注解处理器的实际工作过程是由 JDK 在编译期提供支持的。Java 编译器会定位源文件中的注解。每个注解处理器会依次执行,并得到它表示感兴趣的注解。如果某个注解处理器创建了一个新的源文件,那么上述过程将重复执行。如果某次处理循环没有再产生任何新的源文件,那么就编译所有的源文件。
除了引入新的编译规则外,注解处理器还可以用于修改已有的 Java 源文件(修改源文件生成的字节码)或者生成新的 Java 源文件。下面我将用几个案例来详细阐述注解处理器的这些功能,以及它背后的原理。
2.1 注解处理器使用
首先定义一个编译时注解 @CheckGetter,通过将 RetentionPolicy 的值设为 SOURCE 把该注解的生命周期限定在编译期。
@Target({ ElementType.TYPE, ElementType.FIELD })@Retention(RetentionPolicy.SOURCE)public @interface CheckGetter {}
下面我们来实现一个处理 @CheckGetter 注解的注解处理器。它将遍历被标注的类中的实例字段,并检查有没有相应的 getter 方法。
所有的注解处理器类都需要实现 Processor 接口,在 Java 编译器中,注解处理器的实例是通过反射 API 生成的。也正因为使用反射 API,每个注解处理器类都需要定义一个无参数构造器。不过在编写注解处理器时,通常我们不需要声明任何构造器,依赖 Java 编译器为之插入一个无参构造器。而具体的注解处理器的初始化代码则放入 init 方法之中。
package javax.annotation.processing;public interface Processor {void init(ProcessingEnvironment processingEnv);Set<String> getSupportedAnnotationTypes();SourceVersion getSupportedSourceVersion();boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv);...}
在剩下的三个方法中:getSupportedAnnotationTypes 方法将返回注解处理器所支持的注解类型,这些注解类型只需用字符串形式表示即可。getSupportedSourceVersion 方法将返回该处理器所支持的 Java 版本,通常这个版本要与 Java 编译器版本保持一致,而 process 方法则是最关键的注解处理方法。
此外,JDK 还提供了一个实现 Processor 接口的抽象类 AbstractProcessor。该抽象类已经实现了 init、getSupportedAnnotationTypes 和 getSupportedSourceVersion 方法。它的子类可以通过 @SupportedAnnotationTypes 和 @SupportedSourceVersion 注解来声明所支持的注解类型及 Java 版本。
下面这段代码便是 @CheckGetter 注解处理器的实现:
import javax.annotation.processing.AbstractProcessor;import javax.annotation.processing.RoundEnvironment;import javax.annotation.processing.SupportedAnnotationTypes;import javax.annotation.processing.SupportedSourceVersion;import javax.lang.model.SourceVersion;import javax.lang.model.element.ExecutableElement;import javax.lang.model.element.Modifier;import javax.lang.model.element.TypeElement;import javax.lang.model.element.VariableElement;import javax.lang.model.util.ElementFilter;import javax.tools.Diagnostic;import java.util.Set;@SupportedAnnotationTypes("CheckGetter")@SupportedSourceVersion(SourceVersion.RELEASE_8)public class CheckGetterProcessor extends AbstractProcessor {@Overridepublic boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {for (TypeElement annotatedClass : ElementFilter.typesIn(roundEnv.getElementsAnnotatedWith(CheckGetter.class))) {for (VariableElement field : ElementFilter.fieldsIn(annotatedClass.getEnclosedElements())) {if (!containsGetter(annotatedClass, field.getSimpleName().toString())) {processingEnv.getMessager().printMessage(Diagnostic.Kind.ERROR,String.format("getter not found for '%s.%s'.", annotatedClass.getSimpleName(), field.getSimpleName()));}}} return true;}private static boolean containsGetter(TypeElement typeElement, String name) {String getter = "get" + name.substring(0, 1).toUpperCase() + name.substring(1).toLowerCase();for (ExecutableElement executableElement : ElementFilter.methodsIn(typeElement.getEnclosedElements())) {if (!executableElement.getModifiers().contains(Modifier.STATIC)&& executableElement.getSimpleName().toString().equals(getter)&& executableElement.getParameters().isEmpty()) {return true;}}return false;}}
该注解处理器仅重写了 process 方法。process 方法接收两个参数,分别代表该注解处理器所能处理的注解类型以及囊括当前轮生成的抽象语法树的 RoundEnvironment。
RoundEnvironment 是编译器产生的一棵语法树,其节点是实现了 javax.lang.model.element.Element 接口及其 TypeElement、VariableElement、ExecutableElement 等子接口的类的实例。这些节点可以类比于编译时的 Class、Field/Parament 和 Method/Constructor 反射类,具体示例如下:
package foo; // PackageElementclass Foo { // TypeElementint a; // VariableElementstatic int b; // VariableElementFoo () {} // ExecutableElementvoid setA ( // ExecutableElementint newA // VariableElement){}}
这些 Element 之间也有从属关系,比如上面这段代码,我们可以通过 TypeElement.getEnclosedElements 方法获得上面这段代码中 Foo 类的字段、构造器以及方法。我们也可以通过 ExecutableElement.getParameters 方法获得 setA 方法的参数。具体这些 Element 类都有哪些 API 可以参考它们的 Javadoc 文档。
2.2 注解处理器注册
在将该注解处理器编译成 class 文件后,我们便可以将其注册为 Java 编译器的插件,并用来处理其他源代码。注册的方法主要有两种。第一种是直接使用 javac 命令的 -processor 参数,如下图所示: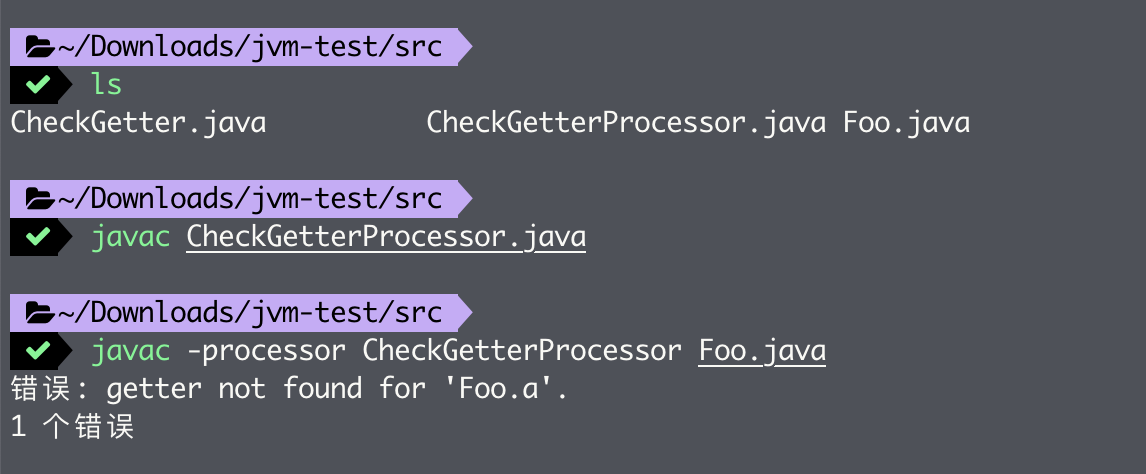
第二种则是将注解处理器编译生成的 class 文件压缩入 jar 包中,并在 jar 包的指定路径及配置文件中记录该注解处理器的包名及类名(类比 SPI 机制)。具体路径及配置文件名为:
META—INF/services/javax.annotation.processing.Processor
我们非常熟悉的 Lombok 就是使用了这种注册方式: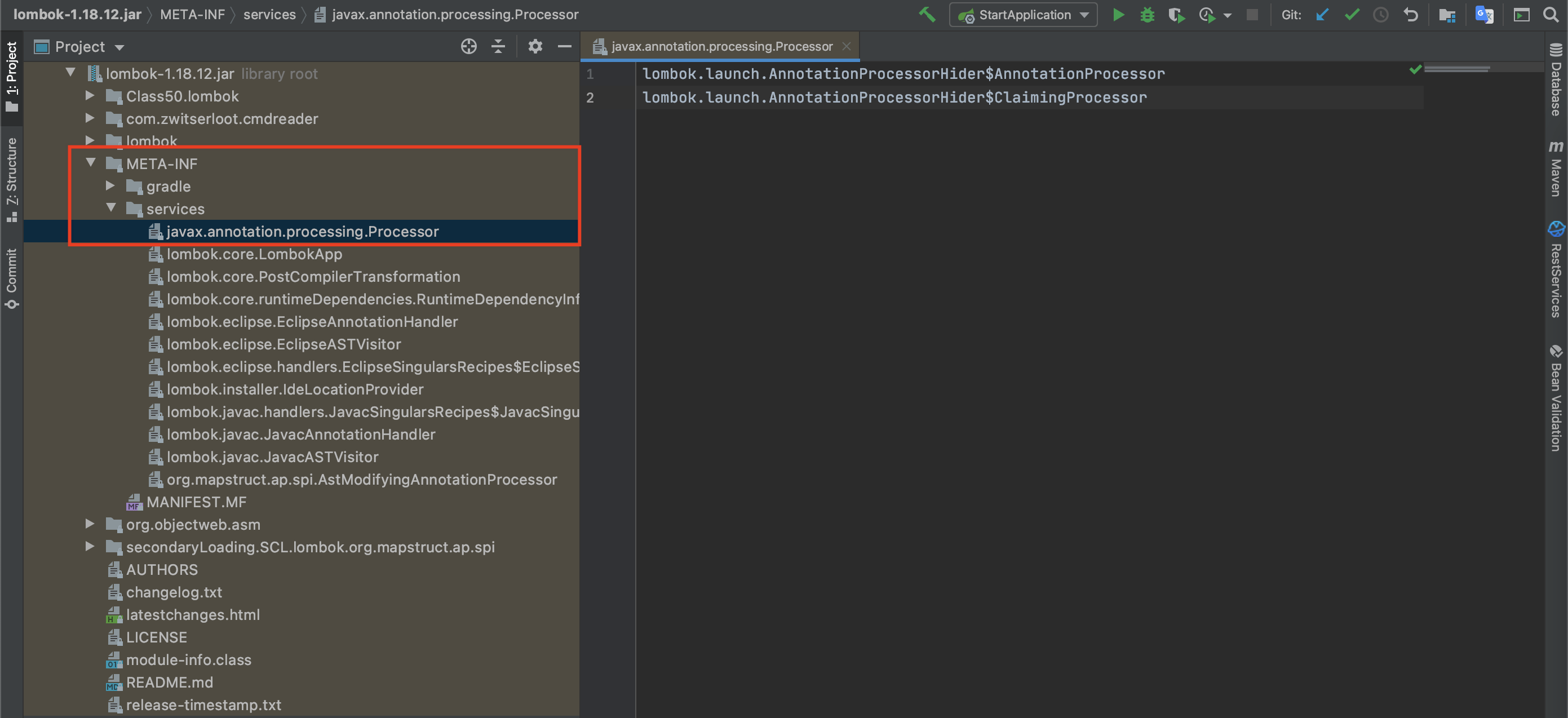
当启动 Java 编译器时,它会寻找 classpath 路径上的 jar 包是否包含上述配置文件,并自动注册其中记录的注解处理器。
2.3 利用注解处理器生成源代码
前面提到,注解处理器可以用来修改已有源代码或生成源代码。确切地说,注解处理器并不能真正地修改已有源代码。这里指的是修改由 Java 源代码生成的抽象语法树,在其中修改已有树节点或者插入新的树节点,从而使生成的字节码发生变化。
但是对抽象语法树的修改涉及了 Java 编译器的内部 API,这部分很可能随着版本变更而失效。因此并不推荐通过注解处理器修改源代码,用注解处理器来生成源代码则比较常用。
package foo;import java.lang.annotation.*;@Target(ElementType.METHOD)@Retention(RetentionPolicy.SOURCE)public @interface Adapt {Class<?> value();}
在上面代码中,定义了一个注解 @Adapt。这个注解将接收一个 Class 类型的参数 value,用法如下:
package test;import java.util.function.IntBinaryOperator;import foo.Adapt;public class Bar {@Adapt(IntBinaryOperator.class)public static int add(int a, int b) {return a + b;}}
下面我们来实现一个处理 @Adapt 注解的处理器。该处理器将生成一个新的源文件,实现参数 value 所指定的接口,并且调用至被该注解所标注的方法之中。
package bar;import java.io.IOException;import java.io.PrintWriter;import java.util.Set;import javax.annotation.processing.AbstractProcessor;import javax.annotation.processing.Filer;import javax.annotation.processing.RoundEnvironment;import javax.annotation.processing.SupportedAnnotationTypes;import javax.annotation.processing.SupportedSourceVersion;import javax.lang.model.SourceVersion;import javax.lang.model.element.AnnotationMirror;import javax.lang.model.element.AnnotationValue;import javax.lang.model.element.Element;import javax.lang.model.element.ElementKind;import javax.lang.model.element.ExecutableElement;import javax.lang.model.element.Modifier;import javax.lang.model.element.PackageElement;import javax.lang.model.element.TypeElement;import javax.lang.model.element.VariableElement;import javax.lang.model.type.TypeMirror;import javax.lang.model.util.ElementFilter;import javax.tools.JavaFileObject;import javax.tools.Diagnostic.Kind;@SupportedAnnotationTypes("foo.Adapt")@SupportedSourceVersion(SourceVersion.RELEASE_8)public class AdaptProcessor extends AbstractProcessor {@Overridepublic boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {for (TypeElement annotation : annotations) {if (!"foo.Adapt".equals(annotation.getQualifiedName().toString())) {continue;}ExecutableElement targetAsKey = getExecutable(annotation, "value");for (ExecutableElement annotatedMethod : ElementFilter.methodsIn(roundEnv.getElementsAnnotatedWith(annotation))) {if (!annotatedMethod.getModifiers().contains(Modifier.PUBLIC)) {processingEnv.getMessager().printMessage(Kind.ERROR, "@Adapt on non-public method");continue;}if (!annotatedMethod.getModifiers().contains(Modifier.STATIC)) {processingEnv.getMessager().printMessage(Kind.ERROR, "@Adapt on non-static method");continue;}TypeElement targetInterface = getAnnotationValueAsTypeElement(annotatedMethod, annotation, targetAsKey);if (targetInterface.getKind() != ElementKind.INTERFACE) {processingEnv.getMessager().printMessage(Kind.ERROR, "@Adapt with non-interface input");continue;}TypeElement enclosingType = getTopLevelEnclosingType(annotatedMethod);createAdapter(enclosingType, annotatedMethod, targetInterface);}}return true;}private void createAdapter(TypeElement enclosingClass, ExecutableElement annotatedMethod,TypeElement targetInterface) {PackageElement packageElement = (PackageElement) enclosingClass.getEnclosingElement();String packageName = packageElement.getQualifiedName().toString();String className = enclosingClass.getSimpleName().toString();String methodName = annotatedMethod.getSimpleName().toString();String adapterName = className + "_" + methodName + "Adapter";ExecutableElement overriddenMethod = getFirstNonDefaultExecutable(targetInterface);try {Filer filer = processingEnv.getFiler();JavaFileObject sourceFile = filer.createSourceFile(packageName + "." + adapterName, new Element[0]);try (PrintWriter out = new PrintWriter(sourceFile.openWriter())) {out.println("package " + packageName + ";");out.println("import " + targetInterface.getQualifiedName() + ";");out.println();out.println("public class " + adapterName + " implements " + targetInterface.getSimpleName() + " {");out.println(" @Override");out.println(" public " + overriddenMethod.getReturnType() + " " + overriddenMethod.getSimpleName()+ formatParameter(overriddenMethod, true) + " {");out.println(" return " + className + "." + methodName + formatParameter(overriddenMethod, false) + ";");out.println(" }");out.println("}");}} catch (IOException e) {throw new RuntimeException(e);}}private ExecutableElement getExecutable(TypeElement annotation, String methodName) {for (ExecutableElement method : ElementFilter.methodsIn(annotation.getEnclosedElements())) {if (methodName.equals(method.getSimpleName().toString())) {return method;}}processingEnv.getMessager().printMessage(Kind.ERROR, "Incompatible @Adapt.");return null;}private ExecutableElement getFirstNonDefaultExecutable(TypeElement annotation) {for (ExecutableElement method : ElementFilter.methodsIn(annotation.getEnclosedElements())) {if (!method.isDefault()) {return method;}}processingEnv.getMessager().printMessage(Kind.ERROR,"Target interface should declare at least one non-default method.");return null;}private TypeElement getAnnotationValueAsTypeElement(ExecutableElement annotatedMethod, TypeElement annotation,ExecutableElement annotationFunction) {TypeMirror annotationType = annotation.asType();for (AnnotationMirror annotationMirror : annotatedMethod.getAnnotationMirrors()) {if (processingEnv.getTypeUtils().isSameType(annotationMirror.getAnnotationType(), annotationType)) {AnnotationValue value = annotationMirror.getElementValues().get(annotationFunction);if (value == null) {processingEnv.getMessager().printMessage(Kind.ERROR, "Unknown @Adapt target");continue;}TypeMirror targetInterfaceTypeMirror = (TypeMirror) value.getValue();return (TypeElement) processingEnv.getTypeUtils().asElement(targetInterfaceTypeMirror);}}processingEnv.getMessager().printMessage(Kind.ERROR, "@Adapt should contain target()");return null;}private TypeElement getTopLevelEnclosingType(ExecutableElement annotatedMethod) {TypeElement enclosingType = null;Element enclosing = annotatedMethod.getEnclosingElement();while (enclosing != null) {if (enclosing.getKind() == ElementKind.CLASS) {enclosingType = (TypeElement) enclosing;} else if (enclosing.getKind() == ElementKind.PACKAGE) {break;}enclosing = enclosing.getEnclosingElement();}return enclosingType;}private String formatParameter(ExecutableElement method, boolean includeType) {StringBuilder builder = new StringBuilder();builder.append('(');String separator = "";for (VariableElement parameter : method.getParameters()) {builder.append(separator);if (includeType) {builder.append(parameter.asType());builder.append(' ');}builder.append(parameter.getSimpleName());separator = ", ";}builder.append(')');return builder.toString();}}
在这个注解处理器实现中,我们将读取注解中的值,因此我将使用 process 方法的第一个参数,并通过它获得被标注方法对应的 @Adapt 注解中的 value 值。
之所以采用这种麻烦的方式,是因为 value 值属于 Class 类型。在编译过程中,被编译代码中的 Class 常量未必被加载进 Java 编译器所在的虚拟机中。因此,我们需要通过 process 方法的第一个参数,获得 value 所指向的接口的抽象语法树,并据此生成源代码。
生成源代码的方式实际上非常容易理解。我们可以通过 Filer.createSourceFile 方法获得一个类似于文件的概念,并通过 PrintWriter 将具体的内容一一写入即可。当将该注解处理器作为插件接入 Java 编译器时,编译前面的 test/Bar.java 将生成下述代码,并且触发新一轮的编译。
package test;import java.util.function.IntBinaryOperator;public class Bar_addAdapter implements IntBinaryOperator {@Overridepublic int applyAsInt(int arg0, int arg1) {return Bar.add(arg0, arg1);}}

若有收获,就点个赞吧
0 人点赞
