我们知道 HashMap 是一种键值对形式的数据存储容器,但是它有一个缺点是,元素内部无序。虽然 JDK 为我们提供了基于红黑树的 TreeMap 容器,但由于内部通过红黑结点的各种变换来维持二叉搜索树的平衡,所以相对复杂,并且不是线程安全的容器。
如果 TreeMap 要实现高效的线程安全是非常困难的,它的实现基于复杂的红黑树。为保证访问效率,当我们插入或删除节点时,会移动节点进行平衡操作,这导致在并发场景中难以进行合理粒度的同步。而 SkipList 结构则要相对简单很多,通过层次结构提高访问速度,虽然不够紧凑,空间使用有一定提高,为 O(nlogn),但是在增删元素时线程安全的开销要好很多。
ConcurrentSkipListMap 是线程安全并且有序的哈希表,底层通过 SkipList 实现,SkipList 是一种随机化的数据结构,通过用空间换时间的思想,对每个节点建立多级索引,实现以二分查找的形式遍历一个有序链表。时间复杂度等同于红黑树,都是 O(logn),但实现却远远比红黑树要简单。根据可比较的自然顺序或根据在创建 map 时提供的 Comparator 对 map 进行排序,具体取决于所使用的构造函数。
跳表
跳表(SkipList)是一种可以用来快速查找的数据结构,本质是多层链表,默认按照 Key 值升序的,有点类似于平衡树。但一个重要的区别是:对平衡树的插入和删除很可能导致平衡树进行一次全局的调整,而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。
SkipList 让已排序的数据分布在多层链表中,通过随机决定一个数据的向上攀升与否,通过用空间换时间的思想在每个节点中增加了向前的指针,在插入、删除、查找时可以忽略一些不会涉及到的结点,从而提高效率。
SkipList 的查找过程:
底层的链表维护了跳表内所有的元素, 每上面一层链表都是下面一层链表的子集,一个元素的 Level 层级完全是随机生成的。跳表内的所有链表的元素都是有序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续找(跳跃式搜索)。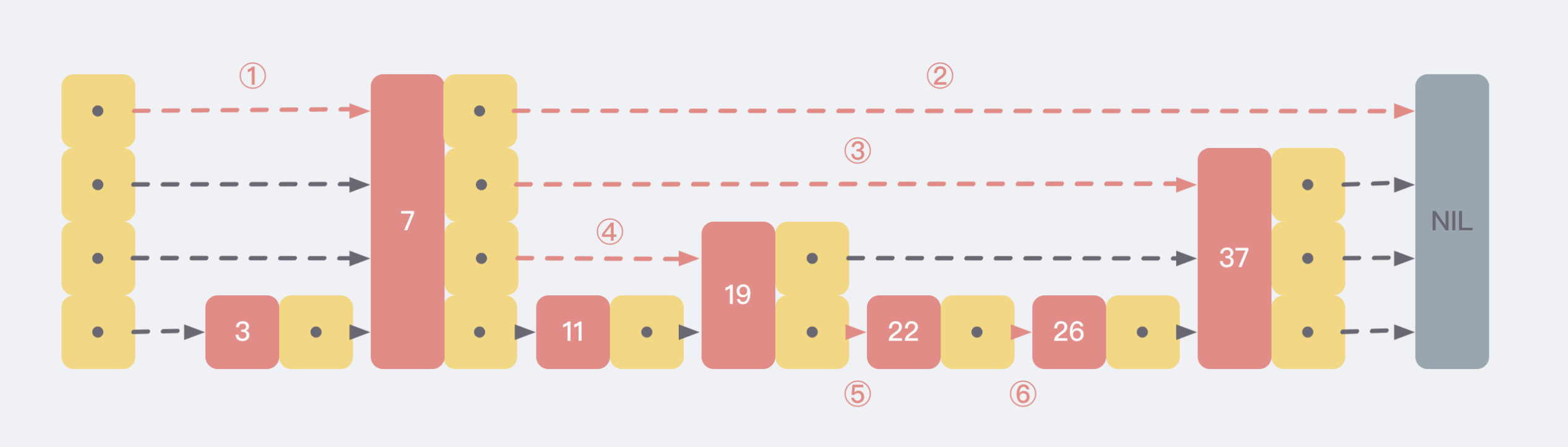
SkipList 的插入过程:
跳表的插入必然会在底层增加一个节点,但是往上的层次是否需要增加节点则完全是随机的,SkipList 通过概率保证整张表的节点分布均匀,它不像红黑树是通过人为的 rebalance 操作来保证二叉树的平衡性。如果新插入节点的 Level 小于当前表的最大 Level,则从最底层到 Level 层都添加一个该节点。如果新插入节点的 Level 大于当前表的最大 Level ,则为首尾节点新增一层 Level,并将新节点添加到该 Level 上。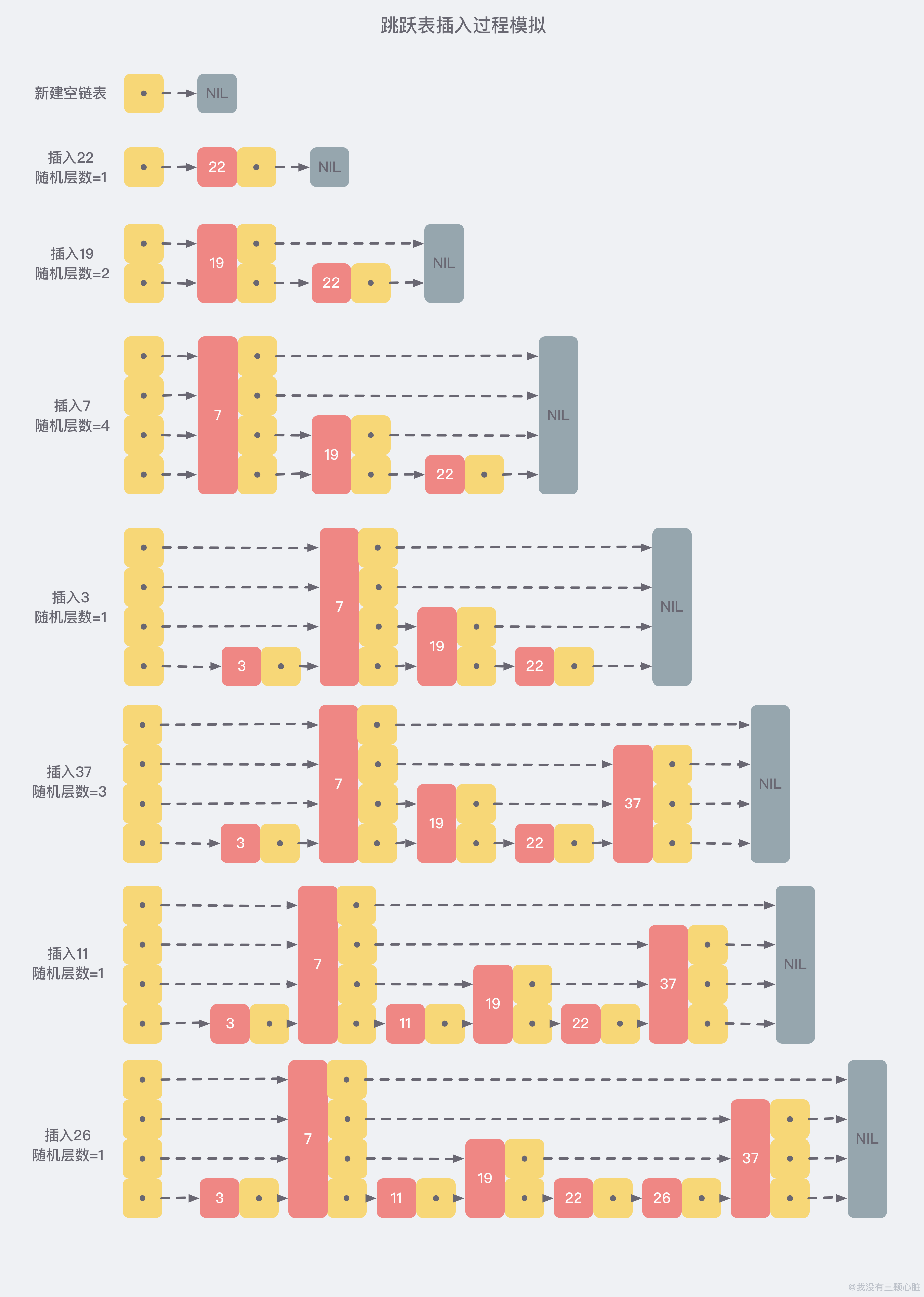
内部结构
public class ConcurrentSkipListMap<K,V> extends AbstractMap<K,V>implements ConcurrentNavigableMap<K,V>, Cloneable, Serializable {// 跳表的最高头索引private transient volatile HeadIndex<K,V> head;// 顺序比较器,如果使用自然顺序则为nullfinal Comparator<? super K> comparator;}
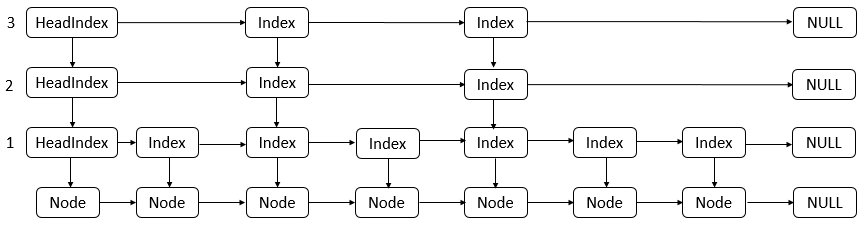
HeadIndex 结构中包含了一个随机的层数,以及向下的引用和向右的引用,整个跳表就是根据 Index 来组织,通过 Index 的索引结构来加速查询。
static class Index<K,V> {final Node<K,V> node;// 向下的索引final Index<K,V> down;// 向右的索引volatile Index<K,V> right;}static final class HeadIndex<K,V> extends Index<K,V> {// 层数final int level;HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {super(node, down, right);this.level = level;}}
Index 内部又包装了 Node,其中 next 用来维护链表关系,链表根据排序器进行排序。
static final class Node<K,V> {final K key;volatile Object value;volatile Node<K,V> next;// CAS设置value的值boolean casValue(Object cmp, Object val) {return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val);}// CAS设置next的值boolean casNext(Node<K,V> cmp, Node<K,V> val) {return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);}}
源码分析
1. put
public V put(K key, V value) {// value不能为空if (value == null)throw new NullPointerException();return doPut(key, value, false);}
1)主要完成了向底层链表插入一个节点,跳表需要根据概率算法保证节点分布稳定,它的调节措施相对于红黑树来说就简单多了,通过往上层索引层添加相关引用即可,以空间换时间。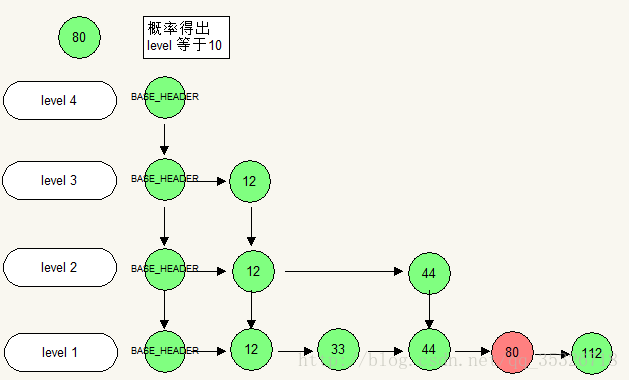
2)根据 level 的值,确认是否需要增加一层索引,如果不需要则构建好底层到 level 层的 index 结点的纵向引用。如果需要则新创建一层索引,完成 head 结点的指针转移,并构建好纵向的 index 结点引用。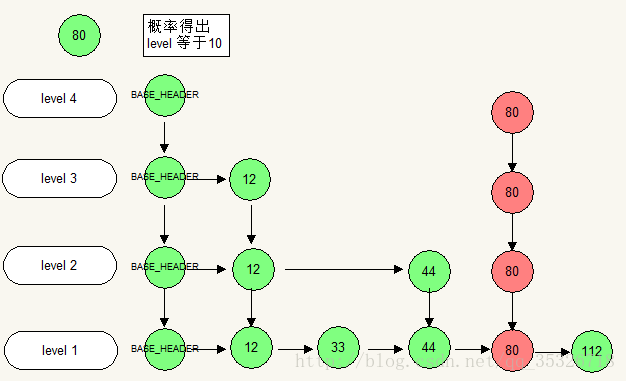
3)将我们的新节点在每个索引层都构建好前后的链接关系。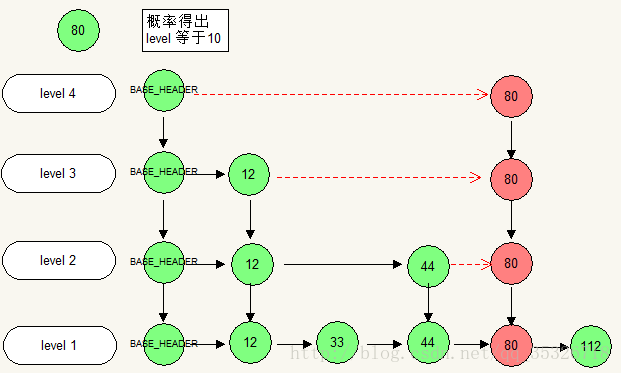
2. get
private V doGet(Object key) {if (key == null)throw new NullPointerException();Comparator<? super K> cmp = comparator;outer: for (;;) {// 找到待删除结点for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {Object v; int c;if (n == null)break outer;Node<K,V> f = n.next;if (n != b.next) // inconsistent readbreak;if ((v = n.value) == null) { // n is deletedn.helpDelete(b, f);break;}if (b.value == null || v == n) // b is deletedbreak;if ((c = cpr(cmp, key, n.key)) == 0) {@SuppressWarnings("unchecked") V vv = (V)v;return vv;}if (c < 0)break outer;b = n;n = f;}}return null;}
1)找到待删除结点,通过 CAS 将其 value 属性值置为 null 以标记该结点无用了。
+———+ +———+ +———+ … | b |———>| null |——->| f | … +———+ +———+ +———+
2)通过 CAS 向待删除结点的 next 位置新增一个空的 marker 标记结点,作用是分散下一步的并发冲突性。
+———+ +———+ +———+ +———+ … | b |———>| null |——->|marker|——>| f | … +———+ +———+ +———+ +———+
3)CAS 删除具体的结点,实际上也就是跳过该待删结点,让待删结点的前驱节点直接指向待删结点的后继结点。
+———+ +———+ … | b |———————————->| f | … +———+ +———+

若有收获,就点个赞吧
0 人点赞
