今天我们来聊聊性能基准测试(benchmarking)。不少开发人员在做性能测试时都会使用 System.nanoTime 或者 System.currentTimeMillis 来测量执行若干个操作所花费的时间。这种测量方式实际上过于理性化,忽略了 Java 虚拟机、操作系统,乃至硬件系统所带来的影响。
性能测试的坑
public class LoopPerformanceTest {static int foo() { ... }public static void main(String[] args) {// 预热for (int i = 0; i < 20_000; i++) {foo();}// 真正进行测试long current = System.nanoTime();for (int i = 1; i <= 10_000; i++) {foo();if (i % 1000 == 0) {long temp = System.nanoTime();System.out.println(temp - current);current = System.nanoTime();}}}}
在上面这段代码中,真正进行测试的代码由于循环次数不多,属于冷循环,没有能触发 OSR 编译。因此我们会先在 main 方法中解释执行,然后再调用 foo 方法即时编译生成的机器码。这种混杂了解释执行以及即时编译生成机器码的测量方式,其得到的数据含义不明。
关于硬件和操作系统所带来的影响,一个较为常见的例子便是电源管理策略。在许多机器上,操作系统会动态配置 CPU 的频率。而 CPU 的频率又直接影响到性能测试,因此短时间的性能测试得出的数据未必可靠。
除了电源管理外,CPU 缓存、分支预测器以及超线程技术,都会对测试结果造成影响。对于 CPU 缓存而言,如果程序的数据本地性较好,那它的性能指标便会非常好;如果程序存在 false sharing 的问题,即几个线程写入内存中属于同一缓存行的不同部分,那它的性能指标便会非常糟糕。超线程技术将为每个物理核心虚拟出两个虚拟核心,从而尽可能地提高物理核心的利用率。如果性能测试的两个线程被安排在同一物理核心上,那得到的测试数据显然要比被安排在不同物理核心上的数据糟糕得多。
总而言之,性能基准测试存在着许多深坑。然而,除了性能测试专家外,大多数开发人员都没有足够全面的知识能够绕开这些坑,因而得出的性能测试数据很有可能是有偏差的。
JMH
下面介绍 OpenJDK 中的开源项目 JMH(Java Microbenchmark Harness)。JMH 是一个面向 Java 语言或其他 Java 虚拟机语言的性能基准测试框架。它针对的是纳秒、微秒、毫秒以及秒级别的性能测试。
由于许多即时编译器的开发人员参与了该项目,因此 JMH 内置了许多功能来控制即时编译器的优化。此外也提供了不少策略来降低甚至彻底解决其他影响性能评测的因素。因此,使用这个性能基准测试框架的开发人员可以将精力完全集中在所要测试的业务逻辑,并以最小的代价控制除业务逻辑外的可能影响性能的因素。
1. 生成 JMH 项目
JMH 的使用方式并不复杂。我们可以借助 JMH 部署在 maven 上的 archetype 生成预设好依赖关系的 maven 项目模板。具体的命令如下所示:
$ mvn archetype:generate \-DinteractiveMode=false \-DarchetypeGroupId=org.openjdk.jmh \-DarchetypeArtifactId=jmh-java-benchmark-archetype \-DgroupId=org.sample \-DartifactId=test \-Dversion=1.21
该命令将在当前目录下生成一个 test 文件夹(-DartifactId=test),其中便包含了定义该 maven 项目依赖的 pom.xml 文件,以及自动生成的测试文件 src/main/java/org/sample/MyBenchmark.java(路径对应参数 -DgroupId=org.sample)。后者的内容如下图所示: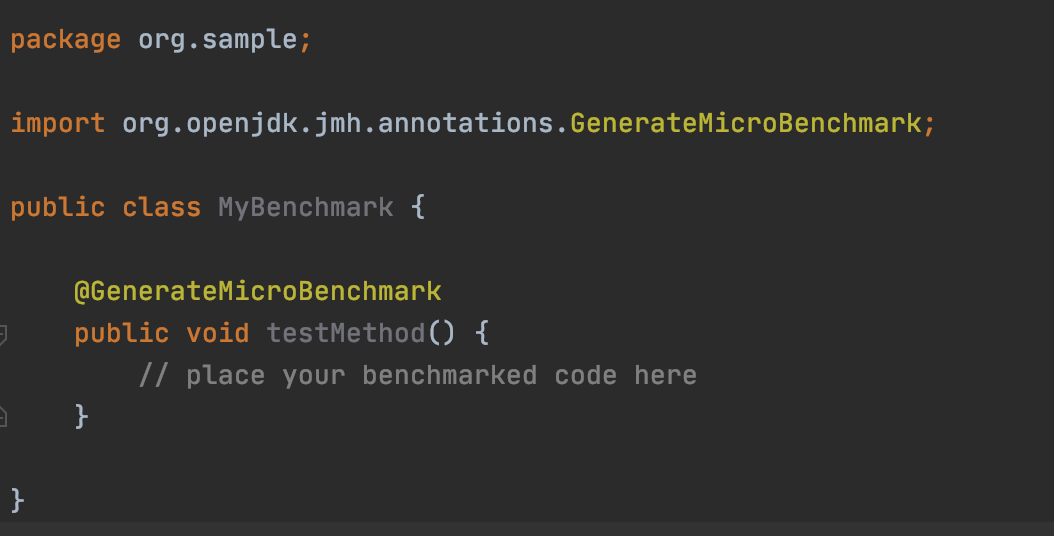
这里面真正重要的是 @GenerateMicroBenchmark 注解,被它标注的方法便是 JMH 基准测试的测试方法,我们可以填入需要进行性能测试的业务逻辑。
2. 编译和运行 JMH 项目
JMH 是利用【注解处理器】来自动生成性能测试的代码。实际上,除了 @GenerateMicroBenchmark 注解之外,JMH 的注解处理器还将处理所有位于 org.openjdk.jmh.annotations 包下的注解。我们运行 mvn compile 命令来编译这个 maven 项目。编译后的文件在原有的 MyBenchmark 类中又新增了一些类:
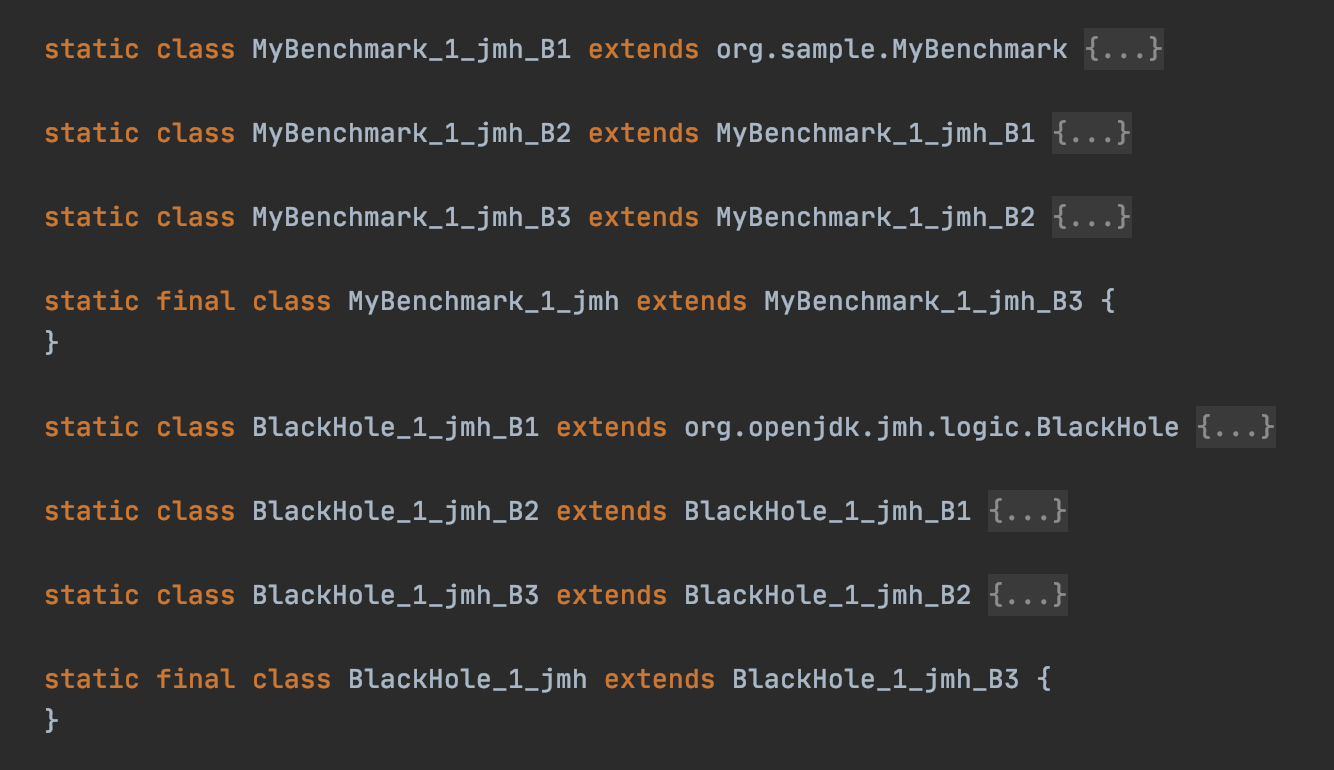
在这些源代码里,所有以 MyBenchmark_1_jmh 为前缀的 Java 类都继承自 MyBenchmark。这是注解处理器的常见用法,即通过生成子类来将注解所带来的额外语义扩张成方法。
具体来说,它们之间的继承关系是 MyBenchmark_1_jmh -> B3 -> B2 -> B1 -> MyBenchmark。其中 B2 存放着 JMH 用来控制基准测试的各项字段。为了避免这些控制字段对 MyBenchmark 类中的字段造成 false sharing 的影响,JMH 生成了 B1 和 B3,里面分别存放了 256 个 boolean 字段,从而避免 B2 中的字段与MyBenchmark 类、MyBenchmark_1_jmh 类中的字段出现在同一缓存行中。
之所以不能在同一类中安排这些字段,是因为 Java 虚拟机的字段重排列。而类之间的继承关系,便可以避免不同类所包含的字段之间的重排列。
接下来,我们可以运行 mvn package 命令将编译好的 class 文件打包成 jar 包。生成的 jar 包同样位于 target 目录下,其名字为 microbenchmarks.jar,jar 包里附带了一系列配置文件,具体如下所示: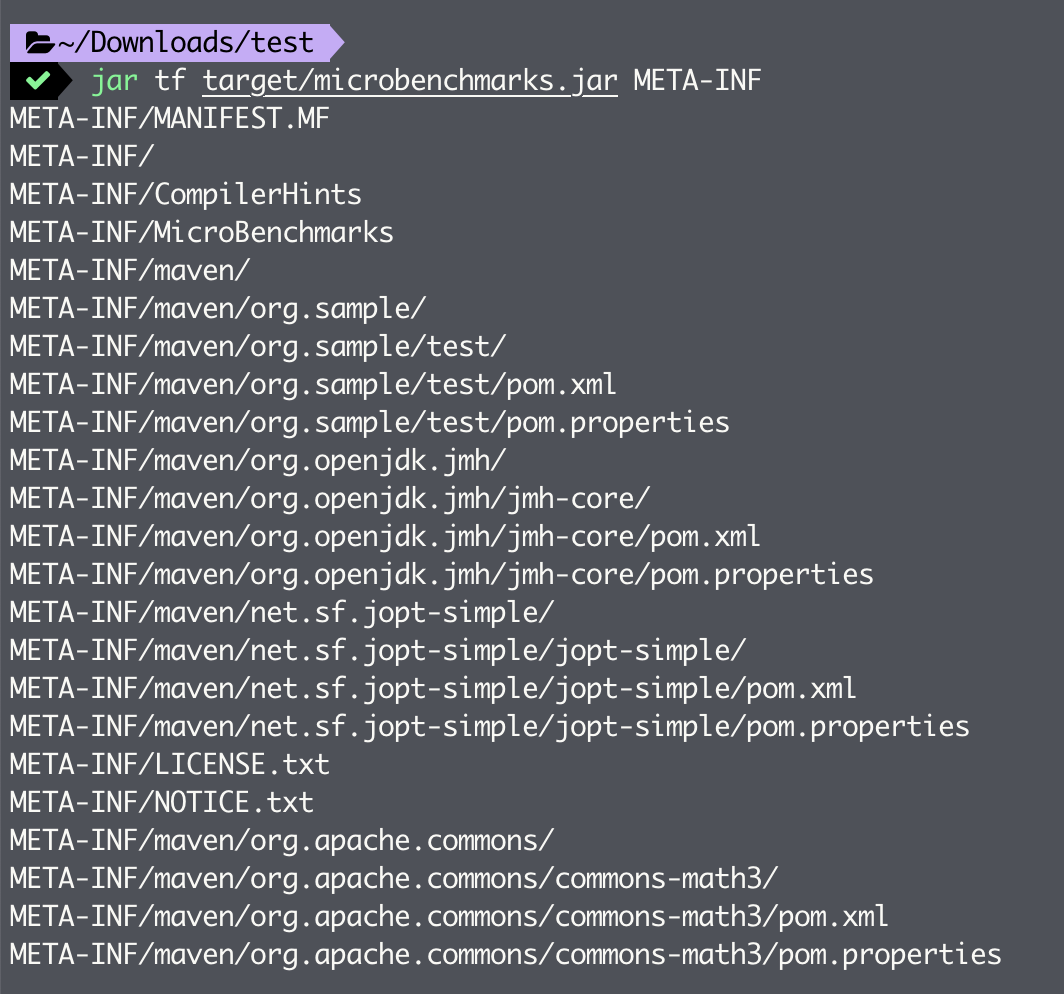
这里展示了其中三个比较重要的配置文件。
1)MANIFEST.MF 中指定了该 jar 包的默认入口,即 org.openjdk.jmh.Main(在生成的 pom.xml 中指定)。 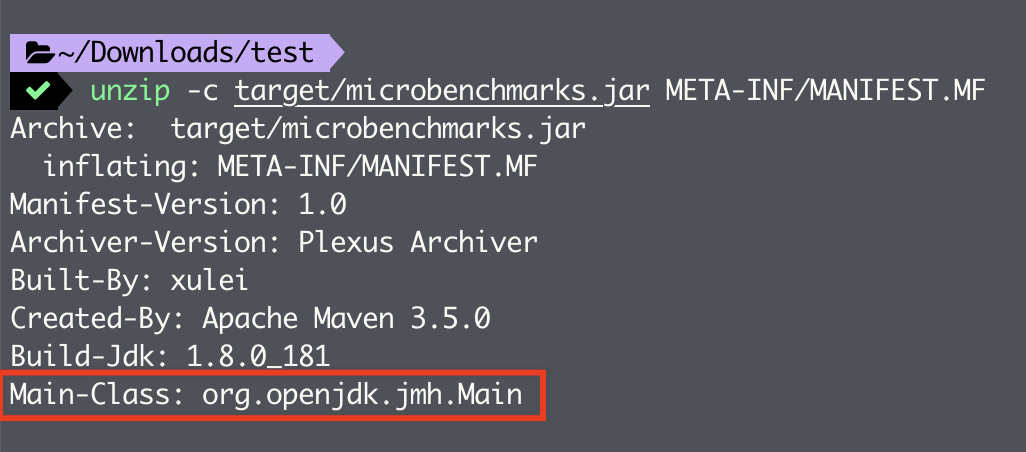
2)MicroBenchmarks 中存放了测试配置。该配置是根据 MyBenchmark.java 里的注解自动生成的。
3)CompilerHints 中存放了传递给 Java 虚拟机的 -XX:CompileCommandFile 参数的内容。它规定了无法内联以及必须内联的几个方法,其中便有存放业务逻辑的测试方法 testMethod。JMH 会让即时编译器强制内联对 MyBenchmark.testMethod 的方法调用,以避免调用开销。
直接运行 jar 包,最后输出的便是本次基准测试的结果。其中比较重要的两项指标是 Mean 和 Mean error,分别代表本次基准测试的平均吞吐量(每毫秒运行 testMethod 方法的次数)以及误差范围。
3. @Fork
我们完整回顾一下由 JMH 项目编译生成的 jar 包,运行后的完整输出结果:
java -jar target/microbenchmarks.jar# Run progress: 0.00% complete, ETA 00:06:40# VM invoker: /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/bin/java# VM options: <none># Fork: 1 of 10# Warmup: 20 iterations, 1 s each# Measurement: 20 iterations, 1 s each# Threads: 1 thread, will synchronize iterations# Benchmark mode: Throughput, ops/time# Benchmark: org.sample.MyBenchmark.testMethod# Warmup Iteration 1: 1158.903 ops/ms# Warmup Iteration 2: 1237.776 ops/ms# Warmup Iteration 3: 1322.917 ops/ms# Warmup Iteration 4: 1301.547 ops/ms# Warmup Iteration 5: 1280.789 ops/ms# Warmup Iteration 6: 1294.365 ops/ms# Warmup Iteration 7: 1277.563 ops/ms# Warmup Iteration 8: 1304.908 ops/ms# Warmup Iteration 9: 1273.873 ops/ms# Warmup Iteration 10: 1301.812 ops/ms# Warmup Iteration 11: 1195.724 ops/ms# Warmup Iteration 12: 1147.860 ops/ms# Warmup Iteration 13: 1178.888 ops/ms# Warmup Iteration 14: 1274.512 ops/ms# Warmup Iteration 15: 1140.939 ops/ms# Warmup Iteration 16: 1192.370 ops/ms# Warmup Iteration 17: 1383.014 ops/ms# Warmup Iteration 18: 1371.368 ops/ms# Warmup Iteration 19: 1203.803 ops/ms# Warmup Iteration 20: 1392.537 ops/msIteration 1: 1373.794 ops/msIteration 2: 1400.983 ops/msIteration 3: 1348.513 ops/msIteration 4: 1346.878 ops/msIteration 5: 1378.482 ops/msIteration 6: 1327.803 ops/msIteration 7: 1345.124 ops/msIteration 8: 1395.781 ops/msIteration 9: 1355.261 ops/msIteration 10: 1278.730 ops/msIteration 11: 1388.079 ops/msIteration 12: 1284.863 ops/msIteration 13: 1271.702 ops/msIteration 14: 1272.836 ops/msIteration 15: 1244.266 ops/msIteration 16: 1148.671 ops/msIteration 17: 1182.143 ops/msIteration 18: 1238.625 ops/msIteration 19: 1275.786 ops/msIteration 20: 1206.649 ops/msResult : 1303.248 ±(99.9%) 64.283 ops/msStatistics: (min, avg, max) = (1148.671, 1303.248, 1400.983), stdev = 74.028Confidence interval (99.9%): [1238.966, 1367.531]# Fork: 2 of 10......Result : 1214.025 ±(99.9%) 45.127 ops/msStatistics: (min, avg, max) = (1137.658, 1214.025, 1317.257), stdev = 51.968Confidence interval (99.9%): [1168.898, 1259.152]# Fork: 3 of 10......Result : 1237.204 ±(99.9%) 56.168 ops/msStatistics: (min, avg, max) = (1131.540, 1237.204, 1390.610), stdev = 64.684Confidence interval (99.9%): [1181.035, 1293.372]......# Run progress: 90.00% complete, ETA 00:00:40# VM invoker: /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/bin/java# VM options: <none># Fork: 10 of 10# Warmup: 20 iterations, 1 s each# Measurement: 20 iterations, 1 s each# Threads: 1 thread, will synchronize iterations# Benchmark mode: Throughput, ops/time# Benchmark: org.sample.MyBenchmark.testMethod# Warmup Iteration 1: 1110.721 ops/ms# Warmup Iteration 2: 1257.029 ops/ms# Warmup Iteration 3: 1296.966 ops/ms# Warmup Iteration 4: 1150.056 ops/ms# Warmup Iteration 5: 1112.340 ops/ms# Warmup Iteration 6: 1235.937 ops/ms# Warmup Iteration 7: 1173.688 ops/ms# Warmup Iteration 8: 1148.562 ops/ms# Warmup Iteration 9: 1196.070 ops/ms# Warmup Iteration 10: 1182.127 ops/ms# Warmup Iteration 11: 1122.463 ops/ms# Warmup Iteration 12: 1216.516 ops/ms# Warmup Iteration 13: 1222.638 ops/ms# Warmup Iteration 14: 1261.748 ops/ms# Warmup Iteration 15: 1213.760 ops/ms# Warmup Iteration 16: 1224.055 ops/ms# Warmup Iteration 17: 1338.128 ops/ms# Warmup Iteration 18: 1305.327 ops/ms# Warmup Iteration 19: 1187.515 ops/ms# Warmup Iteration 20: 1336.241 ops/msIteration 1: 1329.088 ops/msIteration 2: 1122.961 ops/msIteration 3: 1239.192 ops/msIteration 4: 1259.081 ops/msIteration 5: 1259.432 ops/msIteration 6: 1251.819 ops/msIteration 7: 1173.109 ops/msIteration 8: 1257.391 ops/msIteration 9: 1116.438 ops/msIteration 10: 1214.700 ops/msIteration 11: 1262.468 ops/msIteration 12: 1270.855 ops/msIteration 13: 1255.625 ops/msIteration 14: 1321.985 ops/msIteration 15: 1337.681 ops/msIteration 16: 1340.014 ops/msIteration 17: 1321.762 ops/msIteration 18: 1332.541 ops/msIteration 19: 1319.699 ops/msIteration 20: 1301.765 ops/msResult : 1264.380 ±(99.9%) 57.977 ops/msStatistics: (min, avg, max) = (1116.438, 1264.380, 1340.014), stdev = 66.766Confidence interval (99.9%): [1206.404, 1322.357]Benchmark Mode Samples Mean Mean error Unitso.s.MyBenchmark.testMethod thrpt 200 1295.122 20.255 ops/ms
你应该已经留意到 Fork: 1 of 10 的字样。这里指的是 JMH 会 Fork 出一个新的 Java 虚拟机,来运行性能基准测试。目的是为了获得一个相对干净的虚拟机环境。使用新的虚拟机可以极大地降低被即时编译器干扰的可能性,从而保证更加精确的性能数据。
除了对即时编译器的影响外,Fork 出新的 Java 虚拟机还会提升性能数据的准确度。这主要是因为不少 Java 虚拟机的优化会带来不确定性,例如 TLAB 内存分配,偏向锁、轻量锁算法,并发数据结构等。这些不确定性都可能导致不同 Java 虚拟机中运行的性能测试的结果不同。因此,通过运行更多的 Fork 并将每个 Java 虚拟机的性能测试结果平均起来,可以增强最终数据的可信度,使其误差更小。
在 JMH 中,你可以通过 @Fork 注解来配置,具体如下述代码所示:
@Fork(10)public class MyBenchmark {...}
4. @BenchmarkMode
让我们回到刚刚的输出结果。每个 Fork 包含了 20 个预热迭代(Warmup)以及 20 个测试迭代(Measurement)。每个迭代后都跟着一个数据,代表本次迭代的吞吐量,也就是单位时间(ops/ms)内运行了多少次操作。默认情况下,一次操作指的是调用一次测试方法 testMethod。
迭代(Iteration)是 JMH 的测量单位。在大部分测量模式下,一次迭代是 1 秒。在这一秒内,会不间断地调用被测试方法,并采样计算吞吐量、平均时间等性能数据。具体的配置方法及对应参数如下代码所示:
@BenchmarkMode(Mode.AverageTime)public class MyBenchmark {...}
Mode 表示 JMH 的测量方式和角度,共有四种:
- Throughput:整体吞吐量,表示 1 秒内可以执行多少次调用。
- AverageTime:每一次调用的平均时间。
- SampleTime:随机取样,最后输出取样结果的分布,例如:99% 的调用在多少毫秒内
- SingleShotTime:以上模式都是默认一次 Iteration 是 1 秒,而 SingleShotTime 只运行一次
5. @Warmup、@Measurement
之所以区分预热迭代(Warmup)和测试迭代(Measurement),是为了在记录性能数据前,将 Java 虚拟机带至一个稳定状态。这里的稳定状态不仅包括测试方法被即时编译成机器码,还包括 Java 虚拟机中各种自适配优化算法能够稳定下来,如使用传统垃圾回收器时的 Eden 区、Survivor 区和老年代的大小。
通常来说,开发人员需要自行决定预热迭代的次数以及每次迭代的持续时间,一般是在保持 5-10 个预热迭代的前提下(这样可以看出是否达到稳定状况)将总的预热时间优化至最少,以便节省性能测试的机器时间。
当确定了预热迭代的次数以及每次迭代的持续时间之后,我们便可以通过 @Warmup 注解来进行预热配置,具体的配置方法及对应参数如下代码所示:
@Warmup(iterations=10, time=100, timeUnit=TimeUnit.MILLISECONDS, batchSize=10)public class MyBenchmark {...}
@Warmup 注解有四个参数,分别为:
- 预热迭代的次数 iterations
- 每次迭代持续的时间 time 和 timeUnit(前者是数值,后者是单位)
- 每次操作包含多少次对测试方法的调用 batchSize。
测试迭代可通过 @Measurement 注解来进行配置。它的可配置选项和 @Warmup 一致。但是与预热迭代不同的是,每个 Fork 中测试迭代的数目越多,我们得到的性能数据也就越精确。
6. @State
JMH 提供了 @State 注解,被它标注的类便是程序的状态。由于 JMH 将负责生成这些状态类的实例,因此,它要求状态类必须拥有无参数构造器,以及当状态类为内部类时,该状态类必须是静态的。
JMH 还将程序状态细分为整个虚拟机的程序状态,线程私有的程序状态,以及线程组私有的程序状态,分别对应 @State 注解的参数 Scope.Benchmark,Scope.Thread 和 Scope.Group。需要注意的是,这里的线程组并非 JDK 中的那个概念,而是 JMH 自己定义的概念。具体可以参考 @GroupThreads 注解。
@State 注解的配置方法以及状态类的用法如下所示:
public class MyBenchmark {@State(Scope.Benchmark)public static class MyBenchmarkState {String message = "exception";}@GenerateMicroBenchmarkpublic void testMethod(MyBenchmarkState state) {new Exception(state.message);}}
可以看到,状态类是通过方法参数的方式传入测试方法之中的。JMH 将负责把所构造的状态类实例传入该方法之中。不过如果 MyBenchmark 被标注为 @State,那么我们可以不用在测试方法中定义额外的参数,而是直接访问 MyBenchmark 类中的实例变量。
@State(Scope.Benchmark)public class MyBenchmark {private static String message = "exception";@GenerateMicroBenchmarkpublic void testMethod() {new Exception(message);}}
7. @Setup、@TearDown
和 JUnit 测试一样,我们可以在测试前初始化程序状态,在测试后校验程序状态。这两种操作分别对应 @Setup 和 @TearDown 注解,被它们标注的方法必须是状态类中的方法。
而且,JMH 并不限定状态类中 @Setup 方法以及 @TearDown 方法的数目。当存在多个 @Setup 方法或者 @TearDown 方法时,JMH 将按照定义的先后顺序执行。
JMH 对 @Setup 方法以及 @TearDown 方法的调用时机是可配置的。可供选择的粒度有
- 在整个性能测试前后调用,对应 @Setup 和 @TearDown 注解的参数 Level.Trial
- 在每个迭代前后调用,对应注解参数 Level.Iteration
- 在每次调用测试方法前后调用,该粒度将影响测试数据的精度。对应注解参数 Level.Invocation
具体的用法如下所示:
public class MyBenchmark {@State(Scope.Benchmark)public static class MyBenchmarkState {int count;@Setup(Level.Invocation)public void before() {count = 0;}@TearDown(Level.Invocation)public void after() {// Run with -eaassert count == 1 : "ERROR";}}@GenerateMicroBenchmarkpublic void testMethod(MyBenchmarkState state) {state.count++;}}
总结
@Fork 允许开发人员指定所要 Fork 出的 Java 虚拟机的数目。
@BenchmarkMode 允许指定性能数据的格式。
@Warmup 和 @Measurement 允许配置预热迭代或者测试迭代的数目,每个迭代的时间以及每个操作包含多少次对测试方法的调用。
@State 允许配置测试程序的状态。
测试前对程序状态的初始化以及测试后对程序状态的恢复或者校验可分别通过 @Setup 和 @TearDown 来实现。

若有收获,就点个赞吧
0 人点赞
