Lambda 表达式的初衷是进一步简化匿名类的语法(不过实现上 Lambda 表达式并不是匿名类的语法糖),从而使得 Java 走向函数式编程。对于匿名类,虽然没有类名但还是要给出方法定义。这里有个例子,分别使用了匿名类和 Lambda 表达式创建一个线程打印字符串:
//匿名类new Thread(new Runnable(){@Overridepublic void run(){System.out.println("hello1");}}).start();//Lambda表达式new Thread(() -> System.out.println("hello2")).start();
匿名内部类和 Lambda 到底有什么区别呢?为什么匿名内部类会生成 $1 这样的 class 文件而 Lambda 并没有??? 参考资料:https://colobu.com/2014/11/06/secrets-of-java-8-lambda/
那么,Lambda 表达式如何匹配 Java 的类型系统呢?答案就是,函数式接口。
函数式接口
函数式接口是一种只有单一抽象方法的接口,使用 @FunctionalInterface 注解来描述,可以隐式地转换成 Lambda 表达式。使用 Lambda 表达式来实现函数式接口不需要提供类名和方法定义,只需提供函数式接口的实例就可以让函数像普通数据一样作为参数传递,而不是作为一个固定的类中的固定方法。
那函数式接口到底是什么样的呢?java.util.function 包中定义了各种函数式接口。比如,用于提供数据的 Supplier 接口,就只有一个 get 抽象方法,没有任何入参,有一个返回值:
@FunctionalInterfacepublic interface Supplier<T> {T get();}
我们可以使用 Lambda 表达式或方法引用,来得到 Supplier 接口的实例:
//使用Lambda表达式提供Supplier接口实现,返回OK字符串Supplier<String> stringSupplier = ()->"OK";//使用方法引用提供Supplier接口实现,返回空字符串Supplier<String> supplier = String::new;
这样是不是很方便?下面再举几个使用 Lambda 表达式或方法引用来构建函数的例子:
// Predicate接口是输入一个参数,返回布尔值。我们通过and方法组合两个Predicate条件,判断值是否大于0且是偶数Predicate<Integer> positiveNumber = i -> i > 0;Predicate<Integer> evenNumber = i -> i % 2 == 0;assertTrue(positiveNumber.and(evenNumber).test(2));// Consumer接口是消费一个数据。我们通过andThen方法组合调用两个Consumer,输出两行abcdefgConsumer<String> println = System.out::println;println.andThen(println).accept("abcdefg");// Function接口是输入一个数据,计算后输出一个数据。我们先把字符串转换为大写,然后通过andThen组合另一个Function实现字符串拼接Function<String, String> upperCase = String::toUpperCase;Function<String, String> duplicate = s -> s.concat(s);assertThat(upperCase.andThen(duplicate).apply("test"), is("TESTTEST"));// Supplier是提供一个数据的接口。这里我们实现获取一个随机数Supplier<Integer> random = ()->ThreadLocalRandom.current().nextInt();System.out.println(random.get());// BinaryOperator是输入两个同类型参数,输出一个同类型参数的接口。这里我们通过方法引用获得一个整数加法操作,通过Lambda表达式定义一个减法操作,然后依次调用BinaryOperator<Integer> add = Integer::sum;BinaryOperator<Integer> subtraction = (a, b) -> a - b;assertThat(subtraction.apply(add.apply(1, 2), 3), is(0));
Predicate、Function 等函数式接口,还使用 default 关键字实现了几个默认方法。这样一来,它们既可以满足函数式接口只有一个抽象方法,又能为接口提供额外的功能:
@FunctionalInterfacepublic interface Function<T, R> {R apply(T t);default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {Objects.requireNonNull(before);return (V v) -> apply(before.apply(v));}default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {Objects.requireNonNull(after);return (T t) -> after.apply(apply(t));}}
很明显,Lambda 表达式给了我们复用代码的更多可能性:我们可以把一大段逻辑中变化的部分抽象出函数式接口,由外部方法提供函数实现,重用方法内的整体逻辑处理。
不过需要注意的是,在自定义函数式接口前,先确认下 java.util.function 包中的 43 个标准函数式接口是否能满足需求,我们要尽可能重用这些接口,因为使用大家熟悉的标准接口可以提高代码的可读性。
| 函数式接口 | 参数类型 | 返回类型 | 抽象方法名 | 其他方法 |
|---|---|---|---|---|
| Supplier |
T | get | ||
| Consumer |
T | void | accept | andThen |
| BiConsumer |
T, U | void | accept | andThen |
| Function |
T | R | apply | compose,andThen,identity |
| BiFunction |
T, U | R | apply | andThen |
| UnaryOperator |
T | T | apply | compose,andThen,identity |
| BinaryOperator |
T, T | T | apply | andThen,maxBy,minBy |
| Predicate |
T | boolean | test | and,or,negate,isEqual |
| BiPredicate |
T, U | boolean | test | and,or,negate |
常用 Stream 操作

下面以订单场景为例,给出如何使用 Stream 的各种 API 完成订单的统计、搜索、查询等功能。我们先定义一个订单类、一个订单商品类和一个顾客类,用作后续 Demo 代码的数据结构:
//订单类@Datapublic class Order {private Long id;private Long customerId;//顾客IDprivate String customerName;//顾客姓名private List<OrderItem> orderItemList;//订单商品明细private Double totalPrice;//总价格private LocalDateTime placedAt;//下单时间}//订单商品类@Data@AllArgsConstructor@NoArgsConstructorpublic class OrderItem {private Long productId;//商品IDprivate String productName;//商品名称private Double productPrice;//商品价格private Integer productQuantity;//商品数量}//顾客类@Data@AllArgsConstructorpublic class Customer {private Long id;private String name;//顾客姓名}
1. 创建流
要使用流,就要先创建流。创建流一般有五种方式:
- 通过 stream 方法把 List 或数组转换为流;
- 通过 Stream.of 方法直接传入多个元素构成一个流;
- 通过 Stream.ofNullable 方法创建一个短流,如果该对象为 null 则流的长度为 0,否则,流的长度为 1,即只包含该对象;
- 通过 Stream.iterate 方法使用迭代的方式构造一个无限流;
- 通过 Stream.generate 方法从外部传入一个提供元素的 Supplier 来构造无限流;
- 通过 IntStream 或 DoubleStream 构造基本类型的流;
- 如果我们持有的 Iterable 对象不是集合,可通过 StreamSupport.stream 方法将其转换为流。
//通过stream方法把List或数组转换为流@Testpublic void stream(){Arrays.asList("a1", "a2", "a3").stream().forEach(System.out::println);Arrays.stream(new int[]{1, 2, 3}).forEach(System.out::println);}//通过Stream.of方法直接传入多个元素构成一个流@Testpublic void of(){String[] arr = {"a", "b", "c"};Stream.of(arr).forEach(System.out::println);Stream.of("a", "b", "c").forEach(System.out::println);Stream.of(1, 2, "a").map(item -> item.getClass().getName()).forEach(System.out::println);}//通过Stream.iterate方法使用迭代的方式构造一个无限流,然后使用limit限制流元素个数@Testpublic void iterate(){Stream.iterate(2, item -> item * 2).limit(10).forEach(System.out::println);Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.TEN)).limit(10).forEach(System.out::println);}//通过Stream.generate方法从外部传入一个提供元素的Supplier来构造无限流,然后使用limit限制流元素个数@Testpublic void generate(){Stream.generate(() -> "test").limit(3).forEach(System.out::println);Stream.generate(Math::random).limit(10).forEach(System.out::println);}//通过IntStream或DoubleStream构造基本类型的流@Testpublic void primitive(){IntStream.range(1, 3).forEach(System.out::println);IntStream.range(0, 3).mapToObj(i -> "x").forEach(System.out::println);IntStream.rangeClosed(1, 3).forEach(System.out::println);DoubleStream.of(1.1, 2.2, 3.3).forEach(System.out::println);//各种转换,后面注释代表了输出结果System.out.println(IntStream.of(1, 2).toArray().getClass()); //class [ISystem.out.println(Stream.of(1, 2).mapToInt(Integer::intValue).toArray().getClass()); //class [ISystem.out.println(IntStream.of(1, 2).boxed().toArray().getClass()); //class [Ljava.lang.Object;System.out.println(IntStream.of(1, 2).asDoubleStream().toArray().getClass()); //class [DSystem.out.println(IntStream.of(1, 2).asLongStream().toArray().getClass()); //class [J//注意基本类型流和装箱后的流的区别Arrays.asList("a", "b", "c").stream() // Stream<String>.mapToInt(String::length) // IntStream.asLongStream() // LongStream.mapToDouble(x -> x / 10.0) // DoubleStream.boxed() // Stream<Double>.mapToLong(x -> 1L) // LongStream.mapToObj(x -> "") // Stream<String>.collect(Collectors.toList());}
2. filter
filter 方法可以实现过滤操作,类似 SQL 中的 where。我们可以使用一行代码,通过 filter 方法实现查询所有订单中最近半年金额大于 40 的订单,通过连续叠加 filter 方法进行多次条件过滤:
orders.stream().filter(Objects::nonNull) //过滤null值.filter(order -> order.getPlacedAt().isAfter(LocalDateTime.now().minusMonths(6))) //最近半年的订单.filter(order -> order.getTotalPrice() > 40) //金额大于40的订单.forEach(System.out::println);
3. map
map 操作可以做转换(或者说投影),类似 SQL 中的 select。为了对比,我用两种方式统计订单中所有商品的数量,前一种是通过两次遍历实现,后一种是通过两次 mapToLong + sum 方法实现:
//计算所有订单商品数量,通过两次遍历实现LongAdder longAdder = new LongAdder();orders.stream().forEach(order ->order.getOrderItemList().forEach(orderItem -> longAdder.add(orderItem.getProductQuantity())));//使用两次mapToLong+sum方法实现assertThat(longAdder.longValue(), is(orders.stream().mapToLong(order ->order.getOrderItemList().stream().mapToLong(OrderItem::getProductQuantity).sum()).sum()));
显然,后一种方式无需中间变量 longAdder,更直观。
这里再补充一下,使用 for 循环生成数据,是我们平时常用的操作。现在,我们可以用一行代码使用 IntStream 配合 mapToObj 替代 for 循环来生成数据,比如生成 10 个 Product 元素构成 List:
IntStream.rangeClosed(1,10).mapToObj(i->new Product((long)i, "product"+i, i*100.0)).collect(toList());
4. flatMap
接下来,我们看看 flatMap 展开或者叫扁平化操作,相当于 map + flat,通过 map 把每一个元素替换为一个流,然后展开这个流。比如,我们要统计所有订单的总价格,可以有两种方式:
直接通过原始商品列表的商品个数 * 商品单价统计的话,可以先把订单通过 flatMap 展开成商品清单,然后对每一个 OrderItem 用 mapToDouble 转换获得商品总价,最后进行一次 sum 求和;
利用 flatMapToDouble 方法把列表中每一项展开替换为一个 DoubleStream,也就是直接把每一个订单转换为每一个商品的总价,然后求和。 ```java //直接展开订单商品进行价格统计 System.out.println(orders.stream()
.flatMap(order -> order.getOrderItemList().stream()).mapToDouble(item -> item.getProductQuantity() * item.getProductPrice()).sum());
//另一种方式flatMap+mapToDouble=flatMapToDouble System.out.println(orders.stream() .flatMapToDouble(order -> order.getOrderItemList() .stream().mapToDouble(item -> item.getProductQuantity() * item.getProductPrice())) .sum());
这两种方式可以得到相同的结果,并无本质区别。
<a name="OBrLm"></a>
## 5. sorted
sorted 操作可以用于行内排序的场景,类似 SQL 中的 order by。比如,要实现大于 50 元订单的按价格倒序取前 5,可以通过 Order::getTotalPrice 方法引用直接指定需要排序的依据字段,通过 reversed() 实现倒序:
```java
//大于50的订单,按照订单价格倒序前5
orders.stream().filter(order -> order.getTotalPrice() > 50)
.sorted(Comparator.comparing(Order::getTotalPrice).reversed())
.limit(5)
.forEach(System.out::println);
6. distinct
distinct 操作的作用是去重,类似 SQL 中的 distinct。比如下面的代码实现:
- 查询去重后的下单用户。使用 map 从订单提取出购买用户,然后使用 distinct 去重。
- 查询购买过的商品名。使用 flatMap+map 提取出订单中所有的商品名,然后使用 distinct 去重。
```java
//去重的下单用户
System.out.println(orders.stream()
.map(order -> order.getCustomerName()) .distinct().collect(joining(",")));
//所有购买过的商品 System.out.println(orders.stream() .flatMap(order -> order.getOrderItemList().stream()) .map(OrderItem::getProductName) .distinct().collect(joining(“,”)));
<a name="ROx78"></a>
## 7. skip & limit
skip 和 limit 操作用于分页,类似 MySQL 中的 limit。其中,skip 实现跳过一定的项,limit 用于限制项总数。比如下面的两段代码:
- 按照下单时间排序,查询前 2 个订单的顾客姓名和下单时间;
- 按照下单时间排序,查询第 3 和第 4 个订单的顾客姓名和下单时间。
```java
//按照下单时间排序,查询前2个订单的顾客姓名和下单时间
orders.stream()
.sorted(comparing(Order::getPlacedAt))
.map(order -> order.getCustomerName() + "@" + order.getPlacedAt())
.limit(2).forEach(System.out::println);
//按照下单时间排序,查询第3和第4个订单的顾客姓名和下单时间
orders.stream()
.sorted(comparing(Order::getPlacedAt))
.map(order -> order.getCustomerName() + "@" + order.getPlacedAt())
.skip(2).limit(2).forEach(System.out::println);
8. collect
collect 是收集操作,对流进行终结操作,把流导出为我们需要的数据结构。”终结” 是指,导出后无法再串联使用其他中间操作,比如 filter、map、flatmap、sorted、distinct、limit、skip。在 Stream 的操作中 collect 是最复杂的终结操作,简单的终结操作还有 forEach、min、max、count、findFirst、findAny、anyMatch 等。
下面通过 6 个案例,来演示下几种比较常用的 collect 操作:
- 实现了字符串拼接操作,生成一定位数的随机字符串
- 通过 Collectors.toSet 静态方法收集为 Set 去重,得到去重后的下单用户,再通过 Collectors.joining 静态方法实现字符串拼接
- 通过 Collectors.toCollection 静态方法获得指定类型的集合,比如把 List 转成 LinkedList
- 通过 Collectors.toMap 静态方法将对象快速转换为 Map,Key 是订单 ID、Value 是下单用户名。
- 通过 Collectors.toMap 静态方法将对象转换为 Map。Key 是下单用户名,Value 是下单时间,一个用户可能多次下单,所以直接在这里进行了合并,只获取最近一次的下单时间。
- 使用 Collectors.summingInt 方法对商品数量求和,再使用 Collectors.averagingInt 方法对结果求平均值,以统计所有订单平均购买的商品数量。 ```java //生成一定位数的随机字符串 System.out.println(random.ints(48, 122) .filter(i -> (i < 57 || i > 65) && (i < 90 || i > 97)) .mapToObj(i -> (char) i) .limit(20) .collect(StringBuilder::new, StringBuilder::append, StringBuilder::append) .toString());
//所有下单的用户,使用toSet去重后实现字符串拼接 System.out.println(orders.stream() .map(order -> order.getCustomerName()).collect(toSet()) .stream().collect(joining(“,”, “[“, “]”)));
//用toCollection收集器指定集合类型 System.out.println(orders.stream() .limit(2).collect(toCollection(LinkedList::new)).getClass());
//使用toMap获取订单ID+下单用户名的Map orders.stream() .collect(toMap(Order::getId, Order::getCustomerName)) .entrySet().forEach(System.out::println);
//使用toMap获取下单用户名+最近一次下单时间的Map orders.stream() .collect(toMap(Order::getCustomerName, Order::getPlacedAt, (x, y) -> x.isAfter(y) ? x : y)) .entrySet().forEach(System.out::println);
//订单平均购买的商品数量 System.out.println(orders.stream().collect(averagingInt(order -> order.getOrderItemList().stream() .collect(summingInt(OrderItem::getProductQuantity)))));
可以看到,这 6 个操作使用 Stream 方式一行代码就可以实现,但使用非 Stream 方式实现的话,都需要几行甚至十几行代码。下图展示了有关 **Collectors** 类的一些常用静态方法:<br />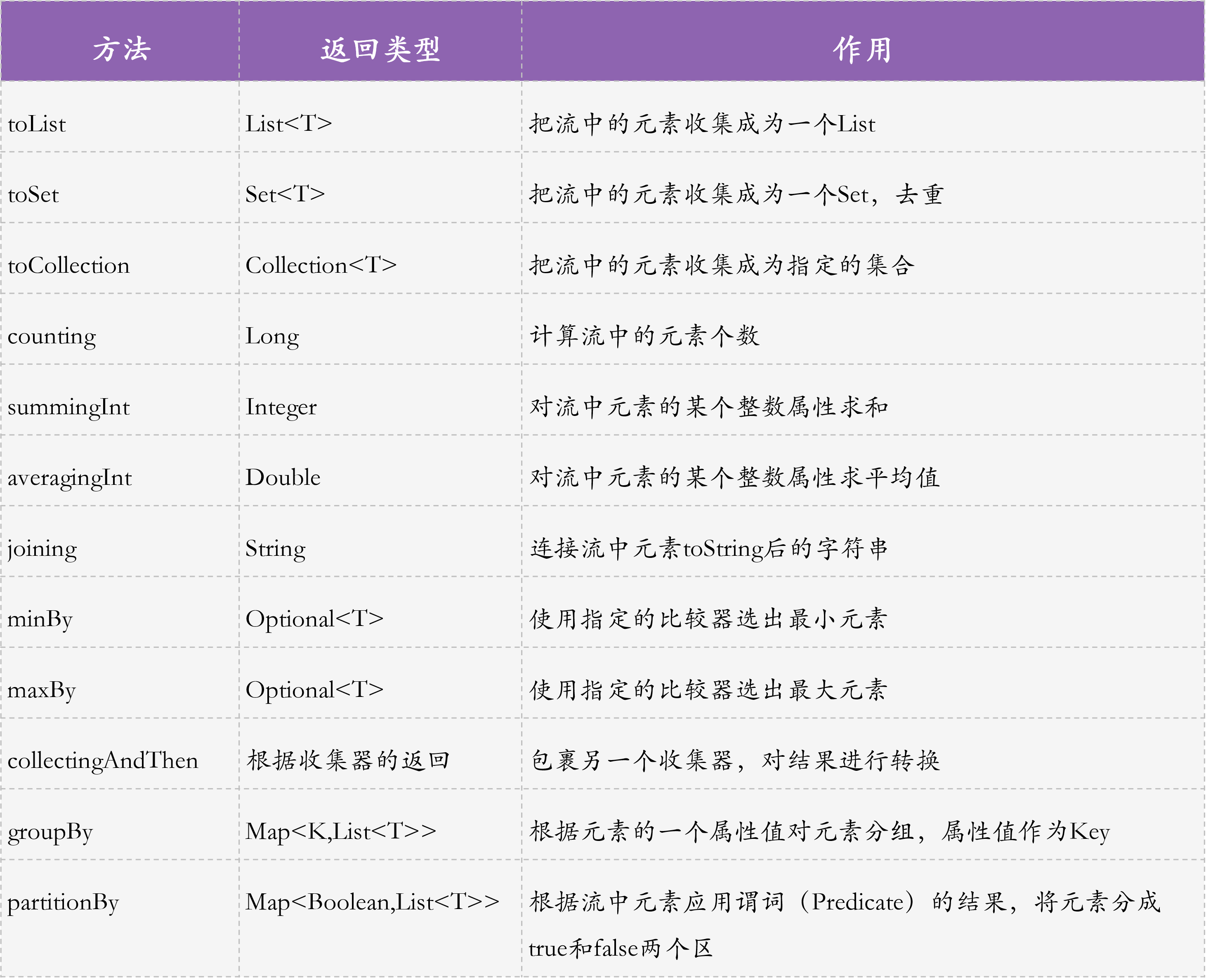<br />其中,groupingBy 和 partitionBy 比较复杂,我和你举例介绍。
<a name="MWXDK"></a>
### 8.1 groupingBy
groupingBy 是分组统计操作,类似 SQL 中的 group by 子句。它和后面介绍的 partitioningBy 都是特殊的收集器,同样也是终结操作。分组操作比较复杂,下面准备了 8 个案例帮助你理解:
- 按照用户名分组,使用 **Collectors.counting **方法统计每个人的下单数量,再按下单数量倒序输出。
- 按照用户名分组,使用 **Collectors.summingDouble** 方法统计订单总金额,再按总金额倒序输出。
- 按照用户名分组,使用两次 **Collectors.summingInt** 方法统计商品采购数量,再按总数量倒序输出。
- 统计被采购最多的商品。先通过 flatMap 把订单转换为商品,然后把商品名作为 Key、Collectors.summingInt 作为 Value 分组统计采购数量,再按 Value 倒序获取第一个 Entry,最后查询 Key 就得到了售出最多的商品。
- 同样统计采购最多的商品。相比第四个案例排序 Map 的方式,这次直接使用 **Collectors.maxBy** 收集器获得最大的 Entry。
- 按照用户名分组,统计用户下的金额最高的订单。Key 是用户名,Value 是 Order,直接通过 **Collectors.maxBy** 方法拿到金额最高的订单,然后通过 **collectingAndThen** 实现 Optional.get 的内容提取,最后遍历 Key/Value 即可。
- 根据下单年月分组统计订单 ID 列表。Key 是格式化成年月后的下单时间,Value 直接通过 **Collectors.mapping** 方法进行了转换,把订单列表转换为订单 ID 构成的 List。
- 根据下单年月 + 用户名两次分组统计订单 ID 列表,相比上一个案例多了一次分组操作,第二次分组是按照用户名进行分组。
```java
//按照用户名分组,统计下单数量
System.out.println(orders.stream()
.collect(groupingBy(Order::getCustomerName, counting()))
.entrySet().stream()
.sorted(Map.Entry.<String, Long>comparingByValue().reversed())
.collect(toList()));
//按照用户名分组,统计订单总金额
System.out.println(orders.stream()
.collect(groupingBy(Order::getCustomerName, summingDouble(Order::getTotalPrice)))
.entrySet().stream()
.sorted(Map.Entry.<String, Double>comparingByValue().reversed())
.collect(toList()));
//按照用户名分组,统计商品采购数量
System.out.println(orders.stream().collect(groupingBy(Order::getCustomerName,
summingInt(order -> order.getOrderItemList().stream()
.collect(summingInt(OrderItem::getProductQuantity)))))
.entrySet().stream().sorted(Map.Entry.<String, Integer>comparingByValue().reversed()).collect(toList()));
//统计最受欢迎的商品,倒序后取第一个
orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.collect(groupingBy(OrderItem::getProductName, summingInt(OrderItem::getProductQuantity)))
.entrySet().stream()
.sorted(Map.Entry.<String, Integer>comparingByValue().reversed())
.map(Map.Entry::getKey)
.findFirst()
.ifPresent(System.out::println);
//统计最受欢迎的商品的另一种方式,直接利用maxBy
orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.collect(groupingBy(OrderItem::getProductName, summingInt(OrderItem::getProductQuantity)))
.entrySet().stream()
.collect(maxBy(Map.Entry.comparingByValue()))
.map(Map.Entry::getKey)
.ifPresent(System.out::println);
//按照用户名分组,选用户下的总金额最大的订单
orders.stream().collect(groupingBy(Order::getCustomerName, collectingAndThen(maxBy(comparingDouble(Order::getTotalPrice)), Optional::get)))
.forEach((k, v) -> System.out.println(k + "#" + v.getTotalPrice() + "@" + v.getPlacedAt()));
//根据下单年月分组,统计订单ID列表
System.out.println(orders.stream().collect
(groupingBy(order -> order.getPlacedAt().format(DateTimeFormatter.ofPattern("yyyyMM")),
mapping(order -> order.getId(), toList()))));
//根据下单年月+用户名两次分组,统计订单ID列表
System.out.println(orders.stream().collect
(groupingBy(order -> order.getPlacedAt().format(DateTimeFormatter.ofPattern("yyyyMM")),
groupingBy(order -> order.getCustomerName(),
mapping(order -> order.getId(), toList())))));
如果不借助 Stream 转换为普通的 Java 代码,实现这些复杂的操作可能需要几十行代码。
8.2 partitionBy
partitioningBy 用于分区,分区是特殊的分组,只有 true 和 false 两组。比如,我们把用户按照是否下单进行分区,给 partitioningBy 方法传入一个 Predicate 作为数据分区的区分,输出是 Map>:
public static <T>
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {
return partitioningBy(predicate, toList());
}
测试一下,partitioningBy 配合 anyMatch,可以把用户分为下过订单和没下过订单两组:
//根据是否有下单记录进行分区
System.out.println(Customer.getData().stream().collect(
partitioningBy(customer -> orders.stream().mapToLong(Order::getCustomerId)
.anyMatch(id -> id == customer.getId()))));
9. peek
使用 Stream 可以非常方便地对 List 做各种操作,那有没有什么办法可以实现在整个过程中观察数据变化呢?比如,我们进行 filter+map 操作,如何观察 filter 后 map 的原始数据呢?
要想观察使用 Stream 对 List 的各种操作的过程中的数据变化,我们可以使用 peek 方法。如下代码,我们对数字 1~10 进行了两次过滤,分别是找出大于 5 的数字和找出偶数,通过 peek 方法把两次过滤操作之前的原始数据保存了下来:
List<Integer> firstPeek = new ArrayList<>();
List<Integer> secondPeek = new ArrayList<>();
List<Integer> result = IntStream.rangeClosed(1, 10)
.boxed()
.peek(i -> firstPeek.add(i))
.filter(i -> i > 5)
.peek(i -> secondPeek.add(i))
.filter(i -> i % 2 == 0)
.collect(Collectors.toList());
System.out.println("firstPeek:" + firstPeek);
System.out.println("secondPeek:" + secondPeek);
System.out.println("result:" + result);
最后得到输出,可以看到第一次过滤之前是数字 1~10,一次过滤后变为 6~10,最终输出 6、8、10 三个数字:
firstPeek:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
secondPeek:[6, 7, 8, 9, 10]
result:[6, 8, 10]

若有收获,就点个赞吧
0 人点赞
